Command Palette
Search for a command to run...
POPE:専用オンポリシー探索を活用した難問における推論の学習
POPE:専用オンポリシー探索を活用した難問における推論の学習
Yuxiao Qu Amrith Setlur Virginia Smith Ruslan Salakhutdinov Aviral Kumar
概要
強化学習(RL)は大規模言語モデル(LLM)の推論能力を向上させてきたが、最新の手法でも多くの学習問題に対しては学習が困難である。困難な問題においては、オンポリシーRLはたとえ一つの正しいロールアウトさえも探索することが稀であり、結果として報酬がゼロとなり、改善を促す学習信号が得られない。我々は、古典的RLにおけるこの探索問題に対する自然な解決策、たとえばエントロピー報酬、重要度比のより緩いクリッピング、またはpass@kの直接最適化などは、この問題を解消せず、むしろ最適化を不安定化させながらも解法可能性を向上させないことを発見した。自然な代替案として、容易な問題からの転移を利用することを考えるが、我々はRL学習中に容易な問題と困難な問題を混合すると、光線干渉(ray interference)という現象により逆効果になることを示した。これは、最適化が既に解ける問題に集中することで、より困難な問題に対する進展を意図的に阻害する現象である。この課題に対処するため、我々は「特権的オンポリシー探索(Privileged On-Policy Exploration: POPE)」を提案する。POPEは、オラクル(人間や他の知能)の解法を特権情報として用い、困難な問題における探索を導く。これは、オラクル解法を学習目標とする従来の手法(例:オフポリシーRLやSFTからのウォームスタート)とは異なり、導入された解法を「指導」の一部として活用する。POPEは困難な問題にオラクル解法のプレフィックスを付加することで、ガイド付きロールアウトにおいて非ゼロの報酬を得られるようにする。重要な点は、このように得られた行動が、指示追随性と推論能力の相互作用を通じて、元のガイドなしの問題に再び転移されることである。実証的に、POPEは解ける問題の範囲を拡大し、困難な推論ベンチマークにおける性能を顕著に向上させることを示した。
One-sentence Summary
Researchers from Carnegie Mellon University propose POPE, a method that uses partial oracle solutions to guide on-policy RL exploration for hard reasoning problems, enabling models to learn from unguided tasks by leveraging instruction-following and backtracking behaviors, without destabilizing optimization or requiring oracle data as training targets.
Key Contributions
- POPE addresses the failure of on-policy RL on hard reasoning problems by using oracle solution prefixes to guide exploration, enabling non-zero reward rollouts without training directly on oracle data as targets.
- Unlike entropy bonuses or mixed easy-hard training—which destabilize optimization or cause ray interference—POPE leverages instruction-following to steer models toward solvable paths, preserving stable training while improving exploration.
- Evaluated on benchmarks like DAPO-MATH-17K, POPE significantly expands the set of solvable problems and boosts performance by enabling transfer from guided to unguided problem solving.
Introduction
The authors leverage reinforcement learning to improve large language models’ reasoning on hard problems, where standard on-policy RL fails because it rarely samples any correct rollout—leaving no learning signal. Prior fixes like entropy bonuses, pass@k optimization, or mixing easy/hard problems don’t help; they either destabilize training or worsen performance due to “ray interference,” where optimization focuses on already-solvable tasks. Their main contribution is Privileged On-Policy Exploration (POPE), which uses short prefixes of human- or oracle-written solutions to guide exploration during RL—without ever training the model to imitate those prefixes. This lets the model sample successful rollouts on hard problems, and the learned behaviors transfer back to unguided settings via instruction-following and backtracking, significantly expanding the set of solvable problems.
Dataset
- The authors use a mix of human-written and model-generated math problem solutions, drawn from two key sources: Omni-MATH (human solutions) and DAPO (solutions generated by gemini-2.5-pro).
- Omni-MATH provides structured problem-solution pairs with step-by-step reasoning, including algebraic expressions and verification steps; examples include problems requiring construction of sets with specific sum properties.
- DAPO contributes model-generated solutions, such as finding the smallest natural number n where n²−n+11 has exactly four prime factors, enabling comparison between human and synthetic reasoning.
- No explicit filtering rules or size metrics are given for either subset in the provided text; the focus is on solution structure and correctness rather than dataset scale.
- The data is used as-is for evaluation or illustration; no training split, mixture ratios, cropping, or metadata construction are mentioned in the excerpt.
- Processing appears minimal: solutions are presented in raw LaTeX and prose form, preserving original formatting and logical flow for direct analysis or comparison.
Method
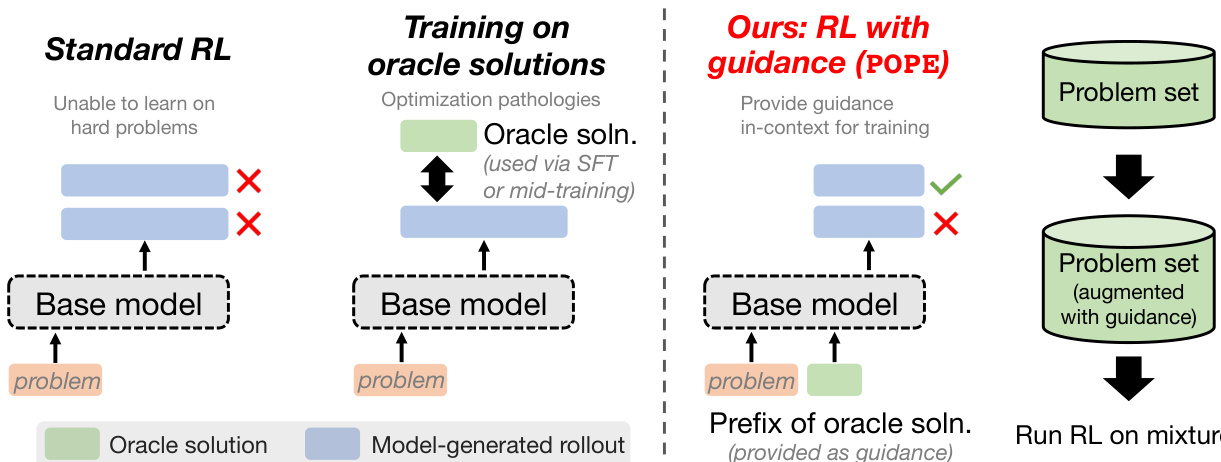
The authors leverage a novel exploration strategy called Privileged On-Policy Exploration (POPE) to address the fundamental limitation of standard on-policy reinforcement learning (RL) on hard problems, where reward signals vanish and training stalls. Rather than treating oracle solutions as direct training targets—which risks memorization or destabilizing the policy—POPE uses them solely as contextual guidance to steer the model’s own on-policy rollouts into regions of the solution space where non-zero reward becomes attainable.
The core mechanism involves augmenting each hard problem with a short, carefully selected prefix from a human-written solution, accompanied by a system instruction that directs the model to build upon this prefix. This guidance does not replace the model’s generative process; instead, it conditions the policy to begin its rollout from a more favorable internal state. The authors identify the minimal prefix length i∗(x) for each problem x by evaluating which prefix enables the base model to produce at least one successful rollout. If no such prefix exists, a short random segment (less than 1/4 of the full solution) is used. The guided dataset is then constructed as:
Dhardguided:={concat(x,z0:i∗(x),I)∣x∈Dhard}.Training proceeds on a 1:1 mixture of unguided hard problems and their guided counterparts, ensuring the model learns to generalize from guided to unguided settings. This approach remains fully on-policy: all rollouts are generated by the current policy, and no off-policy data is used for gradient updates.
Refer to the framework diagram, which contrasts POPE with standard RL and direct oracle training. Standard RL fails on hard problems due to zero advantages when all rollouts are incorrect. Training directly on oracle solutions via SFT or mid-training injection introduces optimization pathologies. POPE, in contrast, provides in-context guidance to enable reward signal without distorting the policy’s generative behavior.
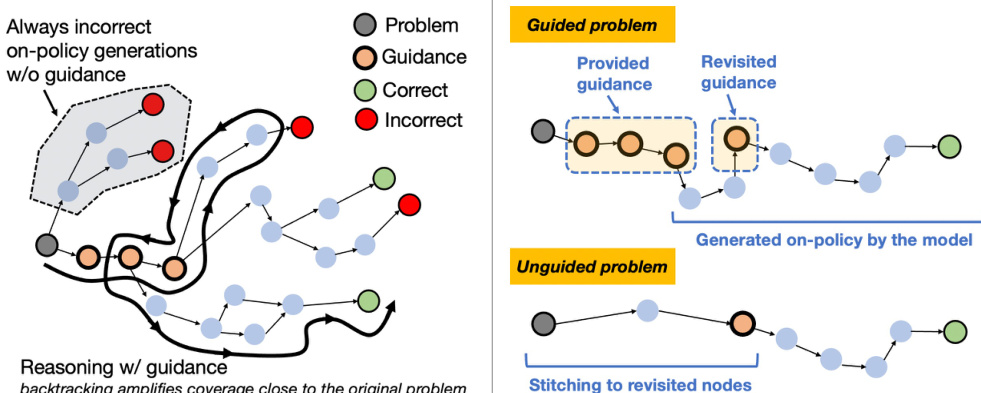
The efficacy of POPE is grounded in a mental model of exploration in an MDP. Hard problems are characterized by sparse reward, where the agent must reach a subset of states Sgood from which reward is reliably attainable. Guidance acts as a roll-in policy that steers the model into Sgood, enabling on-policy RL to learn effective continuations. Once these continuations are learned, the model can succeed from Sgood without guidance, reducing the remaining challenge to reaching such states from the initial problem.
As shown in the figure below, reasoning traces in LLMs often involve self-verification and backtracking, which amplify coverage over states near the initial problem. When these behaviors occur under guidance, they induce overlap between guided and unguided state spaces. This overlap allows the learned policy to generalize from guided successes to unguided prefixes, effectively reducing the exploration problem to reaching any nearby state rather than reproducing the full guidance string.
The training process is implemented using the Pipeline-RL framework with GRPO as the underlying optimizer. Actor workers generate up to 8 rollouts per prompt, which are buffered and processed by preprocessing workers before being used by learner workers for policy updates. The RL loss follows the clipped surrogate objective of GRPO, with advantages normalized by the batch mean to reduce variance. The authors do not include entropy or KL regularization terms by default, focusing instead on the impact of guidance on exploration dynamics.
The authors also explore pass@k optimization as an alternative to standard reward maximization, motivated by the observation that optimizing pass@1 can lead to ray interference—overfitting to easy problems at the expense of hard ones. The pass@k objective maximizes the probability that at least one of k independent rollouts succeeds, estimated via the unbiased estimator:
ρ(n,c,k)=1−(kn)(kn−c),where n is the number of rollouts sampled per prompt, and c is the number of correct rollouts. The gradient is computed as a weighted policy gradient, with weights depending on whether a rollout is correct or incorrect, allowing the model to learn from both successes and near-misses.
In summary, POPE transforms sparse-reward exploration into a two-stage problem: first, reach a state from which reward is attainable (via guidance), then learn to exploit that state (via on-policy RL). The structure of reasoning traces in LLMs, particularly self-correction and backtracking, enables transfer from guided to unguided problems by inducing overlap in the latent state space, making POPE a scalable and effective method for improving performance on hard problems without compromising the model’s generative capabilities.
Experiment
- Token-level exploration methods (entropy bonuses, higher clip ratios) fail on hard problems, causing entropy explosion and no meaningful solvability gains.
- Mixing easy problems with hard ones during training induces ray interference, stalling progress on hard problems despite early gains.
- Direct optimization of pass@k metrics does not aid exploration on hard problems; it reduces reward signals and slows convergence.
- POPE, using guided prefixes, avoids ray interference and enables steady improvement on hard problems, even when mixed with easy problems.
- POPE’s effectiveness relies on overlap between guided and unguided reasoning paths; restricting revisiting guidance weakens transfer to unguided settings.
- POPE outperforms supervised fine-tuning on oracle solutions, which collapse entropy and degrade performance on both hard problems and benchmarks.
- POPE improves downstream performance on standardized benchmarks (AIME2025, HMMT2025), especially on harder ones, while maintaining robustness across heterogeneous training data.
The authors find that standard reinforcement learning and token-level exploration methods fail to solve hard problems due to entropy explosion and ray interference, while supervised fine-tuning on oracle solutions degrades performance by collapsing token entropy. In contrast, POPE—a method using guided prefixes—consistently improves solvability on hard problems, mitigates interference from easy problems, and enhances performance on standardized benchmarks even in mixed training settings.