Command Palette
Search for a command to run...
Green-VLA:汎用ロボット向けの段階的ビジュアル・言語・アクションモデル
Green-VLA:汎用ロボット向けの段階的ビジュアル・言語・アクションモデル
概要
グリーン・VLA(Green-VLA)を紹介する。これは、グリーン人型ロボット(Green humanoid robot)における実世界への展開を目的としつつ、多様なエムボディメント(身体構造)間で一般化性能を維持するための段階的視覚言語行動(Vision-Language-Action: VLA)フレームワークである。グリーン・VLAは以下の5段階のカリキュラムに従う:(L0)基礎となる視覚言語モデル(VLM)、(L1)マルチモーダルな意味の根拠付け、(R0)多エムボディメントでの事前学習、(R1)エムボディメント固有の適応、および(R2)強化学習(Reinforcement Learning: RL)によるポリシーの整合化。本研究では、スケーラブルなデータ処理パイプライン(3,000時間分のデモンストレーションデータ)を、時間軸上の同期処理および品質フィルタリングと組み合わせ、一貫性のあるエムボディメント認識型アクションインターフェースを採用することで、同一のポリシーが人型ロボット、モバイルマニピュレーター、固定基盤型アームを統合制御可能にしている。推論段階では、エピソード進行予測、分布外検出、およびジョイント予測に基づくガイダンスをVLAコントローラーに統合し、安全性の向上および正確なターゲット選択を実現している。シミュレータ上でのSimpler BRIDGE WidowXおよびCALVIN ABC-Dにおける実験、および実機ロボット評価の結果、RLによるポリシー整合化によって、成功確率、ロバスト性、および長期的なタスク効率において顕著な性能向上と優れた一般化能力が確認された。
One-sentence Summary
Sber Robotics Center’s Green-VLA introduces a staged Vision-Language-Action framework that unifies heterogeneous robot data via semantic action alignment, DATAQA filtering, and RL refinement, enabling zero-shot generalization to humanoids and manipulators while boosting long-horizon success through episode-progress prediction and joint-guidance modules.
Key Contributions
- Green-VLA introduces a quality-driven data pipeline with DATAQA filters and temporal alignment, processing 3,000 hours of heterogeneous robot demonstrations to ensure stable, high-fidelity training across diverse embodiments and control types.
- It proposes a five-stage training curriculum (L0–R2) that progressively bridges web-scale vision-language models to embodiment-specific RL alignment, enabling a single policy to control humanoids, mobile manipulators, and fixed-base arms without architectural changes.
- Evaluated on the high-DoF Green humanoid and other platforms, Green-VLA achieves state-of-the-art performance in long-horizon tasks, with RL alignment (R2) yielding significant gains in success rate, robustness, and precise object targeting via joint-prediction guidance.
Introduction
The authors leverage a staged Vision-Language-Action (VLA) framework called Green-VLA to address the gap between scalable foundation models and real-world robotic deployment. While prior VLAs benefit from large datasets and unified architectures, they suffer from heterogeneous, noisy data and reliance on behavior cloning—which fails to optimize for long-horizon success or generalize across robot embodiments. Green-VLA overcomes these by introducing a five-stage training curriculum that progressively builds semantic grounding, unifies action spaces across platforms, and refines policies via reinforcement learning. It also integrates a DATAQA pipeline for data quality filtering and a joint-prediction module for precise targeting, enabling zero-shot generalization to new robots—including the high-DoF Green humanoid—while improving robustness, success rate, and task efficiency.
Dataset
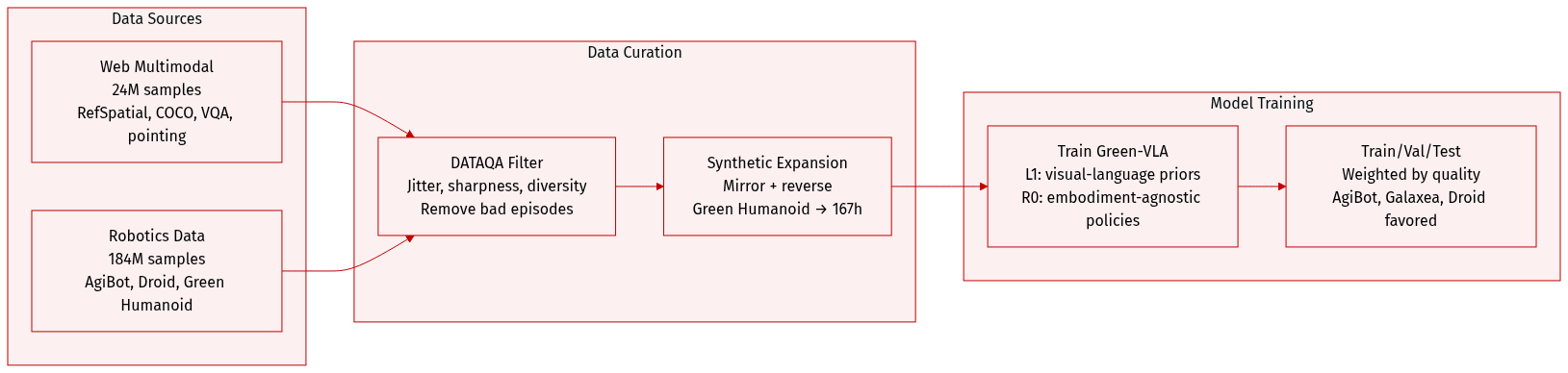
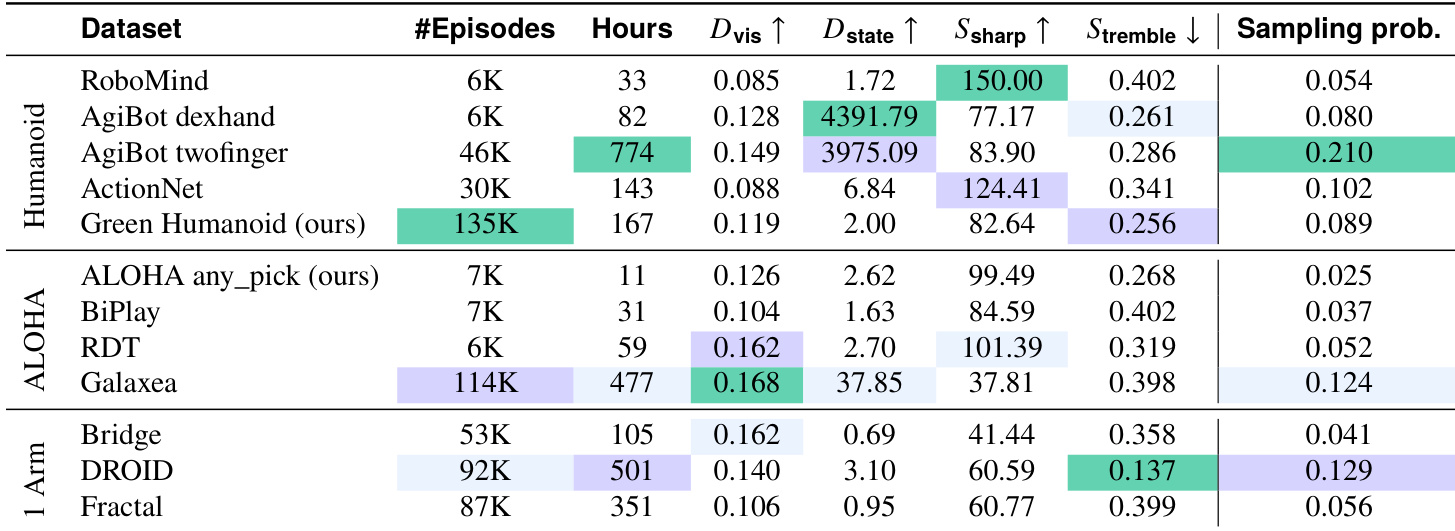
The authors use a two-stage training pipeline for Green-VLA, combining web-scale multimodal data (L1) and large-scale robotics data (R0), totaling over 200M samples and 3,000+ hours of robot trajectories. Here’s how the dataset is composed, processed, and used:
-
Dataset Composition & Sources:
- L1 (24M samples): Web multimodal data from 10+ sources including RefSpatial, AgibotWorld, RoboPoint, ShareRobot, Robo2VLM, PixMo-Points, MS COCO, A-OKVQA, OpenSpaces, and Sun RGB-D. Tasks cover VQA, pointing, captioning, spatial reasoning, and pixel-wise trajectory prediction.
- R0 (184M samples): Robotics data from 12+ open-source and 2 internally collected datasets, including AgiBotWorld, Droid, Galaxea, Action_net, Fractal, Robomind, RDT, Bridge, BiPlay, Green Humanoid, and ALOHA any_pick. Covers humanoid and manipulator platforms with diverse skills and environments.
-
Key Subset Details:
- Web Data (L1): Samples are weighted during training for task balance. RefSpatial and PixMo-Points map spatial points to PaliGemma tokens. MS COCO is limited to object detection; Sun RGB-D uses only 2D annotations.
- Robotics Data (R0): AgiBotWorld_twofinger (774h) and Droid (512h) are largest. Green Humanoid (48h real) is synthetically expanded to 167h via mirroring (flipping cameras/joints, swapping left/right) and time-reversal (only for reversible tasks like pick/place). ALOHA any_pick adds 11.2h focused on pick/place tasks.
-
Data Processing & Filtering:
- All robot data is temporally normalized to align physical progress across sources.
- DATAQA pipeline filters episodes using four metrics: jitter (motion smoothness), diversity (visual/state-space), sharpness (Laplacian-based image clarity), and state variance.
- Additional filters: remove episodes with missing cameras/frames, extreme durations, low motion activity, or invalid gripper patterns (e.g., “open-closed-open” for pick-and-place).
- Visual diversity is measured via DINOv3 feature variance over time; state diversity via Frobenius norm of state covariance.
-
Training Usage:
- L1 trains general visual-language priors; R0 trains embodiment-agnostic policies.
- Mixture ratios are weighted by dataset quality metrics (Table 1). AgiBot twofinger and Galaxea receive highest weights due to size and visual diversity. Droid leads among single-arm datasets for smoothness and task diversity.
- All trajectories are stored with RGB, proprioception, and language instructions. Augmented mirrored/reversed episodes are added to the R0 mixture.
-
Cropping & Metadata:
- No explicit cropping mentioned; processing focuses on temporal alignment, state normalization, and spatial token mapping.
- Metadata includes task text, camera views, joint/Cartesian states, and filtered quality scores per episode.
Method
The authors leverage a staged training pipeline and a unified transformer-based architecture to build Green-VLA, a vision-language-action model capable of multi-embodiment control and real-world deployment. The overall framework is structured around five sequential training stages—L0 through R2—each designed to address distinct bottlenecks in generalization, embodiment adaptation, and long-horizon robustness. As shown in the figure below, the pipeline begins with a base vision-language model (L0), progresses through web-scale multimodal pretraining (L1) and general robotics pretraining (R0), then undergoes embodiment-specific fine-tuning (R1), and finally integrates reinforcement learning alignment (R2) to close the last-mile performance gap.
At the architectural level, Green-VLA employs a single transformer backbone that fuses multimodal inputs—RGB observations, proprioceptive state, and natural language instructions—into a shared token sequence. This sequence is augmented with an embodiment-specific control prompt ce, which encodes the robot’s physical configuration (e.g., number of arms, control type, mobility). The model then predicts actions in a fixed 64-dimensional unified action space Au, where each index corresponds to a semantically consistent physical degree of freedom across all supported embodiments. This design replaces naive padding of heterogeneous action spaces with a masked behavior cloning objective:
Luni(θ)=E[me⊙(πθ(xte,ce)−Φe(ate))22],where me is a binary mask indicating active slots for embodiment e, and Φe maps native actions into the unified layout. The model’s output is then retargeted to the target robot’s native control space via Φe−1, enabling cross-embodiment transfer without semantic drift.
To support real-time inference, the architecture incorporates efficiency optimizations: SDPA attention kernels, lightweight prediction heads, and reduced denoising steps in the flow-matching action expert. The model also predicts an episode progress scalar ρ^t∈[0,1], trained to reflect normalized time-to-completion, which enables downstream planners to dynamically adjust subgoals during long-horizon execution.
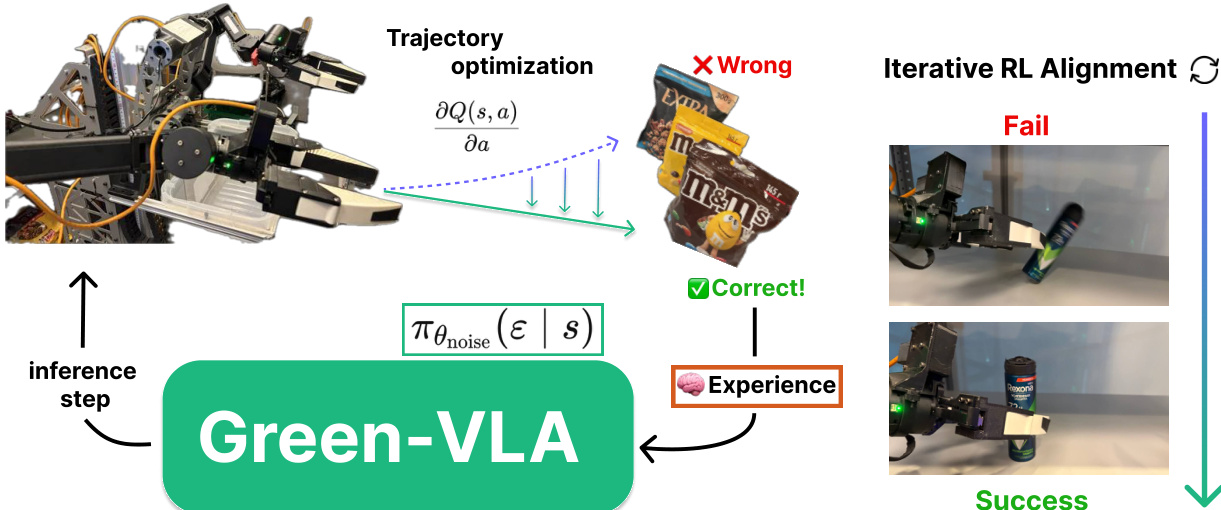
A key innovation is the integration of a high-level task planner based on GigaVision, which operates independently and remains frozen during training. This planner parses user instructions into atomic subtasks (e.g., “pick [item] with [left] hand”) and conditions Green-VLA via structured prompts. During execution, Green-VLA signals task completion via an episode-end probability; if this exceeds a threshold, the planner queries a feedback module to validate success or trigger replanning. Refer to the framework diagram for the full inference loop, which includes guidance and safety modules.

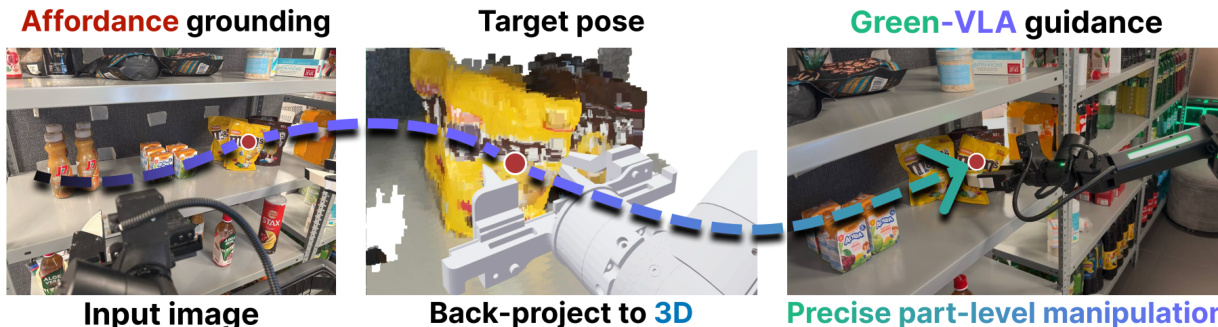
To handle novel objects specified in language, Green-VLA incorporates a Joint Prediction Module (JPM) that infers a 3D target point p∗ in the robot’s workspace from the instruction and visual observation. This point is derived by first predicting a 2D affordance location via a vision-language model, then lifting it to 3D using camera intrinsics and pose:
[p⋆1]=Tcw[d(u,v)K−1[u,v,1]⊤1].The resulting point is used to compute a feasible joint configuration q∗ via inverse kinematics, which then guides the flow-matching policy via pseudoinverse guidance (PiGDM), biasing the velocity field toward trajectories that reach the target.
For safety and stability, Green-VLA includes an online OOD detector modeled as a Gaussian Mixture Model fitted on training robot states. If the predicted trajectory leads to a low-density state s (i.e., ptrain(s)<τood), the model corrects the action by nudging the state toward higher density using the gradient of the GMM:
s←s+α∇ptrain(s),α=0.2.This correction mechanism, illustrated in the inference diagram, ensures the policy remains within the training distribution during long-horizon tasks.
Training stability across diverse embodiments is achieved through a scheduled dataset sampling curriculum. Instead of sampling datasets according to their target weights wi from the start, Green-VLA uses a power-law schedule:
Wi(t)=∑jwjαtwiαt,αt∈[0,1],α0=0,αT=1,which begins with uniform sampling and gradually converges to the target distribution. This prevents early dominance by large datasets and allows the model to first learn shared structure before specializing.
To standardize heterogeneous demonstrations, Green-VLA performs temporal alignment using optical flow magnitude as a proxy for motion speed. Trajectories are resampled via monotonic cubic splines to normalize motion per step, ensuring consistent dynamics across datasets. Additionally, a speed-conditioned modulation is introduced during training: for each sample, a scalar v∼p(v) is drawn, and the target trajectory is warped to operate at different temporal resolutions. The model’s hidden states are modulated via:
h~t=RMSNorm(ht),h^t=γ(v)h~t+β(v),where γ(v) and β(v) are learned functions. This enables Green-VLA to operate on multiple temporal “zoom levels,” supporting both fine-grained manipulation and coarse long-horizon motion.
The final R2 stage employs two RL fine-tuning strategies that preserve the base model’s weights. The first, trajectory optimization with native fine-tuning, trains a separate critic using Implicit Q-Learning and uses its gradient ∇aQ(s,a) to iteratively refine actions:
a←a+η∥∇aQ(s,a)∥∇aQ(s,a),where η is a hyperparameter. Optimized trajectories are validated in the environment before being added to the training set. The second approach, optimization of the source distribution, trains a small actor network to sample noise vectors that, when fed into the flow-matching model, yield higher returns. This method enables online RL without directly modifying the base policy’s parameters.
Experiment
- Green-VLA demonstrates strong task-following and cross-embodiment generalization after R0 pretraining, outperforming prior models despite using substantially less training data, validating the value of unified action representation and quality-aligned datasets.
- In R1 fine-tuning, Green-VLA adapts effectively to new environments like CALVIN and e-commerce shelves without prior exposure, showing robust compositional generalization and improved performance under fine-grained instruction following, especially with JPM guidance for SKU-level accuracy.
- R2 RL alignment significantly boosts long-horizon task consistency and physical reliability, increasing success rates and average chain length across benchmarks, particularly in challenging manipulation scenarios involving deformable or slippery objects.
- Humanoid evaluations confirm the system’s ability to execute complex, multi-step instructions with precise hand selection, object disambiguation, and full upper-body coordination—even under out-of-distribution scene layouts—while maintaining efficiency in table cleaning and sorting workflows.
- Across all phases and embodiments, Green-VLA consistently improves with staged training, showing that combining unified pretraining, embodiment-specific tuning, and RL refinement yields robust, scalable, and instruction-following capable robotic policies.
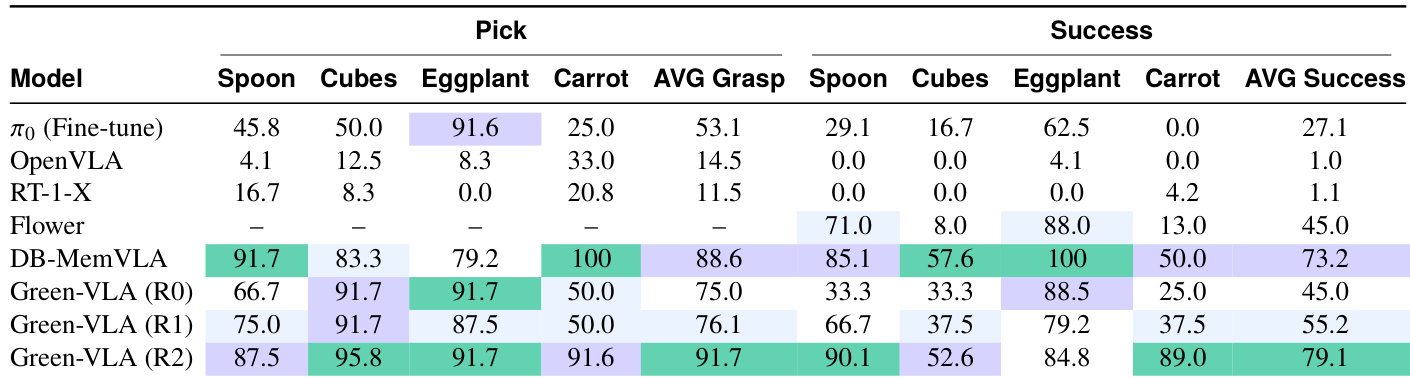
The authors evaluate Green-VLA across training phases R0, R1, and R2, showing progressive gains in both pick accuracy and task success across diverse objects. Results show that R2 RL alignment delivers the largest performance boost, particularly in success rate, outperforming prior models including fine-tuned baselines. Green-VLA consistently improves with each stage, demonstrating that staged training enhances both precision and robustness in manipulation tasks.
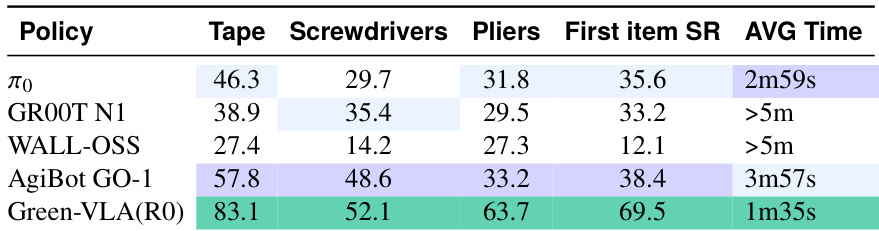
The authors evaluate Green-VLA against several baselines on object picking and table-cleaning tasks, finding that it achieves higher success rates and faster execution times across multiple object categories. Results show Green-VLA outperforms prior models even without embodiment-specific fine-tuning, indicating strong generalization from multi-embodiment pretraining. The model’s efficiency and accuracy improvements are consistent across both single-item and full-task scenarios.
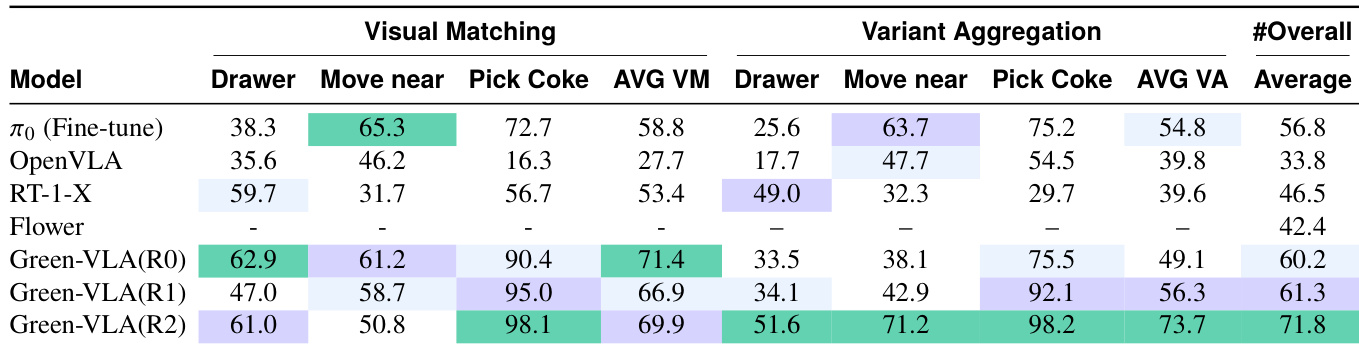
The authors evaluate Green-VLA across training phases R0, R1, and R2, measuring performance on visual matching and variant aggregation tasks. Results show that Green-VLA consistently improves across phases, with R2 achieving the highest overall score, indicating that reinforcement learning alignment enhances both task precision and robustness. The model outperforms baselines like π₀ and OpenVLA, particularly in fine-grained object selection and handling variant conditions.
The authors use a unified multi-embodiment dataset to train Green-VLA, achieving strong task-following and efficiency despite using substantially less data than prior systems. Results show that their model generalizes well across diverse robotic platforms and task types, with performance gains further amplified through embodiment-specific fine-tuning and RL alignment. The architecture’s separation of perception and control enables robust execution even under out-of-distribution conditions and complex multi-step workflows.