Command Palette
Search for a command to run...
Uni-ViGU: A Diffusion-Based Video Generator による、Video Generation と Understanding の統一に向けて
Uni-ViGU: A Diffusion-Based Video Generator による、Video Generation と Understanding の統一に向けて
Luozheng Qin Jia Gong Qian Qiao Tianjiao Li Li Xu Haoyu Pan Chao Qu Zhiyu Tan Hao Li
概要
ご指定いただいた条件に基づき、提供された英文を技術的に正確かつ自然な日本語に翻訳いたしました。視覚的な理解と生成を統合するユニファイド・マルチモーダルモデル(Unified multimodal models)は、根本的な課題に直面しています。それは、視覚的生成における計算コストが、理解に比べて著しく高いことであり、特にビデオにおいてはその傾向が顕著です。この不均衡を解消するため、我々は従来のパラダイムを逆転させるアプローチを提案します。すなわち、理解中心のMLLMを生成に対応させるのではなく、ビデオ生成器を基盤として拡張することで、ビデオの生成と理解を統合するフレームワーク「Uni-ViGU」を提案します。我々は、単一のプロセス内でビデオに対する連続的なflow matchingと、テキストに対する離散的なflow matchingを実行する、統一されたflow手法を導入し、一貫性のあるマルチモーダル生成を可能にしました。さらに、生成的な事前知識(generative priors)を維持しつつ、Transformerブロックに軽量なレイヤーを追加してテキスト生成を強化する、モダリティ駆動型のMoEベースのフレームワークを提案します。生成の知識を理解へと転用するために、我々は二段階からなる双方向のトレーニングメカニズムを設計しました。第一段階の「Knowledge Recall」では、入力されたpromptを再構成することで、学習済みのテキストとビデオの対応関係を活用します。第二段階の「Capability Refinement」では、詳細なキャプションを用いてfine-tuningを行い、識別的な共有表現(discriminative shared representations)を確立します。実験の結果、Uni-ViGUはビデオ生成と理解の両方において競争力のある性能を達成しており、生成中心のアーキテクチャが、統一されたマルチモーダル・インテリジェンスに向けたスケーラブルな道筋であることを実証しました。プロジェクトページおよびコード:https://fr0zencrane.github.io/uni-vigu-page/
One-sentence Summary
Uni-ViGU unifies video generation and understanding by extending a diffusion-based video generator through a unified flow matching method and a modality-driven MoE-based architecture, utilizing a two-stage bidirectional training mechanism to repurpose generative priors for discriminative understanding.
Key Contributions
- The paper introduces Uni-ViGU, a framework that unifies video generation and understanding by extending a pretrained video generator as a foundation to leverage existing spatiotemporal priors.
- A unified flow formulation is presented that enables coherent multimodal generation by performing continuous flow matching for video and discrete flow matching for text within a single process.
- The work implements a modality-driven Mixture-of-Experts (MoE) architecture and a bidirectional training mechanism consisting of Knowledge Recall and Capability Refinement to repurpose generative knowledge for discriminative video understanding.
Introduction
Integrating visual understanding and generation into a single model is essential for developing general purpose visual intelligence. Current approaches typically extend understanding centric multimodal large language models to support generation, but this faces massive scalability issues because video generation requires processing millions of tokens through iterative denoising. The authors propose Uni-ViGU, a framework that inverts this paradigm by using a video generator as the foundational architecture. They introduce a unified flow method that combines continuous flow matching for video with discrete flow matching for text within a single process. To enable this, the authors leverage a modality driven MoE based architecture that augments Transformer blocks with lightweight layers for text while preserving generative priors, alongside a bidirectional training mechanism to repurpose learned text to video correspondences for video understanding.
Dataset
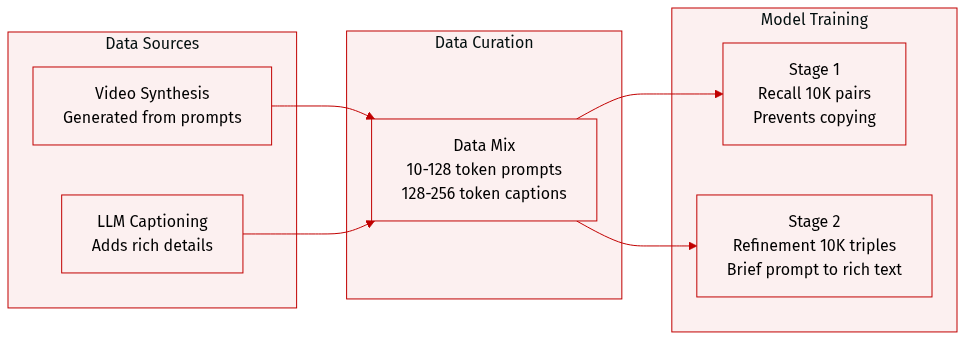
The authors utilize a meticulously curated dataset of synthesized video-text pairs to train Uni-ViGU through a two-stage bidirectional framework. The dataset details are as follows:
- Dataset Composition and Sources: The data is synthesized by using state-of-the-art video generators to create videos from a set of initial conditioning prompts. An LLM is then used to analyze each video-prompt pair to generate highly detailed captions that enrich the original prompt's information.
- Subsets and Training Usage:
- Stage 1 (Knowledge Recall): The model is trained on 10K video-prompt pairs. In this stage, the target text is identical to the conditioning prompt, though condition dropout is applied to prevent the model from simply copying the input.
- Stage 2 (Capability Refinement): The model undergoes fine-tuning on an additional 10K video-prompt-detailed caption triples. Here, the model is conditioned on a brief prompt but tasked with generating a semantically precise, detailed caption.
- Processing and Constraints: To ensure the model develops genuine comprehension rather than trivial inference, the authors enforce strict token-length constraints. Conditioning prompts are limited to 0 to 128 tokens, while detailed captions are restricted to 128 to 256 tokens. This length separation forces the model to rely on the shared attention mechanism to bridge the gap between the brief prompt and the rich description.
Method
The authors leverage the latent diffusion framework of WAN2.1, a state-of-the-art text-to-video generator, as the foundation for their unified model. This framework operates in a compressed latent space, enabling efficient video generation through iterative denoising. The process begins with a video x being encoded into a latent representation z1=E(x) by a Variational Autoencoder (VAE). The model learns a diffusion process by defining a continuous transport path from Gaussian noise z0 to the data latent z1 via linear interpolation, zt=(1−t)z0+tz1. A neural network, specifically a Diffusion Transformer (DiT), is trained to predict the velocity field u=z1−z0 conditioned on the text prompt c, the intermediate latent zt, and the time step t, optimizing a flow matching loss. Inference proceeds by integrating this learned velocity field from t=0 to t=1 to generate the final latent, which is then decoded into the output video x^=D(z1).
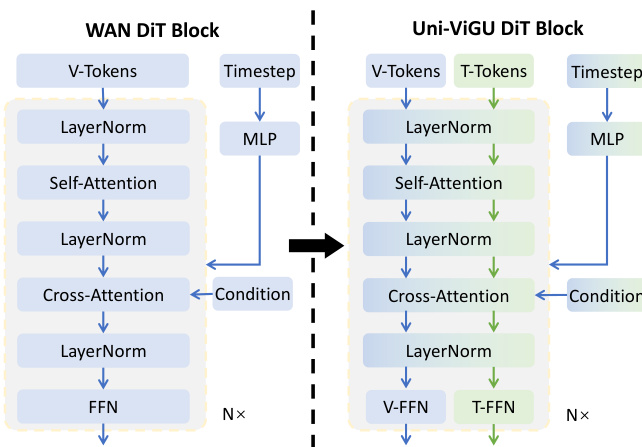
The core architecture of the video generator is a DiT, composed of multiple transformer blocks. Each block processes the input through a sequence of layers: self-attention, cross-attention, and a feed-forward network (FFN). The self-attention layer captures spatial and temporal dependencies within the video features, while the cross-attention layer integrates semantic information from the text prompt c, which is used as the key-value pair. The FFN layer performs position-wise transformations. This structure is extended to support a unified text-video generation framework, as shown in the figure below.
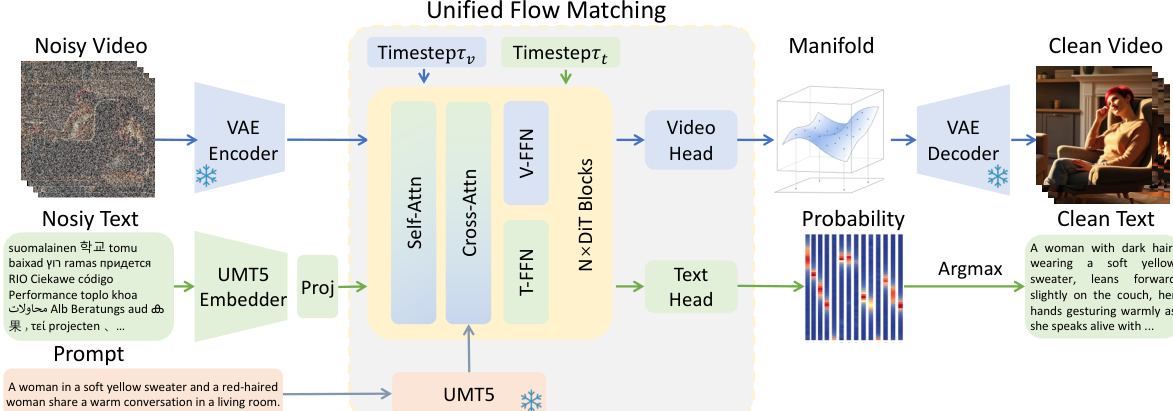
To unify video and text generation, the authors propose a novel uni-flow process that models both modalities within a single generative framework. For video, the continuous flow matching formulation remains, operating in the latent space. For text, a discrete flow matching approach is adapted, where text tokens are mapped to continuous embeddings via a learnable matrix E. The model learns to predict the velocity field ut=zt,1−zt,0 in this embedding space. Crucially, the two modalities are jointly learned in a single Transformer backbone. The key innovation lies in the modality-driven Mixture-of-Experts (MoE) architecture, which shares the attention layers to preserve cross-modal alignment while employing modality-specific FFN branches to capture domain-specific knowledge. The attention mechanism operates over the concatenated sequence of video and text tokens, enabling bidirectional cross-modal interaction. The resulting representations are then routed to modality-specific experts, FFNv and FFNt, ensuring that the shared attention patterns learned during pretraining are fully utilized while the FFN layers can specialize for their respective modalities. This design allows for efficient knowledge transfer from the pretrained video generator to the text generation task.
The training procedure consists of a two-stage bidirectional framework to effectively transfer and refine capabilities. The first stage, Knowledge Recall, initializes the model with a pretrained video generator and trains it to learn the reverse mapping from video to text. To prevent shortcut learning, the conditioning prompt is dropped with a certain probability, forcing the model to recover the text from the noisy video latent. The second stage, Capability Refinement, replaces the target text with detailed video captions, compelling the text generation branch to attend to the video latent to recover fine-grained visual details, thereby developing genuine video understanding. Inference is symmetric: for video generation, the model denoises the video latent from noise, guided by the text prompt; for video understanding, it denoises the text latent from noise, guided by the clean video. For joint generation, both modalities are initialized from noise and denoised in parallel, with their flows coupled through shared attention, allowing for mutual refinement.