Command Palette
Search for a command to run...
価値モデルの復活:LLM強化学習における価値モデル化のための生成批評
価値モデルの復活:LLM強化学習における価値モデル化のための生成批評
Zikang Shan Han Zhong Liwei Wang Li Zhao
概要
強化学習(RL)における中心的な課題の一つは、信用配分(Credit assignment)である。古典的なActor-Critic手法は、学習された価値関数に基づくきめ細かいアドバンテージ推定によってこの課題に対処している。しかし、従来の判別型Criticsは信頼性の高い学習が困難であるため、現代の大規模言語モデル(LLM)を用いた強化学習では、学習済み価値モデルの使用が避けられる傾向にある。我々は価値モデリングを再考し、この困難さが部分的には表現力の限界に起因していると考えている。特に、表現複雑性理論(Representation complexity theory)の観点から、既存の価値モデルが用いる一発予測(one-shot prediction)パラダイム下では、価値関数の近似が困難であり得ることが示唆される。また、スケーリング実験の結果、こうしたCriticsは規模の拡大とともに信頼性を持って性能向上しないことを示した。この観察にもとづき、我々はジェネラティブ・アクター・クリティック(Generative Actor-Critic, GenAC)を提案する。GenACは、一発のスカラー価値予測に代わり、価値推定を行う前にチェーン・オブ・トート(chain-of-thought)推論を実行するジェネラティブ・クリックを採用する。さらに、トレーニング全体を通じてCriticsが現在のActorに対して適切に較正(calibrated)された状態を維持することを支援する、コンテキスト内条件付け(In-Context Conditioning)を導入する。GenACは、価値近似の精度、ランキングの信頼性、および分布外(out-of-distribution)における汎化性能を向上させる。これらの改善は、価値ベース(value-based)およびフリーベース(value-free)のベースラインと比較して、より強力な下流の強化学習性能につながることが示された。
One-sentence Summary
To address the unreliability of conventional discriminative critics in large language model reinforcement learning, the authors propose Generative Actor-Critic (GenAC), which replaces one-shot scalar value prediction with a generative critic performing chain-of-thought reasoning and incorporates In-Context Conditioning to help the critic remain calibrated to the current actor, thereby improving value approximation, ranking reliability, and out-of-distribution generalization to yield stronger downstream RL performance than both value-based and value-free baselines.
Key Contributions
- The paper introduces Generative Actor-Critic (GenAC), which replaces one-shot scalar value prediction with a generative critic that performs chain-of-thought reasoning before producing a value estimate. This design addresses the limited expressiveness of conventional discriminative critics identified through representation complexity theory and scaling experiments.
- The framework introduces In-Context Conditioning to help the critic remain calibrated to the current actor throughout training. This mechanism ensures the value model remains aware of the capabilities of the evaluated policy for dynamic and accurate value estimation.
- Experiments demonstrate that GenAC improves value approximation, ranking reliability, and out-of-distribution generalization over value-based and value-free baselines. These improvements translate into stronger downstream reinforcement learning performance on mathematical reasoning tasks.
Introduction
Reinforcement learning drives large language model post-training, but effective credit assignment remains difficult when supervision is limited to final outcomes. Prior work often avoids discriminative value models due to training instability and limited expressiveness, leading practitioners to adopt value-free methods that assign uniform credit across entire sequences. The authors propose Generative Actor-Critic, which replaces one-shot scalar predictions with a generative critic that performs chain-of-thought reasoning before producing a value estimate. By introducing In-Context Conditioning to maintain calibration with the active policy, this method achieves superior value approximation and downstream performance compared to existing baselines.
Method
The authors propose a Generative Actor-Critic (GenAC) architecture designed to overcome the representation complexity constraints of standard discriminative critics. Unlike traditional approaches that replace the language modeling head with a linear projection to output a scalar value directly, the generative critic retains the original autoregressive structure. This allows the model to perform explicit chain-of-thought reasoning before producing a final value estimate. To make this output tractable for a language model, the critic is tasked with generating an integer score between 0 and 10 representing the likelihood of success, which is subsequently parsed and normalized into a value prediction between 0 and 1.
Refer to the framework diagram to visualize how this approach contrasts with value-free methods and standard PPO with discriminative critics. While value-free methods derive advantages directly from rewards and PPO uses forward passes for value predictions, GenAC utilizes intermediate reasoning steps to inform advantage estimates.
A critical component of this architecture is In-Context Conditioning (ICC). Since value functions are inherently conditioned on the policy, the critic must be aware of the specific capabilities of the active actor. Discriminative critics encode this information in their weights, but the generative critic leverages in-context learning. The authors design a specific prompt template that explicitly instructs the critic to infer the actor's capabilities from the partial response and provides metadata such as model size and the smoothed running average of the success rate.
As shown in the figure below:

This conditioning grounds the critic's reasoning, ensuring it acts as a policy-specific function approximator rather than a general one. The interaction between the actor and critic is dynamic. As the actor generates steps, the critic evaluates the progress and potential errors in real-time.
Refer to the interaction diagram to see how the critic provides feedback at different stages. For instance, after a correct prefix, the critic might assign a moderate rating based on algebraic progress. Conversely, after an error step, the critic identifies the conceptual mistake and assigns a low probability of success, effectively guiding the actor away from invalid solutions.
The training pipeline for the generative critic follows a three-stage process to ensure robustness. First, Supervised Finetuning (SFT) is performed using high-quality reasoning traces synthesized by an oracle model to instill foundational reasoning patterns. Second, RL Pretraining freezes the actor and trains the critic via REINFORCE using a rule-based reward function defined as Rv(s,z)=1−(r−v^)2, where r is the observed reward and v^ is the parsed value prediction. This grounds the reasoning in empirical returns. Finally, in the RL Joint-Training stage, the critic is integrated into the PPO loop. The actor updates using advantages computed from the critic's predictions, while the critic continuously adapts its reasoning to track the shifting value function of the evolving actor.
Experiment
Experiments evaluate Generative Actor-Critic (GenAC) against standard discriminative critics and value-free baselines on mathematical reasoning benchmarks. Controlled approximation tests reveal that discriminative critics face fundamental expressiveness barriers that model scaling cannot overcome, while the generative critic provides more accurate and stable value estimates. Consequently, GenAC achieves superior sample efficiency and sustained performance gains during reinforcement learning, validating that explicit generative reasoning improves credit assignment and generalization to out-of-distribution data.
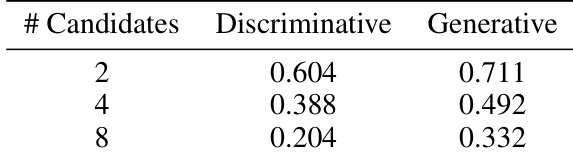
The the the table compares the top-1 ranking accuracy of discriminative and generative critics when selecting the best candidate from pools of varying sizes. The generative critic consistently outperforms the discriminative baseline across all tested pool sizes. While accuracy decreases for both methods as the number of candidates increases, the discriminative critic degrades more rapidly toward random chance levels. Generative critics achieve superior ranking accuracy compared to discriminative critics at every candidate pool size. Both models show decreased performance as the number of candidates to evaluate grows larger. The generative approach maintains a stronger advantage over the baseline as the decision space expands.
The authors evaluate the approximation performance of generative versus discriminative critics across datasets with varying degrees of distribution shift. The results show that the generative critic consistently achieves lower error rates, with the performance gap widening as the distribution shift increases from none to moderate. Generative critics consistently outperform discriminative baselines in approximation accuracy across all tested datasets. The relative improvement of the generative method becomes more substantial as the distribution shift grows more severe. The approach demonstrates robust generalization, maintaining significant error reduction even on out-of-distribution datasets with high distribution shift.

The the the table compares the performance of the proposed GenAC algorithm against three baselines across six mathematical reasoning benchmarks. GenAC achieves the highest overall average score and outperforms all other methods in the majority of individual evaluation categories. While baselines show competitive results on specific datasets, GenAC demonstrates superior consistency and final performance across the board. GenAC achieves the highest average performance and leads in most specific benchmarks. The proposed method demonstrates a clear performance hierarchy, outperforming both discriminative and value-free baselines. While baselines show strength on specific datasets like MATH500, GenAC maintains superior consistency across the evaluation suite.

The authors analyze the computational costs of GenAC compared to PPO and VinePPO, showing that GenAC incurs a moderate increase in resource usage while VinePPO is significantly more expensive. This suggests that GenAC provides a favorable trade-off between computational overhead and the performance benefits of generative value modeling. GenAC requires roughly double the computational resources of standard PPO. VinePPO is the most expensive method, costing over four times as much as the PPO baseline. The analysis indicates GenAC offers a more efficient balance than VinePPO for achieving fine-grained feedback.

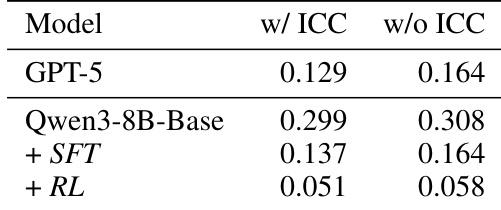
The the the table presents an ablation study on value function approximation performance, comparing models with and without In-Context Conditioning (ICC) across different training stages. Results indicate that ICC consistently lowers approximation error across all configurations, while the full training pipeline involving SFT and RL yields significantly better accuracy than base models or zero-shot prompting. In-Context Conditioning consistently reduces approximation error compared to configurations without it across all model variants. The RL-trained model achieves the lowest error, significantly outperforming the base model and zero-shot GPT-5. Zero-shot GPT-5 performs comparably to the SFT stage but fails to match the accuracy of the fully trained RL model.
The experiments evaluate generative critics against discriminative baselines across ranking accuracy, approximation performance under distribution shift, and mathematical reasoning benchmarks. Generative approaches consistently outperform discriminative methods, maintaining superior accuracy as candidate pools expand or distribution shifts become more severe. The proposed GenAC algorithm demonstrates robust generalization and consistency across tasks while maintaining a favorable computational balance, and ablation studies confirm that In-Context Conditioning combined with full reinforcement learning training significantly enhances value function approximation accuracy.