Command Palette
Search for a command to run...
先読みする学習:オンポリシー蒸留の解錠効率の解明
先読みする学習:オンポリシー蒸留の解錠効率の解明
概要
オンポリシー蒸留(On-policy distillation: OPD)は、大規模言語モデルに対する効率的なポストトレーニングのパラダイムとして台頭してきた。しかし、既存の研究はこの利点をより密で安定した教師信号に帰因しており、OPDの効率性を支えるパラメータレベルのメカニズムについては十分に解明されていない。本研究では、OPDの効率性は「先見性(foresight)」という形態に由来すると主張する。すなわち、OPDはトレーニングの初期段階において最終モデルへの安定した更新軌道確立する。この先見性は2つの側面で現れる。第一に、\textbf{モジュール配分レベル}において、OPDは限界便益が低い領域を特定し、推論にとってより重要なモジュールへの更新に集中する。第二に、\textbf{更新方向レベル}において、OPDはより強い低ランク集中性を示し、その主要な部分空間はトレーニングの初期段階において最終的な更新部分空間と密接に一致する。これらの知見に基づき、本研究ではプラグアンドプレイ可能な加速手法である\textbf{EffOPD}を提案する。EffOPDは、外挿ステップサイズを適応的に選択し、現在の更新方向に沿って移動することで、OPDの速度を向上させる。EffOPDは追加の学習可能モジュールや複雑なハイパーパラメータチューニングを必要とせず、最終的な性能を同等に維持しつつ、平均してトレーニング速度を3倍に加速する。総じて、本研究の知見はOPDの効率性を理解するためのパラメータダイナミクスの視点を提供し、大規模言語モデルのためのより効率的なポストトレーニング手法を設計するための実践的な示唆を与える。
One-sentence Summary
Grounded in the finding that on-policy distillation derives its efficiency from early foresight in module allocation and update-direction alignment, the authors propose EffOPD, a plug-and-play acceleration method that adaptively selects an extrapolation step size to follow current update trajectories, thereby achieving a 3× average training speedup for large language models without requiring additional trainable modules or complex hyperparameter tuning while maintaining comparable final performance.
Key Contributions
- The analysis demonstrates that on-policy distillation improves efficiency by establishing an early foresight that directs parameter updates along a stable trajectory toward the final model. This mechanism concentrates gradient updates on reasoning-critical modules and aligns dominant low-rank subspaces with the final update subspace early in training.
- EffOPD is proposed as a plug-and-play acceleration method that adaptively selects an extrapolation step size to advance along the current update direction. The approach eliminates the need for additional trainable modules or complex hyperparameter tuning.
- Empirical evaluations show that EffOPD achieves an average training acceleration of 3× compared to baseline on-policy distillation while maintaining comparable final performance. These results validate the extrapolation strategy for efficient large language model post-training.
Introduction
On-policy distillation has emerged as a critical post-training paradigm for large language models, delivering reasoning capabilities comparable to reinforcement learning while significantly reducing computational overhead. Existing literature primarily explains this efficiency through macroscopic optimization properties like denser supervision, leaving the underlying parameter-level dynamics and convergence mechanics largely unexplored. The authors uncover a foresight mechanism wherein the distillation process stabilizes its update trajectory early in training by suppressing low-utility modules and locking onto the final optimization subspace. Leveraging this insight, the authors propose EffOPD, a plug-and-play acceleration framework that extrapolates along these early predicted directions to achieve a threefold training speedup without introducing additional trainable modules or complex hyperparameter tuning.
Dataset

- Dataset composition and sources: The authors do not introduce or release a new dataset. Instead, they rely on existing, publicly available datasets, models, and baselines that are fully cited in the paper.
- Key details for each subset: No new subsets are constructed. The work strictly adheres to the original licensing, versioning, and terms of service for all referenced external assets.
- Data usage and training configuration: The authors follow the intended research usage of the cited datasets and baselines. The paper does not specify custom training splits, mixture ratios, or fine-tuning protocols, as the focus remains on established external resources.
- Processing and metadata strategies: No custom cropping, metadata construction, or data filtering rules are applied. The research explicitly excludes crowdsourcing and human subjects, meaning no consent procedures, IRB approvals, or specialized data curation pipelines were required.
Method
The authors leverage On-Policy Distillation (OPD) as a post-training paradigm for large language models, which inherits the on-policy training property while utilizing dense supervisory signals from a teacher model to achieve efficient optimization. The core objective of OPD is to minimize the reverse Kullback-Leibler (KL) divergence between the student model and a fixed teacher model on trajectories generated by the student itself. This is formulated as JOPD(θ)=Ex∼D,y∼πθ(⋅∣x)[DKL(πθ(y∣x)∥π∗(y∣x))], where the student policy πθ generates its own responses y. The corresponding gradient, approximated by focusing on immediate token-level optimization, provides a dense learning signal at every token position, enabling significantly higher training efficiency compared to Reinforcement Learning from Verifiable Rewards (RLVR), which suffers from sparse rewards.
The framework reveals two key properties that explain the efficiency of OPD: Functional Redundancy Avoidance and Early Low-Rank Lock-in. Functional Redundancy Avoidance, observed at the module-allocation level, indicates that OPD concentrates updates on high-utility modules. This is demonstrated through a sliding-window intervention analysis, where localized parameter updates are injected into specific layers and modules of the Transformer architecture. The analysis shows that OPD's parameter updates are highly concentrated in critical layers, such as the top attention and MLP layers, while updates to non-critical modules like embeddings and bottom layers are suppressed. 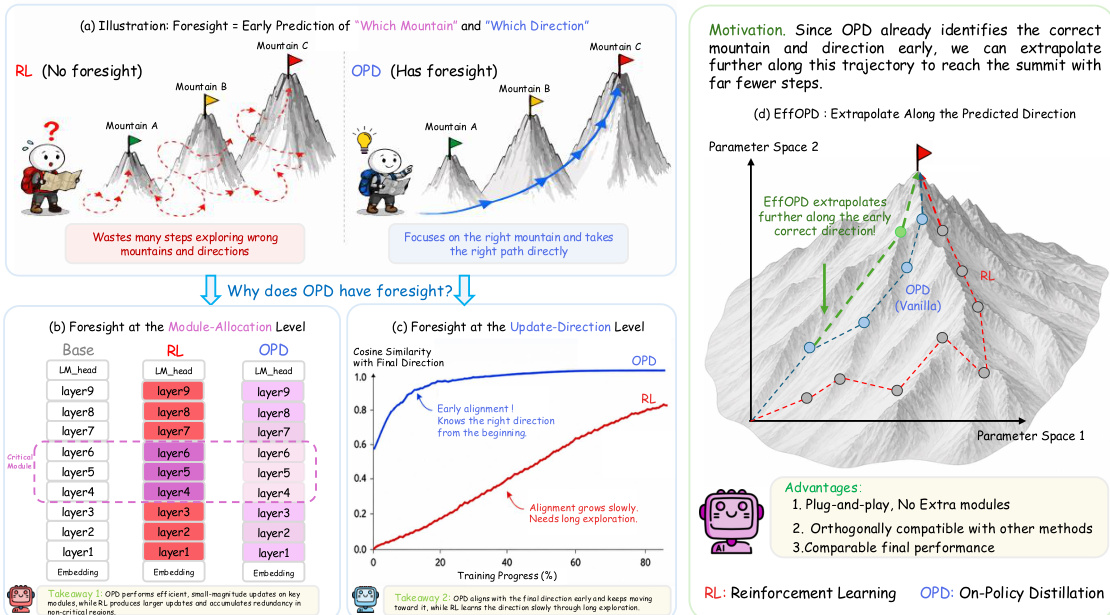
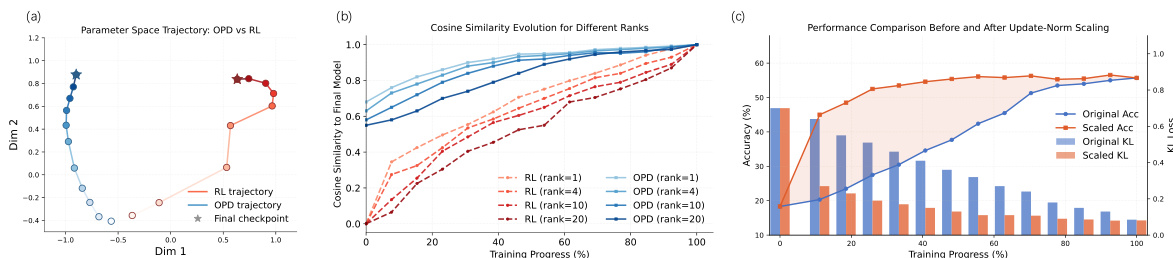
At the update-direction level, OPD exhibits Early Low-Rank Lock-in, meaning its parameter update direction stabilizes early in the training process. This is analyzed through the geometric properties of the update matrix ΔW. The authors employ four metrics: Spectral Norm, Spectral-to-Frobenius Norm Ratio, Effective Rank, and Top-1% Subspace Norm Ratio, to characterize the low-rank structure of the update. The analysis reveals that OPD's updates are highly concentrated along a single dominant direction, resulting in a low effective rank and a high Top-1% subspace norm ratio, in contrast to the more diffuse updates in RL. This early stabilization is further explained by a local geometric analysis of the OPD objective, which approximates the training dynamics as a convex quadratic minimization problem. This analysis shows that the update direction is determined by the projection of the teacher-student logit residual onto the parameter space, which is often low-rank in practice, leading to a stable and confined optimization trajectory from the early stages.
Motivated by the observation of early directional lock-in, the authors propose EffOPD, a plug-and-play acceleration framework. EffOPD exploits this stability by performing an extrapolation search at exponentially spaced checkpoints (t=2n). At each checkpoint, it estimates the local update direction Δn=W2n−W2n−1 and generates candidate parameters by extrapolating along this direction. A lightweight validation set is used to evaluate these candidates, and the best-performing one is accepted, allowing the process to accelerate while avoiding performance degradation. This mechanism enables EffOPD to achieve up to a 3x training speedup while maintaining the final performance of standard OPD.
Experiment
Across multiple model scales and reasoning benchmarks, experiments comparing on-policy distillation with reinforcement learning validate that the distillation method achieves superior parameter efficiency by concentrating updates in high-utility architectural regions while suppressing changes in peripheral layers. Spectral decomposition and training trajectory analyses further demonstrate that this approach stabilizes dominant update directions early in optimization, forming a compact low-rank structure that subsequent steps simply amplify rather than repeatedly explore. This early directional lock-in enables accelerated variants to safely extrapolate along validated pathways, yielding faster convergence and higher performance bounds. Ultimately, the method’s efficiency stems from its intrinsic ability to prioritize task-relevant update geometry and systematically avoid the redundant exploration characteristic of standard reinforcement learning.
The authors compare OPD and RL training methods, showing that OPD achieves more efficient parameter updates by concentrating changes in high-utility functional regions and avoiding redundant updates in low-utility areas. Results indicate that OPD forms stable and task-relevant update directions early in training, leading to faster convergence and higher performance with smaller update norms. The efficiency advantage stems from OPD's ability to lock into low-rank subspaces early and maintain directional stability, whereas RL exhibits more dispersed and unstable update trajectories. OPD achieves higher reasoning performance with smaller parameter updates compared to RL by concentrating changes in high-utility functional regions. OPD forms stable and task-relevant update directions early in training, leading to faster convergence and higher efficiency. OPD exhibits stronger low-rank concentration and directional stability in its update trajectories, while RL shows more dispersed and unstable evolution.
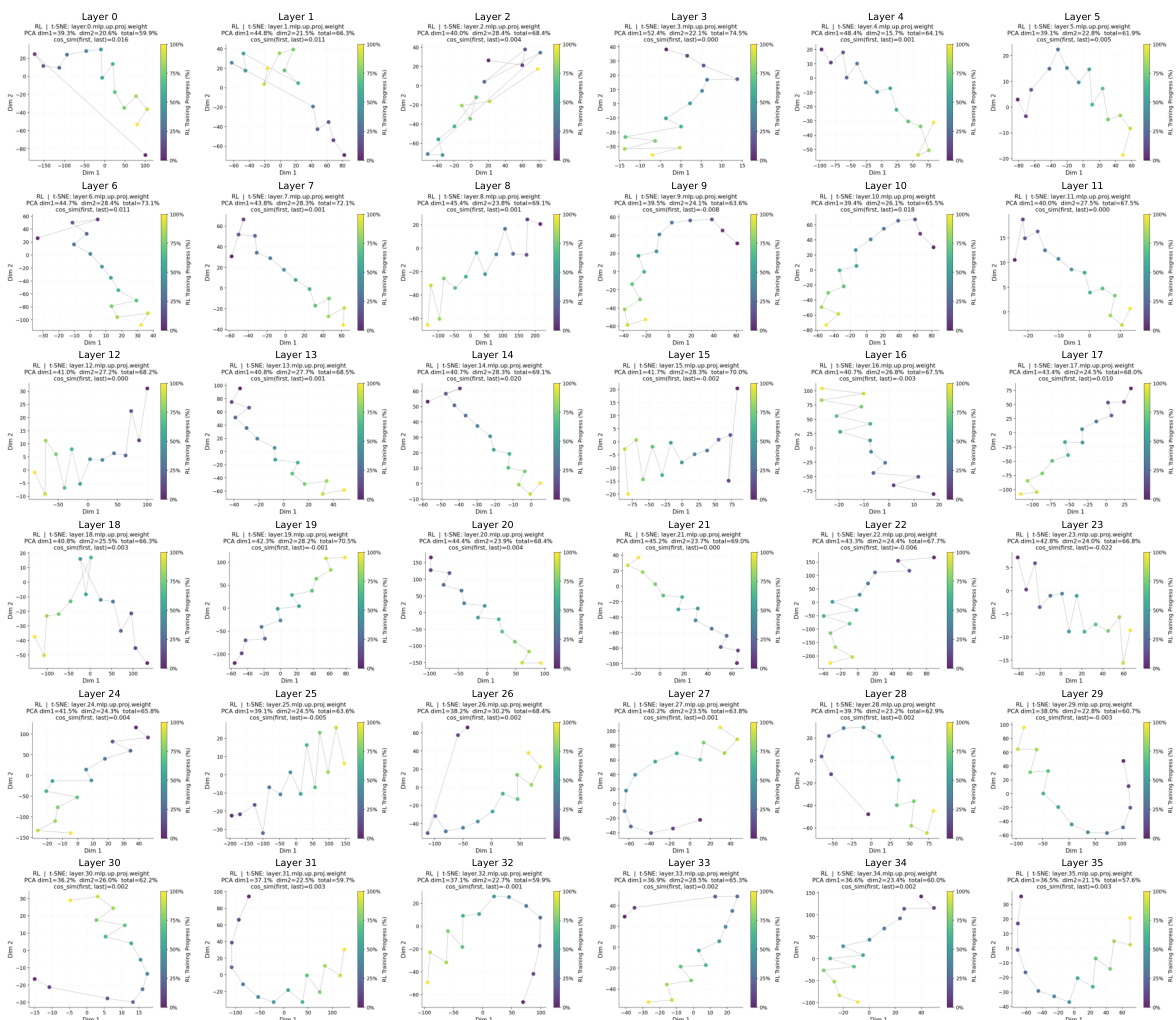
The authors compare the parameter update patterns of OPD and RL across different model layers, showing that OPD achieves higher reasoning performance with smaller parameter updates. OPD exhibits more focused and stable update directions early in training, concentrating changes in middle-layer modules with higher functional contributions while suppressing updates in low-sensitivity regions. This leads to more efficient and compact updates compared to RL, which introduces larger and less targeted changes, particularly in peripheral layers. OPD achieves higher reasoning performance with smaller parameter updates compared to RL across all model layers. OPD concentrates updates in middle-layer modules with higher functional contributions, while RL introduces larger updates in low-sensitivity peripheral layers. OPD establishes stable and task-relevant update directions early in training, leading to more efficient and compact parameter changes.
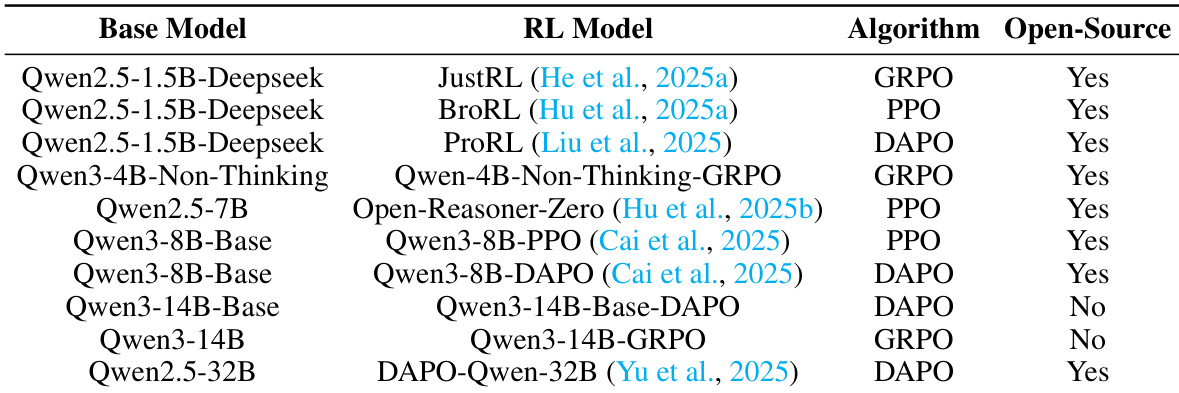
The authors compare different reinforcement learning methods and their corresponding open-source implementations, focusing on model performance and availability. The the the table lists various base models, their associated RL-trained versions, the algorithms used, and whether the models are open-source. Results indicate that while some models are open-source, others are not, with a trend toward more open-source availability for smaller models and specific algorithms like GRPO and PPO. The the the table shows a mix of open-source and non-open-source models, with open-source availability varying by model scale and algorithm. GRPO and PPO are used across multiple models, with some implementations being open-source and others not. Larger models, such as Qwen3-14B and Qwen2.5-32B, are less likely to be open-source compared to smaller models.
The authors compare different training methods for optimizing language models, focusing on efficiency and performance. Results show that the proposed method, EffOPD, achieves faster convergence and higher performance compared to other approaches, particularly in early training stages. The analysis highlights that effective parameter updates are concentrated in specific functional regions of the model, leading to more efficient learning. EffOPD converges faster and achieves higher accuracy than other methods, especially in the early training stages. Parameter updates are concentrated in specific functional regions of the model, leading to more efficient learning. The proposed method maintains high performance while using fewer training steps and resources compared to alternatives.
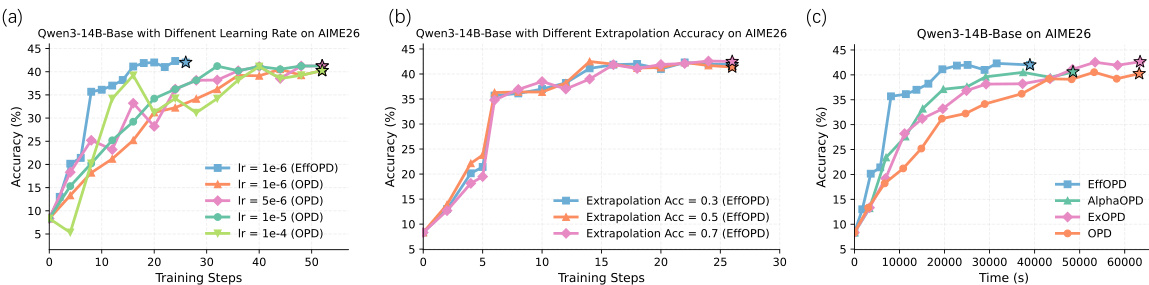
The authors compare different parameter update methods in training large models, focusing on efficiency and performance. Results show that the proposed method achieves faster convergence and higher performance with smaller parameter updates compared to baseline methods. The advantage is consistent across different model scales and tasks, indicating a generalizable efficiency improvement. The proposed method converges significantly faster than baseline methods across multiple models and tasks. The method achieves higher performance with substantially smaller parameter updates compared to baselines. The efficiency advantage is consistent across different model scales and training tasks, suggesting a generalizable improvement.
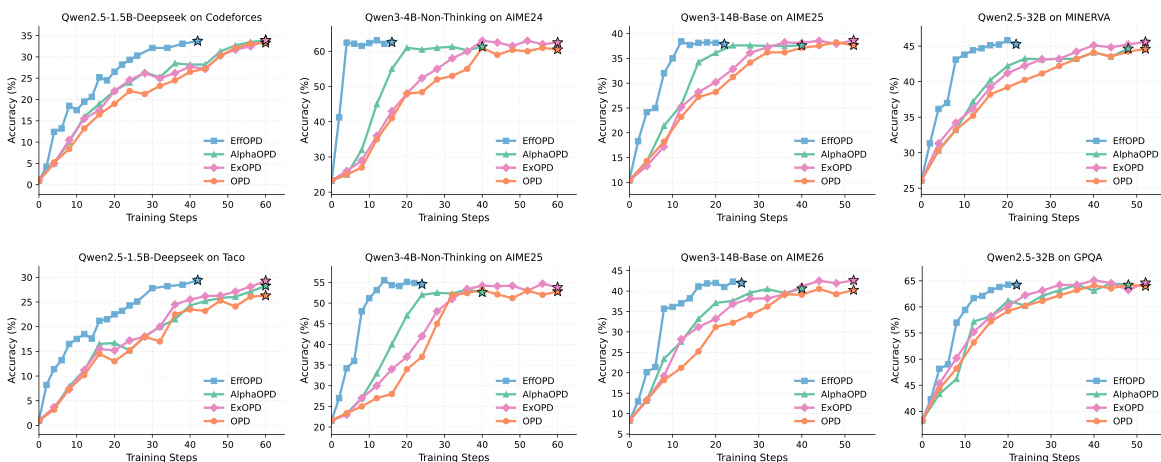
The experiments evaluate parameter update strategies across multiple model scales and tasks, comparing the proposed OPD and EffOPD methods against standard reinforcement learning baselines and existing open-source implementations. These evaluations validate that concentrating updates in high-utility functional regions and middle-layer modules generates stable, low-rank trajectories that emerge early in training. Qualitatively, the proposed approaches consistently achieve faster convergence and superior reasoning performance while requiring substantially smaller parameter modifications, contrasting with the more dispersed and unstable update patterns of conventional reinforcement learning. Furthermore, the analysis of existing implementations highlights varying open-source availability across model sizes and algorithms, underscoring the practical efficiency and broad generalizability of the proposed methods.