Command Palette
Search for a command to run...
BERT-as-a-Judge: 効率的なReference-Based LLM評価における、Lexical Methodに代わるロバストな代替手法
BERT-as-a-Judge: 効率的なReference-Based LLM評価における、Lexical Methodに代わるロバストな代替手法
Hippolyte Gisserot-Boukhlef Nicolas Boizard Emmanuel Malherbe Céline Hudelot Pierre Colombo
概要
ご指定いただいた指示に基づき、提供された英文を技術的に正確かつ自然な日本語に翻訳いたしました。正確な評価は、Large Language Model (LLM) エコシステムの中核をなすものであり、多様なユースケースにおけるモデルの選定やダウンストリームへの導入を導く重要な要素です。しかし、実務においては、生成された出力の評価は、回答を抽出・評価するための厳格な語彙的(lexical)な手法に依存することが一般的です。こうした手法は、モデルの真の課題解決能力と、事前に定義されたフォーマット・ガイドラインへの準拠性を混同させてしまう可能性があります。近年の「LLM-as-a-Judge」アプローチは、厳格な構造的適合性ではなく意味的な正当性を評価することでこの問題を軽減していますが、一方で膨大な計算オーバーヘッドを伴い、評価コストを高大にするという課題があります。本研究では、まず36のモデルと15のダウンストリーム・タスクにわたる大規模な実証研究を通じて、語彙的評価の限界を体系的に調査し、こうした手法が人間の判断と相関が低いことを明らかにします。この限界を克服するために、我々は「BERT-as-a-Judge」を提案します。これは、参照解答(reference)に基づく生成設定において、回答の正当性を評価するためのエンコーダー駆動型アプローチです。この手法は、出力の言い回しの違いに対して堅牢であり、合成的にアノテーションされた「質問・候補回答・参照解答」のトリプレットを用いた軽量なtrainingのみで動作します。実験の結果、提案手法は語彙的なベースラインを一貫して上回るだけでなく、より大規模なLLM judgeの性能にも匹敵することを示しました。これにより、両者の間で極めて優れたトレードオフを実現し、信頼性が高くスケーラブルな評価を可能にします。最後に、広範な実験を通じてBERT-as-a-Judgeの性能に関する詳細な洞察を提供し、実務家への実践的な指針を示すとともに、ダウンストリームでの活用を促進するため、プロジェクトの全アーティファクトを公開します。
One-sentence Summary
To address the poor human correlation of rigid lexical methods and the high computational costs of LLM-as-a-Judge approaches, the authors propose BERT-as-a-Judge, an encoder-driven framework that uses lightweight training on synthetic question-candidate-reference triplets to provide reliable, scalable, and semantically accurate reference-based evaluation for generative models.
Key Contributions
- This work presents a large-scale empirical study involving 36 models and 15 downstream tasks that demonstrates how lexical evaluation methods correlate poorly with human judgments by conflating problem-solving ability with formatting compliance.
- The paper introduces BERT-as-a-Judge, an encoder-driven framework that assesses answer correctness in reference-based generative settings through lightweight training on synthetically annotated question-candidate-reference triplets.
- Experimental results show that the proposed method consistently outperforms lexical baselines and matches the performance of much larger LLM judges while providing a more efficient and scalable computational tradeoff.
Introduction
Accurate evaluation is essential for selecting and deploying large language models (LLMs) across diverse tasks. Current zero-shot evaluation methods often rely on lexical matching or regex-based parsing to compare model outputs against reference answers. However, these approaches frequently conflate a model's core reasoning abilities with its ability to follow strict formatting constraints, leading to underestimated performance. While LLM-as-a-Judge frameworks offer a more semantic alternative, they introduce significant computational overhead and sensitivity to prompt design. The authors introduce BERT-as-a-Judge, an encoder-driven approach that leverages bidirectional attention to assess semantic correctness. This lightweight framework provides a more efficient and reliable alternative that aligns closely with human judgment without the high inference costs of generative judges.
Dataset
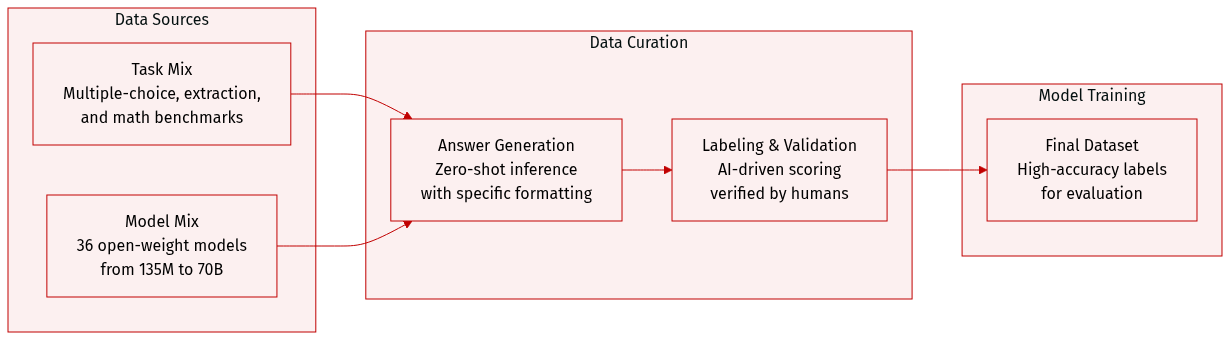
-
Dataset Composition and Sources: The authors construct an evaluation dataset composed of three distinct task families designed for objective assessment:
- Multiple-choice: Includes MMLU, MMLU-Pro, TruthfulQA, ARC-Easy/Challenge, and GPQA.
- Context extraction: Includes SQuAD-v2, HotpotQA, DROP, and CoQA.
- Open-form mathematics: Includes GSM8K, MATH, AsDiv, AIME 24, and AIME 25.
-
Data Processing and Generation:
- The authors perform zero-shot inference across 36 different open-weight instruction-tuned models, ranging in size from 135M to 70B parameters.
- Responses are generated using greedy decoding with a maximum length of 2048 tokens.
- To enable consistent parsing via regular expressions, models are prompted to conclude their outputs using a specific "Final answer: [answer]" format.
-
Labeling and Validation Strategy:
- Synthetic Labeling: The authors use Nemotron-Super-v1.5 as an automated evaluator. This model receives the question, the candidate response, and the reference answer to determine correctness via greedy decoding in non-reasoning mode.
- Human Validation: To ensure the reliability of the synthetic labels, a subset of the data was independently annotated by 11 human evaluators. This resulted in 3,212 annotations with a 97.5% average agreement rate compared to the synthetic labels.
Method
The authors leverage a BERT-like encoder model, referred to as BERT-as-a-Judge, to evaluate model-generated answers by treating the task as a structured text classification problem. The model is trained on labeled question-candidate-reference triplets constructed from multiple benchmark datasets, including MMLU, ARC-Easy, ARC-Challenge, SQuAD-v2, HotpotQA, GSM8K, and Math. These datasets are selected for their availability of explicit training splits, and the training mixture is carefully balanced to ensure approximately one million synthetically labeled samples across task categories and models. The encoder is initialized from EuroBERT 210M and fine-tuned for a single epoch using binary cross-entropy loss. Training employs a learning rate of 2×10−5, with a 5% warmup ratio and a linear decay schedule, conducted on 8 MI250x GPUs, achieving an effective batch size of 32 and requiring approximately 20 GPU hours per run.
The evaluation framework integrates two distinct modules: a regex-based evaluation system and the BERT-as-a-Judge model. In the regex-based approach, model outputs are processed through a parsing step that extracts answers using a regular expression pattern "Final answer:\s*(.)", which enables flexible and general answer extraction. This method relies on a lexical match between the extracted answer and the reference, resulting in binary scores. In contrast, the BERT-as-a-Judge framework employs a fine-tuned encoder that directly assesses the generated answer against the reference. The model processes the question, candidate answer, and reference as structured input, leveraging its bidirectional attention mechanism to produce a confidence score. This approach allows for a more nuanced evaluation by capturing semantic alignment between the answer and the reference. As shown in the figure below, both evaluation paths converge into a true ranking mechanism that compares the performance of different models across tasks.
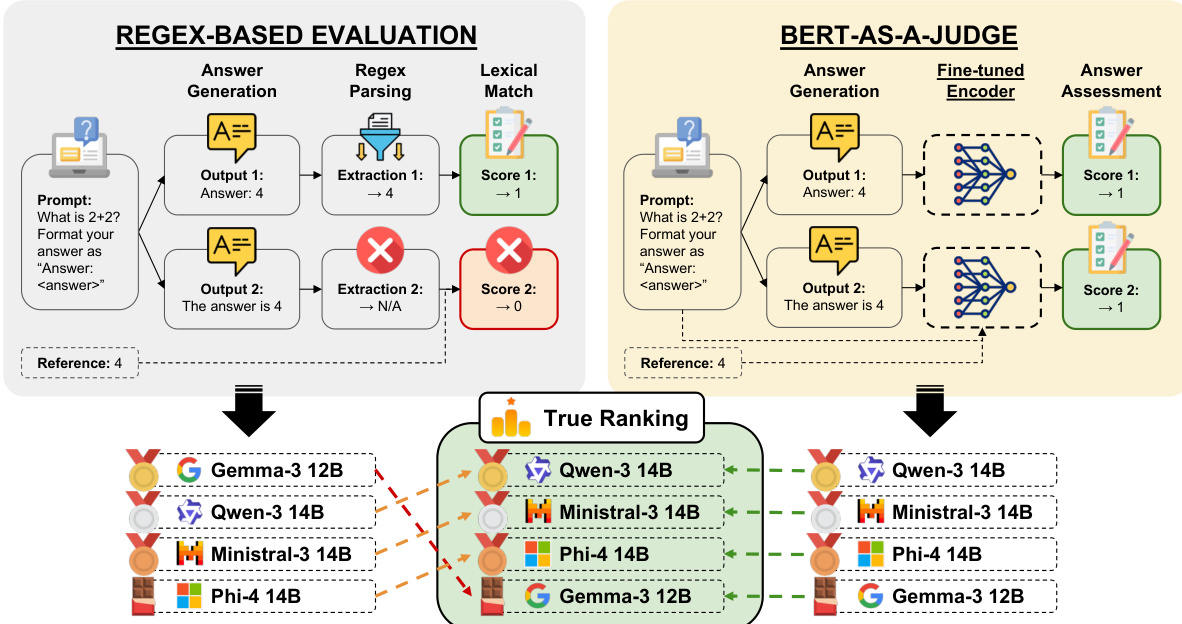
The overall architecture is designed to support both direct and indirect evaluation of model outputs, with the BERT-as-a-Judge model providing a scalable and automated solution for answer assessment that does not rely on manual annotations.
Experiment
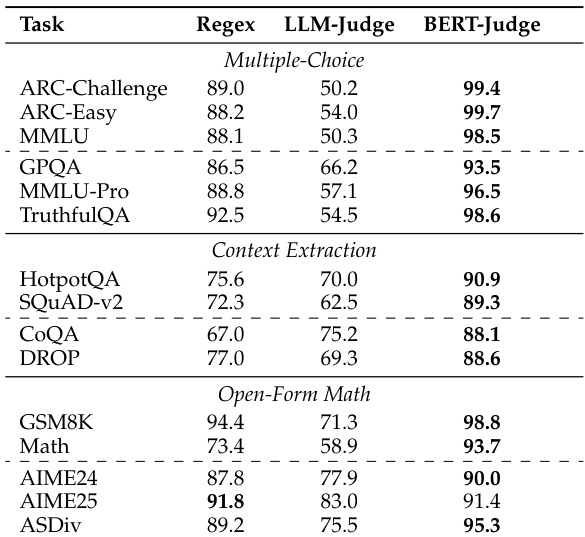
The researchers evaluated several assessment methods, including regex-based parsing, LLM-as-a-Judge, and their proposed BERT-as-a-Judge encoder, against synthetic ground-truth labels across multiple task categories. The results demonstrate that regex-based evaluation significantly distorts model rankings and underestimates performance due to rigid lexical matching and formatting failures. In contrast, the BERT-as-a-Judge encoder provides superior accuracy, strong generalization to out-of-domain models, and high robustness to varying answer formats while remaining computationally efficient.
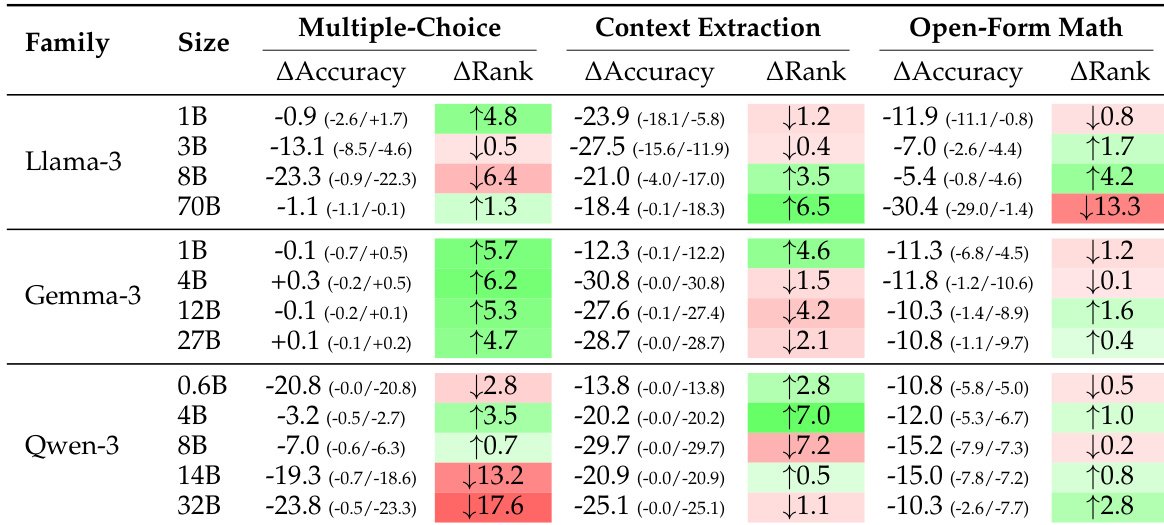
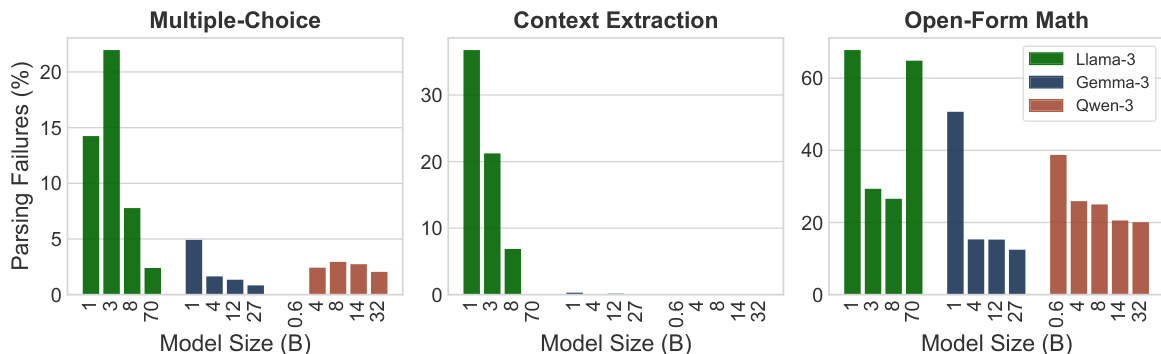
The authors compare regex-based evaluation with BERT-as-a-Judge across multiple task categories. Results show that BERT-as-a-Judge achieves higher accuracy than regex, with minimal performance difference when the question is excluded from the input. The method demonstrates consistent effectiveness across different task types. BERT-as-a-Judge outperforms regex-based evaluation across all task categories Excluding the question from the input has minimal impact on BERT-as-a-Judge performance BERT-as-a-Judge maintains high accuracy on multiple-choice, context extraction, and open-form math tasks
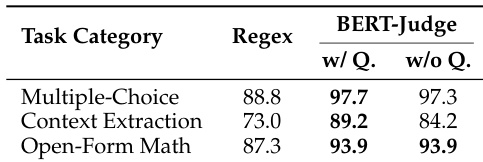
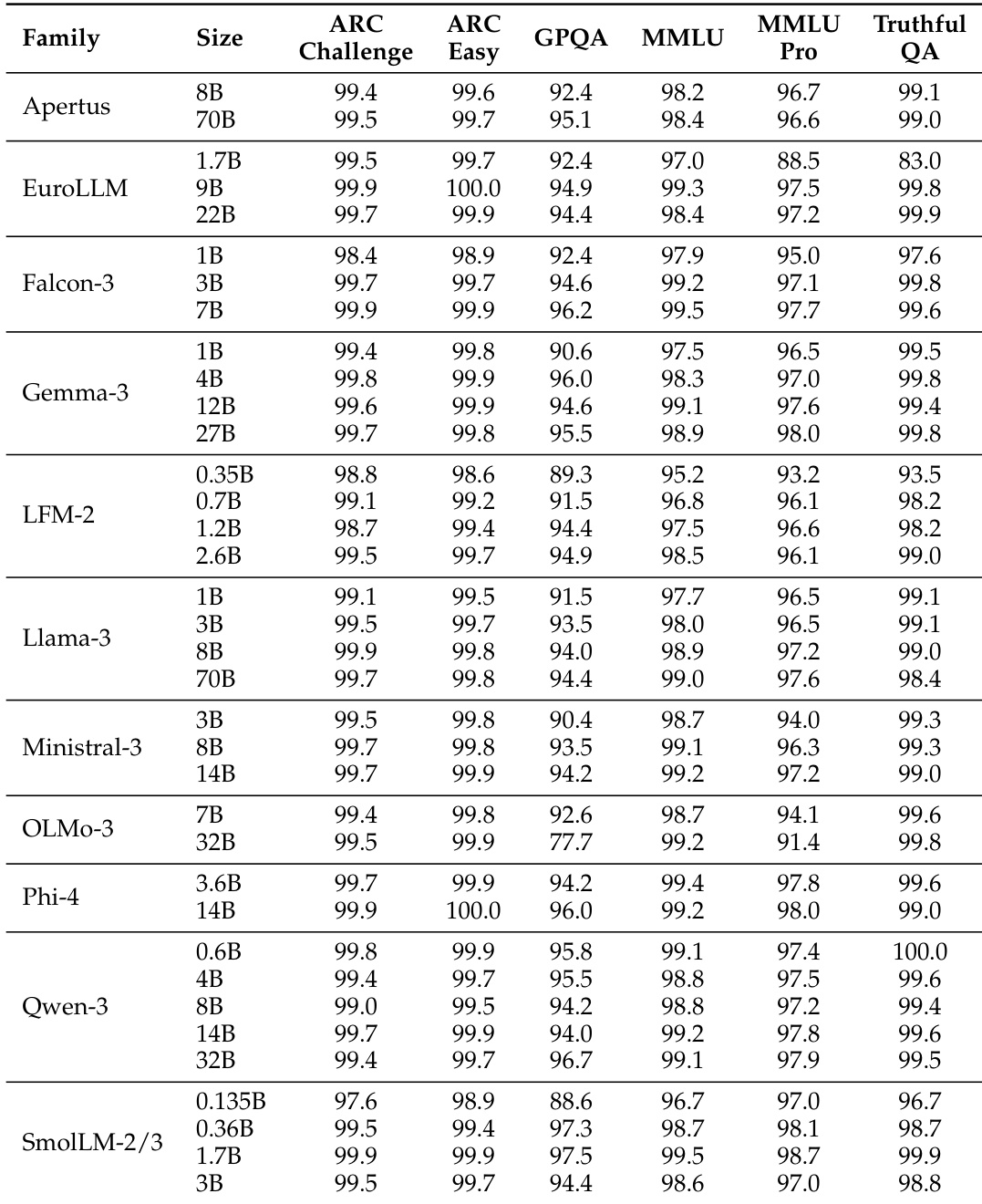
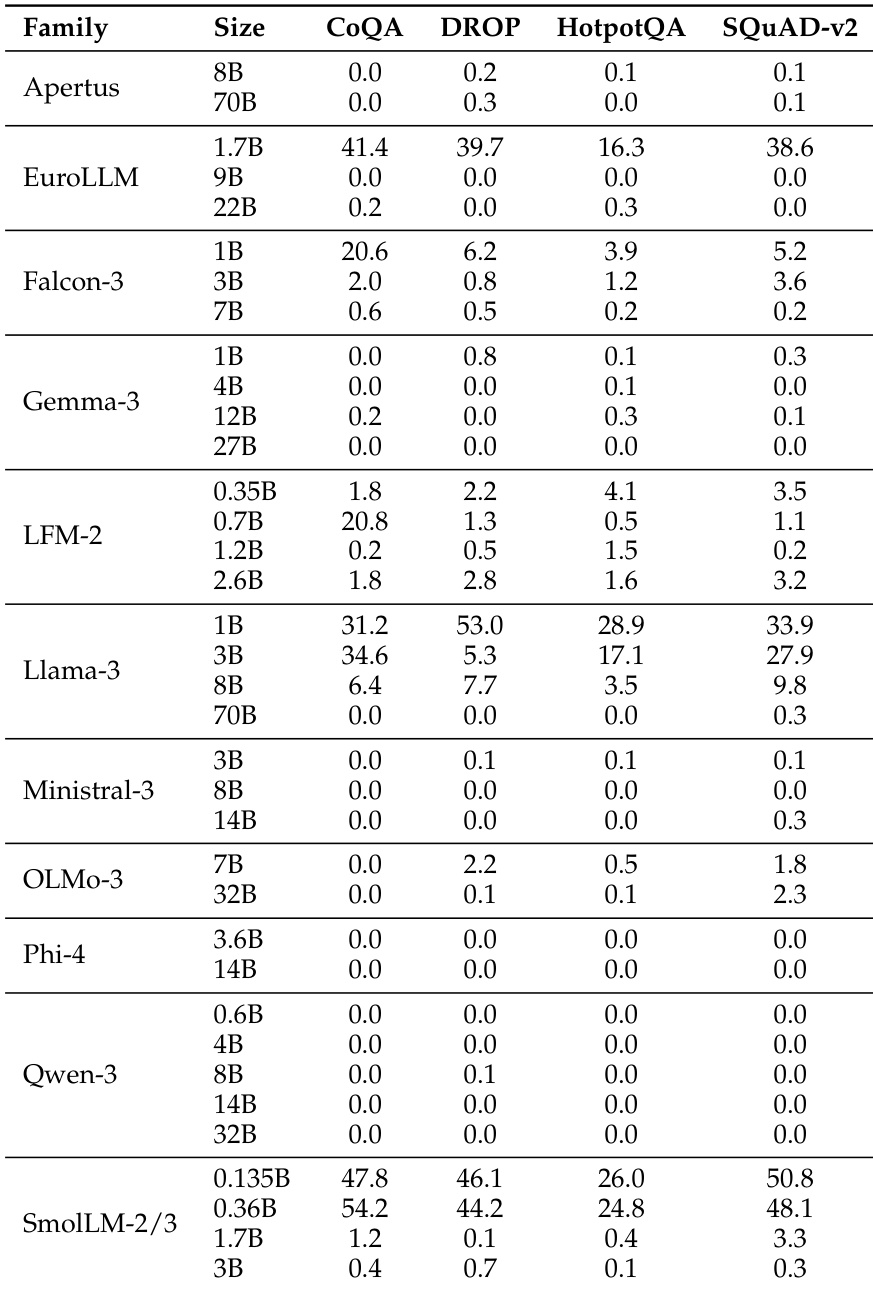
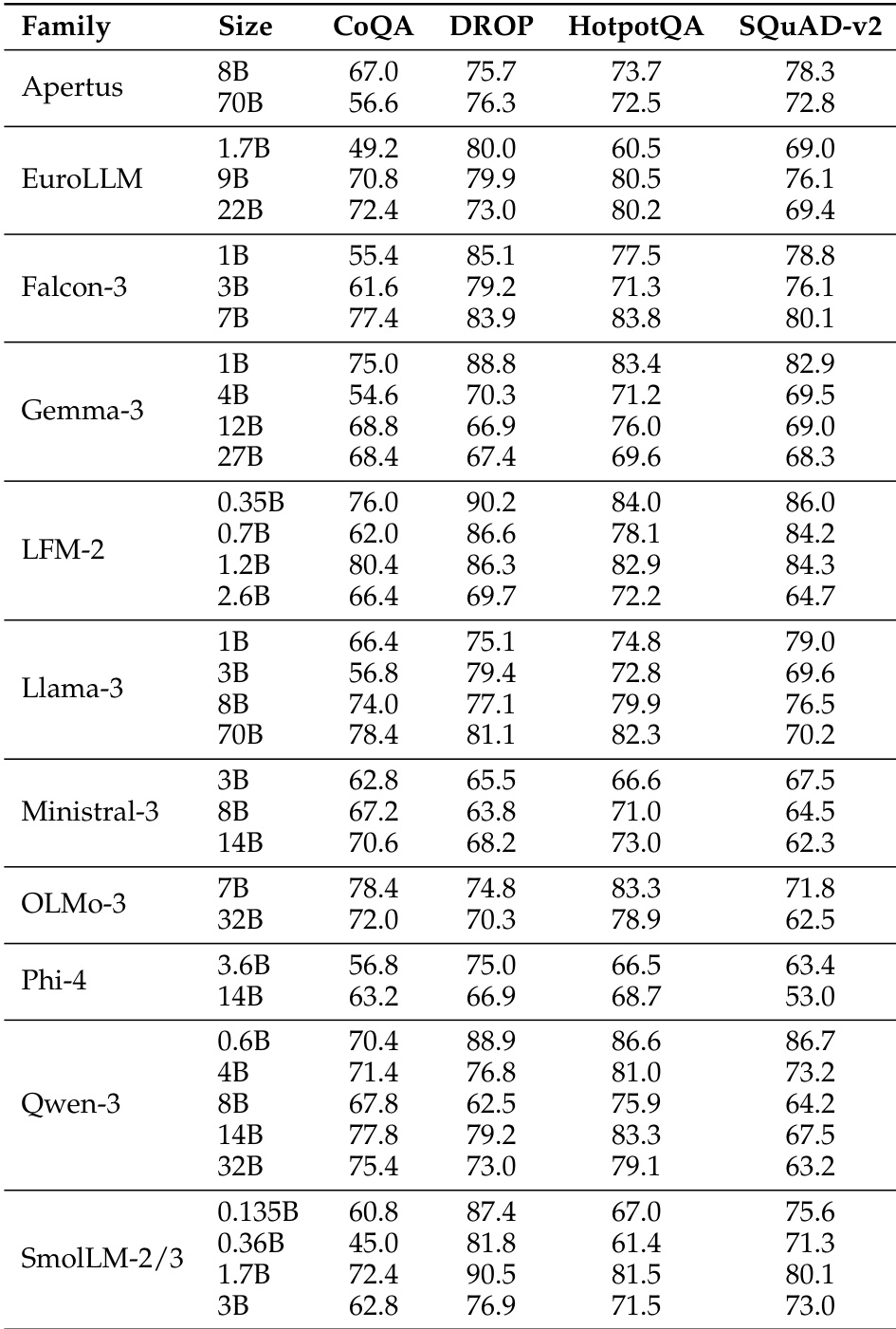
The the the table presents accuracy scores for various model families across multiple benchmarks, showing significant performance differences between models. BERT-as-a-Judge achieves high accuracy across tasks, outperforming regex-based methods, with strong alignment to ground-truth labels. BERT-as-a-Judge consistently outperforms regex-based evaluation across all model families and benchmarks. Larger models generally achieve higher accuracy, with some exceptions in specific tasks. Performance varies widely across tasks, with multiple-choice and open-form math showing higher accuracy compared to context extraction.
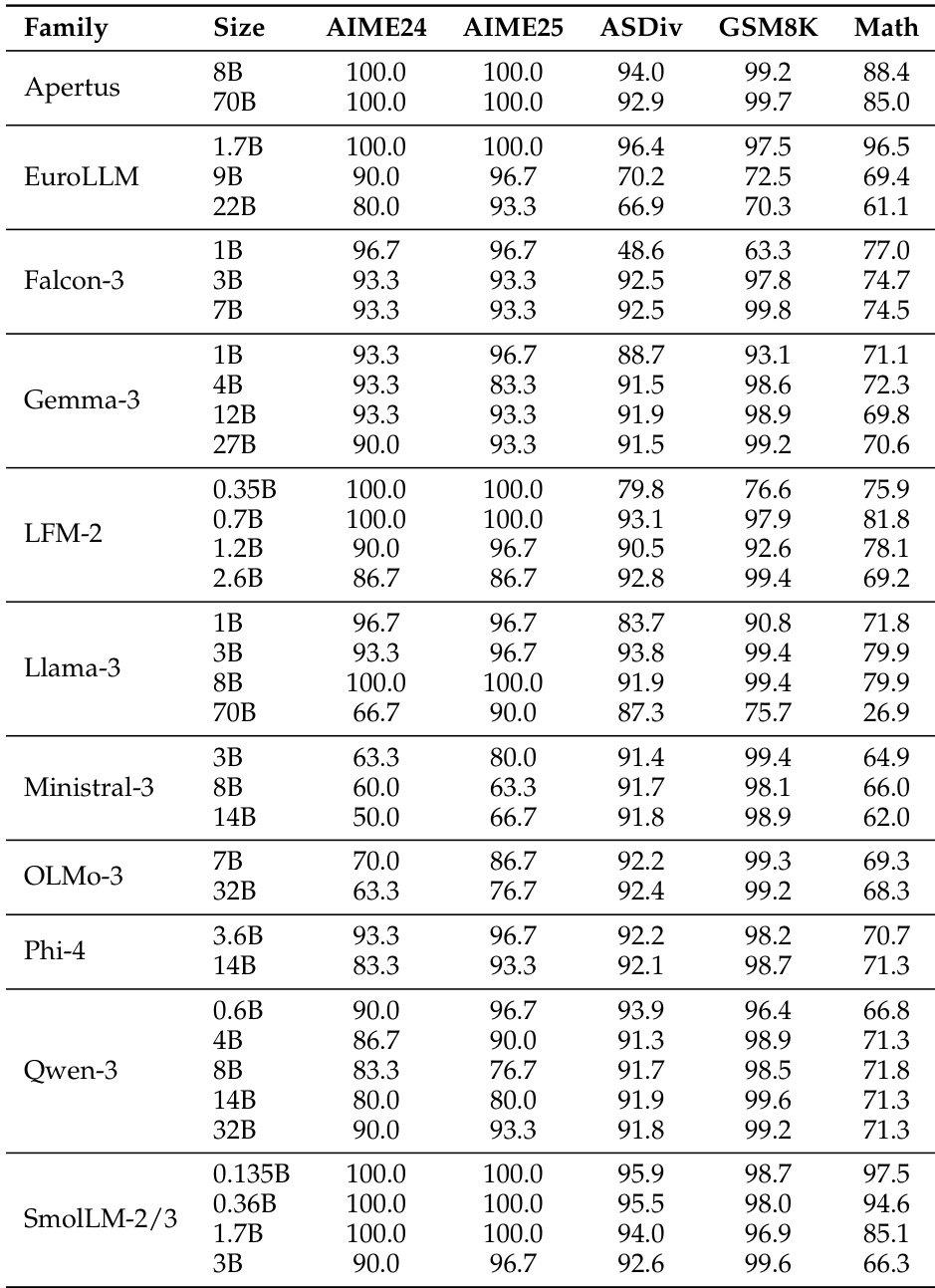
The the the table presents accuracy scores for various language model families across multiple benchmarks, showing significant variation in performance based on model size and family. Results indicate that larger models generally achieve higher accuracy, with some families demonstrating consistent performance across tasks while others show more variability. Performance varies significantly across model families and sizes, with larger models generally outperforming smaller ones Different model families exhibit distinct performance patterns across benchmarks, indicating task-specific strengths Some models achieve high accuracy on specific tasks while showing low scores on others, highlighting task-dependent performance variation
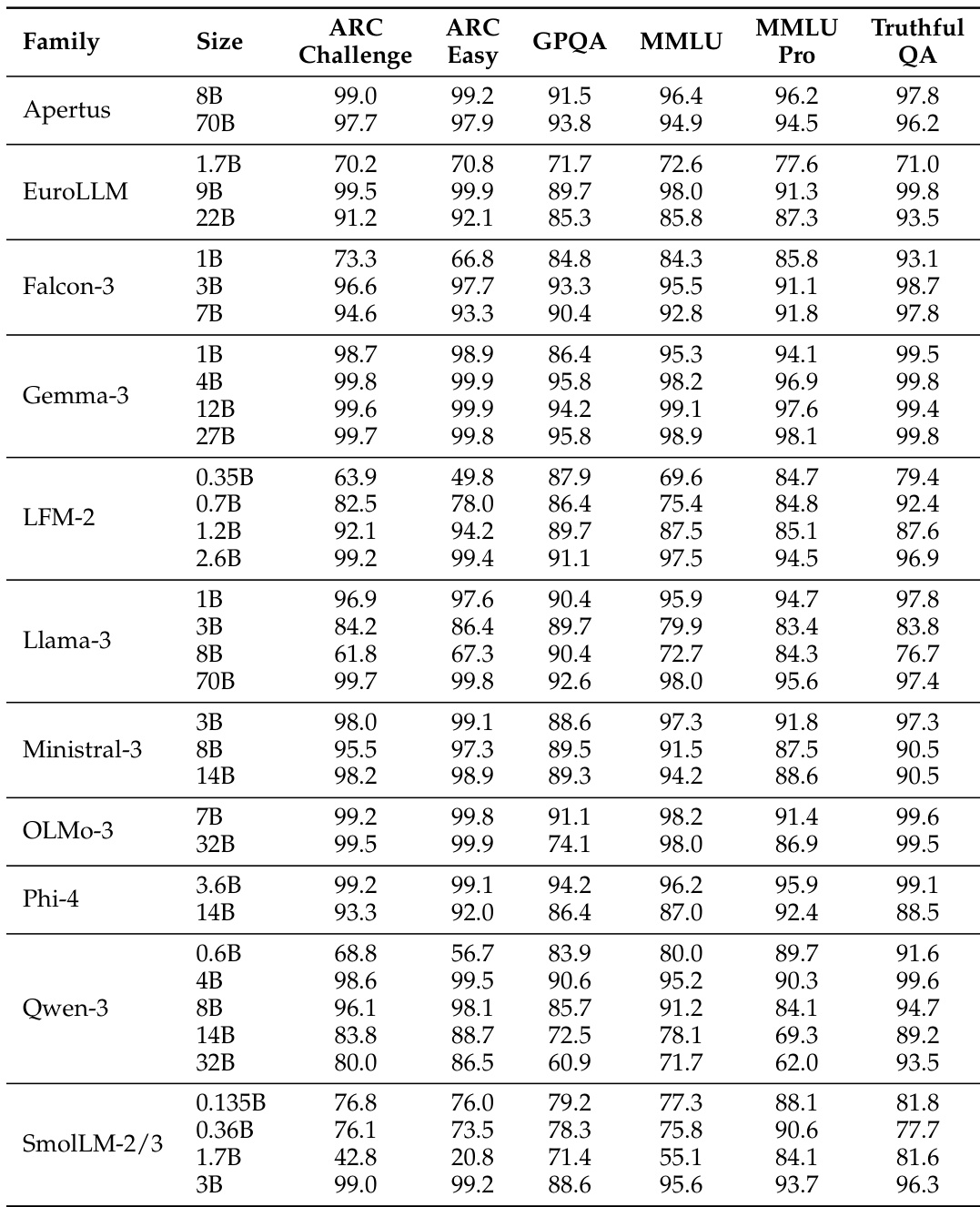
The the the table presents a comparison of model performance across multiple benchmarks for various model families and sizes. It highlights differences in accuracy across tasks, with some models achieving higher scores on certain benchmarks while others perform better on different ones, reflecting varying strengths across model architectures and sizes. Performance varies significantly across models and benchmarks, with no single model excelling in all tasks. Model size influences performance, with larger models generally showing higher accuracy on most benchmarks. Different model families exhibit distinct strengths, with some performing better on specific tasks like CoQA or DROP.
The authors compare BERT-as-a-Judge to regex-based and LLM-as-a-Judge methods, finding that the encoder-based approach achieves higher accuracy across various benchmarks. Results show that regex-based evaluation leads to significant performance distortions, while BERT-as-a-Judge demonstrates robustness and strong alignment with ground-truth labels. BERT-as-a-Judge achieves higher accuracy than regex-based evaluation across all benchmarks Regex-based evaluation causes substantial performance distortions and misranking BERT-as-a-Judge is robust to variations in answer formatting and generalizes well to out-of-domain tasks
The authors evaluate the effectiveness of BERT-as-a-Judge by comparing it against regex-based and LLM-as-a-Judge methods across various task categories and model families. The results demonstrate that BERT-as-a-Judge provides superior accuracy and robustness, avoiding the performance distortions and misranking common in regex-based evaluation. While model performance varies based on architecture, size, and specific task requirements, the BERT-based approach maintains consistent alignment with ground-truth labels across diverse benchmarks.