Command Palette
Search for a command to run...
SANA-WM: ハイブリッド線形拡散トランスフォーマーによる効率的な分単位の世界モデル
SANA-WM: ハイブリッド線形拡散トランスフォーマーによる効率的な分単位の世界モデル
Haoyi Zhu Haozhe Liu Yuyang Zhao Tian Ye Junsong Chen Jincheng Yu Tong He Song Han Enze Xie
概要
タイトル:なし抄録:私たちは、1分間の生成のためにネイティブにトレーニングされた効率的な26億パラメータのオープンソース・ワールドモデルであるSANA-WMを紹介する。SANA-WMは、正確なカメラ制御を備えた高忠実度、720p、1分規模の動画を合成する。SANA-WMは、LingBot-WorldやHY-WorldPlayなどの大規模産業ベースラインと比較して同等の視覚品質を実現しつつ、効率を大幅に向上させる。私たちのアーキテクチャを駆動する4つの主要な設計要素がある:(1) ハイブリッド線形アテンションは、メモリ効率の高い長期コンテキストモデリングのために、フレームごとのGated DeltaNet (GDN) とソフトマックスアテンションを組み合わせる。(2) 二重分岐カメラ制御は、正確な6自由度(6-DoF)軌道追従を保証する。(3) 二段階生成パイプラインは、ステージ1の出力に対して長時間動画リファイナを適用し、シーケンス全体にわたる品質と一貫性を向上させる。(4) 堅牢な注釈パイプラインは、公開動画から正確なメートルスケールの6-DoFカメラ姿勢を抽出し、高品質で時空間的に一貫性のあるアクションラベルを生成する。これらの設計により、SANA-WMはデータ、トレーニング計算量、推論ハードウェアの面で顕著な効率を示す:メートルスケールの姿勢教師付きデータとして公開動画クリップをわずか213K本しか使用せず、64台のH100で15日以内にトレーニングを完了し、単一のGPUで60秒のクリップを生成する。その蒸留版は、NVFP4量子化を用いて単一のRTX 5090上でデプロイ可能であり、60秒の720pクリップのノイズ除去を34秒で実行できる。私たちの1分間ワールドモデルベンチマークにおいて、SANA-WMは既存のオープンソースベースラインよりも優れたアクション追従精度を示し、スケーラブルなワールドモデリングのために36倍高いスループットで同等の視覚品質を達成する。
One-sentence Summary
SANA-WM is a 2.6B-parameter open-source world model that synthesizes high-fidelity, 720p, minute-scale videos with precise 6-DoF trajectory adherence by combining Gated DeltaNet and softmax attention in a hybrid linear attention mechanism, dual-branch camera control, and a two-stage refinement pipeline to achieve 36× higher throughput than industrial baselines while enabling efficient consumer GPU deployment.
Key Contributions
- SANA-WM is a 2.6B-parameter open-source world model natively trained to synthesize high-fidelity, 720p, minute-scale videos with precise camera control.
- The architecture integrates four core innovations to enable efficient long-horizon generation, including a Hybrid Linear Attention mechanism that combines frame-wise Gated DeltaNet with softmax attention for memory-efficient context modeling, a Dual-Branch Camera Control module for strict 6-DoF trajectory adherence, a Two-Stage Generation Pipeline that applies a long-video refiner to enhance sequence consistency, and a Robust Annotation Pipeline that extracts metric-scale camera poses from public footage to produce high-quality spatiotemporal labels.
- The model achieves visual quality comparable to large-scale industrial baselines while requiring only 213K training clips and completing training in 15 days on 64 H100 GPUs. It delivers 36 times higher throughput than prior open-source approaches, generates 60-second clips on a single GPU, and supports a distilled variant that processes a minute-long 720p video in 34 seconds on an RTX 5090 using NVFP4 quantization.
Introduction
World models are emerging as essential interfaces for embodied simulation and interactive environments, yet synthesizing high-fidelity, minute-long videos with precise camera control remains a significant computational bottleneck. Existing open-source approaches typically require large-scale models, extensive training data, and multi-GPU inference, while distilling long-rollout capabilities from short-video generators often results in poor scene persistence and inaccurate trajectory following due to insufficient long-horizon supervision. The authors present SANA-WM, a 2.6B-parameter open-source world model designed around efficiency, which natively trains for one-minute 720p generation using a modest dataset and delivers single-GPU inference across multiple deployment modes. To achieve this, the authors leverage a hybrid Linear DiT backbone that combines recurrent state aggregation with periodic attention for efficient long-context modeling, alongside a dual-branch camera control mechanism that maintains global trajectory structure and fine-grained motion details despite aggressive compression. By incorporating metric-scale pose supervision from public videos and a dedicated visual refinement stage, SANA-WM improves action-following accuracy and throughput by up to 36 times compared to baselines, making long-horizon world modeling accessible to a broader range of researchers and applications.
Dataset
Dataset Composition and Sources
- The authors construct a 213K-clip corpus by re-annotating seven open-source video sources with metric-scale camera poses. Primary sources include Sekai-Game, DL3DV, and OmniWorld, supplemented by additional internet and game footage.
Subset Details and Filtering
- The authors process DL3DV by fitting FCGS 3D Gaussian Splatting models to static 3D captures, rendering diverse one-minute trajectories, and refining the output with DiFix3D to remove rendering artifacts.
- For Sekai-Game and DL3DV, they retain original ground-truth trajectories and apply Pi3X to recover long-sequence metric scale.
- For OmniWorld, they leverage provided ground-truth depth within the VIPE framework and use MoGe-2 for per-frame metric recovery.
- All subsets pass a unified quality filter measuring color saturation, VMAF motion, optical flow consistency, scene cuts, and DOVER aesthetic scores. The authors also enforce camera-specific thresholds requiring a horizontal and vertical field of view between 25 and 120 degrees, a focal mismatch ratio under 0.20, and a scale variation coefficient below 2.0. A Qwen3.5 VLM pass further removes clips with poor visual quality or inappropriate entity counts.
Training Usage and Processing
- The authors use the filtered dataset to train a multi-step, undistilled autoregressive world model. They replace the original VIPE depth backend with Pi3X for sequence consistency and MoGe-2 for precise metric scaling, while also adapting VIPE for per-frame intrinsic optimization.
- Static scene data is augmented with synthetic camera paths drawn from diverse motion families including orbit, spiral, dolly, and fly-through trajectories. Before training, they apply strict splat-coverage tests and discard any rendered clips containing more than 30% near-blank frames.
Metadata Construction and Captioning Strategy
- The authors generate scene-static captions that describe objects, layouts, and lighting while explicitly omitting camera motion verbs. This prevents text from leaking trajectory supervision and forces the model to learn motion control through the dedicated pose branch.
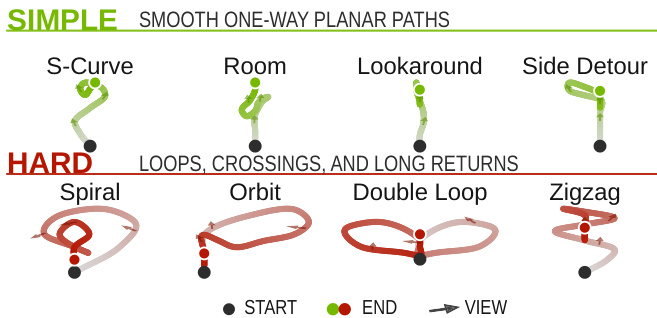
- For evaluation, they construct a benchmark from 80 first-frame conditioning images across four scene categories. Each scene is paired with simple and hard trajectory splits featuring smooth navigation paths and extreme motion templates, complete with revisit metadata, collision-avoidance checks against metric point clouds, and smoothness statistics.
Method
The authors leverage a two-stage generation pipeline to achieve efficient, high-fidelity minute-scale video synthesis with precise camera control. The overall framework, illustrated in the diagram below, consists of a primary generation stage followed by a refinement stage. The initial stage, SANA-WM, generates a latent sequence conditioned on text, camera pose, and reference image tokens. This sequence is then passed to a second-stage refiner that enhances visual quality and temporal consistency. The architecture employs a hybrid attention mechanism combining frame-wise Gated DeltaNet (GDN) with softmax attention, enabling memory-efficient long-context modeling. Each transformer block integrates dual-branch camera conditioning: a coarse branch using ray-local UCPE to encode global 6-DoF poses, and a fine branch using raw-frame Plücker mixing to capture intra-VAE stride motion. The model is trained progressively across four stages: starting with an efficient VAE adaptation, followed by hybrid architecture adaptation, minute-scale extension with action conditioning, and finally chunk-causal fine-tuning and few-step distillation for inference efficiency. 
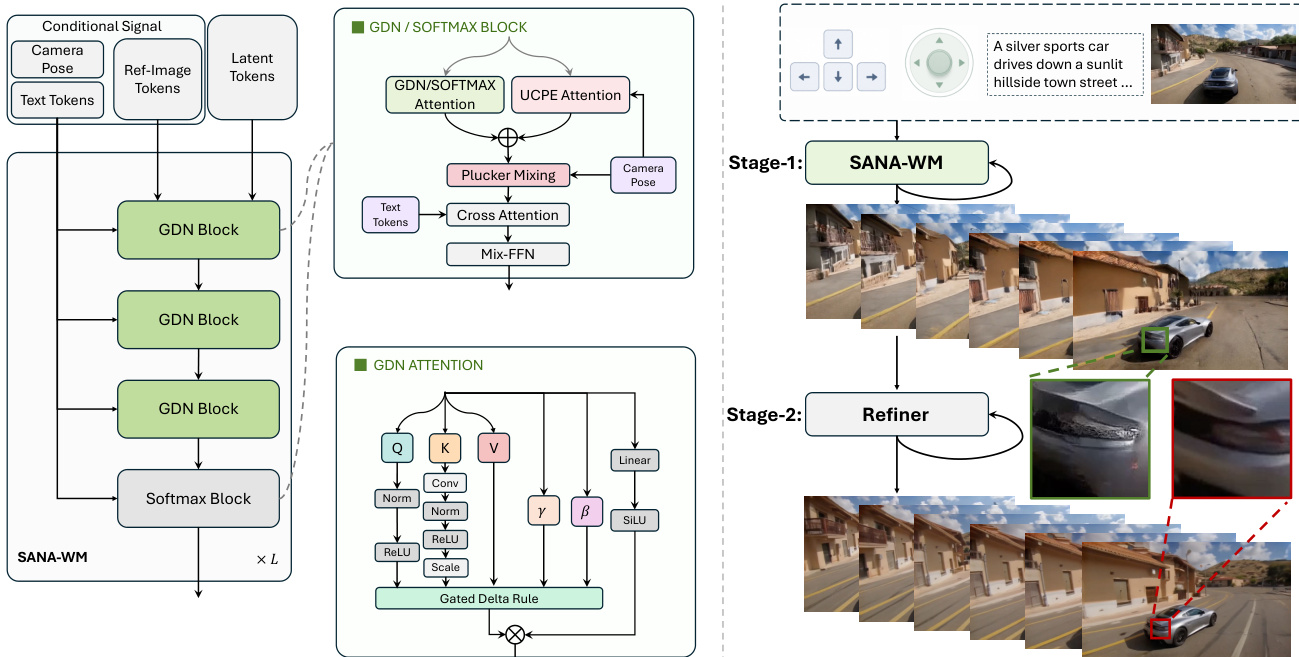
The core architecture of SANA-WM is built upon a Diffusion Transformer (DiT) with 20 transformer blocks, where the model interleaves 15 frame-wise GDN blocks with softmax attention blocks at specific layers. This hybrid design combines the memory efficiency of GDN with the long-range dependency modeling of softmax attention. The GDN blocks operate at the frame level, processing all spatial tokens of a latent frame in a single recurrent step, which maintains a constant D×D recurrent state and avoids the memory explosion associated with cumulative linear attention. The frame-wise GDN is stabilized through algebraic key scaling and a decay gate, ensuring numerical stability over long sequences. For inference, a chunk-causal variant is used, where the reversed-time scan is reset at chunk boundaries to provide local future context without leakage. The model also incorporates dual-rate camera conditioning, with the coarse UCPE branch operating at the latent-frame rate and the fine Plücker mixing branch processing raw-frame raymaps within each VAE temporal stride. 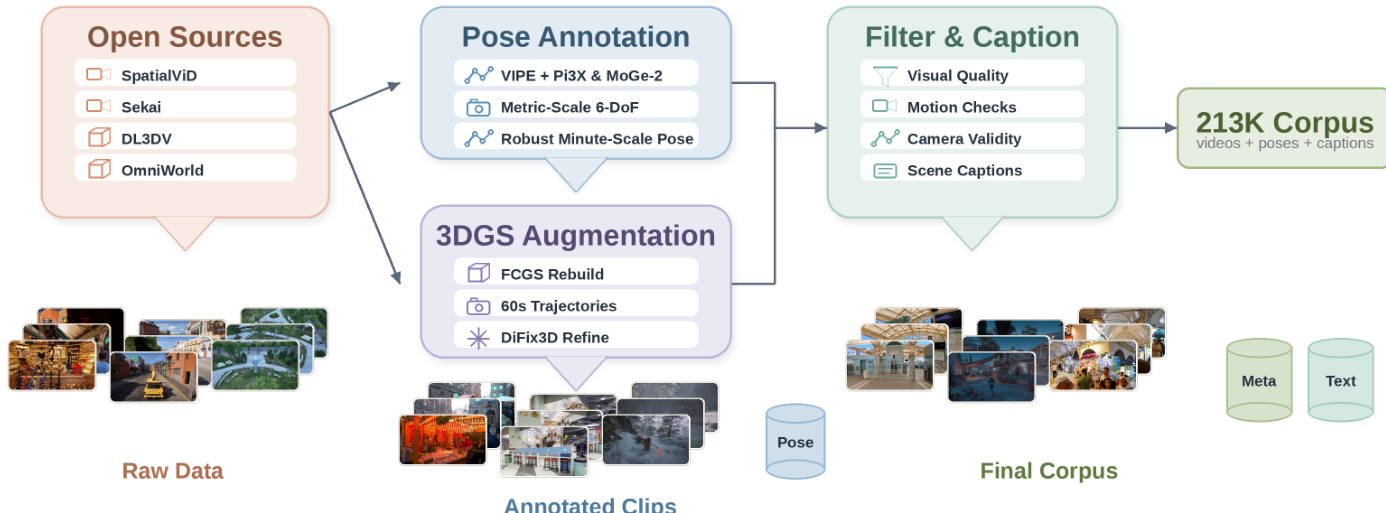
Experiment
The evaluation compares SANA-WM against contemporary world-model baselines across simple and hard camera trajectories, using main experiments to validate action following, visual fidelity, and deployment efficiency, while ablation studies assess architectural components for training stability, memory scaling, and camera conditioning. Results indicate that the architecture successfully balances high-resolution video generation with strict single-GPU limits while significantly reducing late-window visual drift. Qualitatively, the model consistently preserves coherent scene geometry and viewpoint consistency under complex camera motions, whereas competing methods frequently exhibit structural blurring or layout collapse.
The authors compare their method, SANA-WM, with several baselines on camera control accuracy, visual quality, and inference efficiency across two trajectory splits. Results show that SANA-WM achieves strong performance in pose accuracy and visual quality, particularly when combined with a refiner, while maintaining competitive inference speed and memory usage. The refiner improves long-horizon stability and reduces visual drift, especially on challenging trajectories. SANA-WM achieves the best pose accuracy and visual quality on both trajectory splits, outperforming baselines in key metrics. The second-stage refiner improves visual quality and reduces long-horizon degradation, enhancing temporal stability. SANA-WM maintains high inference efficiency with low memory usage and fast generation speed compared to other 720p methods.
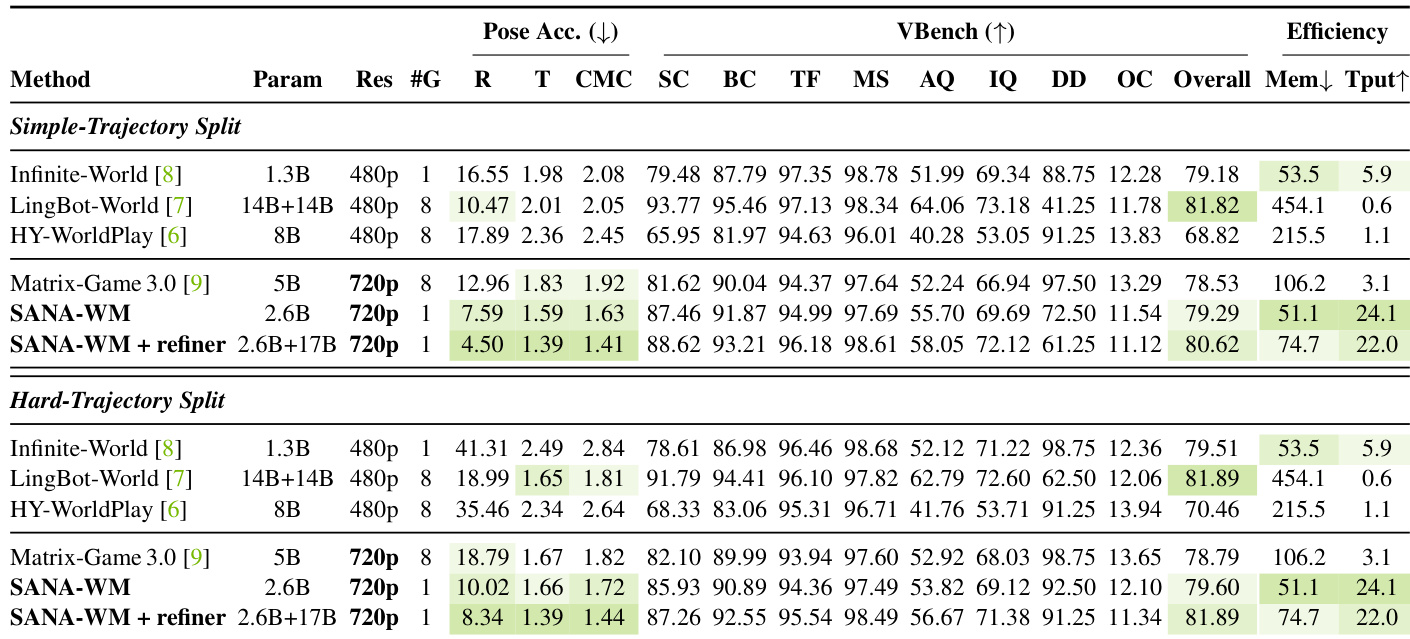
The authors compare their method against baselines on camera control accuracy, visual quality, and temporal stability, showing that their approach achieves strong performance across metrics, particularly in reducing visual drift and improving camera following. The refined version of the model outperforms the original in most aspects, especially in maintaining scene consistency and reducing degradation over long video durations. The results indicate that the proposed method maintains high visual quality while achieving efficient inference and robust camera control. The refined model achieves superior camera control accuracy and reduced visual drift compared to the original version and other baselines. The model maintains high visual quality with minimal degradation over long video durations, particularly on the Hard split. The refined model outperforms the original and other baselines in revisiting memory and temporal stability metrics.

The authors present a comparison of different datasets used in the study, highlighting their respective ranges for various metrics such as motion, color saturation, scene cuts, and quality. The the the table shows that datasets vary in their parameter ranges, with some supporting higher motion values and others emphasizing color and scene changes, indicating diverse evaluation conditions across the experiments. Datasets vary in motion ranges, with some supporting higher motion values than others. Color saturation and scene cuts are defined differently across datasets, indicating varied evaluation conditions. Quality metrics are consistently defined across datasets, suggesting a standardized approach to assessing video quality.

The the the table outlines a progressive training pipeline across four stages, each with distinct purposes, data requirements, and computational budgets. Stage 1 focuses on frame-wise GDN training with SANA-Video SFT data, followed by hybrid attention training in Stage 2, minute-scale video and camera control training in Stage 3, and finally SFT with high-quality clips in Stage 4. The pipeline progresses from shorter clips to longer ones, with increasing compute budgets and decreasing learning rates. The training pipeline progresses through four stages, each with specific data types and clip durations, starting from 5-second clips and moving to 1-minute clips. The effective global batch size decreases from 64 in Stage 1 to 32 in Stage 4, while training steps and compute budgets increase across stages. Learning rates are progressively reduced across stages, starting from 5 × 10^-5 in Stage 1 and ending at 1 × 10^-5 in Stage 4.

The authors compare different training configurations of their model, highlighting improvements in quality, efficiency, and memory usage. The results show that the hybrid attention variant achieves the highest quality scores while maintaining competitive latency and memory consumption, with the GDN + softmax configuration outperforming the others in both metrics. The hybrid attention configuration achieves the highest quality scores while maintaining competitive latency and memory usage. The GDN + softmax tokenizer improves both quality and efficiency compared to the cumulative linear baseline. The LTX2 VAE variant reduces memory consumption and latency while maintaining quality, indicating a trade-off between efficiency and performance.
The evaluation spans diverse video datasets and a progressive training pipeline to validate camera control accuracy, visual fidelity, and temporal consistency across multiple experimental setups. Results indicate that a dedicated refiner substantially enhances long-horizon stability and reduces visual drift, particularly under challenging motion conditions. Further ablation studies on architectural configurations confirm that hybrid attention and optimized tokenizers yield superior visual quality while preserving competitive inference efficiency. Collectively, these findings establish the method as a robust and resource-efficient framework for precise camera-guided video generation.