Command Palette
Search for a command to run...
RubricEM: 検証可能な報酬を超えたルールに基づく政策分解によるメタ強化学習
RubricEM: 検証可能な報酬を超えたルールに基づく政策分解によるメタ強化学習
概要
深層推論エージェント、すなわち計画立案、検索、証拠の評価、そして長文レポートの合成を行うシステムを学習させることは、検証可能な報酬に限定された従来の強化学習の範疇を越えるものです。これらのエージェントの出力には正解が存在せず、その行動履歴は多数のツール活用判断を含んでおり、標準的な後処理学習には過去の試行を再利用可能な経験として転用する仕組みがほとんど備わっていません。本研究では、ルーブリック(評価基準)は単なる最終回答の採点者として機能するだけでなく、ポリシー実行、判定フィードバック、エージェントの記憶を構造化する共通インターフェースとして捉えるべきだと主張します。この見地に基づき、本稿では、段階的なポリシー分解と反射(リフレクション)に基づくメタポリシー学習を組み合わせた、ルーブリック誘導型の強化学習フレームワーク「RUBRICEM」を提案します。RUBRICEMは、まず計画立案、証拠収集、レビュー、合成の各プロセスを自己生成されたルーブリックに条件付けすることで、研究プロセスを段階的に構造化し、段階認識可能な探索履歴を生成します。次に、Stage-Structured GRPOを用いて報酬のアサインメントを行い、段階的なルーブリックによる判定を通じて、長期の最適化に必要なより密度の高い意味的なフィードバックを提供します。並行して、RUBRICEMは共有バックボーンを持つ反射型メタポリシーを学習させ、判定された探索履歴を、将来の試行に向けた再利用可能なルーブリック根拠付きのガイダンスに蒸留します。その結果、RUBRICEM-8Bは4つの代表的な長文レポート生成タスクにおけるベンチマークで強力なパフォーマンスを発揮し、同等のオープンソースモデルを上回り、専有型(プロプライエタリ)の深層推論システムに迫る性能を示しました。最終的な性能評価だけでなく、RUBRICEMの鍵となる要素を解明するために綿密な分析を実施しています。
One-sentence Summary
The authors introduce RUBRICEM, a rubric-guided reinforcement learning framework combining stagewise policy decomposition with reflection-based meta-policy training to optimize deep research agents beyond verifiable rewards by employing Stage-Structured GRPO for denser semantic feedback and distilling judged trajectories into reusable guidance, enabling RUBRICEM-8B to achieve strong performance across four representative long-form research benchmarks while outperforming comparable open models and approaching proprietary deep-research systems.
Key Contributions
- This work introduces RUBRICEM, a rubric-guided reinforcement learning framework that uses rubrics as a shared interface to structure policy execution, judge feedback, and agent memory. The method makes research trajectories stage-aware by conditioning planning, evidence gathering, review, and synthesis on self-generated rubrics.
- Credit assignment relies on Stage-Structured GRPO, which leverages stagewise rubric judgments to provide denser semantic feedback for long-horizon optimization. A shared-backbone reflection meta-policy runs asynchronously to distill judged trajectories into reusable rubric-grounded guidance without imposing sequential bottlenecks.
- Experiments demonstrate that RUBRICEM-8B achieves strong performance across four representative long-form research benchmarks. The resulting system outperforms comparable open models and approaches proprietary deep-research systems in these evaluations.
Introduction
Training deep research agents requires moving beyond verifiable rewards since their long form outputs lack ground truth answers and standard post training offers little reusable experience. Prior methods rely on verifiable search proxies or imitation data, leaving a gap in handling the coarse and delayed feedback of open ended research trajectories. The authors introduce RUBRICEM, a framework that treats rubrics as a shared interface to structure policy execution and agent memory. This system combines stagewise policy decomposition with reflection based meta policy training to provide denser semantic feedback and distill reusable guidance from judged trajectories.
Dataset

-
Dataset Composition and Sources
- The authors construct a supervised fine-tuning dataset comprising approximately 11,000 samples.
- Data originates from agent trajectories generated by a Gemini teacher model and adapted for Qwen3.
- The final volume is roughly 2,000 samples smaller than the DR Tulu baseline due to rigorous filtering.
-
Filtering and Rejection Rules
- Trajectories lacking a closing
</answer>tag are discarded as a hard reject. - Samples missing valid tool calls in non-final rounds are removed to prevent reliance on internal knowledge.
- Data without required XML structures like
<structured_plan>or<state_evaluation>is excluded. - Any trajectory with two or more consecutive tool errors is rejected to ensure reliability.
- Trajectories lacking a closing
-
Processing and Training Format
- Reasoning tags are converted from
<scratchpad>to<think>for template compatibility. - Tool names are normalized to canonical identifiers such as
google_search. - Each sample is formatted as a single-turn ChatML conversation with system, user, and assistant messages.
- Tool output tokens are masked during training so the model does not memorize search results.
- Reasoning tags are converted from
-
Evaluation Benchmarks
- Performance is measured on four long-form datasets including HealthBench and ResearchQA.
- These benchmarks range from 100 to 1,000 questions covering medical and scientific research domains.
Method
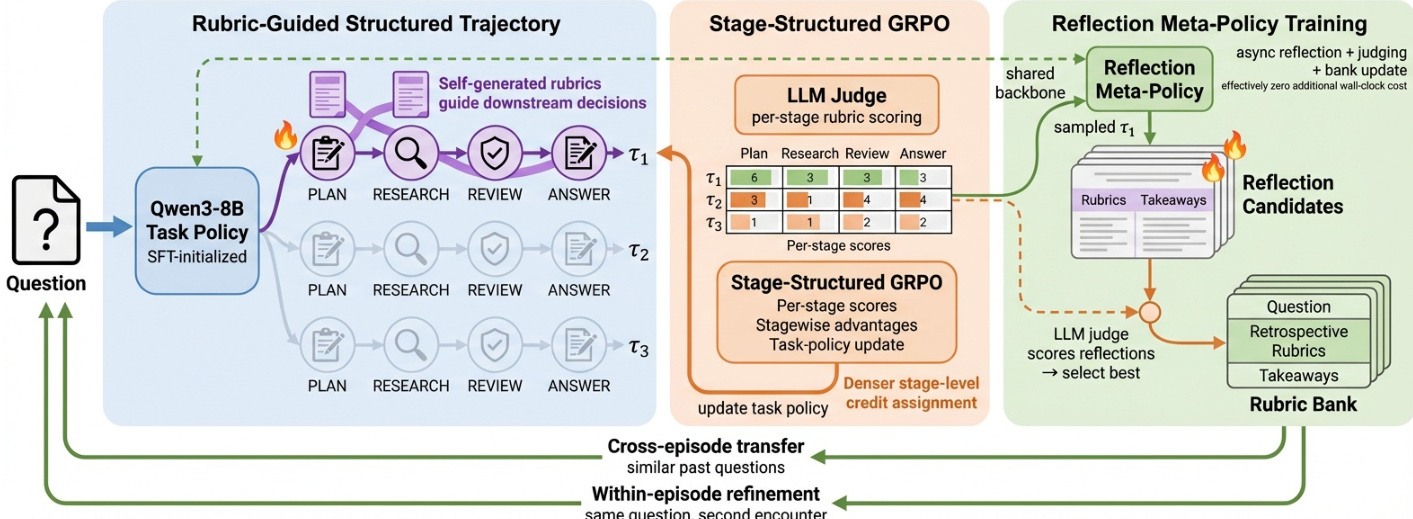
The RubricEM framework operates by treating rubrics as a shared interface across the agent's planning, execution, and learning phases. As illustrated in the framework diagram, the system integrates three core components: a rubric-guided structured trajectory for the task policy, a stage-structured reinforcement learning algorithm for credit assignment, and a reflection meta-policy for experience reuse.
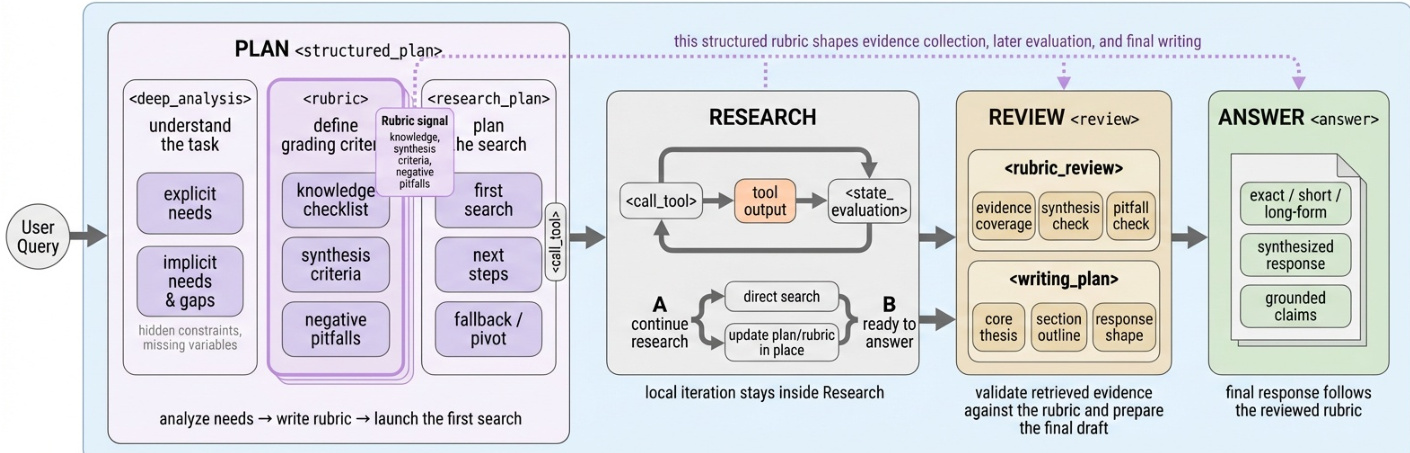
Structured Reasoning Scaffold
To manage long-horizon research tasks, the authors impose an explicit stage structure on agent trajectories. This scaffold decomposes the generation process into four semantically distinct stages: Plan, Research, Review, and Answer. Each stage is marked by XML tags and governed by specific behavioral requirements. In the planning phase, the agent generates task-specific rubrics that define the criteria for success, including a knowledge checklist and negative constraints. These rubrics then guide the subsequent research and synthesis phases. The detailed workflow shows how the agent analyzes needs, defines grading criteria, and plans the search before executing tool calls.
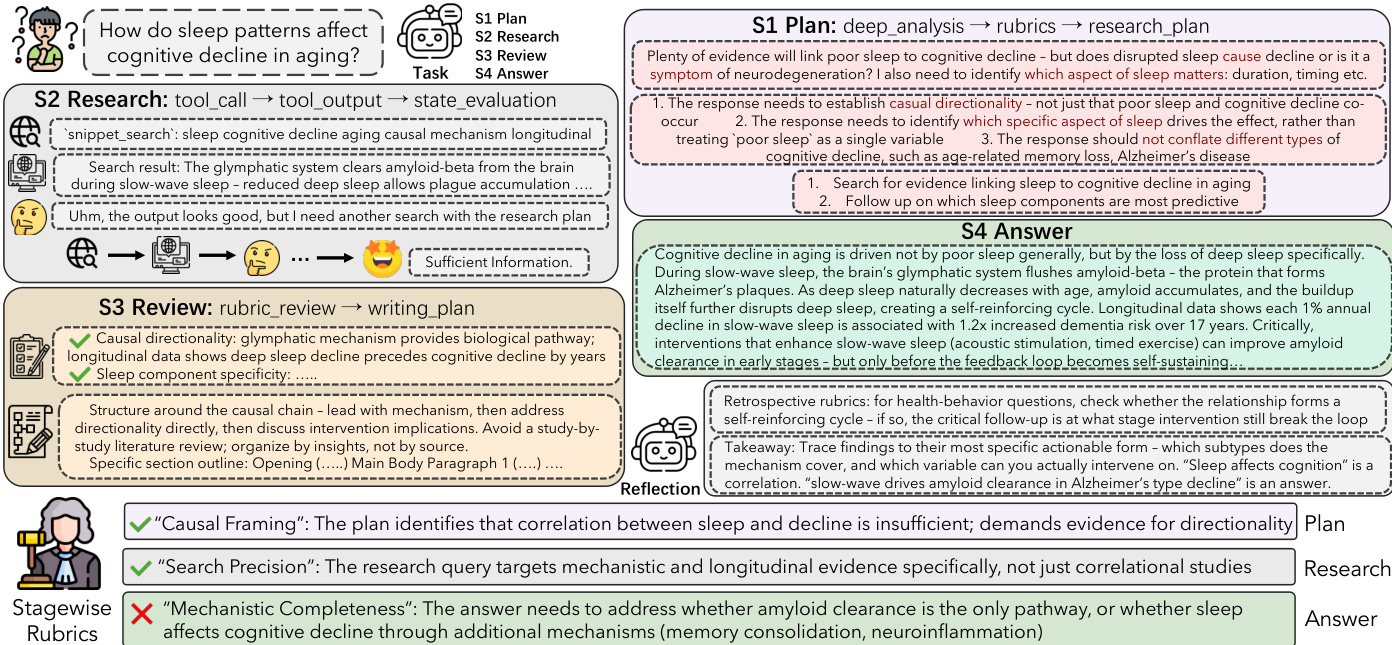
This structure allows the policy to condition its decisions on the current stage, avoiding the aliasing of decision modes that occurs in flat autoregressive processes. A concrete example demonstrates how a query about sleep patterns is broken down into these stages, with specific rubrics generated during planning to direct the research and review steps.
Stage-Structured GRPO and Meta-Policy Training
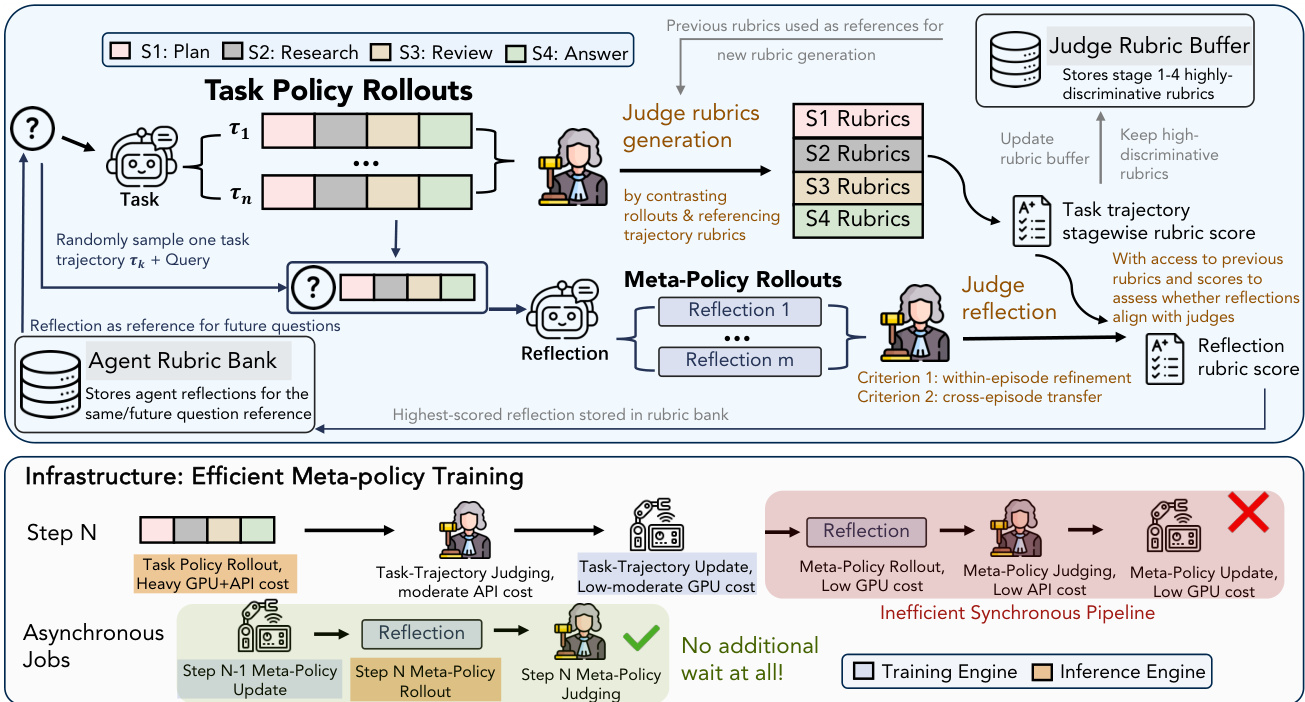
Standard reinforcement learning methods often broadcast a single terminal reward to all tokens, which is inefficient for long-horizon tasks. RubricEM employs Stage-Structured GRPO (SS-GRPO) to provide finer-grained credit assignment. Instead of a single score, the LLM judge evaluates each stage (Plan, Research, Review, Answer) against stage-specific rubrics. These stagewise scores are combined using a causal stage-dependence matrix to compute returns that account for downstream impact. The training pipeline visualizes how task rollouts are judged to generate discriminative rubrics, which are then used to score the trajectories and update the policy.
Beyond optimizing the task policy, the framework explicitly trains a reflection meta-policy to reuse experience. The task policy and reflection meta-policy share the same backbone. After a task rollout is judged, the backbone samples rubric-grounded reflection candidates. A separate judge scores these candidates based on their utility for within-episode refinement and cross-episode transfer. The highest-scoring reflection is stored in a rubric bank, serving as natural-language memory for future queries. To ensure efficiency, the system uses an asynchronous execution pipeline where reflection generation and training run in parallel with task rollouts, avoiding sequential bottlenecks. The infrastructure diagram highlights this asynchronous design, showing how the training engine consumes deferred reflection batches while the inference engine generates new rollouts.
Experiment
The evaluation assesses RUBRICEM on four representative long-form benchmarks using an infrastructure adapted from DR Tulu. Results demonstrate that the proposed reinforcement learning recipe significantly improves performance over supervised fine-tuning and outperforms strong open baselines while remaining competitive with proprietary systems. Ablation studies validate that stagewise credit assignment and structured scaffolding contribute complementary gains, whereas inference-time experience reuse proves effective only with the learned meta-policy. Furthermore, the model exhibits strong generalization to short-form tasks, confirming that the training teaches transferable tool-use and evidence-grounding skills rather than just long-form report writing.
The the the table compares short-form search performance between the proposed RUBRICEM model and DR Tulu baselines. RUBRICEM demonstrates consistent improvements across all benchmarks, with the RL-fine-tuned version achieving the best overall results. RUBRICEM-8B (RL) achieves the highest average score, surpassing strong open baselines like DR Tulu-8B (RL). The model generalizes effectively to short-form tasks despite being trained primarily on long-form deep research data. RUBRICEM reaches superior performance using fewer RL training steps compared to the DR Tulu baseline.
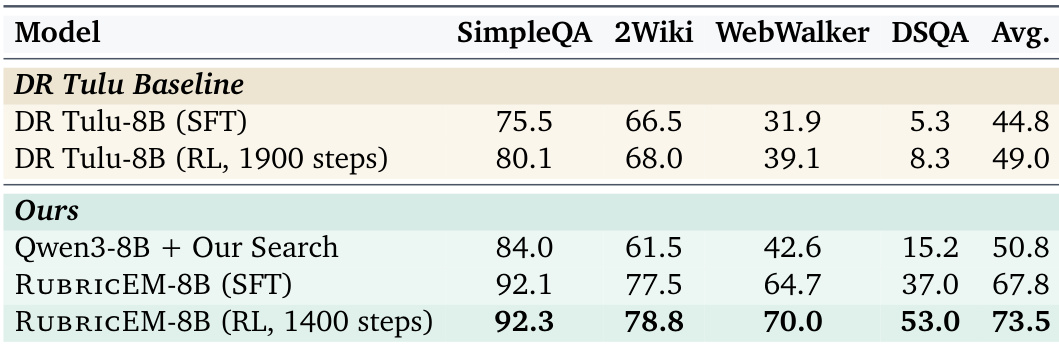
The authors evaluate RUBRICEM against proprietary and open-source deep research models across multiple benchmarks. Results indicate that RUBRICEM-8B-RL achieves the highest performance among non-proprietary systems, surpassing strong open baselines like DR Tulu and Tongyi DeepResearch. Furthermore, the model demonstrates competitive capabilities against top-tier proprietary systems, particularly outperforming them on the DRB benchmark. RUBRICEM-8B-RL achieves the highest average performance among non-proprietary deep research systems evaluated. The Reinforcement Learning stage yields significant performance gains over the Supervised Fine-Tuning baseline. The model outperforms OpenAI Deep Research on the DRB benchmark while remaining competitive with other closed models overall.
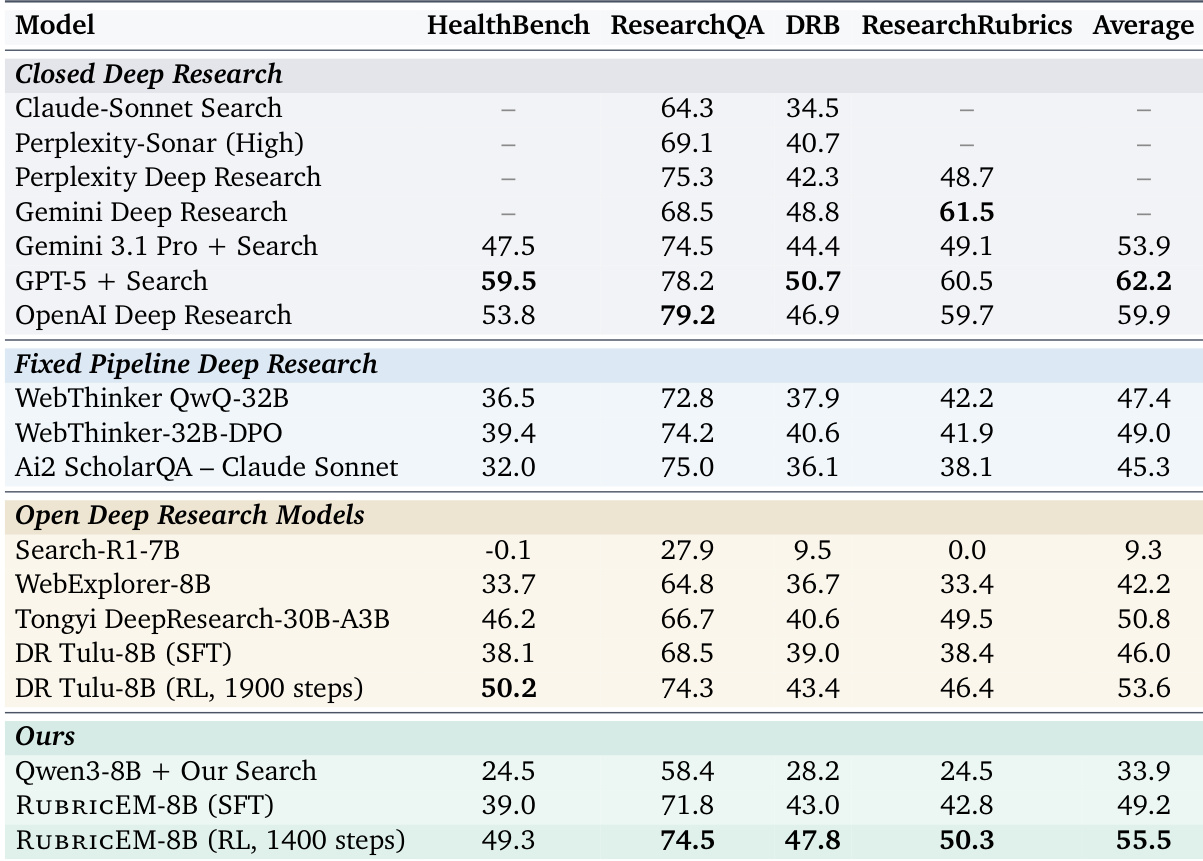
The authors evaluate RUBRICEM against open-source and proprietary deep research models to validate its performance across short-form search and deep research benchmarks. Results indicate that the RL-fine-tuned version generalizes effectively from long-form training data, achieving top performance among non-proprietary systems. Additionally, the model surpasses strong open baselines and remains competitive with top-tier proprietary systems while requiring fewer reinforcement learning training steps.