Command Palette
Search for a command to run...
Audio-Omni:将多模态理解扩展至多功能 Audio Generation 与 Editing
Audio-Omni:将多模态理解扩展至多功能 Audio Generation 与 Editing
概要
マルチモーダルモデルにおける近年の進展は、音声の理解(understanding)、生成(generation)、および編集(editing)の分野に急速な発展をもたらしています。しかし、これらの機能は通常、個別の専門モデルによって扱われており、これら3つのタスクをシームレスに統合できる真に統一されたフレームワークの開発は、未だ十分に探求されていません。一部の先駆的な研究では、音声の理解と生成の統合が試みられていますが、それらは特定のドメインに限定されていることが少なくありません。この課題を解決するため、本研究では Audio-Omni を提案します。これは、一般的な音響、音楽、および音声(speech)のドメインにわたる生成と編集を統合し、さらにマルチモーダルな理解能力を備えた、初のエンドツーエンド(end-to-end)フレームワークです。本アーキテクチャは、高レベルな推論を行うための凍結された(frozen)Multimodal Large Language Modelと、高忠実度な合成を実現する学習可能なDiffusion Transformerを相乗的に組み合わせたものです。音声編集における深刻なデータ不足を克服するため、我々は100万件以上の精緻にキュレーションされた編集ペアを含む新しい大規模データセット、AudioEdit を構築しました。広範な実験の結果、Audio-Omniは一連のbenchmarkにおいて最先端(state-of-the-art)の性能を達成しており、従来の統合型アプローチを凌駕するだけでなく、特定の専門モデルと同等、あるいはそれ以上の性能を実現していることが証明されました。Audio-Omniは、その核心的な能力に加えて、知識拡張型の推論生成(knowledge-augmented reasoning generation)、in-context generation、および音声生成におけるゼロショット(zero-shot)のクロスリンガル制御など、顕著な継承能力を示しており、普遍的な生成音声インテリジェンスに向けた有望な方向性を提示しています。コード、モデル、およびデータセットは、https://zeyuet.github.io/Audio-Omni で公開される予定です。
One-sentence Summary
The authors propose Audio-Omni, the first end-to-end framework to unify audio understanding, generation, and editing across sound, music, and speech domains by synergizing a frozen Multimodal Large Language Model with a trainable Diffusion Transformer and utilizing the new large-scale AudioEdit dataset to achieve state-of-the-art performance and versatile zero-shot control.
Key Contributions
- The paper introduces Audio-Omni, an end-to-end framework that unifies audio understanding, generation, and editing across the sound, music, and speech domains. This architecture combines a frozen Multimodal Large Language Model for high-level reasoning with a trainable Diffusion Transformer and a hybrid conditioning mechanism to separate semantic and signal features.
- This work presents AudioEdit, a large-scale dataset consisting of over one million meticulously curated instruction-guided editing pairs designed to overcome data scarcity in audio editing.
- Experimental results demonstrate that Audio-Omni achieves state-of-the-art performance on multiple benchmarks, matching or exceeding the capabilities of specialized expert models while exhibiting inherited abilities like zero-shot cross-lingual control and knowledge-augmented reasoning.
Introduction
Modern audio processing relies on specialized models for understanding, generation, and editing, which prevents a seamless integration of these tasks. Existing unified approaches often lack end-to-end optimization or are restricted to a single domain like speech or music, while audio editing remains particularly difficult due to a lack of large-scale, instruction-guided datasets. The authors leverage a decoupled architecture that connects a frozen Multimodal Large Language Model for reasoning with a trainable Diffusion Transformer for high-fidelity synthesis. To enable versatile performance, they introduce Audio-Omni, the first end-to-end framework to unify understanding, generation, and editing across general sound, music, and speech, supported by their new large-scale AudioEdit dataset.
Dataset
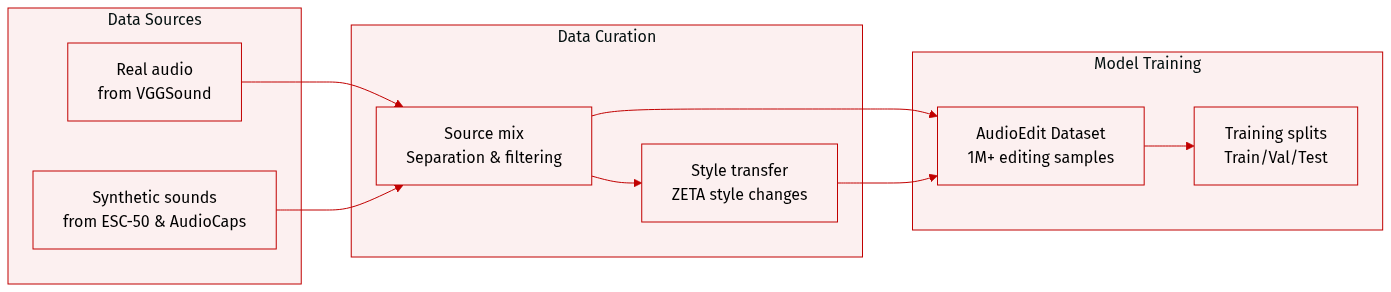
The authors introduce AudioEdit, a large-scale dataset containing over 1 million samples designed for instruction-guided audio editing. The dataset is constructed through a hybrid pipeline consisting of two main branches:
-
Real Data Branch: This branch focuses on acoustic fidelity by mining authentic editing pairs from the VGGSound dataset. The authors use Gemini 2.5 Pro to identify primary sound categories and SAM-Audio for source separation. This process disentangles audio into a target track and a residual track. To ensure high quality, the authors apply a multi-stage filtering process:
- Add, Remove, and Extract tasks: Starting from 540,000 labeled samples, the authors use Voice Activity Detection (VAD) to retain approximately 347,000 pairs, followed by CLAP-based semantic alignment to reach a final set of approximately 50,000 high-quality pairs.
- Style Transfer tasks: The authors expand the filtered targets by using Gemini to generate semantically related keywords. After applying CLAP filtering, they obtain approximately 500,000 pairs. These are processed using ZETA to transform the audio style while preserving pitch and temporal structure, then mixed back with the residual track.
-
Synthesis Data Branch: This branch provides scale and diversity for add, remove, and extract tasks using the Scaper toolkit. The authors programmatically generate soundscapes by mixing foreground events from ESC-50 into 10-second backgrounds from AudioCaps. To increase complexity, they apply randomized parameters including onset time, SNR (0 to 3 dB), pitch shifts (-3 to +3 semitones), and time-stretch factors (0.8 to 1.2).
-
Dataset Usage: The resulting AudioEdit dataset provides a diverse mixture of tasks, including add, remove, extract, and style transfer, to support robust model training with both real-world acoustic characteristics and large-scale synthetic variety.
Method
The authors leverage the Rectified Flow framework as the generative backbone for their Audio-Omni system, which models a deterministic straight-line trajectory between noise and data samples through a constant velocity field. This approach contrasts with traditional diffusion models by using an ordinary differential equation (ODE) defined as dtdxt=v, where v=x1−x0 represents the velocity between a data sample x0 and a noise sample x1∼N(0,I). The solution along this path is given by xt=(1−t)x0+tx1 for t∈[0,1]. A neural network vθ(xt,t,c) is trained to predict this velocity field conditioned on the noisy state xt, time t, and conditioning signals c. During inference, generation proceeds by solving the ODE backward from t=1 using predictions from vθ, with the final output reconstructed via a VAE decoder.
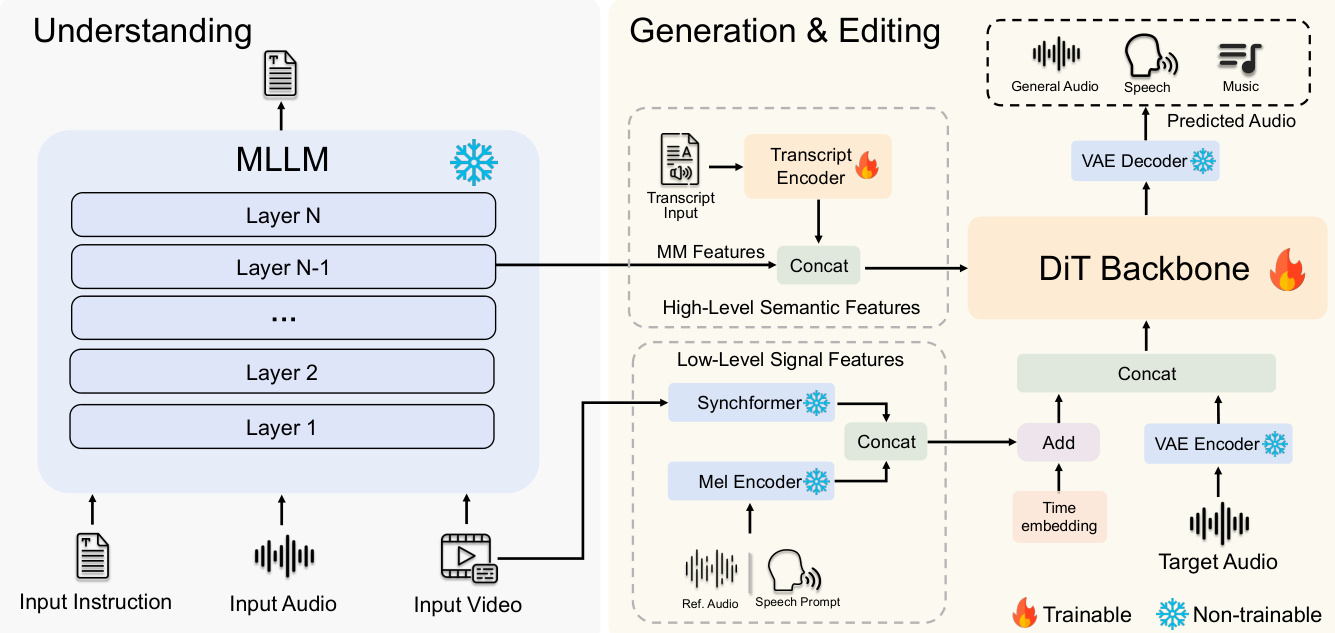
The overall framework consists of two primary components: a frozen multimodal large language model (MLLM) serving as the understanding core and a trainable DiT-based backbone for audio generation and editing. The MLLM processes textual instructions, audio waveforms, and video inputs after they are tokenized by their respective encoders. It performs two key functions: generating textual responses for understanding tasks and producing a multimodal feature representation Fmm∈RLmm×Dmm from its penultimate layer, which serves as a conditioning signal for generative tasks. This feature is combined with a transcript-derived feature Ftrans, obtained from a character-level encoding of the input text using a ConvNeXtV2-based Transcript Encoder, to form the High-Level Semantic Features stream chigh=Concat(Fmm,Ftrans).
For tasks requiring precise temporal alignment, such as editing and synchronization, a second conditioning stream is introduced: the Low-Level Signal Features. This stream is constructed by concatenating a mel-spectrogram feature Fmel, extracted from a reference audio or speech prompt using a Mel Encoder, with a synchronization feature Fsync, derived from the input video via a pre-trained Synchformer model, resulting in clow=Concat(Fsync,Fmel). These two conditioning streams are injected into the DiT backbone through distinct mechanisms. The High-Level Semantic Features are injected as context via cross-attention, enabling the model to attend to abstract instructions throughout the generation process. In contrast, the Low-Level Signal Features are fused with a time embedding through element-wise addition and then concatenated with the VAE-encoded noisy audio latent xt to form the primary input to the DiT, providing strong frame-by-frame guidance.
The training objective is a unified Rectified Flow loss, which minimizes the mean squared error between the predicted velocity vθ(xt,t,c) and the ground-truth velocity v=x1−x0. The loss function is defined as:
L=Et∼U(0,1),x0,x1,c[∣∣vθ(xt,t,c)−(x1−x0)∣∣2]where t is a randomly sampled timestep from a uniform distribution, xt=(1−t)x0+tx1 is the interpolated latent state, and c encompasses the full conditioning signals for the training sample. This objective enables the model to learn a single, unified representation for a wide range of audio generation and editing tasks.
Experiment
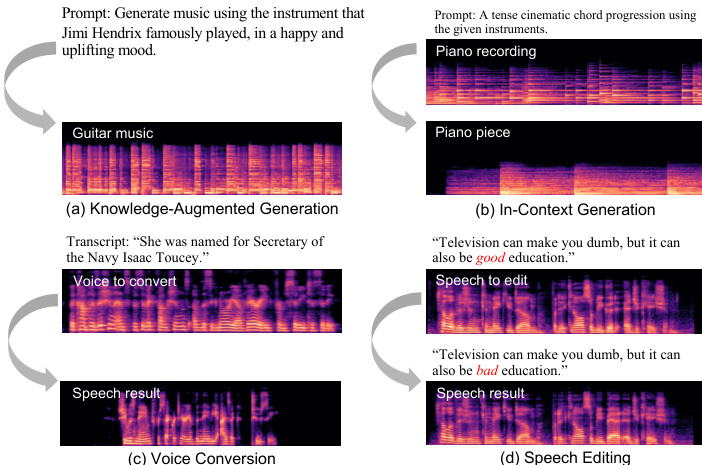
Audio-Omni is evaluated through a comprehensive suite of benchmarks designed to test its understanding, generation, and editing capabilities across the full spectrum of sound, music, and speech. The experiments validate that the decoupled architecture allows the model to inherit strong reasoning and multilingual abilities from a frozen MLLM while achieving state-of-the-art performance in generative and editing tasks. Qualitative results further demonstrate emergent zero-shot capabilities, such as knowledge-augmented generation and voice conversion, proving that a single unified framework can serve as a versatile generalist for diverse audio domains.
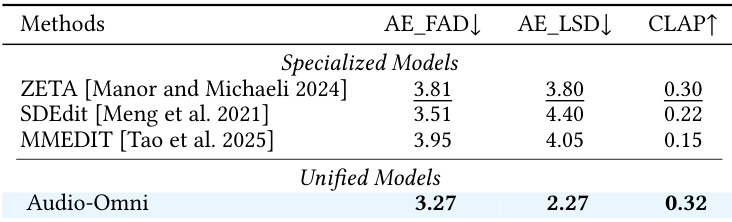
Results show that Audio-Omni achieves superior performance across audio editing metrics compared to specialized models. The model outperforms others in fidelity and instruction adherence, demonstrating strong capabilities in editing tasks. Audio-Omni outperforms specialized models on all editing metrics Audio-Omni achieves the best results in fidelity and instruction adherence The model demonstrates strong performance across multiple editing tasks
The the the table presents an ablation study on the impact of dataset composition for audio editing training, comparing performance across different training configurations. Results show that combining synthetic and real-world data achieves the best overall performance, with the mixed approach outperforming either data type used alone. Combining synthetic and real-world data yields the best performance for audio editing. Training on real-world data alone achieves better results than using synthetic data alone. The mixed data approach consistently outperforms single-data configurations across all evaluation metrics.
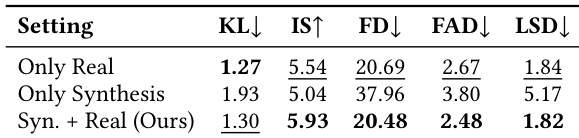
The results show a comparison of audio editing models across multiple tasks, with the proposed method achieving the best overall performance. Audio-Omni demonstrates superior results in both fidelity and quality metrics across all editing operations compared to existing models. Audio-Omni outperforms all baseline models in average performance across editing tasks The proposed method achieves the lowest scores in both FAD and LSD metrics, indicating higher fidelity and quality Audio-Omni shows consistent improvement over baselines in all individual editing operations

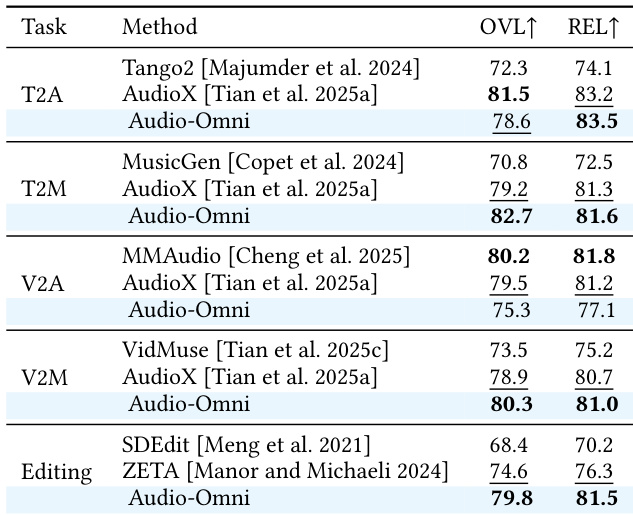
Results show that Audio-Omni achieves strong performance across multiple audio tasks, consistently outperforming other unified models and matching or exceeding specialized models in various benchmarks. The framework demonstrates superior results in both understanding and generation tasks, highlighting its effectiveness as a comprehensive audio system. Audio-Omni surpasses other unified models in understanding and generation tasks The model achieves competitive results compared to specialized expert models It demonstrates strong performance across diverse audio domains including speech, music, and sound
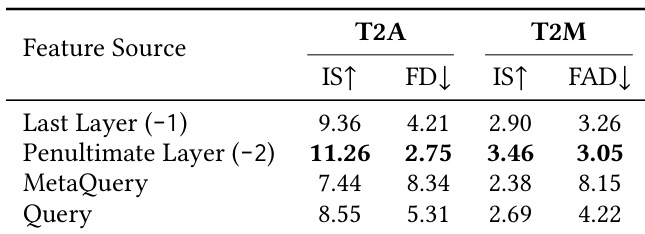
The study compares different feature sources from a frozen MLLM for audio generation tasks, evaluating their impact on text-to-audio and text-to-music performance. Results show that using features from the penultimate layer consistently outperforms other methods across both tasks. Using features from the penultimate layer of the MLLM achieves the best performance for both text-to-audio and text-to-music tasks. The last layer features perform worse than the penultimate layer, indicating over-specialization for text prediction. Complex query mechanisms like MetaQuery and Query degrade performance compared to direct feature extraction from the penultimate layer.
Evaluations demonstrate that Audio-Omni achieves superior fidelity and instruction adherence across diverse audio editing and general tasks, often outperforming both specialized models and existing unified frameworks. Ablation studies reveal that training with a combination of synthetic and real-world data yields the best results, while extracting features from the penultimate layer of a frozen MLLM provides optimal performance for generation tasks. Collectively, these findings highlight the effectiveness of the proposed model and its robust capabilities across speech, music, and sound domains.