Command Palette
Search for a command to run...
daVinci-Agency:長期スパンのエージェンシー・データを効率的に活用する
daVinci-Agency:長期スパンのエージェンシー・データを効率的に活用する
概要
大規模言語モデル(LLM)は短期的なタスクにおいて優れた性能を発揮するが、長期間にわたるエージェント型ワークフローへのスケーリングは依然として困難である。その根本的な課題は、本物の長距離依存構造や段階間の進化的ダイナミクスを捉えたトレーニングデータの不足にあり、既存の合成手法はモデルの分布に制約された単一特徴の状況に閉じ込められたり、人的ラベル付けコストが著しく高くなり、スケーラブルかつ高品質な教師信号を提供できていない。本研究では、現実世界のソフトウェア進化の視点からデータ合成の概念を再定義することで、この課題に取り組む。我々の核心的な洞察は、プルリクエスト(PR)の連鎖が、長期間学習における自然な教師信号を内包しているということである。PRシーケンスは複雑な目標を検証可能な提出単位に分解し、反復的な変更において機能的一貫性を維持するとともに、バグ修正履歴を通じて本物の改良パターンを記録している。この知見を基に、我々は「daVinci-Agency」を提案する。これは、PR連鎖から構造化された教師信号を体系的に抽出するための3つの相互接続されたメカニズムを備えている:(1)継続的なコミットによる段階的タスク分解、(2)統一された機能的目標による長期的整合性の確保、(3)本物のバグ修正経路から得られる検証可能な改良プロセス。従来の合成シーケンスが各ステップを独立して扱うのに対し、daVinci-AgencyはPRに基づく構造により、持続的な目的指向行動を学習するために不可欠な因果関係と反復的改善を自然に保持する。これにより、プロジェクト単位の全サイクルタスクモデリングとの自然な整合性も実現できる。得られたシーケンスは非常に規模が大きく、平均して85,000トークン、116回のツール呼び出しを含むが、驚くべきデータ効率性を備えている。239サンプルのdaVinci-AgencyデータでGLM-4.6をファインチューニングした結果、複数のベンチマークで広範な性能向上が得られ、特にToolathlonでは相対的に47%の向上を達成した。ベンチマーク性能以上の意義として、我々の分析は……
One-sentence Summary
Researchers from SII, SJTU, PolyU, and GAIR propose daVinci-Agency, a novel framework mining long-horizon supervision from real-world PR sequences to train LLMs for agentic workflows, outperforming synthetic methods by preserving causal dependencies and achieving 47% gains on Toolathon with minimal data.
Key Contributions
- daVinci-Agency addresses the scarcity of long-horizon training data by mining structured supervision from real-world GitHub Pull Request sequences, which naturally encode task decomposition, functional consistency, and iterative refinement through authentic software evolution.
- The method constructs multi-PR trajectories averaging 85k tokens and 116 tool calls, enabling data-efficient training—fine-tuning GLM-4.6 on just 239 samples yields a 47% relative gain on Toolathon and outperforms models trained on 66k synthetic samples.
- Beyond benchmark gains, the approach reveals the model’s internalization of long-horizon behaviors and uncovers scaling laws specific to extended planning, establishing PR-grounded evolution as a scalable paradigm for teaching persistent, goal-directed agency.
Introduction
The authors leverage real-world GitHub Pull Request (PR) sequences to address the scarcity of high-quality, long-horizon training data for agentic LLMs. While existing methods either rely on synthetic trajectories that lack cross-stage dependencies or expensive human annotations, PR chains naturally encode iterative refinement, functional consistency, and verifiable feedback—critical for teaching persistent goal-directed behavior. Their contribution, daVinci-Agency, mines structured supervision from chained PRs to train agents on task decomposition, long-term consistency, and refinement, achieving a 47% gain on Toolathon with just 239 samples—demonstrating exceptional data efficiency and revealing scalable training laws for extended planning tasks.
Dataset

The authors use nine carefully selected GitHub repositories as the foundation of the daVinci-Agency dataset, chosen to reflect real-world, long-horizon software development. Selection criteria include:
- Scale and Maturity: Repositories with over 7,000 effective PRs to ensure rich inter-PR dependencies.
- Community Interactivity: High-frequency code reviews to capture natural language reasoning signals.
- Linguistic Diversity: Spanning Python, Java, C, Rust, and Go to cover diverse technology stacks.
Each repository contributes PR chains constructed via GitHub API metadata, using commit and review citations to build a dependency topology (e.g., PR #21 references PR #15). This topology preserves non-contiguous, real-world iteration patterns.
For each PR in a chain, the authors generate a sub-query using an LLM, which describes the problem and reasoning chain while intentionally omitting implementation details—forcing the agent to navigate and localize code during rollout. Each query is augmented with a global overview of the entire PR chain to provide macroscopic context.
The final dataset comprises 9 repositories, including numpy/numpy, scipy/scipy, apache/pulsar, and astral-sh/ruff, covering scientific computing, distributed systems, and modern tooling. Table 4 lists each repo’s total PRs and final constructed task queries.
The data is used to train agents on long-horizon reasoning, with queries serving as inputs to agentic rollouts. No cropping or metadata construction beyond PR topology and query synthesis is applied. The pipeline emphasizes state evolution and step-by-step consistency over isolated task solving.
Method
The authors leverage a hierarchical, long-horizon agent-environment interaction framework to model autonomous software engineering as a sequential decision-making process grounded in Markov Decision Processes. At each time step, the agent observes a state and alternates between internal reasoning messages and external tool executions, forming a trajectory that transforms the codebase from an initial to a target state aligned with a given query. This paradigm explicitly captures the temporal and semantic dependencies inherent in real-world development workflows, where tasks are rarely isolated but instead evolve through chains of interdependent Pull Requests.
Refer to the framework diagram illustrating the end-to-end pipeline: the process begins with query construction from a PR chain, proceeds through multi-stage rollout data collection under a state-propagating environment, and concludes with training data processing via rejection sampling and scaling. The environment enforces continuity by recursively applying the agent’s prior patch to the next stage’s base commit, formalized as Sinit(t)=Bt⊕Δτt−1, ensuring that each subsequent task is conditioned on the agent’s own evolving codebase state. This recursive dependency compels the agent to maintain long-term consistency and manage error accumulation across stages.
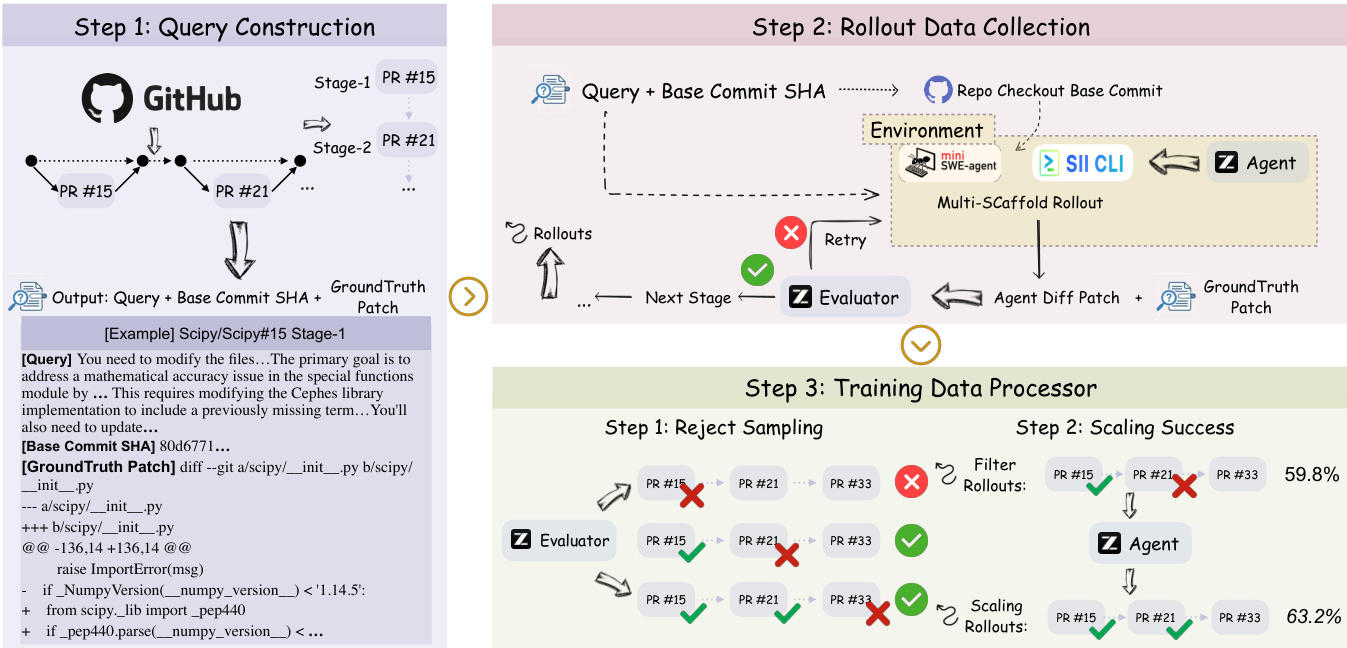
The training objective minimizes the negative log-likelihood of the agent’s policy πθ over high-fidelity trajectories, where supervision is derived from cross-stage evolution. Trajectories are filtered using a semantic evaluator—GLM-4.6—that scores alignment between generated and ground truth patches, retaining only those with s≥0.8. This rigorous filtering ensures that the training dataset Dtrain encodes not just task completion but also refinement strategies and long-term consistency, as emphasized in the project evolution level of software development.
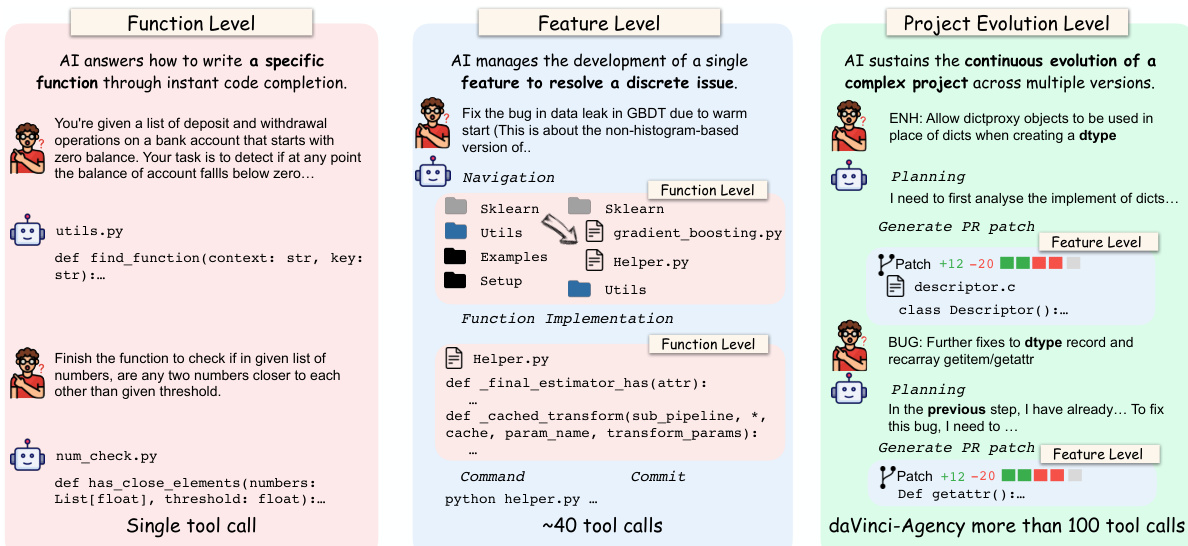
As shown in the figure below, the model operates across three distinct horizons: function level (single tool calls), feature level (~40 tool calls), and project evolution level (100+ tool calls). The project evolution level, which daVinci-Agency targets, demands sustained planning, navigation, and iterative patch generation across multiple PRs, reflecting the complexity of real-world software maintenance. The agent must abstract key logic from patches, synthesize directives that combine intent, location, and implementation strategy, and execute them while preserving state across stages.
During rollout, the agent deploys across multiple scaffolds—SII-CLI and mini-swe-agent—to capture diverse agentic behaviors, logging full trajectories that include observations, reasoning messages, and tool executions. The evaluator provides textual feedback for up to three refinement iterations, enabling the agent to iteratively improve its patch before final submission. This process yields a compact yet high-quality dataset that, despite its small size, enables superior long-horizon performance, as demonstrated by the 148% improvement over baselines trained on orders-of-magnitude larger datasets.
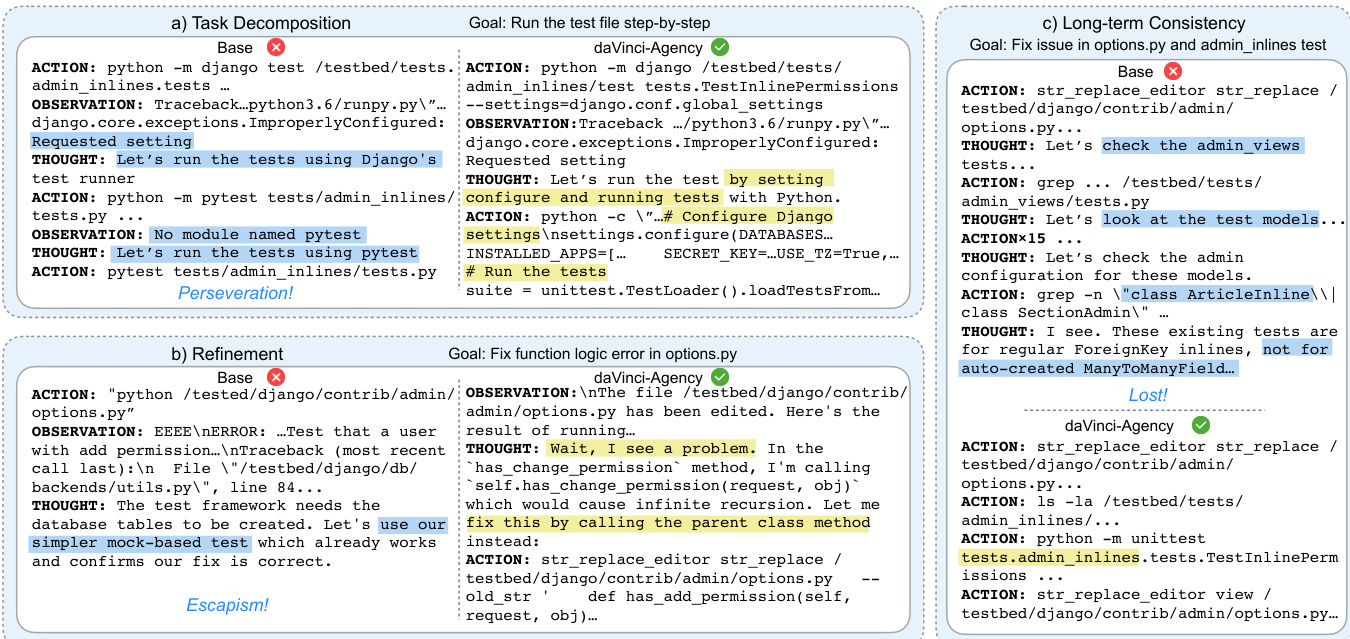
The agent’s reasoning process follows a structured four-step analysis: identifying the core intent, pinpointing the conceptual locus (file paths and variables), abstracting key logic into a vague plan, and synthesizing a directive that guides execution. This ensures that the agent’s actions are not merely reactive but strategically aligned with the evolving context of the PR chain. The resulting trajectories exhibit behaviors such as test configuration, bug detection, and long-term consistency maintenance—capabilities that distinguish daVinci-Agency from base models that often resort to escapism or lose context over extended interactions.
The training data processor further enhances dataset quality through two stages: rejection sampling to discard low-fidelity rollouts and scaling success to amplify high-performing trajectories. This dual-stage filtering ensures that the final training set is both semantically accurate and behaviorally robust, enabling the agent to generalize across complex, multi-stage software evolution tasks.
Experiment
- daVinci-Agency outperforms major open-source baselines across long-horizon agentic benchmarks, particularly excelling in software engineering, tool use, and cross-domain reliability, despite smaller data volume.
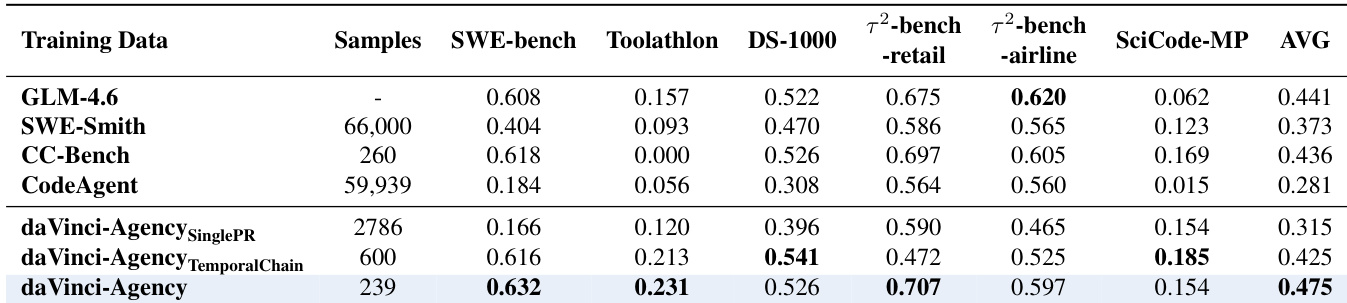
- Ablation studies confirm that modeling real-world PR evolution—especially through semantic dependency chains—is critical for developing long-horizon agency; single-PR or temporal-only sequences yield inferior results.
- The paradigm enables self-distillation: training trajectories generated by GLM-4.6 itself drive performance gains, proving that high-quality data structure—not superior teacher models—unlocks latent agentic capabilities.
- daVinci-Agency generalizes effectively across model architectures (MoE and dense) and scales, improving performance even on smaller models like Qwen3-8B.
- Models trained on daVinci-Agency exhibit emergent meta-skills: structured task decomposition, self-correction, and goal preservation, contrasting with baseline models’ goal drift and escapism.
- Efficiency gains are substantial: reduced token and tool usage indicate higher reasoning density and better context management, directly enhancing long-horizon performance.
- Extending trajectory length via completed PR chains boosts performance, confirming that longer, semantically coherent sequences are a key scaling dimension for agentic capability.
- Rejection sampling is essential: filtering low-quality trajectories prevents performance collapse and enables meaningful self-improvement through high-fidelity supervision.
The authors use rejection sampling to filter self-generated training trajectories, and results show that this significantly improves model performance across multiple benchmarks compared to using unfiltered data. Without rejection sampling, the model’s average score drops sharply, indicating that low-quality supervision degrades reasoning ability. With rejection sampling, the model not only recovers but exceeds baseline performance, particularly on complex tasks like SciCode-MP, confirming that high-fidelity data is critical for effective self-distillation.

The authors use daVinci-Agency to train models on structured, evolution-based pull request sequences, achieving superior performance across long-horizon benchmarks despite smaller dataset sizes. Results show that modeling semantic dependencies between PRs, rather than chronological order or isolated tasks, is critical for developing robust agentic behaviors. The approach consistently improves performance across model architectures and scales, demonstrating that high-quality, logically structured data alone can unlock advanced long-horizon reasoning without relying on stronger teacher models.
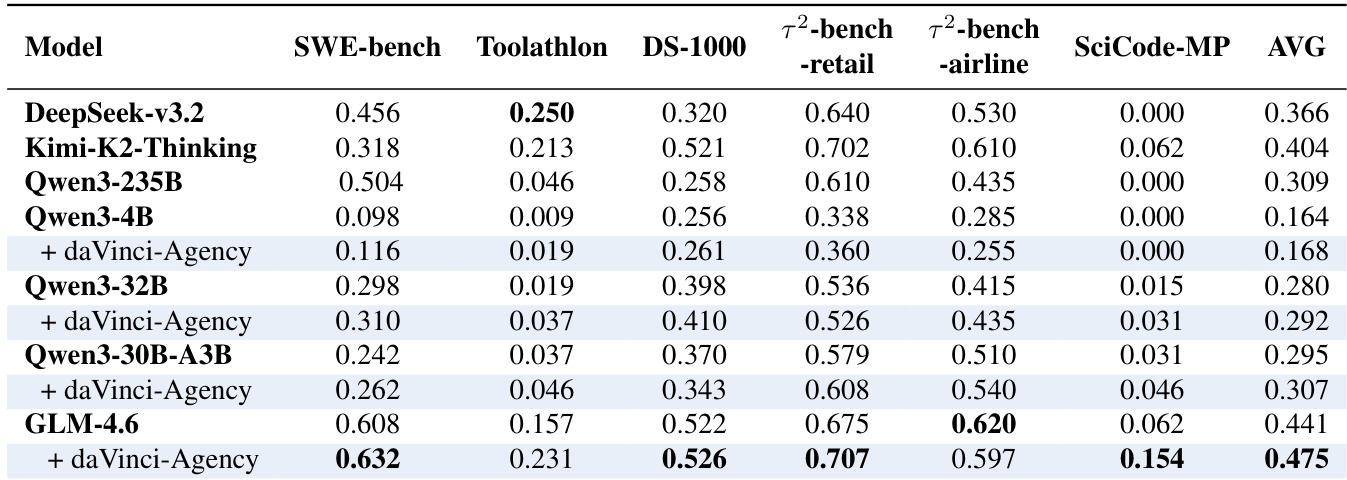
The authors use daVinci-Agency to fine-tune GLM-4.6, resulting in a substantial performance gain on long-horizon agentic tasks as measured by AgencyBench. Results show that the fine-tuned model significantly outperforms both its base version and other large-scale baselines, including DeepSeek-v3.2 and Kimi-K2-Thinking. This improvement is attributed to the structured supervision derived from real-world pull request evolution, rather than reliance on a stronger teacher model or simple data scaling.

The authors use daVinci-Agency to fine-tune multiple model architectures and demonstrate consistent performance gains across long-horizon agentic benchmarks, with GLM-4.6 achieving the highest average score of 0.475. Results show that training on daVinci-Agency improves not only task success rates but also token and tool efficiency, indicating better internalization of structured reasoning and planning. The gains are model-agnostic, observed across dense and MoE architectures, and stem from the dataset’s emphasis on authentic, evolution-based supervision rather than mere sequence length or teacher model quality.