Command Palette
Search for a command to run...
3Dアウェアな暗黙的モーション制御を用いた視点適応型人体動画生成
3Dアウェアな暗黙的モーション制御を用いた視点適応型人体動画生成
Zhixue Fang Xu He Songlin Tang Haoxian Zhang Qingfeng Li Xiaoqiang Liu Pengfei Wan Kun Gai
概要
ビデオ生成における人間の動き制御を実現する従来の手法は、通常、2次元ポーズまたは明示的な3次元パラメトリックモデル(例:SMPL)を制御信号として用いている。しかし、2次元ポーズは動きをドライブする視点に強く束縛され、新視点の合成を不可能にしている。一方、明示的な3次元モデルは構造的な情報を提供するものの、本質的な不正確さ(例:奥行の曖昧さや不正確な運動特性)を抱えており、これらを強い制約として用いると、大規模なビデオ生成モデルが持つ強力な内在的3次元認識能力が覆されてしまう。本研究では、3次元認識に配慮した観点から動き制御を見直し、生成モデルの空間的事前知識と自然に整合する、暗黙的かつ視点に依存しない動き表現の導入を提唱する。そこで、事前学習済みのビデオ生成モデルと連携して動作エンコーダを共同学習させる「3DiMo」を提案する。この手法により、ドライブフレームからコンパクトで視点に依存しない動きトークンを抽出し、クロスアテンションを介して意味的に注入する。3次元認識を強化するため、単一視点、多視点、および動くカメラによるビデオを用いた豊富な視点監督を導入し、異なる視点間での動きの一貫性を強制する。さらに、補助的な幾何学的監督を用いるが、SMPLは初期化にのみ利用し、学習の進行に伴い徐々に減衰させることで、外部の3次元ガイドからデータおよび生成モデルの事前知識に基づく本質的な3次元空間的動き理解の学習へとモデルを移行させる。実験の結果、3DiMoは柔軟なテキスト駆動カメラ制御を可能にしつつ、ドライブ動作を忠実に再現でき、従来手法に比べて動きの忠実度および視覚的品質の両面で顕著な性能向上を示した。
One-sentence Summary
Researchers from Kuaishou Technology, Tsinghua University, and CASIA propose 3DiMo, a view-agnostic motion representation that enables faithful 3D motion reproduction from 2D videos via text-guided camera control, outperforming prior methods by aligning with generator priors rather than relying on rigid 3D models.
Key Contributions
- 3DiMo introduces a 3D-aware motion control framework that extracts implicit, view-agnostic motion tokens from 2D driving videos, enabling novel-view synthesis and text-guided camera control without rigid geometric constraints from external 3D models.
- The method jointly trains a motion encoder with a pretrained video generator using view-rich supervision—including single-view, multi-view, and moving-camera videos—to enforce motion consistency across viewpoints and align with the generator’s intrinsic spatial priors.
- Auxiliary geometric supervision from SMPL is used only during early training and gradually annealed to zero, allowing the model to transition from external guidance to learning genuine 3D motion understanding, resulting in state-of-the-art motion fidelity and visual quality on benchmark tasks.
Introduction
The authors leverage large-scale video generators’ inherent 3D spatial awareness to rethink human motion control, moving beyond rigid 2D pose conditioning or error-prone explicit 3D models like SMPL. Prior methods either lock motion to the driving viewpoint or impose inaccurate 3D constraints that override the generator’s native priors, limiting viewpoint flexibility and motion fidelity. Their main contribution is 3DiMo, an end-to-end framework that learns implicit, view-agnostic motion tokens from 2D driving frames via a Transformer encoder, injected through cross-attention to align with the generator’s spatial understanding. Training uses view-rich supervision—single-view, multi-view, and moving-camera videos—plus an annealed auxiliary loss tied to SMPL for early geometric guidance, enabling the model to transition toward genuine 3D motion reasoning. This yields high-fidelity, text-guided camera control while preserving 3D consistency across views.
Dataset

- The authors construct a view-rich 3D-aware dataset combining three sources: large-scale internet videos for expressive motion diversity, synthetic UE5-rendered sequences for precise camera motion control, and real-world multi-view captures (including proprietary recordings) for authentic 3D supervision.
- Internet videos dominate in volume and train expressive motion dynamics under single-view reconstruction; synthetic and real multi-view data are smaller but critical for enforcing 3D consistency via cross-view motion reproduction and moving-camera supervision.
- Text prompts for camera viewpoints and movements are generated using Qwen2.5-VL, unifying annotations across all data types for text-guided camera control.
- Training follows a three-stage progressive strategy: Stage 1 uses only single-view reconstruction for stable motion initialization; Stage 2 mixes reconstruction and cross-view reproduction to transition toward 3D semantics; Stage 3 focuses entirely on multi-view and camera-motion data to strengthen view-agnostic motion features.
- Reference images are taken from the first frame of the target video to align generated motion with subject orientation, avoiding explicit camera alignment or SMPL regression.
- Auxiliary geometric supervision is introduced early via a lightweight MLP decoder predicting SMPL/MANO pose parameters (excluding global root orientation) to stabilize training and initialize motion representations; this supervision is gradually annealed and removed by Stage 3.
- Proprietary real-world captures use a three-camera array with randomized camera motions—including static, linear, zoom, and complex trajectories—paired with identical human motions to maximize view-agnostic learning signals.
Method
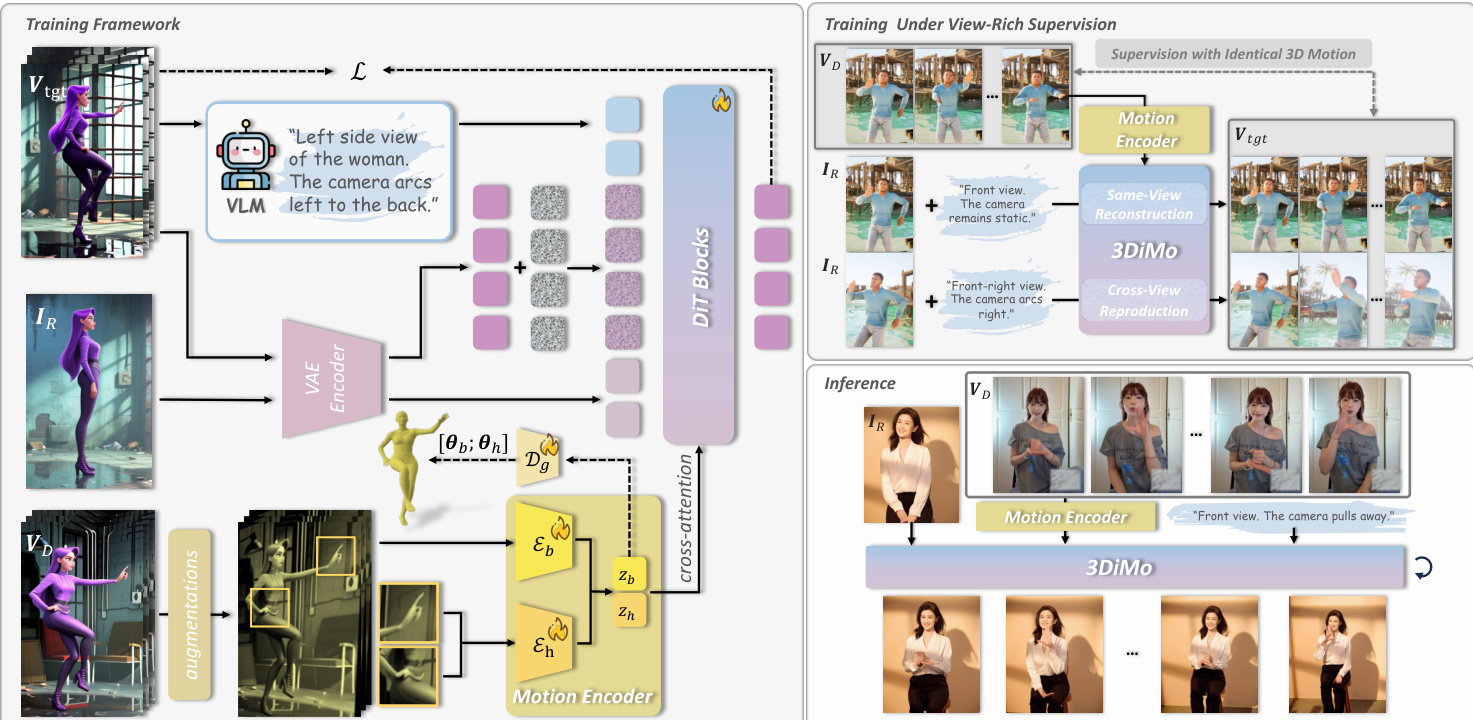
The authors leverage a pretrained DiT-based video generation model as the backbone, which is conditioned on a reference image, a driving video, and a text prompt to synthesize a target video that reenacts the driving motion while preserving text-guided camera control. The core innovation lies in the design of an implicit motion encoder, trained end-to-end with the generator, that extracts view-agnostic motion representations from 2D driving frames and injects them via cross-attention to enable semantically coherent motion transfer.
Refer to the framework diagram, which illustrates the full pipeline. The motion encoder consists of two specialized components: a body encoder Eb and a hand encoder Eh, each designed to capture coarse body motion and fine hand dynamics, respectively. Driving frames are first augmented with random perspective transformations and appearance perturbations to encourage the encoder to discard view-specific and identity-dependent cues. Each frame is patchified into visual tokens and concatenated with a fixed number K of learnable latent tokens. After several attention layers, only the latent tokens are retained as the motion representation zb and zh, forming a semantic bottleneck that strips away 2D structural information while preserving the intrinsic 3D motion semantics.
These motion tokens are then concatenated and injected into the DiT generator via cross-attention layers appended after each full self-attention block. This design allows motion tokens to interact semantically with video tokens without imposing rigid spatial alignment constraints, enabling flexible coexistence with the generator’s native text-driven camera control. The text prompt, which may include camera movement instructions, is processed through the same self-attention mechanism as the visual tokens, allowing joint control over motion and viewpoint.
To endow the motion representations with 3D awareness, the authors introduce early-stage geometric supervision using parametric human models (SMPL for body, MANO for hands). During training, auxiliary decoders regress the motion tokens to external 3D pose parameters θb and θh, providing geometric alignment signals that accelerate spatial understanding. The framework is trained on a view-rich dataset that includes single-view, multi-view, and camera-motion sequences, enabling the model to learn cross-view motion consistency and genuine 3D motion priors. Training alternates between same-view reconstruction and cross-view motion reproduction tasks, reinforcing the emergence of expressive, 3D-aware motion representations.
At inference, the motion encoder directly processes 2D driving frames to extract motion tokens, which are then used to animate any reference subject under arbitrary text-guided camera trajectories. This eliminates the need for external pose estimation or explicit 3D reconstruction, enabling high-fidelity, view-adaptive motion-controlled video generation.
Experiment
- 3DiMo outperforms state-of-the-art 2D and 3D methods in motion control and visual fidelity, particularly in LPIPS, FID, and FVD, demonstrating superior 3D-aware reenactment despite slightly lower PSNR/SSIM due to intentional geometric consistency over pixel alignment.
- Qualitative results show 3DiMo produces physically plausible, depth-accurate motions, avoiding limb ordering errors common in 2D methods and pose inaccuracies in SMPL-based approaches, especially under dynamic camera prompts.
- User studies confirm 3DiMo excels in motion naturalness and 3D plausibility, validating its learned motion representation better captures spatial and dynamic realism than parametric or 2D alignment methods.
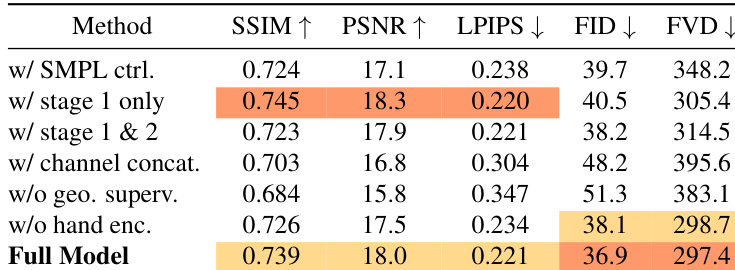
- Ablation studies reveal that implicit motion representation, multi-stage view-rich training, cross-attention conditioning, and auxiliary geometric supervision are critical for stable training and 3D-aware control; removing them degrades quality or causes collapse.
- The model enables novel applications: single-image human novel view synthesis with stable subject rendering, video stabilization by enforcing static camera prompts, and automatic motion-image alignment via view-agnostic motion transfer without manual calibration.
The authors evaluate ablation variants of their model and find that removing key components such as geometric supervision, hand motion encoding, or using channel concatenation instead of cross-attention consistently degrades performance. The full model achieves the best balance across metrics, particularly in FID and FVD, indicating superior visual fidelity and motion coherence. Results confirm that multi-stage training with view-rich data and auxiliary supervision is essential for stable learning and 3D-aware motion control.
The authors use a 3D-aware implicit motion representation to achieve superior motion control and visual fidelity compared to both 2D pose-based and SMPL-based baselines. Results show their method outperforms others in perceptual metrics and user studies, particularly in motion naturalness and 3D plausibility, despite slightly lower pixel-wise scores due to enforced geometric consistency. Ablation studies confirm that multi-stage view-rich training and cross-attention conditioning are critical for stable, high-fidelity 3D motion synthesis.
