Command Palette
Search for a command to run...
Reasoning SFTにおける汎化性能の再考:Optimization、Data、およびModel Capabilityに関する条件付き解析
Reasoning SFTにおける汎化性能の再考:Optimization、Data、およびModel Capabilityに関する条件付き解析
概要
ご指定いただいた条件に基づき、提供された英文を日本語に翻訳いたしました。LLMのポストトレーニング(post-training)における主流な見解として、「supervised finetuning (SFT) は記憶(memorization)を促進し、reinforcement learning (RL) は汎化(generalization)を促進する」というものがあります。本研究では、長いchain-of-thought (CoT) による教師あり学習を用いた推論型SFTにおいて、この主張を再検証しました。その結果、クロスドメインの汎化能力は欠如しているわけではなく、最適化のダイナミクス、学習データ、およびベースモデルの能力によって共同で形成される「条件付き」のものであることが明らかになりました。報告されている失敗例のいくつかは、最適化不足(under-optimization)に起因するアーティファクト(artifacts)です。具体的には、クロスドメインの性能は、学習時間の延長に伴い、一度低下してから回復・向上するという「ディップ・アンド・リカバリー(dip-and-recovery)」のパターンを示します。そのため、短期間の学習チェックポイントでは、汎化性能を過小評価してしまう可能性があります。また、データの品質と構造の両方が重要です。低品質な解法は汎化性能を広範に低下させますが、検証済みの長いCoTトレースは、一貫したクロスドメインの向上をもたらします。さらに、モデルの能力も不可欠な要素です。強力なモデルは、たとえ単純な算術ゲームであっても、転用可能な手続き的パターン(例:バックトラッキング)を内部化しますが、能力の低いモデルは表面的な冗長性(verbosity)を模倣するに留まります。しかし、この汎化には非対称性が存在します。すなわち、推論能力は向上する一方で、安全性(safety)は低下するという傾向があります。したがって、本研究の問いは「推論型SFTは汎化するか否か」ではなく、「どのような条件下で、どのようなコストを払って汎化するのか」へと再定義されるべきです。
One-sentence Summary
By conducting a conditional analysis of reasoning supervised fine-tuning (SFT) with long chain-of-thought supervision, this study challenges the belief that SFT lacks generalization, demonstrating instead that cross-domain performance is shaped by optimization dynamics, data quality, and base-model capability while revealing an asymmetric trade-off where reasoning improves at the cost of safety.
Key Contributions
- The paper identifies a dip-and-recovery pattern in cross-domain generalization, demonstrating that short-training checkpoints can lead to an underestimation of the generalization capabilities achieved through extended optimization.
- This research establishes that generalization is driven by the interaction of data quality and model capability, showing that verified long-chain-of-thought traces and stronger base models facilitate the internalization of transferable procedural patterns.
- The study reveals an asymmetric relationship between reasoning and safety, finding that improvements in reasoning performance through supervised fine-tuning are consistently accompanied by a degradation in model safety.
Introduction
In the field of Large Language Model (LLM) post-training, a common consensus suggests that supervised fine-tuning (SFT) primarily leads to memorization, while reinforcement learning (RL) is required for true generalization. This distinction is critical for developing models capable of complex reasoning across diverse domains. However, prior research often relies on short training durations, low-quality datasets, or smaller base models, which may lead to the mistaken conclusion that SFT is inherently incapable of cross-domain transfer.
The authors challenge this narrative by demonstrating that generalization in reasoning SFT is a conditional property rather than an absent one. Through a systematic analysis, they show that apparent failures in generalization are often artifacts of under-optimization, where performance follows a dip-and-recovery pattern during training. The authors leverage a controlled experimental setup to reveal that successful generalization depends on three key factors: sufficient optimization, high-quality long chain-of-thought data, and strong base-model capability. Furthermore, they identify an asymmetric trade-off where improved reasoning capabilities through SFT can lead to a degradation in model safety.
Dataset
The authors utilize several specialized datasets to train and evaluate their models, focusing primarily on mathematical reasoning and safety alignment.
-
Dataset Composition and Subsets
- Math-CoT-20k: The primary training set consisting of 20,480 math reasoning examples. The queries are sampled from the OpenR1-Math-220k subset, while the responses are generated by Qwen3-32B with thinking enabled.
- Math-NoCoT-20k: A derivative of the Math-CoT-20k dataset created by removing the thinking process from the responses.
- Countdown-CoT-20k: Contains 20,000 queries sampled from Countdown-Tasks-3to4-Unique, with responses generated by Qwen3-32B.
- NuminaMath-20k: A subset containing the same queries as the math sets but uses responses sourced from the NuminaMath-1.5 dataset.
-
Data Processing and Filtering
- Response Generation: For the CoT datasets, the authors use Qwen3-32B with a maximum response length of 16,384 tokens. Generation parameters are set to temperature 0.6, top-p 0.95, top-k 20, and min-p 0.
- Verification and Selection: The authors generate multiple responses per query and apply math-verify to ensure accuracy. Only responses with correct answers are retained. If multiple correct responses are available for a single query, one is selected at random.
-
Evaluation and Metadata Construction
- Reward Modeling: The authors use specific prompt formats for different evaluation tasks, such as the IFEval format for instruction following and specialized prompts for TruthfulQA to judge truthfulness and helpfulness.
- Safety Alignment: To evaluate policy adherence, the authors use a structured scoring system (1 to 5) based on Meta's usage guidelines. This process involves a step-by-step analysis of user intent, model response alignment, and the presence of prohibited content.
Method
The authors leverage a framework designed to evaluate and improve the reasoning and factual consistency of large language models across diverse tasks. The overall architecture consists of three primary components: optimization dynamics, training data curation, and model capability assessment, each addressing different aspects of model behavior and performance.
Refer to the framework diagram
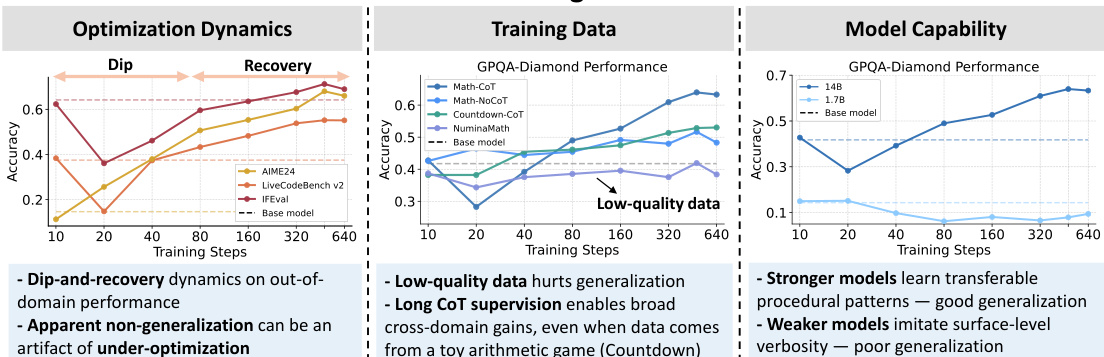
The training data panel evaluates the impact of data quality on model performance. It shows that low-quality data significantly harms generalization, particularly for models trained on such datasets. In contrast, long-chain-of-thought (CoT) supervision enables broad cross-domain generalization, even when data originates from a toy arithmetic game like Countdown. This demonstrates that the quality and structure of training signals are critical for achieving robust performance across domains.
The model capability panel assesses how different model sizes affect performance on the GPQA-Diamond benchmark. Larger models exhibit stronger learning of transferable procedural patterns, leading to good generalization, while weaker models tend to imitate surface-level verbosity, resulting in poor generalization. This suggests that model capacity plays a crucial role in the ability to extract and apply meaningful reasoning patterns from training data.
The framework also incorporates task-specific templates for generating evaluation data. For instance, the GPQA Diamond generation template is used to create multi-choice reasoning problems that require step-by-step explanations. Similarly, the HaluEval templates are designed to detect hallucinations in QA, dialogue, and summarization contexts by comparing model outputs against known facts. These templates ensure that evaluations are standardized and focused on specific aspects of model behavior, such as factual accuracy and reasoning coherence.
The authors further demonstrate the model's behavior through examples. As shown in the figure below:
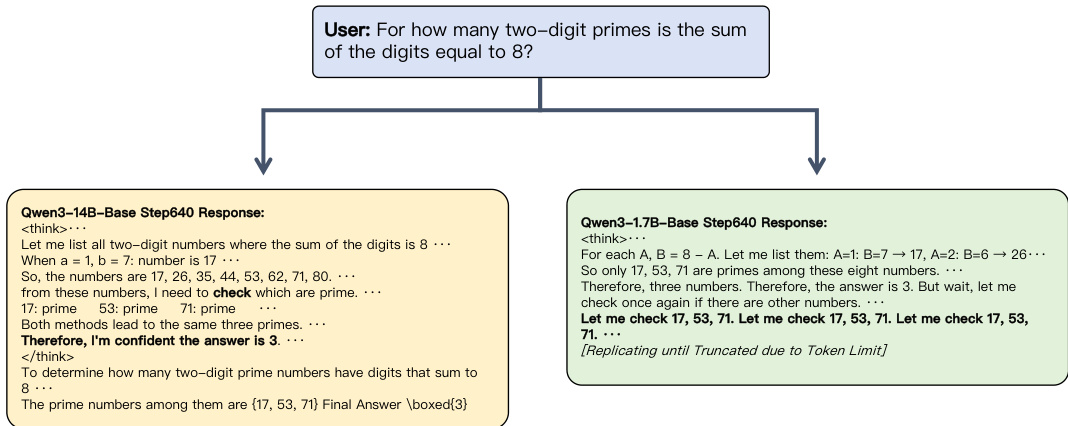
Another example illustrates the model's ability to handle factual and procedural knowledge in dialogue. As shown in the figure below:
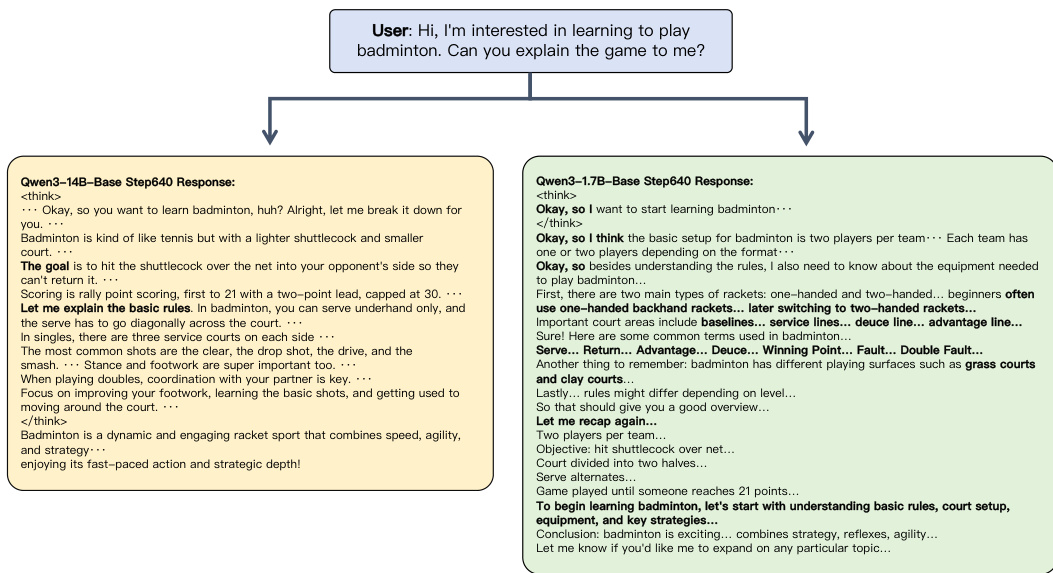
These examples underscore the importance of model scale and training data quality in enabling accurate reasoning and factual consistency. The framework allows for systematic evaluation of these factors, providing insights into the strengths and limitations of different model architectures and training approaches.
Experiment
The experiments evaluate the impact of optimization, data quality, and model scale on the generalization of long-Chain-of-Thought (CoT) reasoning SFT. By testing various base models and training schedules across in-domain math and out-of-domain reasoning tasks, the study reveals that perceived limits in generalization are often artifacts of under-optimization rather than intrinsic flaws. Findings suggest that successful cross-domain transfer requires a combination of high-quality procedural data, sufficient training epochs, and higher base-model capability to move beyond shallow pattern imitation toward internalized reasoning.
The authors examine the training dynamics of reasoning SFT, observing a dip-and-recovery pattern in benchmark performance and a corresponding rise and fall in response length. This indicates that extended training is necessary for models to move beyond surface-level imitation and achieve better cross-domain generalization, with larger models showing stronger and more efficient learning. Performance shows a dip-and-recovery pattern across benchmarks, with in-domain and out-of-domain tasks improving after initial degradation. Response length increases early in training and then decreases, serving as a diagnostic of optimization progress. Larger models achieve better generalization and converge faster, while smaller models remain in a prolonged response phase.
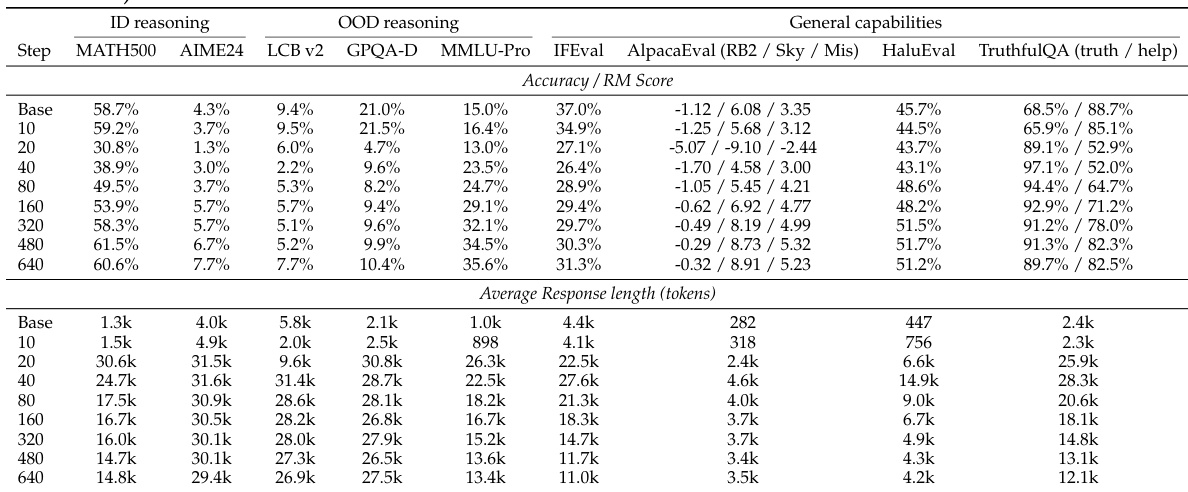
The authors use a long-CoT reasoning SFT setup to train models on math reasoning data, observing a dip-and-recovery performance pattern across benchmarks. Response length initially increases and then decreases, serving as a diagnostic of optimization progress. Larger models show better generalization and more efficient learning compared to smaller ones. Performance initially dips before recovering on both in-domain and out-of-domain tasks after extended training. Response length rises early in training and then declines, indicating a shift from surface imitation to deeper reasoning. Larger models achieve better generalization and stabilize at shorter response lengths compared to smaller models.
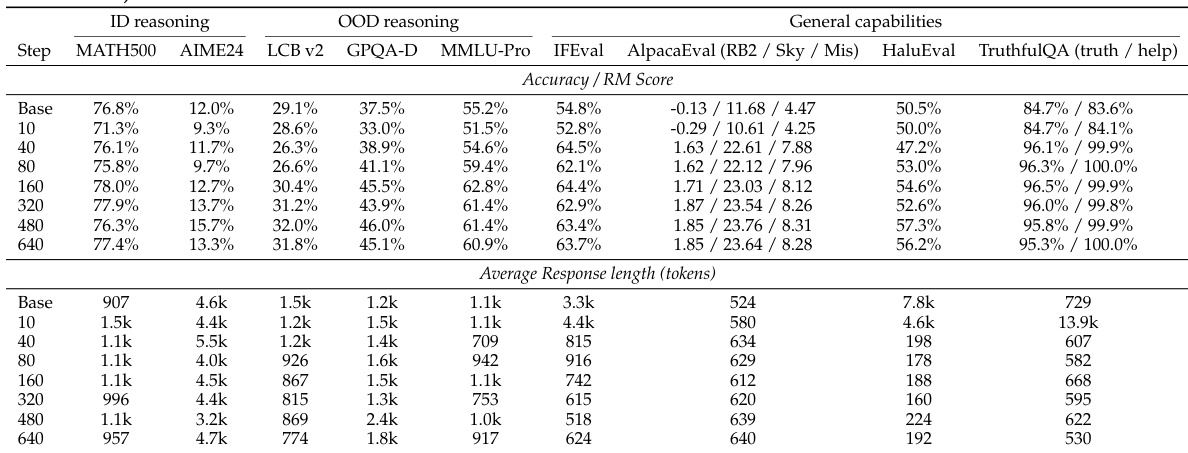
The experiment tracks model performance and response length over training steps, showing a dip-and-recovery pattern on most benchmarks. Performance initially declines before improving, while response length increases early and then decreases, indicating optimization progress. Performance shows a dip-and-recovery pattern across benchmarks during training. Response length increases initially and then decreases, correlating with performance changes. Larger models achieve better generalization and shorter response lengths compared to smaller models.
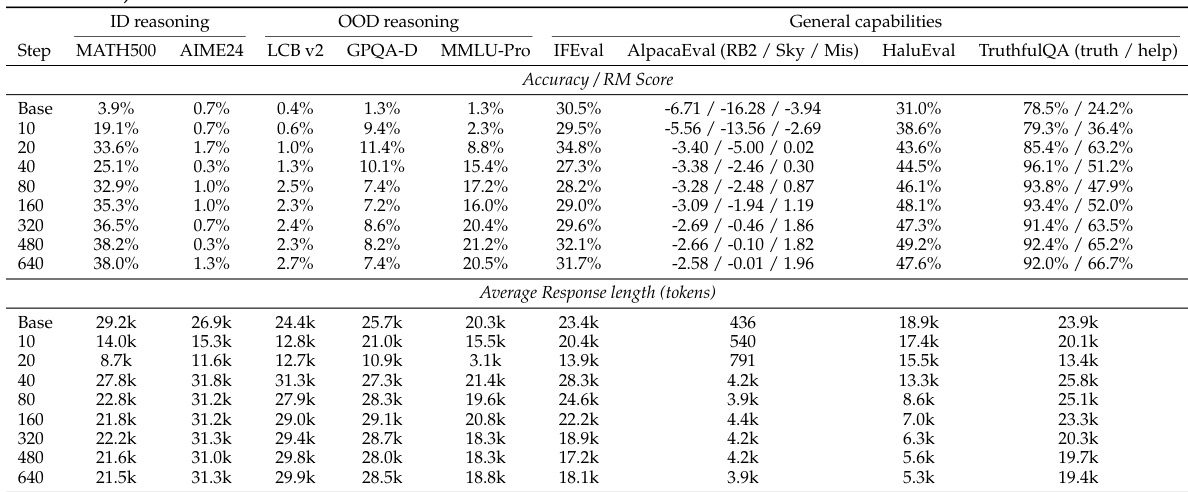
The experiment examines the effects of long-chain-of-thought supervised fine-tuning on model performance and response length across training steps. Results show a dip-and-recovery pattern in benchmark performance and an initial surge followed by a decline in response length, indicating optimization dynamics. These trends are observed across various models and tasks, suggesting that under-optimization may explain previous reports of limited generalization. Performance shows a dip-and-recovery pattern on both in-domain and out-of-domain benchmarks during training. Response length increases early in training and then decreases, correlating with performance changes. The trends are consistent across different models and training data, indicating a general optimization phenomenon.
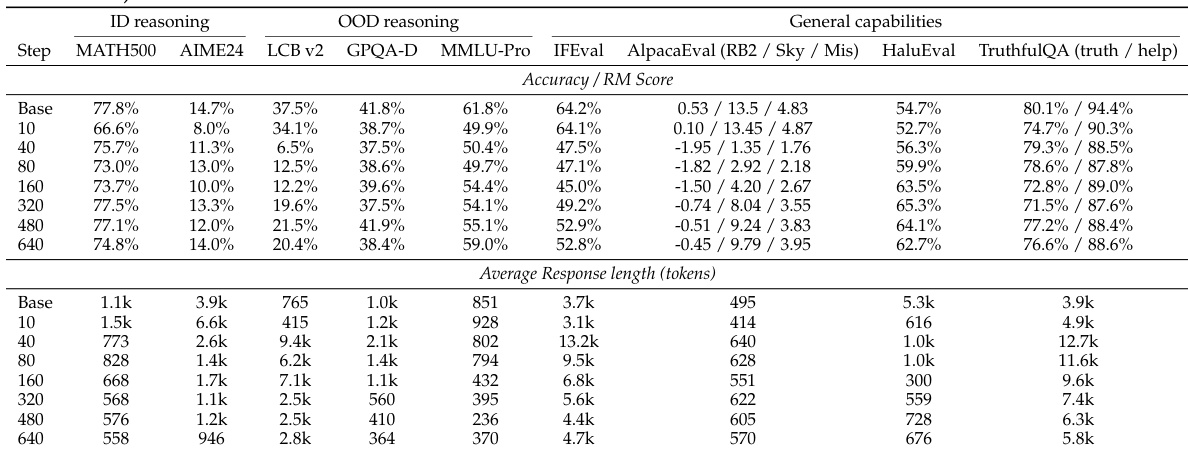
The experiment tracks model performance and response length over training steps, showing a dip-and-recovery pattern across benchmarks. Performance initially declines before improving, while response length increases early and then decreases, indicating optimization dynamics. Larger models show stronger generalization and faster convergence. Performance shows a dip-and-recovery pattern across all benchmarks during training. Response length increases early and then decreases, correlating with performance changes. Larger models exhibit stronger cross-domain generalization and faster response length stabilization.
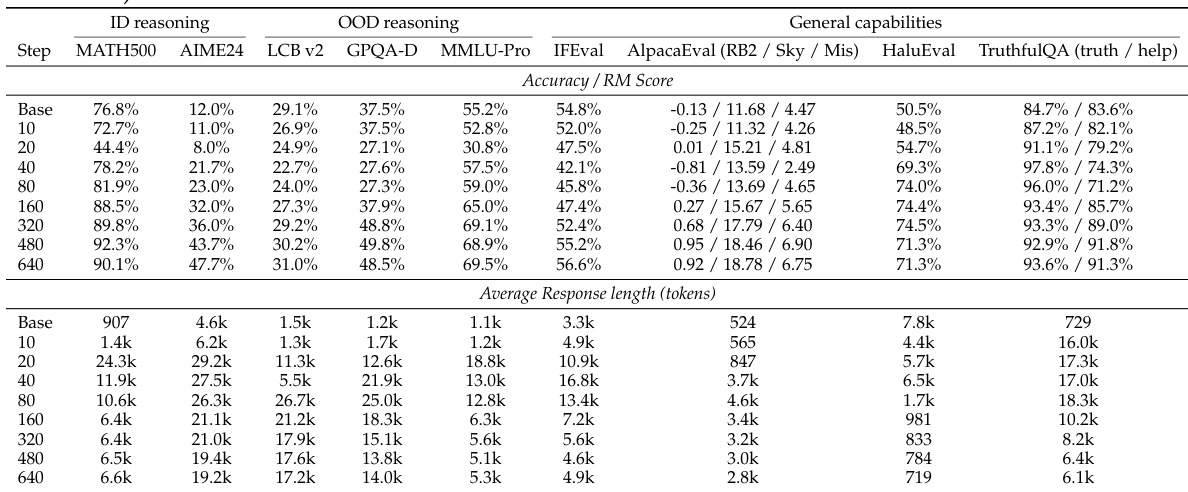
The authors investigate the training dynamics of long-chain-of-thought supervised fine-tuning by tracking benchmark performance and response length across various model scales. The experiments reveal a consistent dip-and-recovery pattern in performance and a corresponding rise and fall in response length, suggesting that extended training is essential for models to transition from surface-level imitation to genuine reasoning. Ultimately, larger models demonstrate superior cross-domain generalization and more efficient optimization compared to smaller models.