Command Palette
Search for a command to run...
ParseBench: AI Agentのためのドキュメント解析ベンチマーク
ParseBench: AI Agentのためのドキュメント解析ベンチマーク
Boyang Zhang Sebastián G. Acosta Preston Carlson Sacha Bron Pierre-Loic Doulcot Daniel B. Ospina Simon Suo
概要
AI Agentの台頭により、ドキュメント解析(document parsing)に求められる要件が変化しています。現在重要視されているのは「意味論的な正確性(semantic correctness)」です。解析された出力は、自律的な意思決定に必要な構造と意味を保持していなければなりません。これには、正確なテーブル構造、精密なチャートデータ、意味的に適切なフォーマット、そしてvisual grounding(視覚的根拠の特定)が含まれます。既存のbenchmarkは、ドキュメントの分布が限定的であることや、Agentにとって致命的な失敗を見逃してしまうテキスト類似度指標に依存していることから、エンタープライズ自動化におけるこうした実態を十分に捉えきれていません。本研究では、保険、金融、行政などのエンタープライズドキュメントから、人間が検証した約2,000ページからなるbenchmark「ParseBench」を導入します。ParseBenchは、「tables(表)」「charts(図表)」「content faithfulness(内容の忠実性)」「semantic formatting(意味論的フォーマット)」「visual grounding」の5つの能力次元に基づいて構成されています。Vision-Language Model、特化型ドキュメントパーサー、およびLlamaParseを含む14の手法を用いて評価を行った結果、能力の分布が断片化していることが明らかになりました。すなわち、5つの次元すべてにおいて一貫して高い性能を示す手法は存在しませんでした。総合スコアでは「LlamaParse Agentic」が84.9%で最高値を記録しましたが、本benchmarkは、現在のシステムにおける依然として残る能力のギャップを浮き彫りにしています。データセットおよび評価用コードは、HuggingFaceとGitHubにて公開されています。
One-sentence Summary
ParseBench evaluates 14 methods spanning vision-language models, specialized document parsers, and LlamaParse across ~2,000 human-verified enterprise pages from insurance, finance, and government using five capability dimensions of tables, charts, content faithfulness, semantic formatting, and visual grounding to prioritize semantic correctness over text-similarity metrics, revealing a fragmented capability landscape where LlamaParse Agentic achieved the highest overall score of 84.9%.
Key Contributions
- The paper introduces ParseBench, a benchmark of approximately 2,000 human-verified pages from enterprise documents organized around five capability dimensions. This resource addresses semantic correctness requirements for autonomous decisions by spanning insurance, finance, and government sectors.
- Experiments across 14 methods spanning vision-language models and specialized parsers reveal a fragmented capability landscape where no method is consistently strong across all dimensions. Results indicate LlamaParse Agentic achieves the highest overall score at 84.9%, highlighting specific capability gaps that remain across current systems.
- The work defines visual grounding as a joint problem over localization, classification, and attribution to ensure extracted claims remain auditable. Dataset and evaluation code are released on HuggingFace and GitHub to facilitate future research in enterprise automation.
Introduction
Visual grounding measures whether a system connects generated document content to the correct region on the page. This metric is essential for agents and human reviewers because extracted claims and tables remain auditable only when traceable to their source region. Parsers can produce readable Markdown while failing to assign words to the correct visual region. The authors evaluate visual grounding as a joint problem over localization, classification, and attribution.
Dataset

- Dataset Composition and Sources
- The authors curate approximately 2,000 human-verified pages from over 1,100 enterprise documents.
- Sources include publicly available insurance filings, financial reports, government documents, and industry publications.
- The collection prioritizes production-level complexity such as merged cells, dense layouts, and multi-element pages.
- Key Details for Each Subset
- Tables: Evaluates structural fidelity including merged cells and hierarchical headers using full HTML ground truth.
- Charts: Covers bar, line, pie, and compound types with annotated data points rather than full tables to handle visual estimation tolerance.
- Content Faithfulness: Measures omissions and hallucinations across 500 sampled PDF documents with Markdown transcriptions.
- Semantic Formatting: Tests preservation of strikethrough, superscript, subscript, and bold text using rule-based binary checks.
- Visual Grounding: Requires precise bounding box localization and content attribution for elements like text, tables, and pictures.
- Data Usage and Evaluation
- The benchmark serves as an evaluation suite rather than a training set for the proposed methods.
- The authors test 14 different methods spanning vision-language models and specialized document parsers.
- Evaluation relies on over 169K test rules and dimension-specific metrics like TableRecordMatch and ChartDataPointMatch.
- Processing and Annotation Strategy
- Cropping: The authors parse entire PDF pages instead of cropped images to preserve surrounding context for tables and charts.
- Annotation Pipeline: A two-pass process generates ground truth where frontier VLMs create initial labels followed by human verification and correction.
- Metadata: The dataset includes layout-level reading order and a common label space to ensure fair cross-model comparison.
- Normalization: Text comparisons strip Markdown formatting and canonicalize Unicode to focus on semantic correctness.
Method
The authors categorize current document parsing approaches into two distinct paradigms: general-purpose vision-language models and specialized document parsers. General-purpose vision-language models, such as GPT and Gemini, are capable of extracting structured content from document images in a single pass. A subset of these models, including Qwen-VL and Dots OCR, are fine-tuned specifically for document transcription, offering competitive quality at a lower cost. These models generalize well across various document types and layouts without requiring task-specific engineering. However, visual grounding remains a weak point for most of these models, although recent iterations show improvement.
In contrast, specialized document parsers utilize a pipeline approach that combines layout detection, OCR, and table recognition modules. Commercial platforms and open-source pipelines like Docling and PaddleOCR fall into this category. These systems excel at layout detection and spatial grounding but often struggle to adapt to diverse document formats beyond their training distribution. They were primarily built for digitization workflows rather than the open-ended understanding required by agents, often lacking support for capabilities like chart data extraction.
Refer to the figure below for a visual breakdown of the key capabilities and challenges in modern document parsing systems.

The figure highlights five critical dimensions: Table Record Match, Charts, Content Faithfulness, Semantic Formatting, and Visual Grounding. These dimensions represent the complex tasks that parsing models must handle, ranging from identifying row and column keys in tables to extracting exact data points from charts and preserving document hierarchy and formatting.
For the specific task of table extraction, precise evaluation is essential. The authors utilize a metric called TableRecordMatch to quantify the alignment between ground truth and predicted records. This metric scores the prediction based on matched cells and accounts for unmatched entries. The calculation is defined as follows:
TableRecordMatch(G,P)=max(∣G∣,∣P∣)∑Per-pair scoring
Refer to the diagram below which illustrates the scoring process for table record matching.

The diagram demonstrates how individual records are compared. For each matched pair of ground truth and prediction records, the system checks for matches in company, revenue, and year-over-year percentage fields. Unmatched records contribute to the denominator but not the numerator, ensuring a rigorous assessment of the model's ability to reconstruct tabular data accurately.
Experiment
The evaluation compares VLMs, specialized parsers, and LlamaParse across five dimensions including tables, charts, content faithfulness, semantic formatting, and visual grounding. Qualitative analysis reveals that VLMs excel at content understanding but often fail at structural layout and visual grounding, while specialized parsers frequently ignore semantically significant formatting cues like strikethrough or superscripts. LlamaParse Agentic distinguishes itself by maintaining high accuracy across all dimensions, particularly in complex tasks like chart data extraction and multi-column linearization, thereby establishing a superior quality-cost frontier for downstream agentic workflows.
The authors present a breakdown of content faithfulness on a multi-column document, separating text correctness from reading order to reveal distinct failure modes. LlamaParse Agentic outperforms all other providers by maintaining perfect reading order while preserving text accuracy. Competing models exhibit specific weaknesses, such as interleaving columns or duplicating content, which disproportionately impact either the order or correctness sub-metrics. LlamaParse Agentic achieves perfect reading order and the highest overall faithfulness score. Haiku 4.5 maintains high text correctness but fails significantly on reading order due to column interleaving. Textract preserves reading order reasonably well but suffers from content duplication that lowers text correctness.
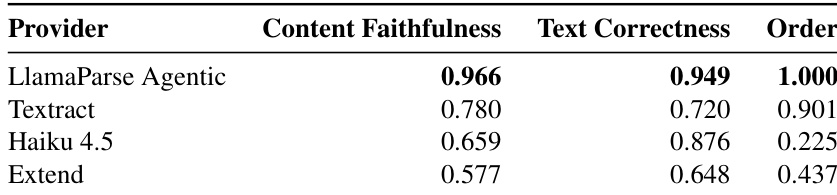
The authors evaluate various document parsing methods, including VLMs and specialized parsers, across multiple capability dimensions. Their proposed LlamaParse system in Agentic configuration achieves the highest overall performance, outperforming leading baselines like Gemini 3 Flash and Reducto. The results highlight that while some models excel in content faithfulness, the proposed system offers superior capabilities in chart parsing and visual grounding. LlamaParse Agentic achieves the highest overall performance, surpassing both proprietary VLMs and specialized document parsers. The system demonstrates particular strength in chart parsing and semantic formatting, areas where many competitors score significantly lower. Layout-aware approaches outperform standard VLMs in visual grounding, which remains a challenge for single-pass models.
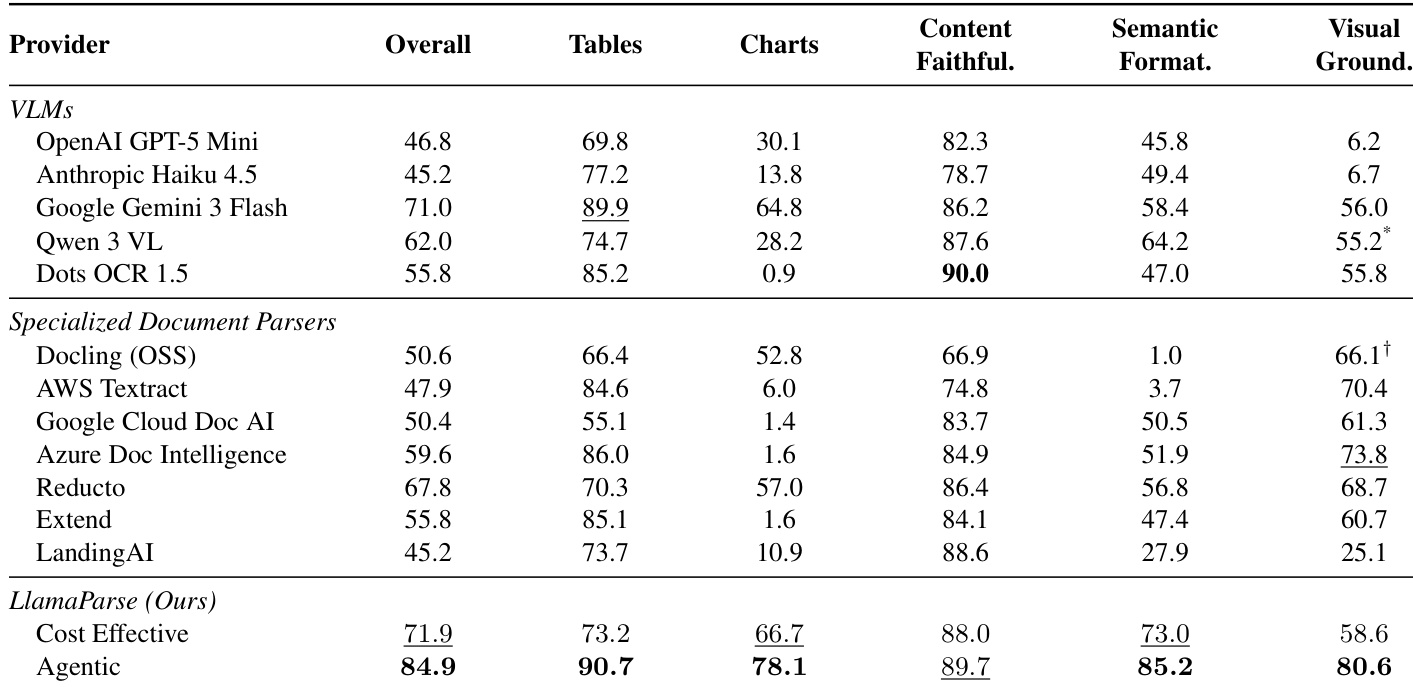
The authors utilize an OECD literacy proficiency chart as a ground truth benchmark to evaluate how well document parsers can extract structured data from complex 3D visualizations. The the the table presents reference values for proficiency changes across multiple countries and educational levels, which parsers must accurately reproduce to pass the evaluation rules. This setup specifically tests the ability to associate numerical values with the correct country and education labels in a dense chart layout. The the the table organizes proficiency changes by country and three distinct educational attainment levels. Columns differentiate between unadjusted and adjusted metrics for upper secondary and tertiary education. The benchmark evaluates parser accuracy against these specific ground truth values for countries like Sweden and Finland.
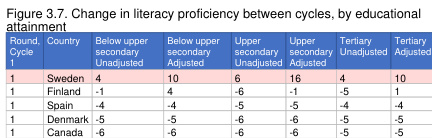
The authors evaluate document parsers on their ability to preserve semantic formatting, such as bold text and heading hierarchy, using a specific infographic example. LlamaParse Agentic outperformed all competitors by maintaining perfect structure and styling, while other models exhibited distinct failure modes like flattening hierarchies or ignoring formatting entirely. LlamaParse Agentic achieved perfect performance across semantic formatting, text styling, and title accuracy. GPT-5 Mini successfully preserved inline text styling but failed to maintain the correct heading hierarchy. Haiku 4.5 and Textract received no credit for text styling due to incorrect syntax usage or a lack of formatting preservation.
The authors evaluate visual grounding performance on a specific corporate annual report page to test the ability to decompose complex layouts into semantic elements. LlamaParse Agentic demonstrates superior capability, achieving high accuracy in localization and perfect attribution, while other providers struggle with granularity. In contrast, models like Haiku 4.5 and LandingAI fail to identify individual elements, producing coarse predictions that do not match the ground truth. LlamaParse Agentic leads the evaluation with near-perfect localization and perfect attribution scores. Gemini 3 Flash detects a portion of the elements but fails significantly on classification and attribution. LandingAI and Haiku 4.5 produce very few predictions that fail to correspond to individual layout elements, resulting in negligible pass rates.

The authors evaluate document parsers across multiple dimensions including content faithfulness, chart parsing, semantic formatting, and visual grounding to assess their ability to handle complex layouts. LlamaParse Agentic consistently achieves the highest overall performance by maintaining perfect reading order and text accuracy while preserving semantic structure and precise visual element localization. Competing models exhibit specific weaknesses such as column interleaving or flattened hierarchies, demonstrating that layout-aware approaches outperform standard VLMs in tasks requiring fine-grained visual understanding.