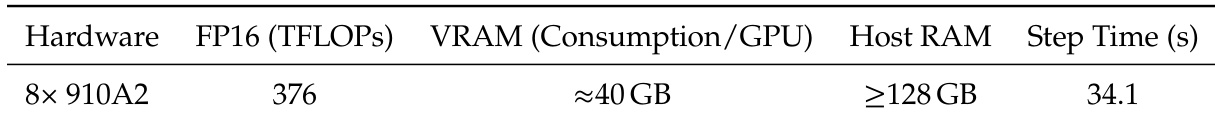Command Palette
Search for a command to run...
MOVA:迈向可扩展且同步的视频-音频生成
MOVA:迈向可扩展且同步的视频-音频生成
摘要
音频在真实世界的视频内容中至关重要,然而现有的生成模型在很大程度上忽视了音频组件。当前生成音视频内容的方法多依赖于级联式流水线(cascaded pipelines),这不仅增加了成本,还导致误差累积,进而降低整体生成质量。尽管像Veo 3和Sora 2等系统强调了同步生成的价值,但联合多模态建模在架构设计、数据处理和训练策略方面带来了独特的挑战。此外,现有系统的闭源特性严重制约了该领域的研究进展。在本工作中,我们提出了MOVA(MOSS Video and Audio),一个开源的音视频生成模型,能够生成高质量且高度同步的音视频内容,包括逼真的唇形同步语音、环境感知的声音效果以及与内容高度匹配的背景音乐。MOVA采用混合专家(Mixture-of-Experts, MoE)架构,总参数量达320亿,推理过程中激活参数为180亿。该模型支持IT2VA(Image-Text to Video-Audio)生成任务。通过公开模型权重与源代码,我们旨在推动该领域的研究发展,并促进创作者生态的繁荣。发布的代码库提供了对高效推理、LoRA微调以及提示词增强的全面支持。
一句话总结
SII-OpenMOSS 团队推出 MOVA,一款开源的 320 亿参数 MoE 模型,可生成同步的音视频内容,具备逼真的唇形同步与环境感知声音,突破级联流水线的限制,通过开放代码与权重推动社区驱动的创新。
主要贡献
- MOVA 填补开源音视频生成领域的空白,引入联合训练模型,同步合成视频与音频(包括唇形同步语音与环境感知声音),克服级联流水线带来的误差累积与成本问题。
- 采用非对称双塔架构,结合双向交叉注意力与混合专家设计(总参数 32B,激活参数 18B),高效实现高保真图文到音视频生成,同时应对模态间信息密度差异等挑战。
- 通过细粒度音视频标注流水线与开放训练基础设施,模型展现出可扩展的性能提升,支持社区研究,提供开放权重、LoRA 微调与提示增强工具。
引言
作者利用扩散视频生成技术的日益成熟,应对同步音视频合成这一尚未充分探索的挑战——此前多数系统要么忽略音频,要么依赖易出错的级联流水线。现有联合模型如 Veo3 和 Sora2 已证明可行性,但均为闭源;开源替代方案则受限于规模小、音频保真度差或模态融合能力弱。MOVA 通过引入可扩展的 320 亿参数混合专家双塔架构与双向交叉注意力,实现从图文提示端到端生成高质量唇形同步语音、环境感知音效与内容匹配音乐。通过开放权重、训练代码与推理工具,作者旨在推动研究民主化,加速同步多模态生成领域的进展。
数据集

作者使用从公开与内部来源精心筛选的音视频数据集训练视频-音频生成模型。以下是数据组成、处理与使用方式:
-
来源与组成:
数据集源自 VGGSound、AutoRe-Cap、ChronoMagic-Pro、ACAV-100M、OpenHumanVid、SpeakerVid-5M 和 OpenVid-1M 等公开数据集的高质量子集,并补充内部录制内容。涵盖教育、体育、美妆、新闻、电影、Vlog 与动画等多元领域,确保广泛泛化能力。 -
关键子集细节:
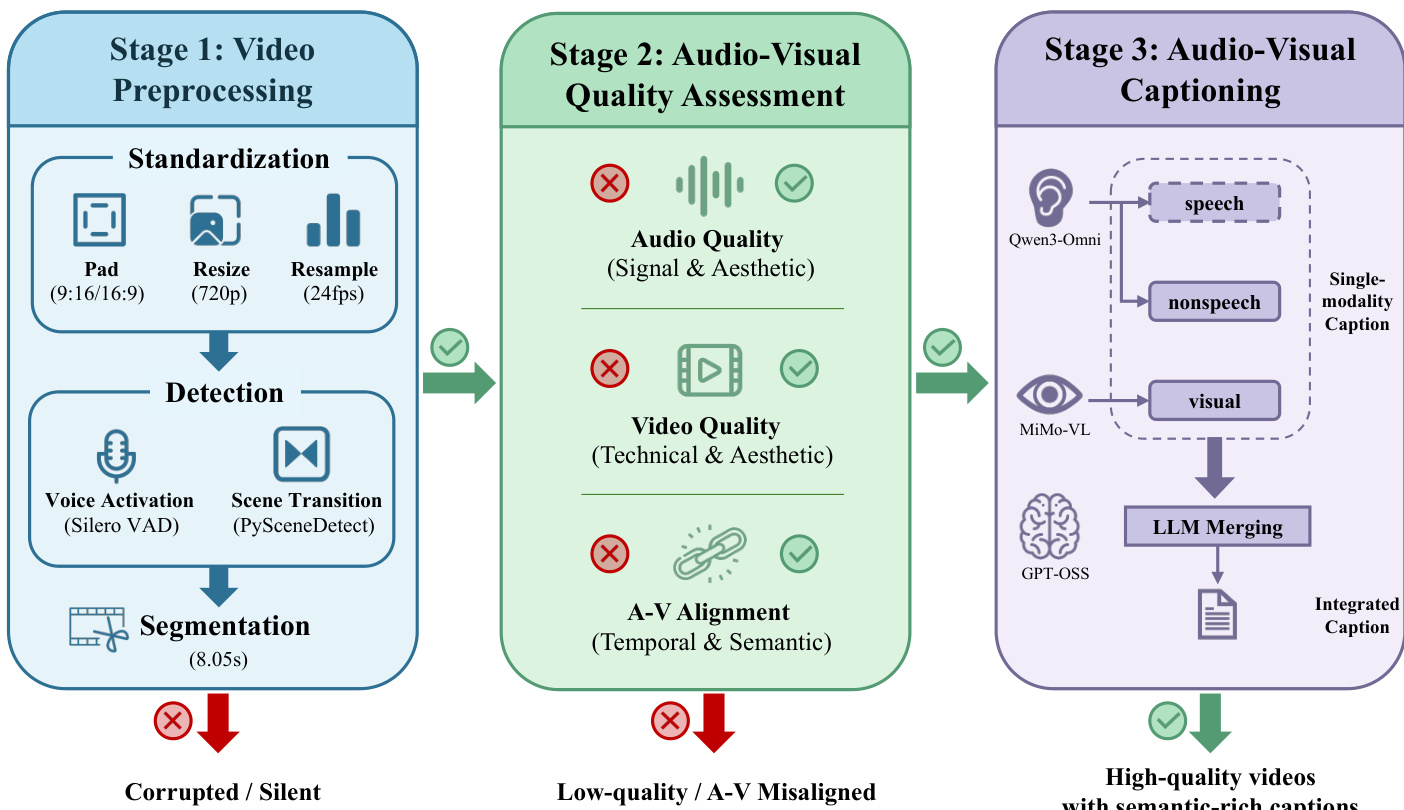
- 所有原始视频预处理为固定 8.05 秒片段(24fps 下 193 帧),调整为 720p 分辨率,并通过裁剪与填充归一化为 9:16 或 16:9 宽高比。
- 仅保留含语音的片段(占预处理片段的 69.47%),通过 VAD 与场景转换检测识别。
- 音视频质量通过三重过滤评估:
- 音频:静音比、带宽与 Audiobox 美学评分。
- 视频:DOVER 工具评估技术与美学质量。
- 对齐:SynchFormer(时间同步)与 ImageBind(语义同步);片段需满足 IB-Score ≥ 0.2 或 DeSync ≤ 0.5。
- 语音子集使用 EAT 分类保留确认含语音或歌唱内容的片段。
-
训练使用与处理:
- 最终训练集为通过预处理、质量过滤与多模态标注三阶段流水线的片段混合体。
- 使用 Qwen3-Omni 与 MiMo-VL 分别为音频与视觉内容生成字幕,再通过 GPT-OSS 合并为统一、丰富的描述。
- 模型训练使用 720p 分辨率、24fps 的片段;仅包含语音片段,聚焦唇形同步与对话生成。
-
裁剪与元数据:
- 核心视觉内容通过 FFmpeg 的 cropdetect 居中裁剪并填充至标准宽高比。
- 分段元数据结合 VAD 与场景转换时间戳生成四类片段,仅选择含语音者。
- 元数据包含时间戳、场景边界与音频分类标签,用于引导模型条件生成与评估。
该流水线确保高保真、语义对齐、时间一致的训练数据,专为联合视频-音频生成优化。
方法
作者采用非对称双塔架构 MOVA,通过双向 Bridge 模块耦合大型视频扩散 Transformer 与小型音频扩散 Transformer,实现同步音视频生成。整体框架在预训练 VAE 定义的潜在空间中运行:视频 VAE 将输入视频压缩为时空潜在变量 xv,音频 VAE 将波形编码为 xa。生成过程采用流匹配:在每个时间步 t∼U(0,1),噪声潜在变量构造为 xtv=(1−t)xv+tεv 与 xta=(1−t)xa+tεa,其中 εv,εa∼N(0,I)。模型预测速度场 v^θv 与 v^θa,目标为 vtv=εv−xv 与 vta=εa−xa,优化损失为 LFM=Et,c,xv,xa,ε[λv∥v^θv−vtv∥22+λa∥v^θa−vta∥22]。
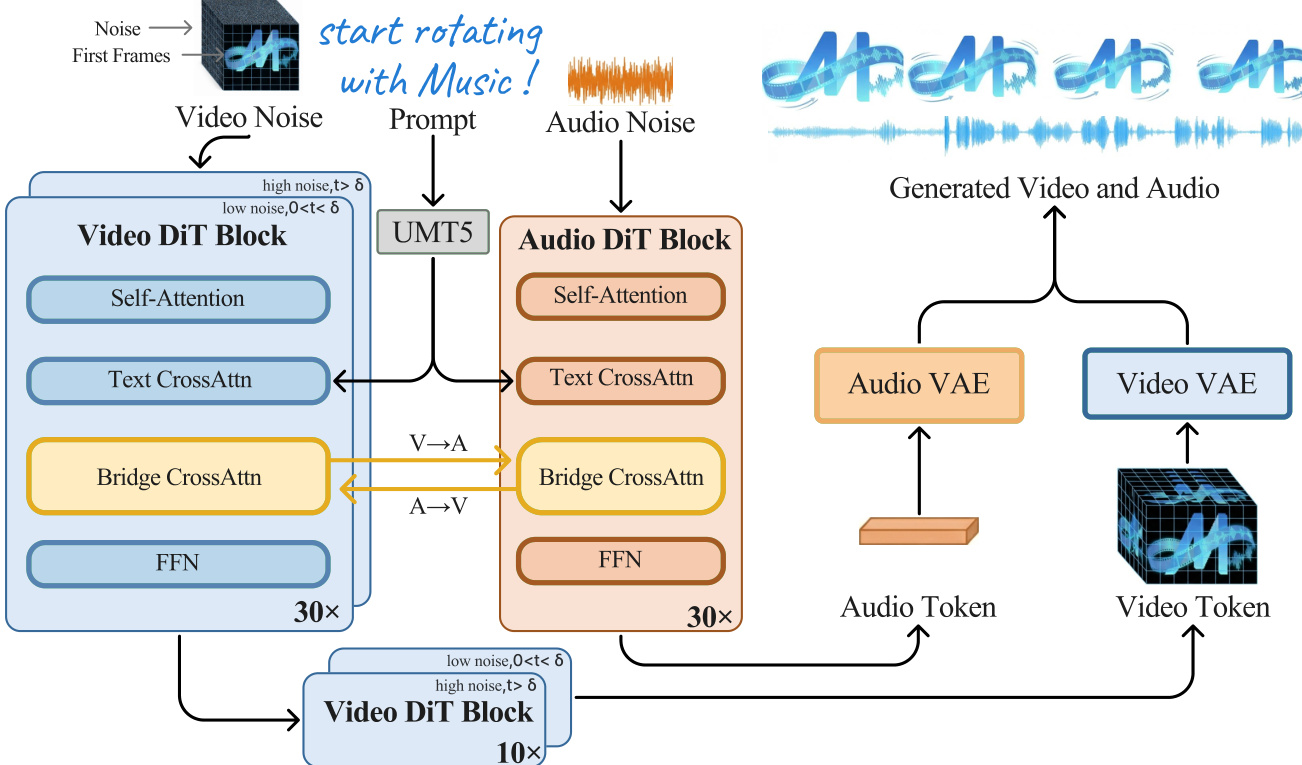
参考架构图,核心架构包括基于 A14B Wan2.2 DiT 的视频塔与 1.3B 参数 DiT 的音频塔,通过 2.6B 参数 Bridge 模块连接,支持双向交叉注意力。每个 DiT 块包含自注意力、文本交叉注意力与前馈层。Bridge 将视频隐藏状态注入音频 DiT,反之亦然,促进跨模态交互。为解决视频与音频潜在变量的时间不对齐问题(视频潜在变量时间下采样,音频潜在变量密集),作者实现 Aligned RoPE:修改标准旋转位置编码,将视频标记位置按比例 s=fa/fv 缩放,映射到音频时间网格:pη(i)=s⋅i 与 pα(j)=j,确保表示相同物理时间的标记对齐,保持平移不变性,防止音视频漂移。
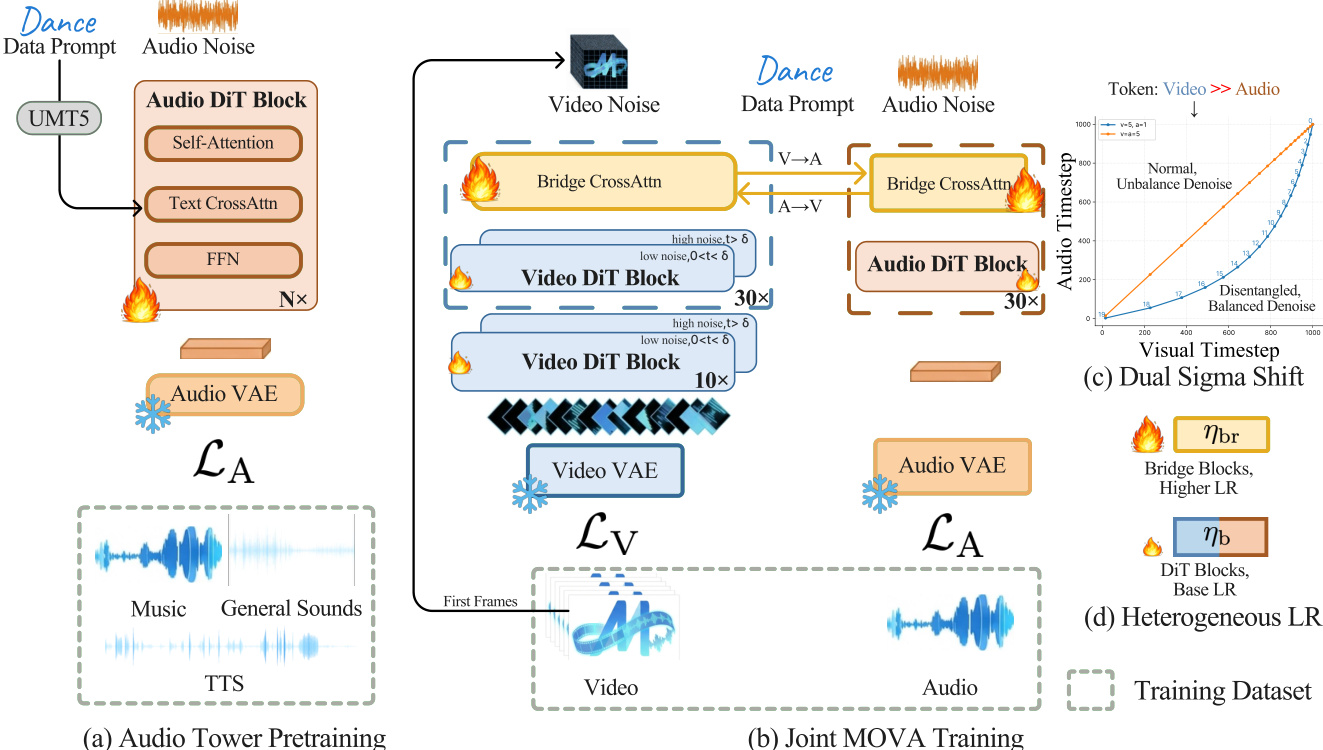
训练流水线分为两个主要阶段。第一阶段独立在多样化音频数据(音乐、通用声音、TTS)上预训练音频塔,使用 1.3B DiT。第二阶段联合训练预训练视频塔、音频塔与随机初始化 Bridge 模块。联合训练分为三阶段,逐步提升数据质量与分辨率:第一阶段在 360p 分辨率下使用 61,500 小时多样化数据训练,采用非对称 sigma-shift 值(shiftv=5.0, shifta=1.0)与激进文本丢弃(pdroptxt=0.5),鼓励 Bridge 对齐。第二阶段精炼数据集至 37,600 小时质量过滤片段,使用 OCR、唇形同步指标(LSE-D ≤ 9.5, LSE-C ≥ 4.5)与 DOVER 技术评分(>0.15),将音频 sigma shift 对齐至 5.0 以提升音色保真度,文本丢弃降至 0.2。第三阶段在 720p 分辨率下使用 11,000 小时最高质量数据(DOVER > 0.14)训练,调整上下文并行从 CP=8 至 CP=16 以处理更长序列。
如下图所示,联合训练采用异构学习率:Bridge 模块优化率为 ηbr=2×10−5,主干塔使用 ηb=1×10−5,加速 Bridge 收敛而不破坏预训练先验。此外,作者解耦视频与音频的时间步采样,独立从 U(0,1) 采样 tv 与 ta,并通过 σm(t)=shiftm+t(1−shiftm)shiftm⋅t 应用模态特定噪声调度。这允许独立控制各模态的去噪强度,对音频音色保真度至关重要。
推理时,作者实现双分类器自由引导(dual CFG)方案,独立控制文本引导与跨模态对齐。联合后验分解为 P(z∣cT,cB)∝P(cT∣cB,z)P(cB∣z)P(z),导出速度预测 v~θ=vθ(zt,∅,∅)+sB⋅[vθ(zt,∅,cB)−vθ(zt,∅,∅)]+sT⋅[vθ(zt,cT,cB)−vθ(zt,∅,cB)]。通过调节 sB 与 sT,用户可在对齐强度与感知质量间权衡。通用 dual CFG 每步需三次函数评估(NFE=3),特殊情形如仅文本 CFG(sB=1,sT=s)或文本+模态 CFG(sB=s,sT=s)可降至 NFE=2。
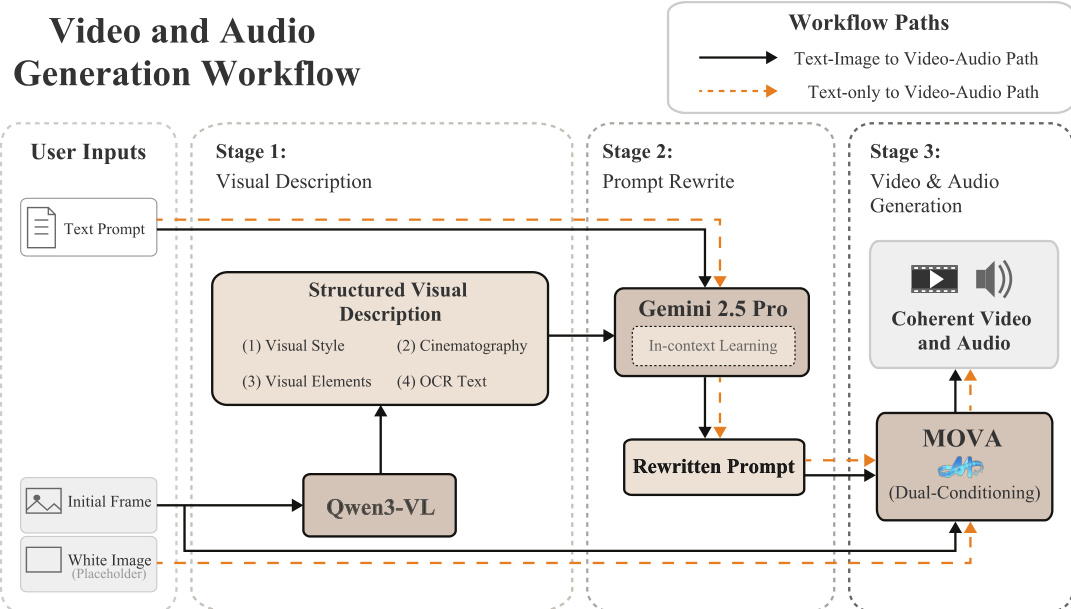
生成流程支持图文与纯文本输入。对于图文生成,初始帧由 Qwen3-VL 处理,提取涵盖风格、摄影、元素与 OCR 文本的结构化视觉描述。该描述与用户提示通过 LLM(如 Gemini 2.5 Pro)结合上下文学习重写,生成与训练数据分布对齐的提示。MOVA 随后使用重写提示与初始帧进行双重条件生成视频与音频。对于纯文本生成,使用空白占位图像,实现零样本合成。
为支持大规模训练,作者使用三阶段流水线整理超 10 万小时双模态数据:预处理(标准化、语音激活、场景检测)、质量评估(音频、视频、音视频对齐过滤)与标注。标注使用 MiMo-VL-7B-RL 处理视频,Qwen3-Omni-Instruct 处理语音,Qwen3-Omni-Captioner 处理非语音音频,再通过 GPT-OSS-120B 与显式规则合并,确保连贯性、避免重复、锚定语音至视觉上下文。该流水线产出高质量、语义丰富的字幕,适用于训练。
实验
- 训练效率通过 FSDP、序列并行与内存管理优化,实现约 35% MFU;通过每 CP 组预处理一次并广播特征减少 VAE 冗余,Ascend NPU 上通过算子融合进一步提升性能。
- MOVA 在音频保真度、语音清晰度与音视频对齐方面优于基线(LTX-2、Ovi、WAN2.1+MMAudio),尤其在唇形同步精度与多说话人归属上表现突出,dual CFG 增强跨模态绑定,但略微牺牲语音质量与指令遵循能力。
- 扩展至 720p 保持强跨模态一致性,提升唇形同步与说话人归属,验证分阶段训练;dual CFG 提升对齐指标,但因引导失衡降低语音自然度与指令遵循。
- MOVA 展现出新兴的 T2VA 能力,仅从文本生成同步音视频内容,具备高音频保真度与时间对齐,尽管缺乏视觉条件。
- 人工评估确认 MOVA 在偏好与胜率上的优越性,提示优化显著提升性能;dual CFG 改善客观对齐,但因文本引导减弱略微降低主观偏好。
- 唇形同步质量在三阶段训练中逐步提升:初始桥接建立对齐,精炼噪声调度增强一致性,高分辨率扩展在添加细节的同时保持同步。
- 局限包括音乐/歌唱建模受限、多说话人同步因数据噪声困难、长序列导致高计算成本,需在物理推理、监督与效率方面改进。
结果表明,移除 MOVA-360p-T2VA 中的参考图像可提升音频保真度与时间同步性(IS 更高、DeSync 更低),但略微降低唇形同步精度与多说话人归属准确率。这表明模型可仅从文本生成连贯音视频内容,即使无视觉条件,亦能利用内化的跨模态先验。

作者使用分阶段过滤流程精炼训练数据,从原始视频到第二阶段逐步降低保留比例,优先保留语音内容并移除非语音片段。结果表明,语音数据占初始数据集不足 60%,第二阶段进一步保留约四分之一原始材料,表明训练聚焦高质量、语音相关样本。这种选择性过滤可能促成模型在后续评估中表现出的音视频对齐与唇形同步性能提升。

作者使用 1.3B 参数模型与 100 NFE 步,实现低于 TangoFLUX 与 AudioLDM2 的 FID 与更高 IS,表明尽管 KL 散度较高,样本质量与多样性仍获提升。结果表明,扩大模型规模与优化推理步数可增强生成性能,即使部分对齐指标下降。

作者采用三阶段训练策略逐步扩展分辨率并精炼跨模态对齐,从 360p 开始推进至 720p,同时调整文本丢弃与音频归一化等超参数以稳定学习。结果表明,此分阶段方法使模型在更高分辨率下仍保持强音视频同步与唇形同步精度,对齐指标无显著下降。每阶段调整训练时长与检查点间隔,以适应更高分辨率合成的复杂性与数据需求。

作者在 8× Ascend 910A2 设备上使用 CP=4 与 DP-shard=2 配置测量训练效率,单步耗时 34.1 秒。系统每 GPU 消耗约 40 GB 显存,需至少 128 GB 主机内存,FP16 精度下运行于 376 TFLOPs。这些基准反映优化内存管理与算子融合以降低大规模训练时的框架开销。