Command Palette
Search for a command to run...
チェーン・オブ・シンキングにおけるグローバル・プランの不在:LLMの潜在的計画ホライズンの解明
チェーン・オブ・シンキングにおけるグローバル・プランの不在:LLMの潜在的計画ホライズンの解明
Liyan Xu Mo Yu Fandong Meng Jie Zhou
概要
本研究は、Chain-of-Thought(CoT)の動態に関する先行研究における補完的観察に由来する。すなわち、大規模言語モデル(LLMs)はCoTの出現以前に、後の推論を潜在的に計画していることが示されており、その結果、明示的なCoTの重要性が相対的に低下する一方で、複数ステップにわたる推論を要するタスクにおいてはCoTが依然として不可欠である。LLMの内部状態とその言語化された推論経路の関係をより深く理解するため、本研究では、多様なタスク領域にわたる隠れ状態に対して、我々が提案する探査手法「Tele-Lens」を適用し、LLMの潜在的計画の強度を検証した。実証結果から、LLMはグローバルな計画を精密に行うのではなく、主に逐次的な遷移に特徴づけられる「短視眼的視野(myopic horizon)」を持つことが明らかになった。この特徴を活用して、CoTにおける不確実性推定の向上に関する仮説を提示し、実証的に「CoTの一部の特定位置の小さなサブセット」が、全体の推論経路の不確実性を効果的に代表できることを確認した。さらに、CoTの動態を活用する意義を強調し、性能の低下を伴わずとも自動的にCoTの回避(bypass)を認識可能であることを示した。本研究のコード、データおよびモデルは、https://github.com/lxucs/tele-lens にて公開されている。
One-sentence Summary
Liyan Xu et al. from Tsinghua University propose Tele-Lens to probe LLMs’ latent planning, revealing myopic reasoning; they show sparse CoT positions suffice for uncertainty estimation and enable CoT bypass without performance loss, advancing efficient reasoning in multi-step tasks.
Key Contributions
- We introduce Tele-Lens, a probing method that analyzes LLM hidden states across 12 diverse datasets to reveal that models exhibit a myopic planning horizon, favoring local transitions over global reasoning plans, especially in complex multi-step tasks.
- Leveraging this myopic behavior, we propose and validate the “Wooden Barrel” hypothesis: uncertainty in CoT reasoning is best captured by a small subset of pivot positions, achieving up to 6% improvement in uncertainty estimation without full-path computation.
- We demonstrate that CoT bypass—automatically skipping unnecessary reasoning steps—can be reliably detected and applied without degrading performance, highlighting the practical value of modeling CoT dynamics for efficiency and calibration.
Introduction
The authors leverage probing techniques to investigate whether large language models (LLMs) internally plan entire reasoning chains before generating Chain-of-Thought (CoT) outputs — a key question given CoT’s role in enabling complex, multi-step reasoning. Prior work presents conflicting views: some suggest early hidden states encode future reasoning paths, while others argue CoT remains essential due to architectural limits of Transformers. The authors introduce Tele-Lens, a low-rank adapter that probes hidden states across 12 diverse tasks, revealing that LLMs exhibit a myopic planning horizon — they primarily support local transitions rather than global plans, except for simple tasks where early states hint at coarse answer gists. Building on this, they propose and validate two applications: a “Wooden Barrel” hypothesis for uncertainty estimation (focusing on pivot CoT positions improves accuracy by up to 6%) and a method to automatically bypass CoT when unnecessary, achieving 16.2% bypass rate with negligible performance loss.
Dataset

The authors use a diverse, multi-task dataset spanning 12 tasks grouped into three categories: Explicit Compositional, Implicit Compositional, and Knowledge and Semantic Tasks.
-
Explicit Compositional Tasks (3 tasks, synthetically generated):
- Parity: Random digit sequences (length 5–100), target digit from {1,2,7,8}, label = parity of count.
- Cycle: Random edge lists (4–100 edges), generates single or dual cycles, labels based on path existence between two randomly selected vertices.
- Subsum: Random integer lists (length 2–50, values 1–9), label = least significant digit of max subsequence sum via DP.
- All three tasks are fully controllable, with balanced label distributions.
-
Implicit Compositional Tasks (5 tasks, adapted from existing datasets):
- Math: GSM8K, MATH, AIME — originally free-form; converted to multiple-choice using GPT-4.1 to generate 4 distractors per problem.
- Logic: MuSR, Zebra — natural language reasoning tasks with soft or symbolic constraints.
- MATH uses the MATH-500 test split; AIME’25 includes all 30 problems in test set only.
-
Knowledge and Semantic Tasks (4 tasks, sampled from existing benchmarks):
- CSQA, MMLU, QuALITY, GPQA — focus on knowledge retrieval and semantic understanding.
- QuALITY uses RAG-style snippets (max 2K context) for efficiency.
- All multiple-choice tasks have answer options shuffled to reduce positional bias.
-
Dataset Splits and Processing:
- Each task has up to 4K train / 100 dev / 500 test problems.
- Train/dev splits for non-synthetic tasks sample from original test sets; if insufficient, draw from train/dev sets.
- Final answer probing uses a fixed 20-token label set: {A–E, F, YES, NO, even, odd, 0–9}.
-
Model Use and Metadata:
- Used to train Tele-Lens adapters per Transformer layer (rank 256) for ~5K steps with early stopping.
- Hidden states collected from CoT rollouts (max length 16,384 for test; 5–10% sampled for train/dev to reduce storage).
- Dataset sizes per layer: Off-the-Shelf LLM — 2.4M train / 81K dev / 11M test hidden states; In-Domain LLM — 2.5M / 57K / 2.7M.
- Labels encode teleological dimensions: next token ID, final answer token, CoT length, etc.
Method
The authors leverage a probing mechanism called Tele-Lens to extract teleological signals from intermediate hidden states of large language models during chain-of-thought (CoT) reasoning. This method extends the Logit Lens paradigm by introducing a low-rank adapter with nonlinearity to transform hidden states into vocabulary-scale predictions while minimizing computational overhead and overfitting. For each token ti in a reasoning trajectory T={t1,t2,..,tn}, the hidden state Hik at layer k is transformed via a bottleneck adapter into Hik, which is then projected through the frozen language model head to yield a probability distribution Pik over the vocabulary V:
Hik=GeLU((Hik+Embk(δ))Ak)BkPik(V∣ti,Ak,Bk,Embk,δ)=Softmax(HikL)Here, Ak∈Rd×r and Bk∈Rr×d are low-rank adapter matrices, and Embk optionally encodes positional offsets δ to predict future tokens. The frozen LM head L∈Rd×∣V∣ ensures alignment with the model’s native output space.
Tele-Lens probes three distinct teleological dimensions per hidden state: subsequent token prediction (using offset-aware embeddings), reasoning length estimation (via a regression head on Hik), and direct final answer prediction (omitting Embk). This enables fine-grained analysis of how internal representations evolve toward task completion.
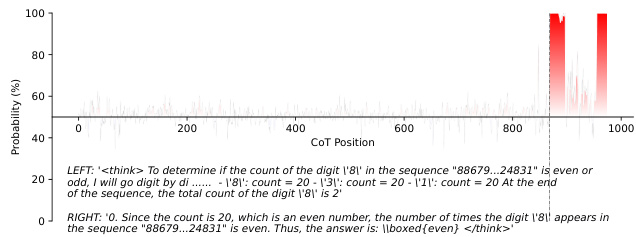
As shown in the figure below, the probability distribution across CoT positions reveals how Tele-Lens identifies critical reasoning steps — for instance, detecting the final count of digit '8' in a sequence and aligning high confidence with the concluding assertion. This illustrates how the method captures not just token-level predictions but also the teleological structure of reasoning.
The framework operates on two types of LLM backbones: off-the-shelf models like Qwen3-32B, which natively support CoT, and in-domain LLMs trained via GRPO reinforcement learning from Qwen2.5-7B-Instruct. The latter provides a controlled environment to study task-specific reasoning dynamics without confounding factors from general-purpose architectures.

Refer to the framework diagram above, which illustrates a CoT trace for a graph pathfinding problem. The model explicitly enumerates edge traversals from source to target vertex, culminating in a binary answer. Tele-Lens can probe each intermediate step — such as the state after step 31 — to predict the final answer or estimate remaining reasoning length, thereby exposing the internal planning structure embedded in the hidden states.
Experiment
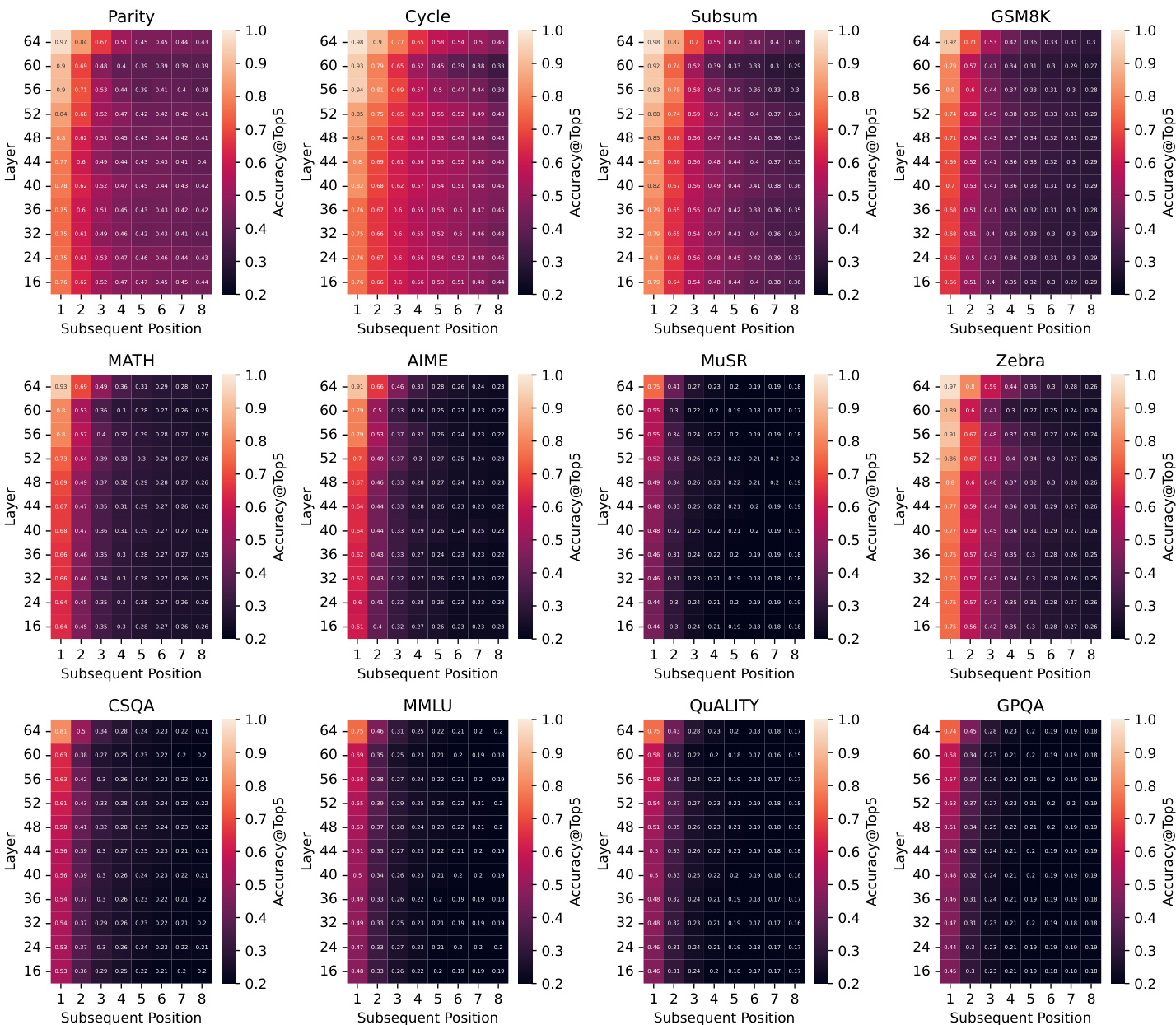
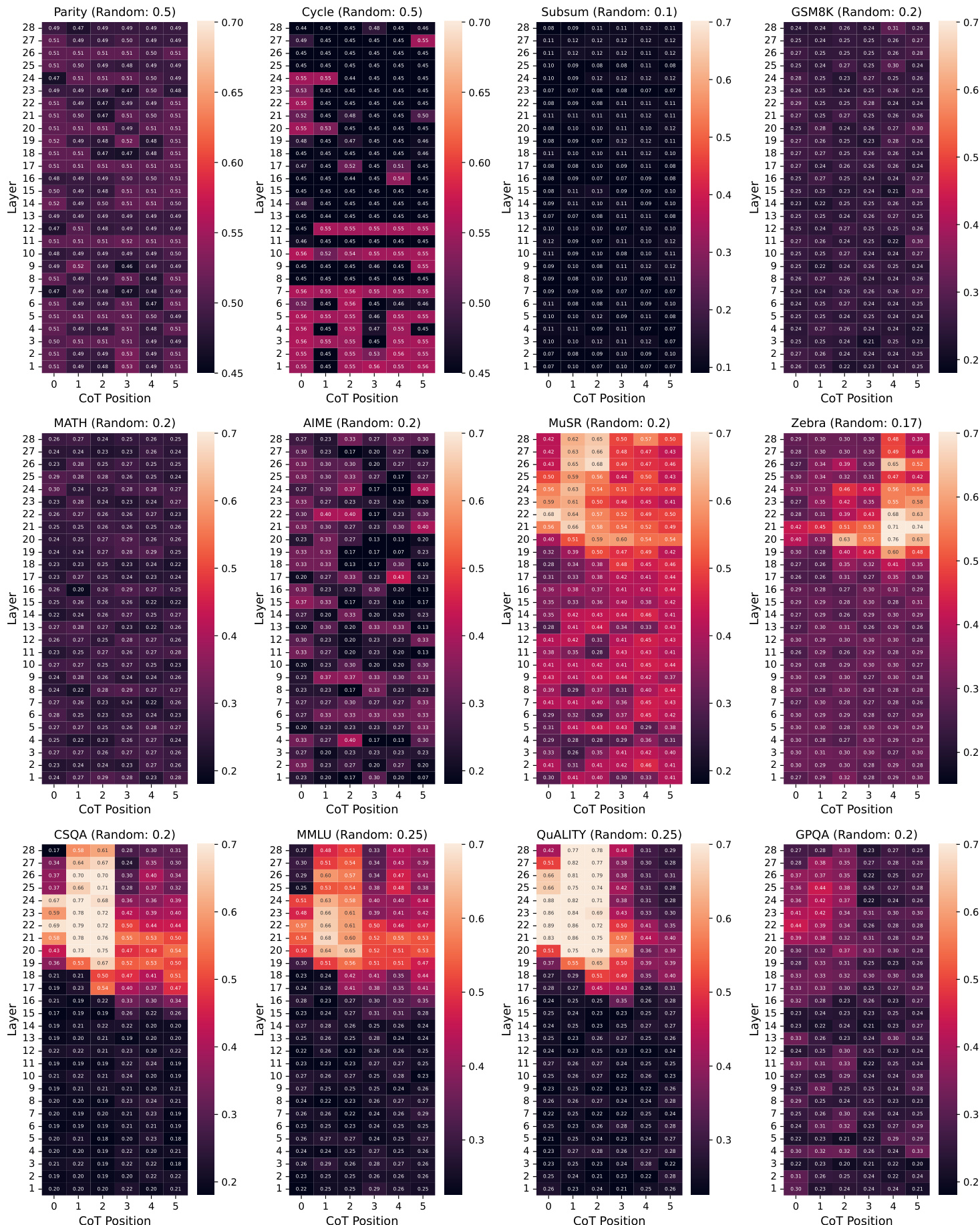
- LLMs exhibit a myopic planning horizon, with precise final-answer planning emerging only near the end of reasoning, not at the start, especially for compositional tasks like Parity and Cycle.
- Early hidden states may show coarse signals hinting at the answer gist, particularly in semantic tasks like CSQA, but these signals reflect vague perception rather than structured planning and yield lower accuracy than direct answering or full CoT.
- LLMs show limited foresight over subsequent reasoning steps, with prediction accuracy declining sharply beyond the next two tokens, except in structurally modular tasks where patterns are discernible.
- Global reasoning length is poorly predicted early in CoT; apparent correlations in some tasks stem from observable input heuristics rather than genuine planning.
- Training an in-domain LLM yields shorter, more decisive CoT trajectories and competitive performance despite smaller scale, validating effective induction of stable reasoning paths.
- Uncertainty in CoT can be better estimated by focusing on a few critical “pivot” tokens rather than averaging across the full trajectory, improving calibration significantly.
- Early CoT signals can identify when CoT is unnecessary, enabling safe bypass for simpler tasks without harming overall accuracy, reducing computational load.
The authors use Tele-Lens to probe LLM hidden states for their ability to predict subsequent tokens along CoT trajectories, revealing that prediction accuracy declines sharply beyond the next one or two steps across most tasks. While structural tasks like Parity and Cycle show slightly more sustained foresight, the overall pattern indicates LLMs lack long-term planning capacity and primarily operate with a myopic horizon. This limited foresight holds across both in-domain and off-the-shelf models, suggesting it is a fundamental characteristic of current LLM reasoning dynamics.
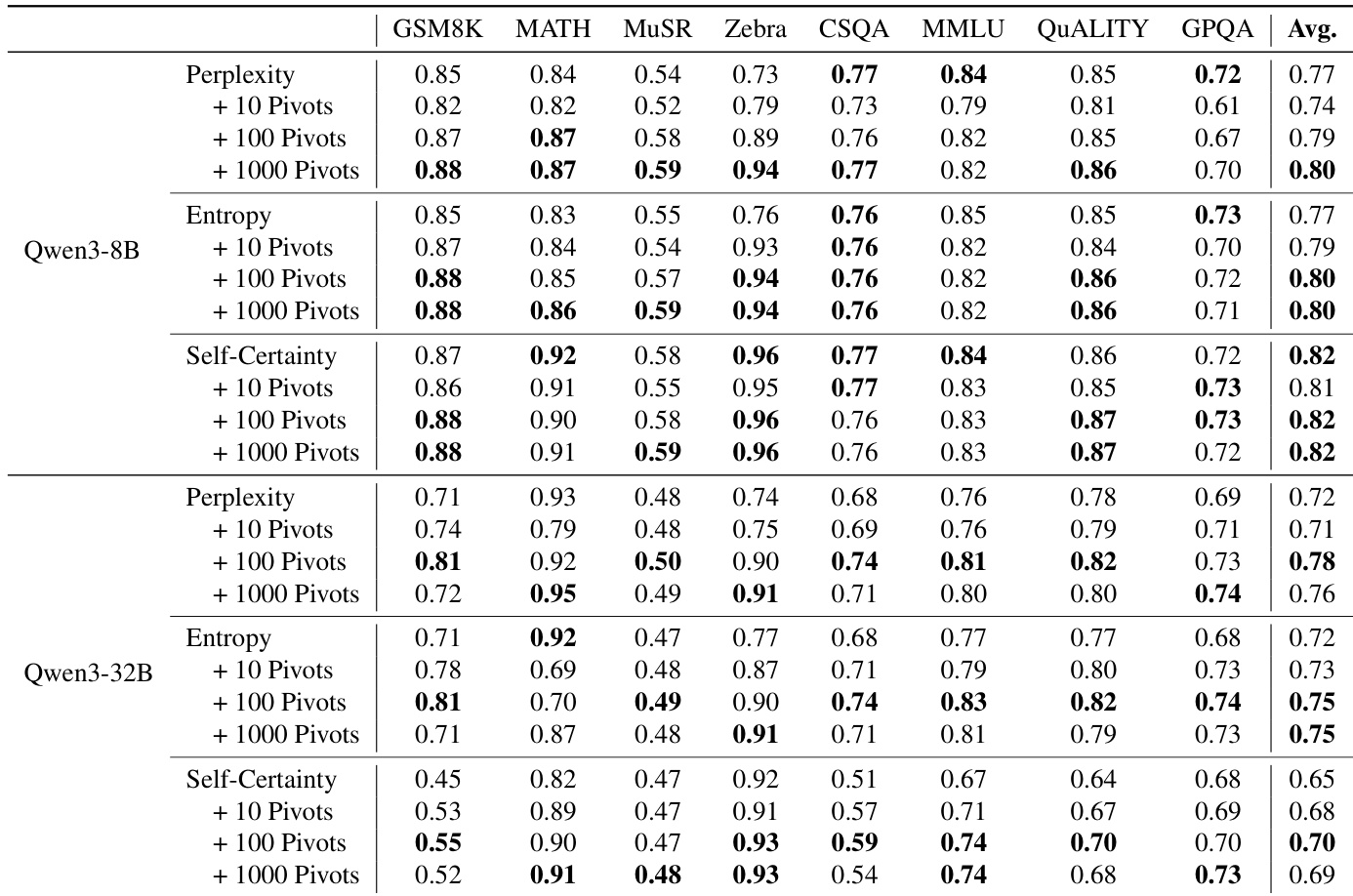
The authors use a top-k pivot selection strategy based on latent signals from CoT trajectories to improve uncertainty estimation, achieving up to 9% absolute AUROC gain over full-path baselines. Results show that focusing on a sparse subset of critical reasoning steps yields more reliable uncertainty metrics than aggregating signals across the entire chain. This approach consistently enhances performance across multiple metrics and model sizes, supporting the hypothesis that reasoning uncertainty is governed by key logical leaps rather than overall token confidence.
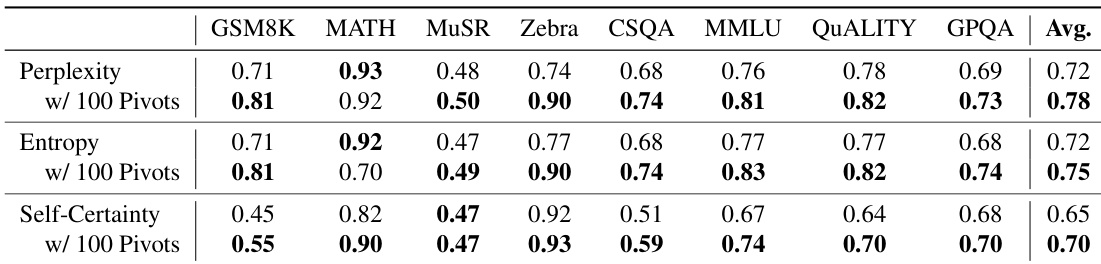
The authors use Tele-Lens to extract latent signals from critical positions in CoT trajectories, finding that focusing on a sparse subset of high-confidence tokens significantly improves uncertainty estimation. Results show that selecting just the top 5 pivot positions yields the best calibration, outperforming both full-trajectory averages and standard metrics like perplexity or entropy. This supports the hypothesis that reasoning uncertainty is governed by a few decisive steps rather than the entire chain.
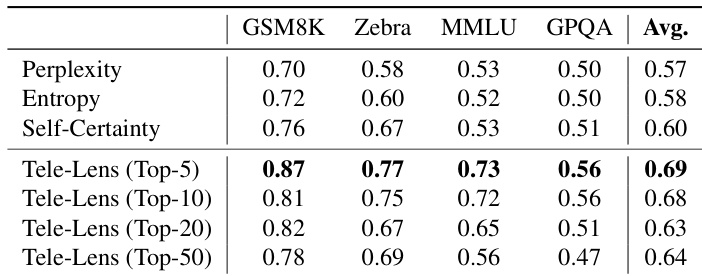
The authors use Tele-Lens to probe latent planning in LLMs by analyzing final-answer prediction accuracy across early CoT positions and transformer layers. Results show that precise final-answer planning is largely absent at the start of reasoning, emerging only near completion for compositional tasks, while semantic tasks may show early but vague predictive signals that do not translate to better task performance. This indicates LLMs operate with a myopic planning horizon, relying on step-by-step exploration rather than global foresight.
The authors use a top-k pivot selection strategy based on internal token-level signals to estimate reasoning uncertainty, finding that focusing on a sparse subset of critical positions significantly improves calibration over full-trajectory averaging. Results show consistent gains across both Qwen3-8B and Qwen3-32B models, with up to 9% absolute improvement in AUROC when using just five pivot tokens. This supports the hypothesis that uncertainty in chain-of-thought reasoning is governed by a few decisive logical steps rather than the entire trajectory.