Command Palette
Search for a command to run...
SkillsVote: コレクション、レコメンデーションから進化に至るまでのエージェントスキルのライフサイクルガバナンス
SkillsVote: コレクション、レコメンデーションから進化に至るまでのエージェントスキルのライフサイクルガバナンス
Hongyi Liu Haoyan Yang Tao Jiang Bo Tang Feiyu Xiong Zhiyu Li
概要
タイトル:(空)抄録:長期ホライズンを持つLLMエージェントは、再利用可能な経験となり得る痕跡を残すが、生データ(raw)の軌跡はノイズが多く、管理が困難である。我々は、実行可能なスクリプトと、手順に関する非実行型のガイダンスを結合した経験スキーマとして「エージェントスキル」を位置づける。しかし、オープンなスキルエコシステムには冗長性、不均一性、環境依存性の高いアーティファクトが含まれており、無差別な更新は将来のコンテキストを汚染する可能性がある。本稿では、収集、推薦、進化を含むライフサイクル全体を管理するエージェントスキルのガバナンスフレームワーク「SkillsVote」を提示する。SkillsVoteは、環境要件、品質、検証可能性について百万規模のオープンソースコーパスをプロファイリングし、検証可能なスキル用のタスクを合成する。実行前に、SkillsVoteは構造化されたスキルライブラリに対してエージェントによるライブラリ検索を実行し、指示付きスキルのコンテキストを露出させる。実行後、SkillsVoteは軌跡をスキル関連のサブタスクに分解し、結果をスキルの使用、エージェントの探索、環境、結果シグナルに帰属させ、成功した再利用可能な発見のみを証拠に基づく更新(evidence-gated updates)として認める。評価結果、オフライン進化によりGPT-5.2はTerminal-Bench 2.0で最大7.9ポイント向上し、オンライン進化によりSWE-Bench Proで最大2.6ポイント向上した。全体として、曝露、帰属、保持をシステムが制御する管理された外部スキルライブラリは、モデル更新なしで凍結されたエージェントの性能を向上させることができる。
One-sentence Summary
SKILLSVOTE governs the lifecycle of agent skills by coupling executable scripts with procedural guidance, applying evidence-gated updates after decomposing execution trajectories and attributing outcomes, and filtering reusable experiences through million-scale corpus profiling and pre-execution library searches, ultimately improving frozen LLM agents by up to 7.9 percentage points on Terminal-Bench 2.0 with GPT-5.2 and 2.6 percentage points on SWE-Bench Pro without model updates.
Key Contributions
- SKILLSVOTE is a lifecycle-governance framework that structures reusable Agent Skills by coupling executable scripts with procedural guidance. The system profiles a million-scale open-source corpus to assess environmental requirements and quality, then employs a task-conditioned agentic library search to expose only relevant skills and usage instructions prior to execution.
- Post-execution trajectories are decomposed into skill-linked subtasks to attribute outcomes to specific skill applications, agent exploration, or environmental factors. An evidence-gated update policy filters noisy traces and admits only successful, reusable discoveries into the persistent skill library.
- Evaluations on Terminal-Bench 2.0 and SWE-Bench Pro demonstrate that offline evolution improves GPT-5.2 performance by up to 7.9 percentage points, while online evolution increases SWE-Bench Pro scores by up to 2.6 percentage points. These results confirm that governed external skill libraries enhance frozen agents without requiring model parameter updates.
Introduction
Recent advances in LLM agents have shifted focus toward long-horizon tasks that require interacting with complex environments like codebases and web applications. These scenarios generate rich trajectories where reusing past experience becomes essential for efficiency. However, raw execution traces are often too noisy and context-dependent to serve as reliable knowledge bases. While prior work introduced agent skills to structure this experience, scaling these libraries introduces significant challenges. Ecosystems suffer from redundancy, inconsistent quality, and safety risks. Furthermore, existing retrieval methods often rely on static metadata, missing critical details, and evolution mechanisms frequently misattribute outcomes, allowing spurious or environment-dependent failures to pollute the skill repository.
The authors introduce SKILLSVOTE, a lifecycle framework that treats agent skills as governed, versionable artifacts managed through a closed loop of recommendation, attribution, and evolution. The system profiles a million-scale open-source skill corpus and employs agentic search to dynamically recommend a compact set of relevant skills before execution, rather than relying on shallow metadata matching. After a task completes, SKILLSVOTE performs granular outcome attribution by decomposing trajectories into skill-linked subtasks to determine whether success or failure stems from the skill itself, the agent's exploration, or external factors. This attribution layer gates library updates, ensuring only verified, reusable discoveries are admitted while filtering out noise. Experiments demonstrate that this controlled evolution improves agent performance on benchmarks like Terminal-Bench 2.0 and SWE-Bench Pro without requiring model parameter updates.
Dataset

-
Dataset Composition and Sources The authors construct the SKILLSVOTE dataset, a million-scale corpus of open-source agent skills aggregated from GitHub through ecosystems like SkillsMP and skills.sh. Each skill is treated as a directory-level package containing a required SKILL.md file that defines capabilities and usage conditions, alongside optional directories for executable scripts, references, and assets.
-
Subset Details and Filtering Rules The raw corpus is profiled across three dimensions: runtime requirements, quality metrics, and verifiability. Skills that pass the verifiability profile are synthesized into benchmark tasks featuring clear instructions, reproducible environments, and executable verifiers in the Harbor task format. Skills identified as preference-driven, open-world, or hardware-intensive remain as profiled corpus items but are excluded from forced benchmark conversion.
-
Data Usage and Processing The authors run agent-model combinations on the synthesized tasks using prebuilt experiment images derived from Harbor dataset images. This prebuild process fixes agent CLI versions, specifically nv0.40.4, Node.js 22, and Codex CLI 0.125.0, to eliminate runtime installation delays and ensure version consistency. Execution traces, success rates, costs, and verifier outcomes are recorded to connect static skill descriptions with observed agent behavior.
-
Metadata Construction and Artifacts The dataset includes structured attribution and evolution artifacts. Trajectories are segmented into subtasks with standalone goals, factual summaries, and reusable explorations. Each subtask is annotated with a judgment signal type, such as environment or human, and an attribution label categorizing outcomes like success_skill_used_with_extra_exploration or fail_skill_issue. Metadata tracks skill influence via linked skill names and precise knowledge spans defined by file paths and line numbers. Evolution artifacts document edit and create requests with rationales and action summaries, ensuring modifications are grounded in exploration and adhere to constraints like local replacement.
Method
The SKILLSVOTE framework operates as a lifecycle-governance system for Agent Skills, integrating collection, recommendation, execution, and evolution stages to manage open skill ecosystems. The overall architecture is structured around a three-stage pipeline: pre-task recommendation, in-task execution, and post-task attribution and evolution. At the core, the system maintains a structured skill library, which serves as the foundation for both recommendation and evolution. Before execution, the recommendation stage selects a curated set of skills relevant to the task, ensuring the solver agent operates within a constrained and meaningful context. After execution, the system decomposes the agent's trajectory into semantically coherent subtasks, attributes outcomes to skill use, exploration, and environment, and then applies controlled updates to the skill library based on verified reusable discoveries. This lifecycle approach ensures that external skill libraries can be safely evolved without model updates, provided exposure, credit, and preservation are properly governed.
The pre-task recommendation stage begins by filtering a large corpus of open-source skills based on environment requirements, quality, and verifiability. This profiled skill library enables a targeted search for relevant skills before execution. As shown in the framework diagram, the agent receives a set of skills and usage guidance, which are derived from a structured skill library. The recommendation process involves parsing the task instruction, breaking it into core capabilities, and searching for candidate skills using filesystem tools like grep and glob. The system prioritizes skills with direct evidence of capability in their SKILL.md files, avoiding reliance on directory names or descriptions alone. After identifying relevant skills, the system generates concise usage guidance that explains how the selected skills cover specific task stages, their combination, and any coverage gaps, without completing the task or copying skill content. This guidance is appended to the task instruction, ensuring the solver agent receives only the necessary context. The recommendation stage runs before the solver agent starts, as it controls which skills are installed into the agent's visible directory and modifies the task instruction accordingly.
Following the recommendation, the solver agent executes the task within a controlled environment. The agent's trajectory, including all actions, observations, and feedback, is recorded as a sequence of steps. After the trial ends, the attribution stage processes this complete trajectory to distill it into structured subtasks. This stage does not simply compress the session into text; instead, it resumes the original agent session to preserve contextual details, which is critical for maintaining chain-of-thought integrity. The system identifies subtasks based on changes in outcome evidence, responsibility assignment, or reusable delta. Each subtask is a semantically complete unit with a standalone objective, a primary evaluation signal, and at most one associated skill context. The attribution process evaluates whether the subtask outcome can be assessed by objective environment feedback, depends on human preference, or lacks an explicit signal. Responsibility is assigned to skill-guided execution, independent exploration, or exploration after observing an irrelevant skill. For skill-related subtasks, the system localizes the portions of skill knowledge that actually shaped execution and extracts only reusable discoveries, such as missing procedures or recovery patterns, while discarding trial-and-error and task-specific constants.
The resulting evolvable units are then processed by the controlled evolution stage. This stage first applies admissibility filters, allowing only successful subtasks with reusable exploration to proceed. Failed or uncertain subtasks are retained for diagnosis but do not directly authorize updates. Admissible units are aggregated into groups based on shared reusable procedures, preconditions, or corrections, ensuring repeated observations strengthen a single change rather than producing fragmented edits. Each aggregated group is then routed to an update action. If the evidence extends a skill that shaped execution, the system edits that skill through the smallest justified change—fixing incorrect guidance, adding missing knowledge, or tightening prerequisites. If the evidence reflects a new, independent capability outside the current skill boundary, the system creates a new skill. When evidence is weak or semantically misaligned, the system skips evolution. This conservative design ensures every library change is supported by attributed execution evidence, localized to the relevant skill boundary, and expressed as reusable procedural knowledge. The evolution process is guided by a structured schema that defines actions such as error fix, knowledge addition, prerequisite addition, skill creation, or skip, with strict constraints on read and write operations to isolate the evolution scope.


The framework ensures that the evolution process is both evidence-based and conservative. The system uses a unified local agent home for credentials and sessions, while each evolution request has an independent working directory to isolate the read/write scope. Before any edit, the current version of the skill is backed up. The evolution prompt for edit requests provides both an editable copy of the old skill and a new-skill creation directory, allowing the agent to make local edits or create new skills when necessary. For create requests, the system ensures that new skills are coherent, self-contained, and reusable, following a standard skill folder layout. The decision to edit or create a new skill is based on whether the exploration belongs to the same tool, workflow family, or problem type, or if it introduces a different tool, workflow, or domain. When in doubt, the system prefers creating a new skill to avoid forcing semantically unrelated knowledge into an existing one. This approach ensures that the skill library evolves in a controlled and meaningful way, preserving the integrity of the agent's knowledge base.
Experiment
The evaluation assesses SKILLSVOTE across Terminal-Bench 2.0 and SWE-Bench Pro using GPT-based backbones to validate three core lifecycle stages: offline evolution, online evolution, and task-conditioned recommendation. Offline evolution successfully distills historical trajectories into a frozen library that transfers reusable procedural knowledge to unseen tasks, while online evolution demonstrates the system's capacity to continuously accumulate experience throughout sequential workflows. Task-conditioned recommendation serves as a critical filter that prevents negative transfer by exposing only relevant skills, thereby complementing the evolution process. Ultimately, the experiments confirm that integrating procedural skill accumulation with intelligent exposure mechanisms significantly enhances agent performance across diverse software engineering and terminal environments.
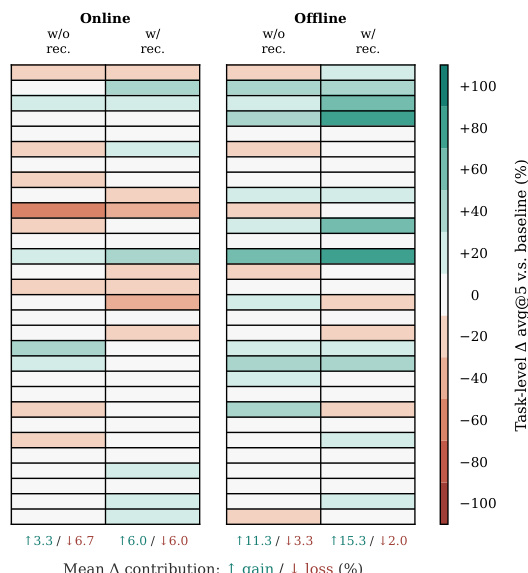
The authors evaluate SKILLSVOTE on Terminal-Bench 2.0, comparing offline and online evolution settings with a no-skill baseline. Results show that offline evolution yields significant improvements across all difficulty levels, while online evolution provides smaller but positive gains, particularly on medium and hard tasks. The use of task-conditioned recommendation enhances performance by mitigating negative transfer from irrelevant skills. Offline evolution consistently improves performance across all difficulty levels compared to the baseline. Online evolution provides smaller but positive gains, with the largest improvements observed on medium and hard tasks. Task-conditioned recommendation reduces negative transfer and enhances the overall effectiveness of skill exposure.
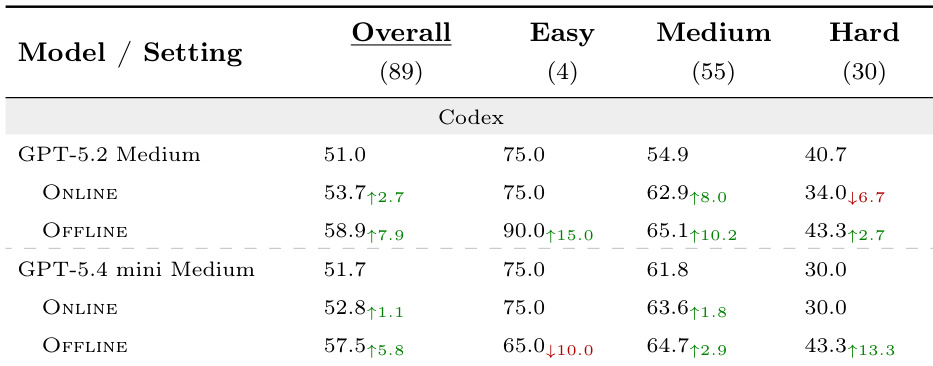
The authors evaluate SKILLSVOTE on two benchmarks, showing that both offline and online evolution improve performance across different task types. Results indicate that skill recommendation enhances the utility of the library by filtering out harmful or irrelevant skills, leading to more consistent gains. Offline evolution transfers skills from historical trajectories to unseen tasks, improving performance on both benchmarks. Online evolution yields smaller but positive gains, with recommendation helping to mitigate negative transfer from poorly matched skills. Task-conditioned recommendation improves the balance of skill exposure, reducing harmful effects and enhancing overall performance.
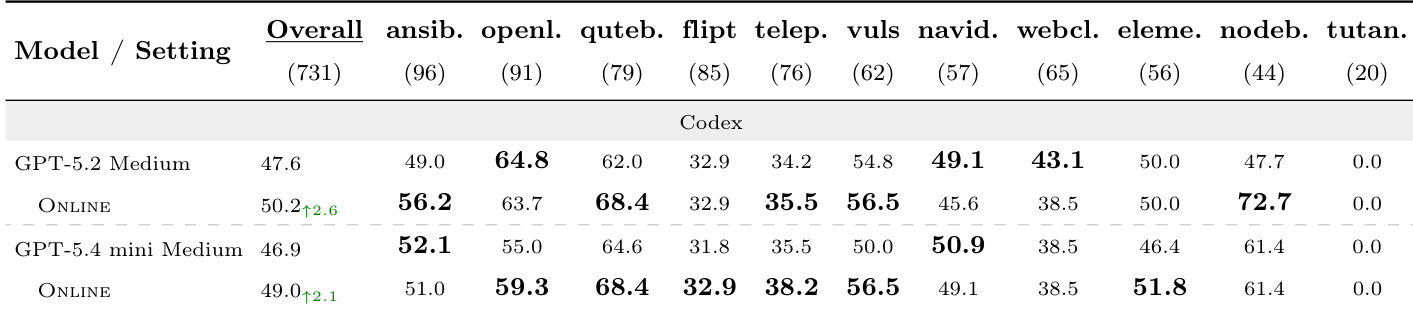
The authors analyze the impact of recommendation on skill library performance in both online and offline settings, showing that recommendation mitigates negative transfer by filtering harmful skill exposure. Results indicate that offline evolution produces a more effective skill library than online evolution, and that recommendation enhances the utility of both types of libraries by improving the balance between positive and negative task-level contributions. Recommendation reduces negative transfer by filtering harmful skill exposure in both online and offline settings. Offline evolution produces a more effective skill library than online evolution, as evidenced by stronger gains in the offline setting. Recommendation improves the balance between positive and negative task-level contributions, enhancing overall library utility.
The authors evaluate SKILLSVOTE across multiple benchmarks by comparing offline and online evolution strategies against a no-skill baseline. Results indicate that offline evolution consistently yields stronger performance gains across all difficulty levels by effectively transferring historical skills to unseen tasks, whereas online evolution provides more modest but reliable improvements, particularly on complex tasks. The integration of task-conditioned recommendation further validates its capacity to filter out irrelevant or harmful skills, effectively mitigating negative transfer and balancing task-level contributions in both settings. Overall, the experiments demonstrate that evolutionary skill exposure combined with targeted recommendation significantly enhances model performance and library utility.