Command Palette
Search for a command to run...
SMoA: パラメータ効率的なファインチューニングのためのスペクトラム変調アダプタ
SMoA: パラメータ効率的なファインチューニングのためのスペクトラム変調アダプタ
Yongkang Liu Xing Li Mengjie Zhao Shanru Zhang Zijing Wang Qian Li Shi Feng Feiliang Ren Daling Wang Hinrich Schütze
概要
モデルパラメータ数が増加するにつれ、パラメータ効率的ファインチューニング(PEFT)は、事前学習済み大規模言語モデルを調整するための標準的な選択肢となっている。低ランク適応(LoRA)は、低ランク更新手法を用いてフルパラメータファインチューニングをシミュレートし、リソース要件を削減するために広く使用されている。しかし、ランクを低下させると、表現能力の制限に伴う課題に直面する。理論的には、ランクrのLoRAファインチューニングは、事前学習済み重み行列の上位r個の特異値へと収束することが示されている。ランクが増加すると、より多くの主特異方向が保持され、一般的にモデルの性能が向上する。しかし、より大きなランクはより多くの学習可能パラメータを導入し、計算コストが高くなる。このジレンマを克服するため、私たちはSMoAを提案する。SMoAは、より小さなパラメータ予算の下で、スペクトル認識型更新のアクセス可能なファミリーを拡大するSpectrum Modulation Adapterである。SMoAはレイヤーを複数の整列されたスペクトルブロックに分割し、各対角ブロックに対して1つのインブロック・アダマール変調低ランクブランチを適用し、事前学習済みスペクトル方向のより広範なカバレッジを実現する。私たちは、複数のタスクにおいて理論的解析と実証結果を提供する。実験において、SMoAは現在の低予算設定において、LoRAおよび競争力のあるLoRAスタイルのベースラインを上回る平均性能を向上させる。
One-sentence Summary
The authors propose SMoA, a Spectrum Modulation Adapter that partitions layers into multiple aligned spectral blocks and applies one in-block Hadamard-modulated low-rank branch to each diagonal block to yield broader coverage of pretrained spectral directions under a smaller parameter budget, thereby improving average performance across multiple tasks over LoRA and competitive LoRA-style baselines in lower-budget settings.
Key Contributions
- SMoA addresses the representational capacity versus computational cost trade-off in parameter-efficient fine-tuning by expanding the accessible family of spectrum-aware updates under a reduced parameter budget.
- The method partitions neural network layers into multiple aligned spectral blocks and applies an in-block Hadamard-modulated low-rank branch to each diagonal block. This design enables structured rank accumulation and broader coverage of pretrained spectral directions.
- Theoretical analysis and empirical evaluations across multiple tasks demonstrate that SMoA improves average performance in lower-budget settings over standard LoRA and competitive LoRA-style baselines.
Introduction
Fine-tuning large language models is critical for adapting to specialized applications, but full-parameter updates are computationally prohibitive. Parameter-efficient fine-tuning solves this by restricting training to a small parameter subset, enabling scalable and cost-effective model customization. Low-rank adaptation has become the standard approach due to its minimal memory overhead and zero inference latency. However, standard methods restrict weight updates to a single global low-rank matrix, confining adaptation to a narrow set of spectral directions. Since pretrained transformer weights contain functionally relevant information in their spectral tails, this rank constraint leaves valuable signal unmodeled and limits performance on complex reasoning tasks. The authors leverage a spectrum-aware design to overcome this bottleneck by introducing the Spectrum Modulation Adapter. SMoA partitions input and output dimensions into aligned spectral blocks and applies Hadamard-modulated low-rank updates to each diagonal block, distributing the parameter budget across multiple local subspaces. This construction yields a strictly higher rank ceiling than standard low-rank adaptation and demonstrates superior performance across diverse benchmarks under tight parameter constraints.
Dataset
Dataset Composition and Sources The authors assemble a multi-task evaluation suite spanning commonsense reasoning, dialogue generation, and mathematical reasoning. All subsets are drawn from established academic benchmarks and publicly available corpora.
Subset Details
- BoolQ: Wikipedia passages paired with naturally occurring yes or no questions to measure semantic understanding.
- PIQA: Focuses on physical interaction and everyday object knowledge through goal-oriented questions.
- SIQA: Evaluates social interaction comprehension and human intention prediction in everyday scenarios.
- ARC-c and ARC-e: Grade-school science questions requiring nontrivial reasoning and simpler factual knowledge, respectively.
- OBQA: Multiple-choice science questions that combine open-book facts with commonsense inference.
- HellaSwag: Tests the ability to predict realistic next events in everyday contexts.
- WinoGrande: Large-scale pronoun resolution tasks that rely on contextual and commonsense cues.
- ConvAI2: Persona-based open-domain dialogue dataset used to generate coherent and engaging responses.
- GSM8K: Standard benchmark for mathematical reasoning evaluation.
- MetaMath: Sourced specifically for mathematical task training. Note: Specific dataset sizes and exact statistics are referenced in the original paper Table 8 and are not provided in the excerpts.
Training and Evaluation Strategy The authors use these datasets to benchmark model capabilities across the three target domains. For mathematical reasoning, they follow a standard protocol where training is conducted on MetaMath while evaluation is performed on GSM8K. The remaining benchmarks function as direct evaluation sets without specified mixture ratios or custom splits.
Processing and Preparation The provided excerpts do not outline custom cropping strategies, metadata construction, or advanced filtering rules. The authors rely on the standard formatting and preprocessing conventions inherent to each benchmark. Detailed preparation steps and dataset statistics are directed to the original Table 8.
Method
The authors propose SMoA, a parameter-efficient fine-tuning method designed to enhance the representational capacity of low-rank adaptation techniques under a constrained parameter budget. The core motivation stems from the observation that pretrained transformer weight matrices exhibit long-tailed singular value spectra, indicating that informative directions extend into the spectral tail rather than being confined to a few leading singular values. This suggests that restricting updates to a low-rank subspace, as in standard LoRA, may under-model task-relevant information.
The SMoA architecture operates by partitioning the frozen weight matrix into multiple aligned spectral blocks and applying a localized, Hadamard-modulated low-rank update to each block. The framework proceeds in three main steps, as illustrated in the figure below. First, the coordinates of the frozen weight matrix W0 are reordered once according to its spectral structure. This is achieved by computing the singular value decomposition W0=UΣV⊤ and using the resulting singular vectors to define permutation matrices Pout and Pin that reorder the output and input dimensions, respectively. This reordering groups coordinates with similar spectral roles into contiguous intervals, resulting in a reordered matrix W0=PoutW0Pin⊤.

The second step involves identifying K aligned diagonal blocks from this reordered matrix, referred to as the block anchors Mk. These anchors are fixed and not updated during fine-tuning. The third step distributes the total rank budget r across these K blocks, defining a local rank of ρ=r/K for each. A learnable low-rank factorization Ak∈Rρ×din/K and Bk∈Rdout/K×ρ is attached to each anchor Mk, and the local update is constructed as ΔMk=(BkAk)⊙Mk, where ⊙ denotes the Hadamard product. These local updates are assembled into a block-diagonal matrix ΔW, which is then scattered back to the original coordinate system via the inverse permutations to yield the final update ΔW=Pout⊤ΔWPin. The trainable parameters are therefore the Ak and Bk factors for all K blocks.
This block-diagonal structure in the reordered coordinates is fundamental to SMoA's theoretical advantages. Compared to a standard rank-r LoRA layer, SMoA uses a fraction 1/K of the trainable parameters while achieving a strictly larger analytic rank ceiling. This is because the rank of the update on each block k is bounded by min(sk,ρ⋅rank(Mk)), where sk is the block size, and the total rank of the full update is the sum of the ranks of these blocks. This sum, U, is provably greater than r, the maximum rank achievable by standard LoRA. This structural separation means that SMoA can represent certain block-aligned target updates that are outside the expressivity of standard LoRA, leading to a zero approximation error for such targets, whereas LoRA incurs a non-zero spectral-tail residual error.
Experiment
The evaluation spans commonsense reasoning, dialogue generation, and mathematical reasoning across Llama-2 and Llama-3 models, benchmarking SMoA against established parameter-efficient fine-tuning methods. Performance tests demonstrate that SMoA consistently achieves superior or competitive results while maintaining a highly favorable parameter efficiency, indicating its robustness across diverse task complexities. Spectral and ablation analyses reveal that the method’s success stems from selectively amplifying underutilized tail singular directions rather than uniformly updating dominant pretrained weights, with rank and block configuration studies further confirming that strategic spectral reallocation enhances model expressiveness. Collectively, these findings validate SMoA as a structured adaptation approach that effectively balances computational efficiency with strong generalization capabilities.
The authors conduct experiments on multiple task families including commonsense reasoning, dialogue generation, and mathematical reasoning, comparing SMoA with various PEFT methods. Results show that SMoA achieves competitive or superior performance across different tasks and model scales, particularly excelling in tasks that benefit from structured adaptation and maintaining a favorable balance between accuracy and parameter efficiency. The method demonstrates consistent improvements in dialogue generation and mathematical reasoning, with performance gains attributed to its ability to adapt to underutilized spectral directions. SMoA achieves competitive performance across diverse tasks and model scales while maintaining parameter efficiency. SMoA shows consistent improvements in dialogue generation and mathematical reasoning compared to baseline methods. The effectiveness of SMoA is attributed to its ability to adapt to underutilized spectral directions, leading to better performance with fewer trainable parameters.
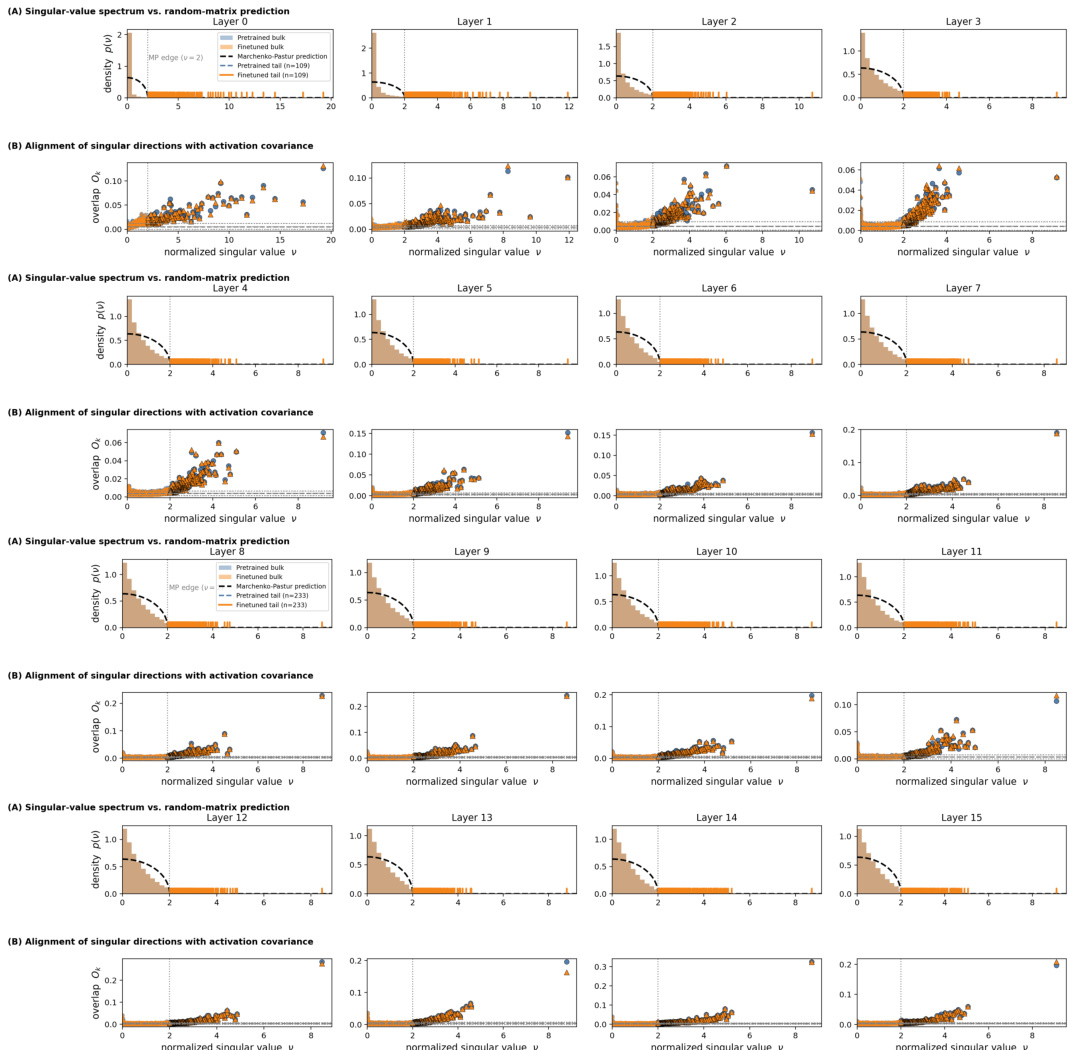
The authors analyze the spectral changes in a pretrained language model after fine-tuning with SMoA, focusing on how the singular value spectrum and alignment with activation covariance evolve across different layers. Results show a consistent shift in the spectrum toward higher singular values and increased alignment of singular directions with task-induced activation structure, particularly in the tail regions, indicating that SMoA selectively adapts underutilized directions rather than perturbing dominant ones. This structured adaptation mechanism is observed across multiple layers and supports the effectiveness of SMoA in achieving parameter-efficient fine-tuning. SMoA fine-tuning induces a right-tail shift in the singular value spectrum, indicating selective adaptation of underutilized directions rather than uniform perturbation of the pretrained model. The alignment between singular directions and activation-covariance eigenvectors increases in the intermediate and tail regions after fine-tuning, suggesting that SMoA adapts directions that are functionally relevant to the task. The spectral and alignment patterns are consistent across layers, with deeper layers showing more pronounced localization of fine-tuning signals, supporting a structured and layer-wise adaptation mechanism.
The authors evaluate SMoA against various PEFT methods across multiple tasks, including commonsense reasoning, dialogue generation, and mathematical reasoning. Results show that SMoA achieves the highest average performance on most benchmarks, particularly in dialogue generation and commonsense reasoning, while maintaining a favorable balance between accuracy and parameter efficiency. The analysis highlights that SMoA's effectiveness stems from its ability to adapt underutilized tail spectral directions, which are distributed across attention projections and contribute significantly to task-specific performance. SMoA achieves the highest average performance on most tasks compared to other PEFT methods, particularly in dialogue generation and commonsense reasoning. The performance of SMoA is attributed to its ability to adapt tail spectral directions, which are distributed across attention projections and contribute significantly to task-specific performance. SMoA maintains a favorable balance between accuracy and parameter efficiency, outperforming methods with similar or higher parameter budgets.
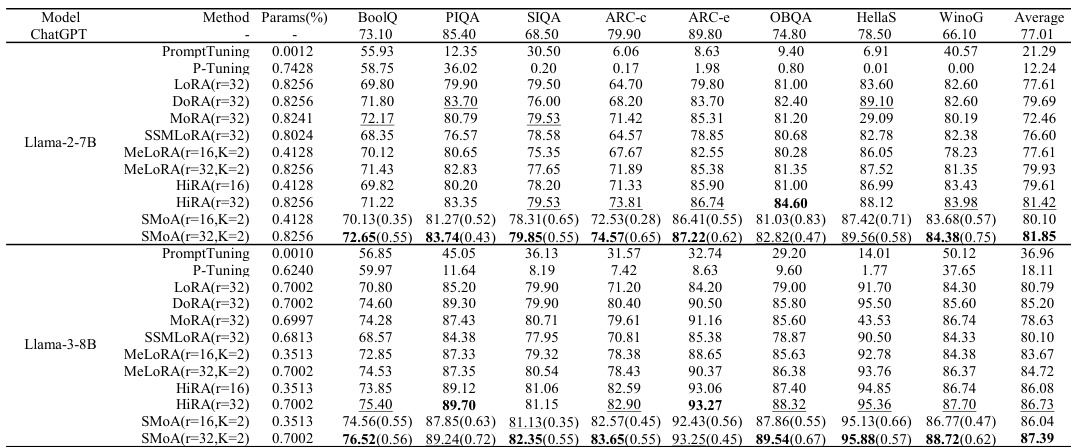
The authors compare SMoA with various PEFT methods across multiple tasks, including commonsense reasoning, dialogue generation, and mathematical reasoning. Results show that SMoA achieves the highest average performance on most benchmarks, particularly with a specific configuration, and demonstrates consistent improvements over baselines. The method is effective even under parameter-efficient settings and maintains a favorable balance between performance and parameter efficiency. SMoA's success is attributed to its ability to adapt informative tail-spectrum directions, which are selectively activated during fine-tuning. SMoA achieves the highest average performance on most benchmarks compared to other PEFT methods. SMoA demonstrates consistent improvements over baselines across different tasks and model scales. The method is effective even with a smaller parameter budget, maintaining a favorable accuracy-efficiency trade-off.
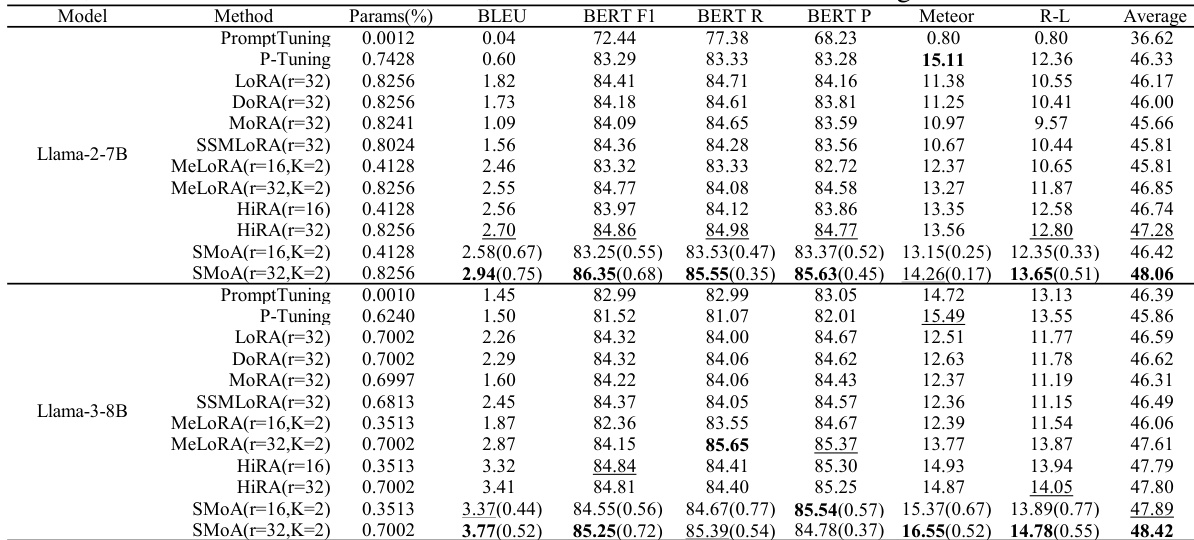
The authors compare SMoA with various PEFT methods on the CONVAI2 dataset, evaluating performance using multiple automatic metrics. Results show that SMoA achieves the highest average score, outperforming baselines across most metrics, indicating its effectiveness in dialogue generation tasks. The improvement is consistent across different parameter budgets and model sizes. SMoA achieves the highest average score on the CONVAI2 dataset, outperforming all compared PEFT methods. SMoA consistently outperforms baselines across multiple automatic evaluation metrics, including BLEU, METEOR, and ROUGE-L. The performance advantage of SMoA is observed under different parameter budgets and across different model sizes.
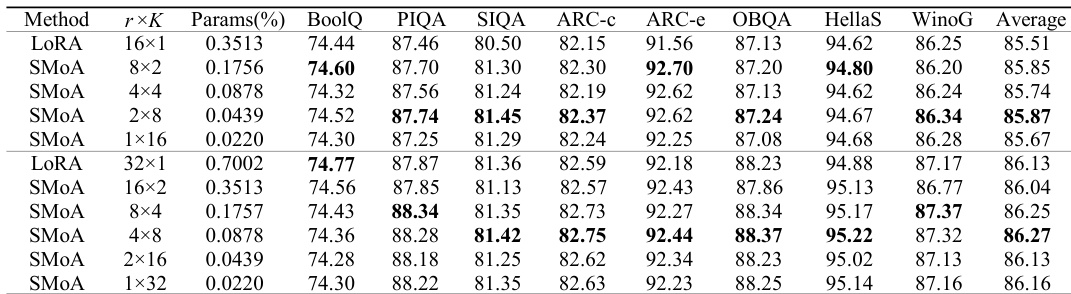
The evaluation compares SMoA against multiple parameter-efficient fine-tuning baselines across diverse task families, including commonsense reasoning, dialogue generation, and mathematical reasoning, while varying model scales and parameter budgets. A dedicated spectral analysis further validates how the method modifies pretrained representations by tracking singular value shifts and activation alignment across network layers. Collectively, these experiments demonstrate that SMoA consistently delivers superior or highly competitive performance with a favorable accuracy-efficiency trade-off. Qualitatively, the method achieves these gains through a structured adaptation mechanism that selectively tunes underutilized tail spectral directions, preserving core pretrained knowledge while effectively capturing task-specific signals.