Command Palette
Search for a command to run...
LLaDA2.1:通过Token编辑加速文本扩散
LLaDA2.1:通过Token编辑加速文本扩散
摘要
尽管LLaDA2.0展现了百亿级别块扩散模型(block-diffusion models)在规模扩展方面的潜力及其固有的并行化能力,但解码速度与生成质量之间的微妙平衡仍是一个难以突破的前沿难题。如今,我们正式发布LLaDA2.1,这标志着一次范式革新,旨在彻底超越这一权衡困境。通过将Token-to-Token(T2T)编辑机制无缝融合进传统的Mask-to-Token(M2T)框架,我们提出了一种联合可配置阈值解码机制。这一结构创新赋予模型两种截然不同的运行模式:极速模式(S Mode),通过大幅降低M2T阈值以突破传统限制,同时依赖T2T机制对输出进行精细化修正;高质量模式(Q Mode),则采用更为保守的阈值策略,在保持可接受效率损耗的前提下,显著提升基准测试表现。进一步推动这一演进,基于超长上下文窗口的支持,我们首次构建了专为扩散型大语言模型(dLLMs)量身定制的大规模强化学习(Reinforcement Learning, RL)框架,并引入了保障梯度估计稳定性的专用技术。该对齐机制不仅显著提升了模型的推理精准度,还大幅增强了指令遵循的一致性,有效弥合了扩散动态过程与复杂人类意图之间的鸿沟。本研究最终成果为:发布LLaDA2.1-Mini(16B)与LLaDA2.1-Flash(100B)两个版本。在33项严格基准测试中,LLaDA2.1展现出卓越的任务执行能力与闪电般的解码速度。尽管模型规模达到1000亿参数,其在编码任务上的表现尤为惊人:在HumanEval+上达到892 TPS(每秒处理数),BigCodeBench上达801 TPS,LiveCodeBench上达663 TPS,充分彰显了其在高吞吐量场景下的强大实力。
一句话摘要
蚂蚁集团、浙江大学、西湖大学和南方科技大学的研究人员提出了 LLaDA2.1,这是一款 100B 参数的扩散式大语言模型,通过联合 T2T/M2T 解码模式和强化学习对齐,打破了速度与质量之间的权衡,在 HumanEval+ 上实现了 892 TPS 的吞吐量,同时保持了强大的基准测试性能。
主要贡献
- LLaDA2.1 引入了一种可配置阈值的联合 Token-to-Token 和 Mask-to-Token 解码方案,支持两种运行模式——“快速模式”用于激进的并行生成,“质量模式”用于高保真输出,从而解决了离散扩散大语言模型中长期存在的解码速度与生成质量之间的权衡问题。
- 该模型集成了首个专为 dLLM 设计的大规模强化学习框架,采用基于 ELBO 的块级策略优化方法稳定梯度估计,在不牺牲并行解码架构的前提下提升推理精度和指令遵循保真度。
- 在 33 个基准测试中评估,LLaDA2.1-Flash(100B)实现了业界领先的吞吐量——HumanEval+ 上 892 TPS、BigCodeBench 上 801 TPS、LiveCodeBench 上 663 TPS——同时保持了强大的任务性能,证明可编辑性能够在不牺牲质量的前提下实现极致效率。
引言
作者利用离散扩散语言模型(dLLM)克服了传统自回归或 Mask-to-Token 框架中固有的解码速度与生成质量之间的刚性权衡。以往工作在并行解码中存在词元级不一致性,且缺乏在不牺牲效率的前提下动态纠正错误的机制。LLaDA2.1 引入了一种可配置阈值的联合 Token-to-Token(T2T)和 Mask-to-Token(M2T)解码方案,支持两种运行模式:用于高吞吐量的“快速模式”和用于高精度的“质量模式”。他们进一步通过一种专为可编辑状态演进设计的新型 RL 框架(EBPO)增强推理和指令对齐能力,同时保持模型规模和训练数据约束。结果是一个可扩展、可编辑的扩散架构,在编码基准测试上实现了高达 892 TPS 的业界领先速度,且未牺牲保真度。
方法
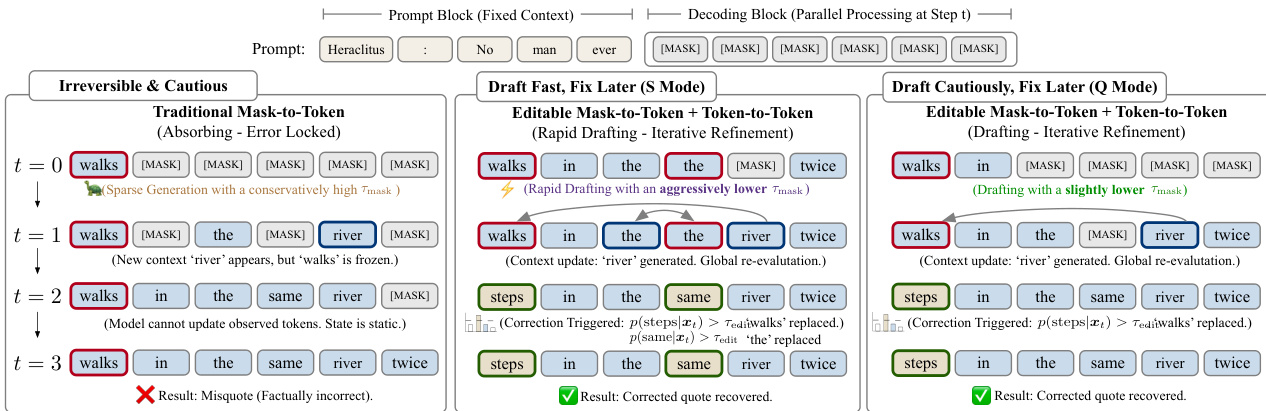
作者采用了一种新颖的“草稿-编辑”解码范式,以缓解基于扩散的大语言模型(dLLM)中的暴露偏差问题,同时在保持速度的前提下实现并行词元生成的迭代优化。该方法不同于传统的吸收态扩散模型,引入了由可配置概率阈值 τmask 和 τedit 控制的两个动态更新集——解掩码集 Γt 和编辑集 Δt。在每个时间步 t,模型根据最高候选词元 vti=argmaxvpθ(v∣xt) 识别需解掩码或编辑的位置,形式化为:
Γt={i∣xti=[MASK] and pθ(vti∣xt)>τmask},Δt={i∣xti=vti and pθ(vti∣xt)>τedit},状态转移严格应用于 Γt∪Δt 的并集:
xt−1i={vtixtiif i∈Γt∪Δt,otherwise.该机制允许模型回溯纠正并行生成中引入的错误,平衡速度与质量。可通过阈值设置调整解码行为:激进的解掩码支持快速草稿(S 模式),保守的阈值支持谨慎草稿与迭代精修(Q 模式)。参见框架图,对比传统 Mask-to-Token 解码与所提出的可编辑范式。
为使模型适配该推理范式,作者在持续预训练(CPT)和监督微调(SFT)阶段均采用统一的 Mask-to-Token(M2T)与 Token-to-Token(T2T)混合训练目标。M2T 流训练模型从掩码上下文中生成初始草稿,而 T2T 流教导模型从扰动输入中恢复正确词元,从而发展编辑能力。多轮前向(MTF)数据增强进一步使模型暴露于多样化的编辑场景,增强其修订伪影的能力。训练流程在第三阶段应用强化学习(RL),通过 EBPO(基于 ELBO 的块级策略优化)实现,该方法在块因果掩码 M 下并行计算块条件概率,以近似难以处理的序列级对数似然。策略更新最大化一个裁剪代理目标:
JEBPO(θ)=Ex,y∼πθold[min(ρ(y∣x)A^,clip(ρ(y∣x),1−ϵlow,1+ϵhigh)A^)],其中 ρ(y∣x) 通过以下方式估计:
logρ(y∣x)≈n=1∑Nwnb=1∑B(logpθ(yb∣zn,x;M)−logpθold(yb∣zn,x;M)).如下图所示,训练与推理工作流紧密耦合:模型在双 M2T/T2T 监督下训练,然后在推理阶段部署带阈值控制的解掩码与修正操作。
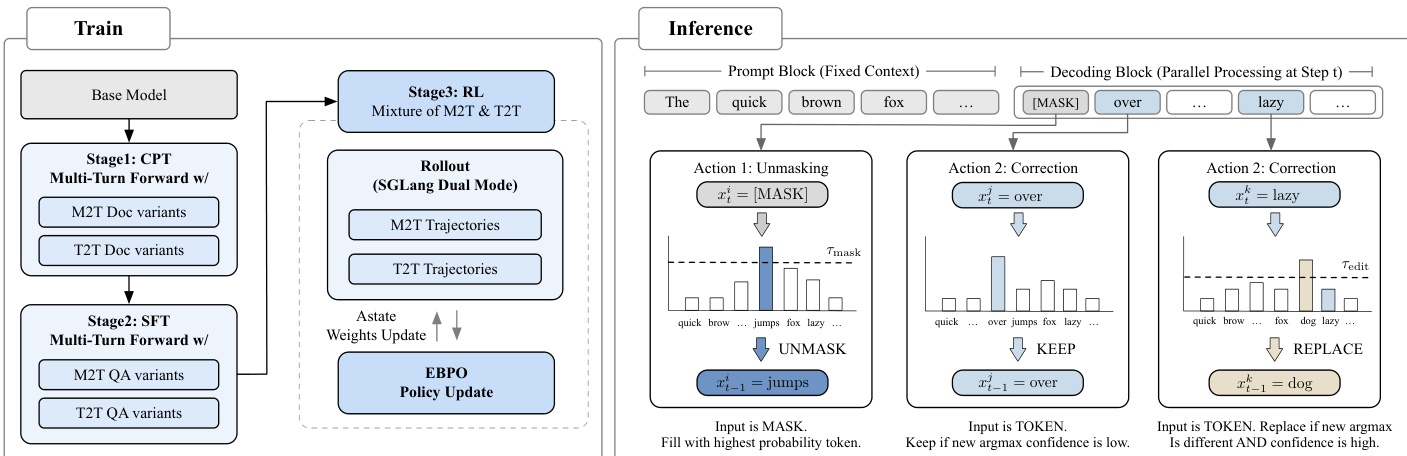
推理阶段,解码算法结合基于阈值的解掩码与显式修正。在单块模式下,词元在 τmask 下生成,局部编辑在最终化前应用。多块编辑(MBE)扩展允许基于新解码内容回溯并修订先前块,实现全局一致性。基础设施优化——包括 Alpha-MoE 超核、每块 FP8 量化和块级因果掩码注意力——进一步加速推理,尤其对长上下文,而基数缓存和批处理确保可扩展性。
实验
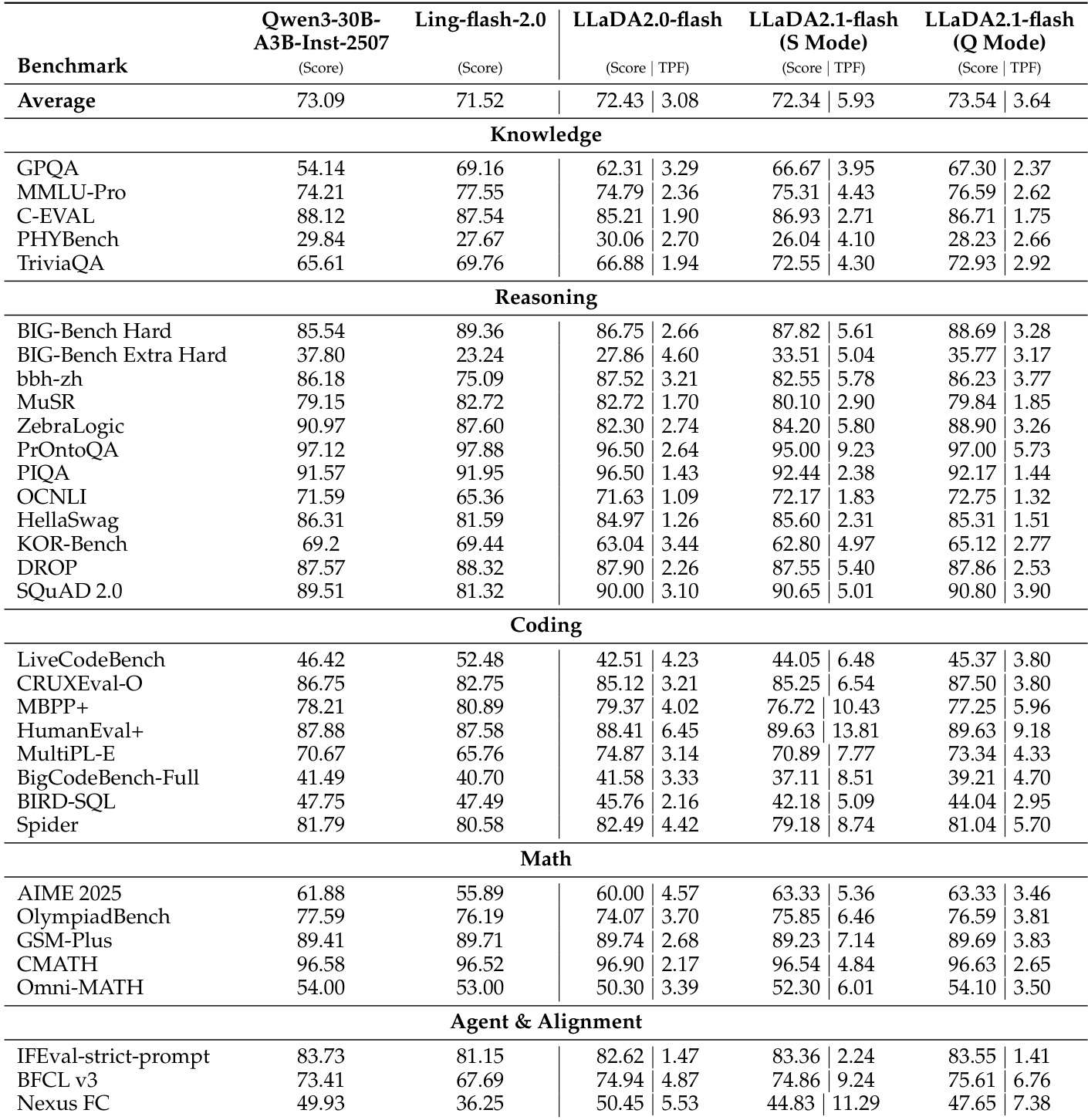
- LLaDA2.1 展示了明确的速度-精度权衡:S 模式优先考虑推理速度,质量略有损失,尤其在编码和数学等结构化领域表现突出;Q 模式则在通用聊天任务中保持更高精度。
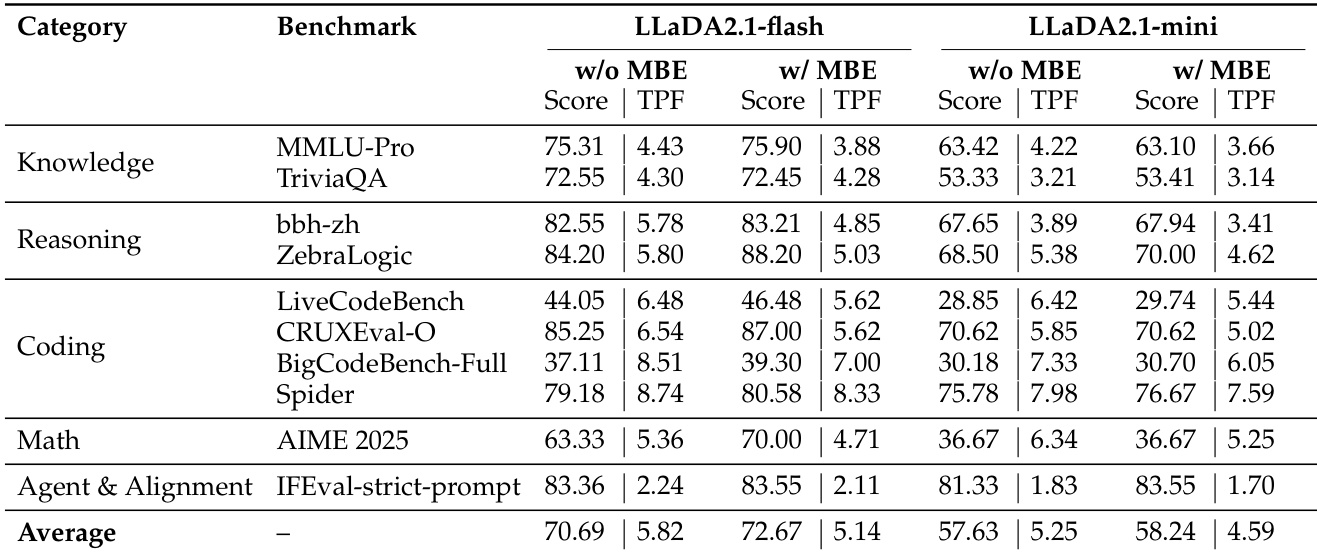
- 多块编辑在推理和编码基准测试中持续提升性能,通过纠正局部错误并增强全局一致性,仅带来适度吞吐量下降。
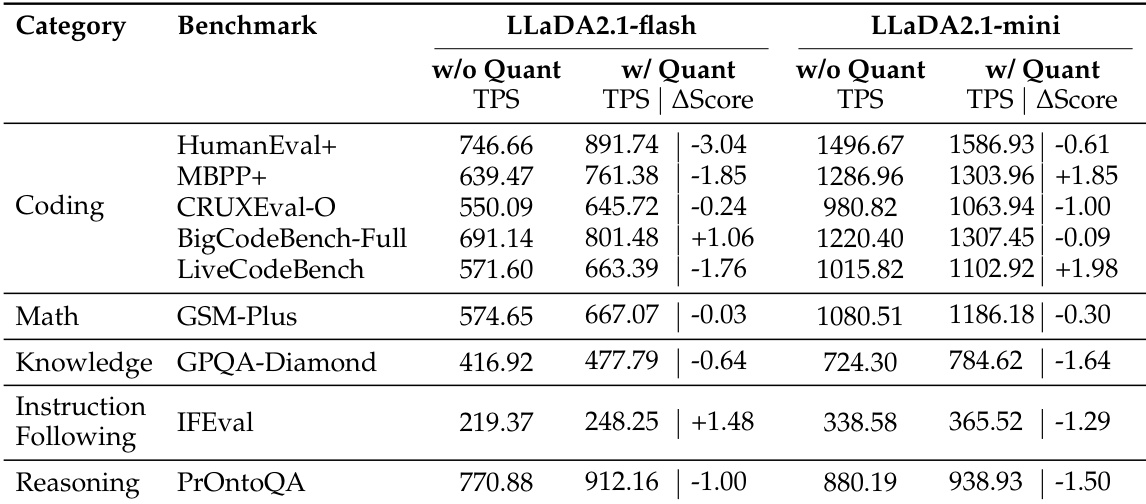
- LLaDA2.1 的量化变体在 HumanEval+ 上实现高达 1586.93 的峰值吞吐量(TPS),在速度上显著优于 LLaDA2.0、Ling 和 Qwen3 等先前模型,尤其在代码领域。
- 尽管理论上具有并行优势,扩散语言模型的错误率仍高于自回归模型;及时编辑对在推理中保持速度和置信度至关重要。
- LLaDA2.1 的编辑机制降低了解码阈值并实现更快推理,但平衡初始草稿速度与结构质量仍是一大挑战,尤其在激进掩码设置下。
- 该模型仍处于实验阶段,边缘情况和伪影(如重复)需仔细调参;未来工作旨在将编辑集成到强化学习中,以实现更强的自我纠正能力。
作者在两种模式下使用 LLaDA2.1——S 模式用于速度,Q 模式用于质量——发现 S 模式虽略微降低精度,但在编码和数学任务中显著提高吞吐量。结果表明 Q 模式在总分上始终优于 S 模式,表明跨领域存在明确的推理速度与输出质量权衡。多块编辑进一步在推理和编码基准测试中提升性能,仅带来适度吞吐量成本,表明迭代优化有助于在不牺牲效率的前提下维持质量。
作者在多个基准测试中评估了启用和未启用多块编辑(MBE)的 LLaDA2.1-flash 和 LLaDA2.1-mini,发现 MBE 持续提升分数,但以降低吞吐量为代价。结果显示最大收益出现在推理和编码任务中,迭代优化增强了输出质量,同时保持可接受的解码效率。总体而言,通过模式选择和编辑可有效管理速度与精度的权衡,结构化领域从激进的速度优化中受益最多。
作者在多个领域评估了 LLaDA2.1-flash 和 LLaDA2.1-mini,表明量化通常提升吞吐量,但引起轻微分数波动,编码任务在速度上受益最大,指令遵循则显示混合精度影响。结果表明明确的速度-精度权衡,量化设置下的更高吞吐量常伴随轻微性能下降,但部分基准(如 MBPP+ 和 LiveCodeBench)分数有所提升。模型性能因领域而异,表明最优配置取决于任务类型,结构化领域(如编码)比通用指令遵循更能容忍更高速度设置。
作者在两种模式下评估了 LLaDA2.1-mini,发现 S 模式以牺牲部分精度为代价提升推理速度,Q 模式则以适度吞吐量恢复或超越先前性能水平。结果表明 Q 模式在编码和推理任务中持续提升,而知识和数学基准测试揭示了权衡——S 模式速度提升伴随分数下降。总体而言,模型表明自适应模式选择可根据任务类型平衡速度与精度。
