Command Palette
Search for a command to run...
SPPO:長期間の推論タスクに向けたSequence-Level PPO
SPPO:長期間の推論タスクに向けたSequence-Level PPO
Tianyi Wang Yixia Li Long Li Yibiao Chen Shaohan Huang Yun Chen Peng Li Yang Liu Guanhua Chen
概要
ご指定いただいた条件に基づき、提供された英文を技術的に正確かつ自然な日本語(学術・技術論文スタイル)に翻訳いたしました。【翻訳文】Proximal Policy Optimization (PPO) は、検証可能な報酬(verifiable rewards)を用いた推論タスクにおける Large Language Models (LLMs) のアライメントにおいて中心的な役割を果たしている。しかしながら、標準的な token レベルの PPO は、長い Chain-of-Thought (CoT) のスパンにおける時間的クレジット割り当て(temporal credit assignment)の不安定さや、value model の膨大なメモリコストに起因して、この設定下では困難を伴う。GRPO のような critic-free な代替手法はこれらの問題を緩和するものの、ベースライン推定のために複数のサンプルを必要とするため、多大な計算オーバーヘッドが発生し、training throughput を著しく制限するという課題がある。本論文では、PPO のサンプル効率と結果ベース(outcome-based)の更新の安定性を調和させた、スケーラブルなアルゴリズムである Sequence-Level PPO (SPPO) を提案する。SPPO は、推論プロセスを Sequence-Level Contextual Bandit 問題として再定式化し、デカップリングされたスカラー値関数(decoupled scalar value function)を採用することで、マルチサンプリングを行うことなく低分散な advantage 信号を導出する。数学的 benchmark における広範な実験により、SPPO は標準的な PPO を大幅に上回り、計算負荷の高いグループベースの手法と同等の性能を示すことが実証された。これにより、推論能力を持つ LLMs をアライメントするための、リソース効率の高いフレームワークを提供する。
One-sentence Summary
The authors propose SPPO, a scalable sequence-level reinforcement learning algorithm that reformulates long-horizon reasoning as a contextual bandit problem and employs a decoupled scalar value function to achieve low-variance advantage signals without the multi-sampling overhead of group-based methods, significantly outperforming standard PPO on mathematical benchmarks.
Key Contributions
- The paper introduces Sequence-Level PPO (SPPO), an algorithm that reformulates the reasoning process as a Sequence-Level Contextual Bandit problem to harmonize sample efficiency with the stability of outcome-based updates.
- This work implements a Decoupled Critic strategy that uses a lightweight critic to align a larger policy, which reduces memory usage by 12.8% while enabling high-throughput single-sample updates.
- Extensive evaluations on mathematical benchmarks such as AIME, AMC, and MATH demonstrate that SPPO matches the performance of group-based methods like GRPO while achieving a 5.9x training speedup.
Introduction
Aligning Large Language Models (LLMs) for complex reasoning tasks requires Reinforcement Learning with Verifiable Rewards (RLVR) to ensure logical correctness. While standard token-level Proximal Policy Optimization (PPO) is widely used, it suffers from unstable temporal credit assignment and high memory costs when dealing with long Chain-of-Thought horizons. Conversely, critic-free methods like Group Relative Policy Optimization (GRPO) reduce bias but introduce high variance and significant computational overhead because they require sampling multiple responses per prompt to estimate baselines. The authors leverage a new perspective that treats reasoning as a Sequence-Level Contextual Bandit problem rather than a multi-step Markov Decision Process. They introduce Sequence-Level PPO (SPPO), which uses a learned scalar value function to provide stable advantage signals. This approach allows for high-throughput single-sample updates, matching the performance of group-based methods while achieving a significant training speedup.
Method
The authors leverage a sequence-level optimization framework to address the challenges of credit assignment in long-horizon reasoning tasks. The proposed method, SPPO, reformulates the standard token-level Markov Decision Process (MDP) into a Sequence-Level Contextual Bandit (SL-CB) setting, where the entire generated response sequence is treated as a single atomic action. This shift fundamentally alters the policy optimization process by eliminating the need for a token-level critic that attempts to estimate future returns from intermediate states. Instead, SPPO introduces a scalar value model Vϕ(sp), which predicts the probability of success for a given prompt sp. This value function is trained using Binary Cross-Entropy (BCE) loss to ensure it serves as a calibrated baseline for the advantage calculation.
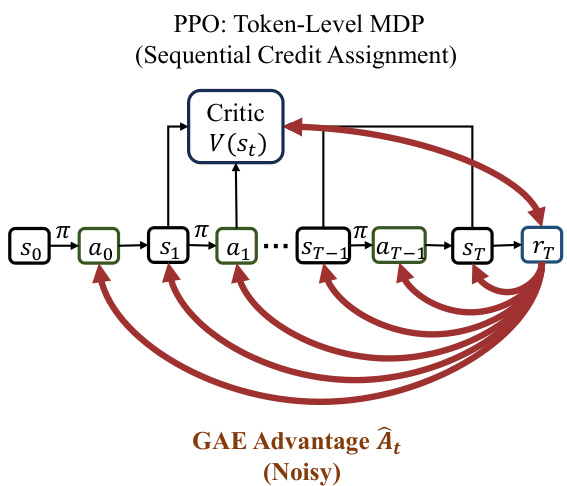
As shown in the figure below, the standard PPO framework operates within a token-level MDP, where the policy π generates actions at sequentially from states st. A critic V(st) estimates the value of each intermediate state, and the advantage A^t is computed via Generalized Advantage Estimation (GAE), which sums discounted temporal difference errors. This mechanism leads to noisy, position-dependent credit assignment, as the advantage signal is heavily influenced by the token's position in the sequence, causing the "tail effect" where rewards are only propagated effectively near the end of the generation.
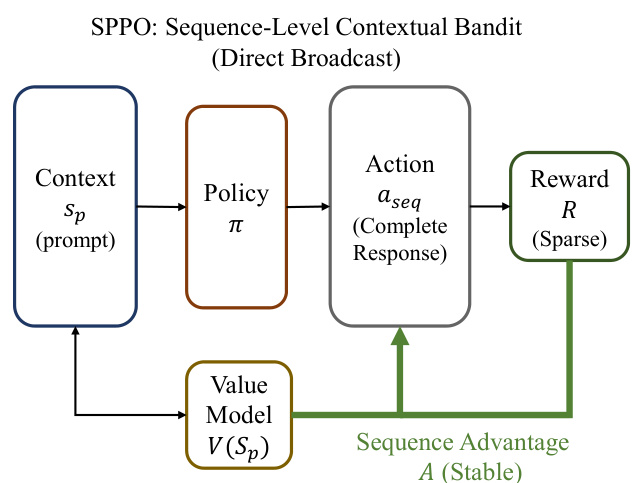
In contrast, the SPPO framework, as illustrated in the figure below, operates on the prompt sp as the sole context. The policy π outputs a complete response sequence aseq, which is then evaluated by a sparse reward function R to determine its correctness. The advantage is computed as a simple scalar difference A(sp,a)=R−Vϕ(sp), which is then directly broadcast to every token within the generated sequence. This sequence-level advantage A is stable and independent of the response length, effectively solving the temporal credit assignment problem by reinforcing or penalizing the entire chain of actions uniformly based on the final outcome. The policy optimization objective adapts the PPO clipped surrogate objective but applies the single sequence-level advantage to all tokens, ensuring that the policy update is aligned with the holistic success or failure of the reasoning process.
Experiment
The evaluation compares the proposed SPPO algorithm against several baselines, including standard PPO, GRPO, RLOO, and ReMax, using mathematical reasoning benchmarks and reinforcement learning control tasks. Results demonstrate that SPPO achieves superior performance and faster convergence by utilizing a sequence-level contextual bandit formulation that effectively resolves credit assignment issues in sparse-reward settings. Furthermore, the study validates that decoupling the critic size from the policy significantly reduces memory overhead without sacrificing accuracy, making large-scale reasoning model alignment more resource-efficient.
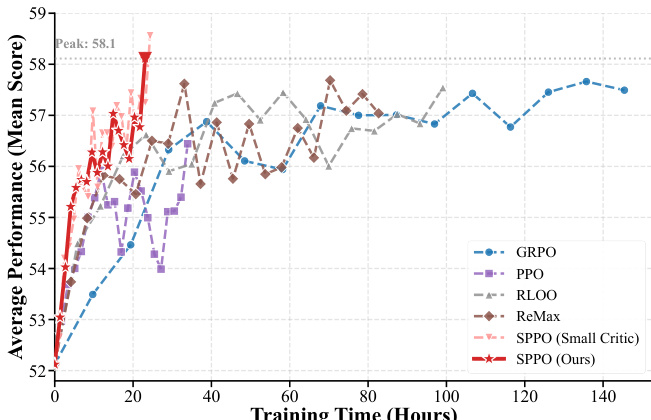
The results show that SPPO achieves higher average performance and faster convergence compared to baseline methods. The approach demonstrates improved training efficiency, with SPPO reaching peak performance more quickly than other algorithms. SPPO outperforms all baselines in average performance and convergence speed SPPO achieves peak performance significantly faster than group-based methods The small critic variant of SPPO maintains high performance while reducing computational overhead
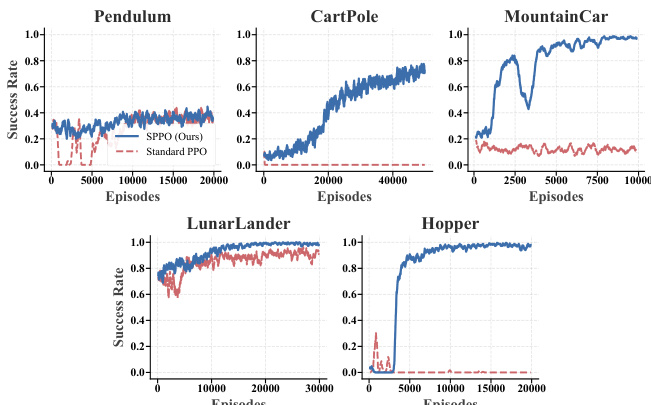
The authors evaluate SPPO against Standard PPO across five control tasks with sparse rewards. Results show SPPO consistently converges and outperforms Standard PPO, particularly in long-horizon tasks where the baseline fails. SPPO achieves robust convergence across all control tasks, while Standard PPO fails in complex environments. In long-horizon tasks, SPPO successfully solves problems where Standard PPO remains at low success rates. SPPO demonstrates superior sample efficiency, rapidly improving in precision tasks like CartPole.
The the the table compares the performance of various reinforcement learning methods on mathematical reasoning benchmarks. SPPO consistently achieves higher average scores than baselines, with the best results observed when using a smaller critic model. The authors use a sequence-level advantage estimation method to improve training stability and efficiency. SPPO outperforms all baselines on both model scales, achieving the highest average score. Using a smaller critic model improves performance and reduces memory usage while maintaining effectiveness. Standard PPO shows limited improvement over the base model, indicating instability in sparse-reward settings.
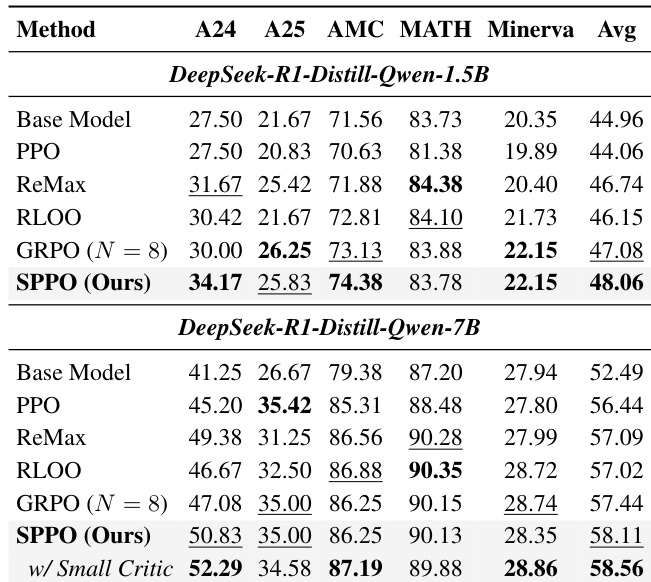
SPPO is evaluated against Standard PPO and other baseline methods across control tasks with sparse rewards and mathematical reasoning benchmarks to validate its training efficiency and stability. The results demonstrate that SPPO achieves superior average performance and faster convergence, particularly in complex, long-horizon environments where baseline methods often fail. Additionally, employing a smaller critic model enhances performance and reduces computational overhead without sacrificing effectiveness.