Command Palette
Search for a command to run...
OPUS:面向大语言模型预训练中每轮迭代的高效且原则性数据选择
OPUS:面向大语言模型预训练中每轮迭代的高效且原则性数据选择
摘要
随着高质量公共文本数据逐渐枯竭,一种被称为“数据墙”(Data Wall)的现象正在显现,预训练正从追求更多token转向更优token。然而,现有方法要么依赖于忽视训练动态的启发式静态过滤器,要么采用基于原始梯度的动态但与优化器无关的筛选标准。为此,我们提出OPUS(Optimizer-induced Projected Utility Selection)——一种动态数据选择框架,其在优化器诱导的更新空间中定义数据的“效用”。OPUS通过将现代优化器所塑造的有效更新向量,投影到由稳定且分布内代理(in-distribution proxy)导出的目标方向上,从而对候选数据进行评分。为保障可扩展性,OPUS采用Ghost技术结合CountSketch以提升计算效率,并引入Boltzmann采样以维持数据多样性,整体仅带来4.7%的额外计算开销。OPUS在多种语料库、数据质量层级、优化器类型及模型规模下均展现出卓越性能。在基于300亿token的FineWeb与FineWeb-Edu数据集上对GPT-2 Large/XL进行预训练时,OPUS不仅超越了工业级基线方法,甚至优于完整的2000亿token训练。此外,当与工业级静态过滤器结合使用时,OPUS进一步提升了预训练效率,即便在低质量数据环境下仍表现优异。更值得注意的是,在Qwen3-8B-Base模型的持续预训练任务中,利用仅0.5亿token的OPUS筛选数据即可达到使用完整30亿token全量训练的性能水平,充分体现了其在专业领域中的显著数据效率优势。
一句话总结
EPIC 实验室、Qwen 团队、威斯康星大学麦迪逊分校、伊利诺伊大学厄巴纳-香槟分校和 Mila 的研究人员提出了 OPUS,这是一种动态数据选择方法,通过将优化器塑造的更新投影到稳定方向上,相比随机选择效率提升 8 倍、准确率提升 2.2%,尤其在 SciencePedia 等专业领域使用极少 token 即可取得显著效果。
主要贡献
- OPUS 引入了一种优化器感知的效用度量指标用于动态数据选择,根据样本在 AdamW 和 Muon 等自适应优化器实际更新空间中的投影影响进行打分,解决了基于梯度评分与现代训练动态不一致的问题。
- 该方法采用从训练语料中提取的稳定、分布内代理数据集(BENCH-PROXY),并通过 Ghost 技术结合 CountSketch 投影实现高效扩展,在仅增加 4.7% 计算开销的同时,通过玻尔兹曼采样保持数据多样性。
- 实验表明,OPUS 在使用 30B token(而非 200B)对 GPT-2 Large/XL 进行预训练时优于工业基线,并在仅使用 0.5B token(而非 3B)对 Qwen3-8B-Base 在 SciencePedia 上进行持续预训练时取得更优结果,展现出在不同模型规模和领域中的显著数据效率。
引言
作者利用高质量预训练数据日益稀缺的现状,将数据选择重新定义为一种优化器感知的动态过程,而非静态预处理步骤。以往方法要么依赖忽略模型演化的固定质量启发式规则,要么在原始梯度空间中对样本打分,与 AdamW 和 Muon 等重塑更新方向的现代自适应优化器不匹配。OPUS 引入“优化器诱导效用”——一种基于实际优化器几何结构、可扩展的框架,通过高效投影和稳定分布内代理对数据进行评分。它进一步通过玻尔兹曼采样保持多样性,并在多个大语言模型和数据集上优于静态过滤器和先前动态选择器。
数据集
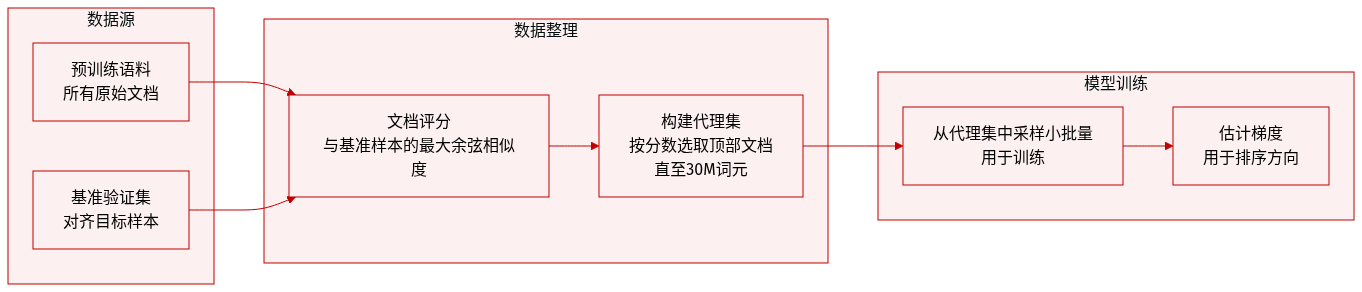
- 作者构建了 BENCH-PROXY,一个从预训练语料中采样的小型代理数据集,用于近似目标基准分布,从而在训练期间高效计算梯度。
- 他们使用 Arctic-Embed-L v2(Yu 等,2024a)的嵌入计算每个预训练文档的基准相关性得分——将每个文档与所有基准验证样本进行余弦相似度比较,并取每个文档的最大相似度。
- 代理集 𝒟_proxy 通过按相关性得分排序文档并贪心选取最高分文档构建,直到达到 30M token 预算,确保紧凑性和分布对齐。
- 训练期间,从 𝒟_proxy 中重复采样小批量数据以估计梯度方向,用于步骤内排序,保持稳定、低方差评分,同时引导模型朝向与基准对齐的数据。
方法
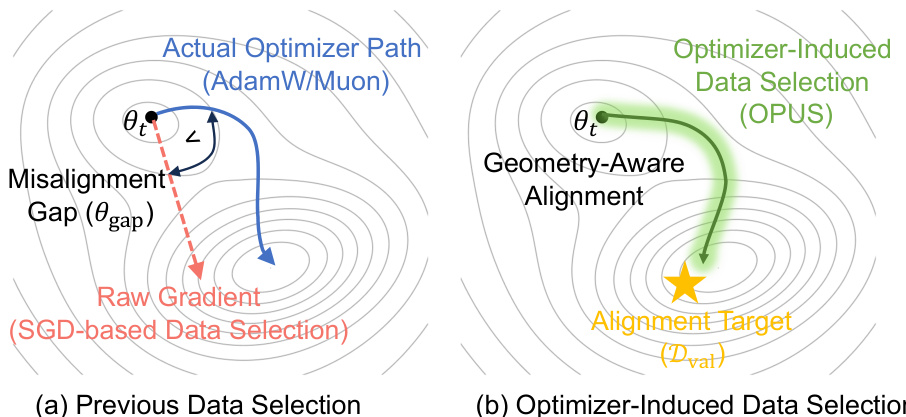
作者采用 OPUS,这是一种在优化器诱导的更新几何结构内运行的动态数据选择框架,优先选择能最大程度减少验证损失的训练样本,且基于现代优化器的实际轨迹。与先前使用原始梯度评分的方法不同(隐含假设更新空间类似 SGD),OPUS 显式考虑了 AdamW 和 Muon 等优化器施加的状态依赖预处理。这一点至关重要,因为现代优化器通过动量、自适应缩放或矩阵正交化重塑梯度方向,从而改变有效更新路径。如下图所示,OPUS 将选择与实际优化器诱导路径(绿色曲线)对齐,避免了在非 SGD 优化器下使用原始梯度选择(蓝色曲线)时产生的错位间隙(红色虚线箭头)。
在每个训练步骤 t,OPUS 接收候选缓冲区 Bt,并选择大小为 K=⌊ρN⌋ 的子集 Bt 以形成更新批次。选择由基于一次优化器步骤后验证损失预期减少的效用函数引导。具体而言,将候选样本 z 添加到当前选定子集 Bt 的边际效用近似为:
Uz(t)≈ηt⟨uz(t),gproxy(t)⟩−ηt2⟨uz(t),G(t)⟩,其中 uz(t)=Pt∇θL(z;θt) 是样本 z 的优化器诱导有效更新,gproxy(t) 是从稳定、分布内验证代理池 Dproxy 估计的代理梯度,G(t)=∑zj∈Btuzj(t) 是已选样本的累积有效方向。第一项鼓励与代理目标方向对齐,第二项通过惩罚几何上与已选样本更新方向对齐的样本来避免冗余。
为构建代理方向,OPUS 采用 BENCH-Proxy:一种基于检索的方法,使用冻结文本编码器对基准验证数据和预训练文档进行嵌入,然后选择最相似的前 M 个预训练文档以形成 Dproxy。这确保代理保持在预训练流形内,同时与下游任务分布对齐,从而产生稳定且任务相关的梯度信号。
为将此效用计算扩展到大语言模型规模,OPUS 通过利用 ghost 技术避免物化完整逐样本梯度。对于每个线性层 r,逐样本梯度 ∇WrL(z;θt) 被分解为输入激活 ar(z) 和输出梯度 br(z) 的外积。优化器诱导的有效更新 Pt,r(ar(z)⊗br(z)) 随后使用 CountSketch 算子 Πr 投影到低维空间 Rm,从而在不物化完整梯度的情况下实现高效内积计算。对于对角预处理(如 AdamW),该投影与预处理交错进行,保持每层 O(din+dout) 的计算效率。对于稠密预处理(如 Muon),成本增加到 O(dindout),但由于草图维度 m≪d,仍可处理。
最后,为保持数据多样性并避免过拟合瞬态代理噪声,OPUS 用玻尔兹曼采样替代确定性贪心选择。每个候选样本 z 以与 exp(Uz(t)/τ) 成比例的概率被采样,其中 τ>0 是温度超参数。这种随机选择确保高效用样本被优先选择,同时保留互补候选样本的非零概率,增强对估计噪声和数据流非平稳性的鲁棒性。
请参阅框架图以全面了解 OPUS 流程,该流程在单个训练循环内集成了代理构建、高效梯度投影、迭代效用估计和多样性保持采样。
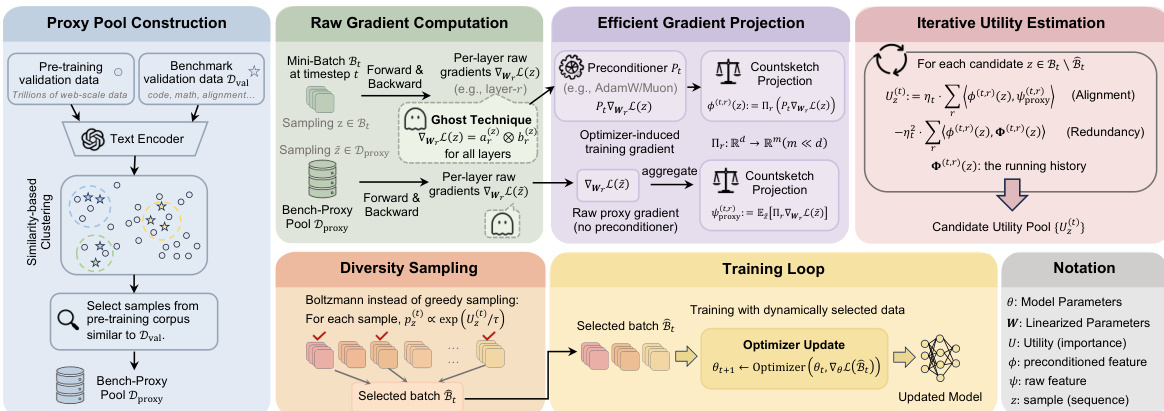
整个过程迭代执行:在每一步,OPUS 计算优化器诱导预处理器 Pt,为代理和候选样本生成每层草图,在投影空间中估计边际效用,通过玻尔兹曼分布采样下一批,然后使用所选子集更新模型。这确保每个训练步骤都由优化器的实际几何结构、代理的任务相关方向和所选数据的多样性指导。
实验
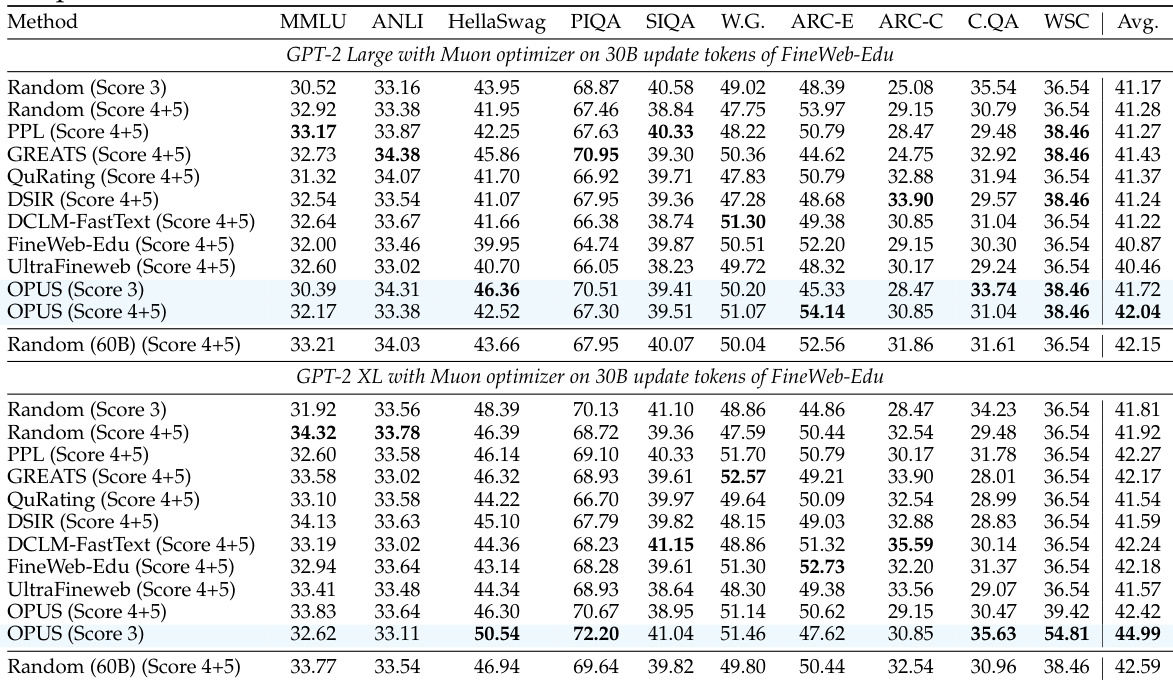
- OPUS 显著提升预训练效率,在 GPT-XL 使用 FineWeb 时,相比随机选择实现 2.2% 平均准确率提升和 8 倍计算减少。
- 即使从较低质量数据(FineWeb-Edu 得分 3)中选择,OPUS 仍优于静态和动态基线,匹配或超过在更高质量数据(得分 4–5)上训练的方法。
- 在 AdamW 和 Muon 优化器下,性能增益均成立,验证了与预处理更新轨迹对齐的数据选择可提升训练信号质量。
- OPUS 超越代理对齐基准,在分布外推理和理解任务中表现更优。
- 在 SciencePedia 上持续预训练时,OPUS 仅用 0.5B token 即达到最佳性能——比在 3B token 上训练的随机选择数据效率高 6 倍——同时在科学领域内表现提升。
- 消融实验证实,随机采样和基准匹配代理至关重要;贪心选择和默认代理表现不佳。
- OPUS 通过 CountSketch 投影保持最小计算开销(4.7% 延迟),优于产生更高选择成本的静态方法。
- 定性上,OPUS 选择更多样化、更广泛有用的样本,而静态方法过度集中于狭窄或高损失模式。
作者使用 OPUS 在预训练期间动态选择训练数据,使选择与优化器特定的更新方向对齐。结果表明,OPUS 在多个模型规模和优化器下始终优于静态过滤和其他动态方法,实现更高平均基准分数,同时保持计算效率。该方法还表现出强大的泛化能力和更快收敛,常匹配或超越使用两倍计算预算训练的模型。
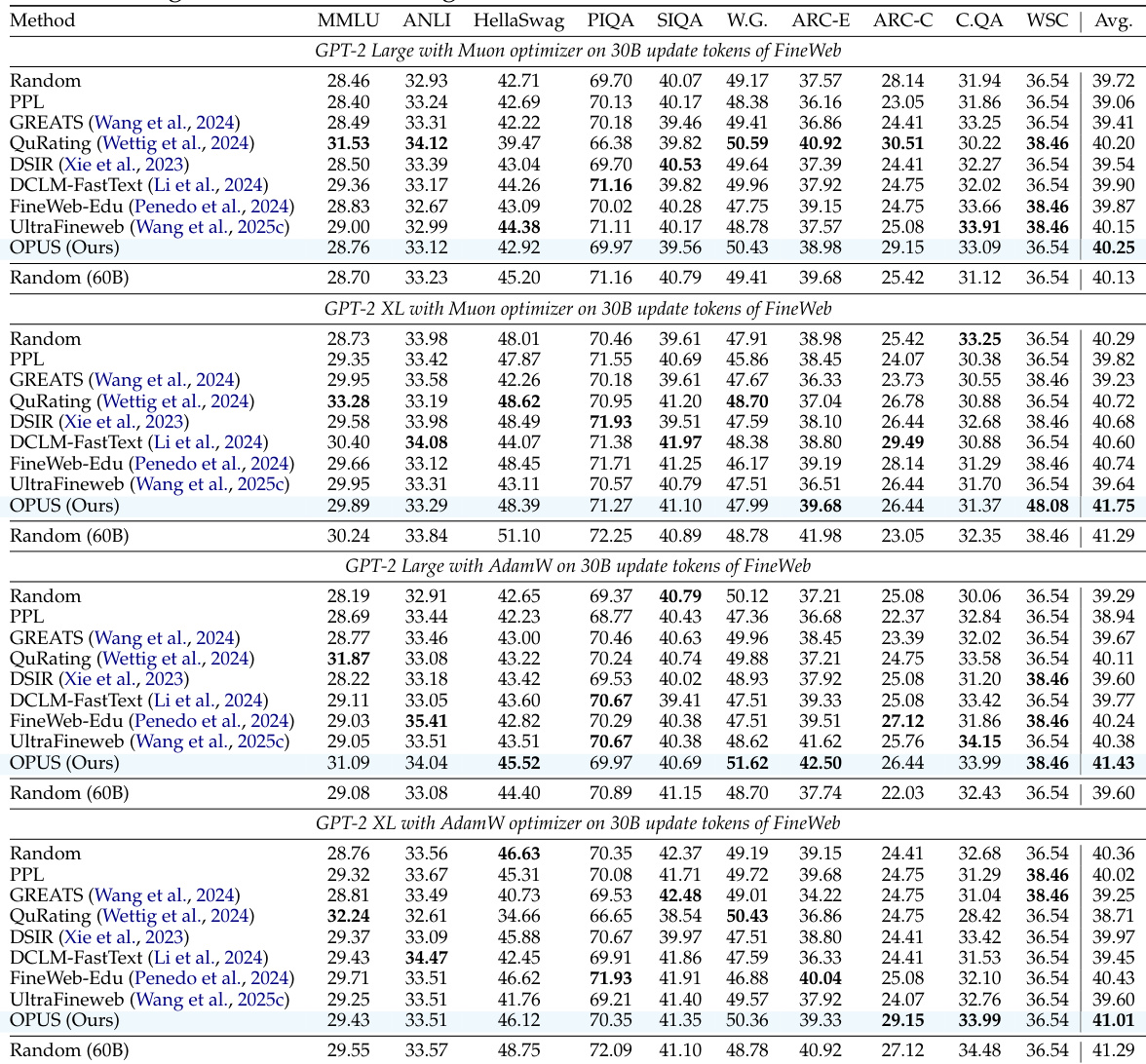
作者在不同超参数(包括缓冲区大小、采样温度和投影维度)下评估 OPUS,发现更大的缓冲区和中等温度表现最佳,而 8192 维投影始终提供最优结果。结果表明,OPUS 在所有配置下均优于随机选择,证实其对超参数变化的鲁棒性。即使调整关键组件,方法的有效性仍保持不变,表明模型性能具有稳定可靠的提升。
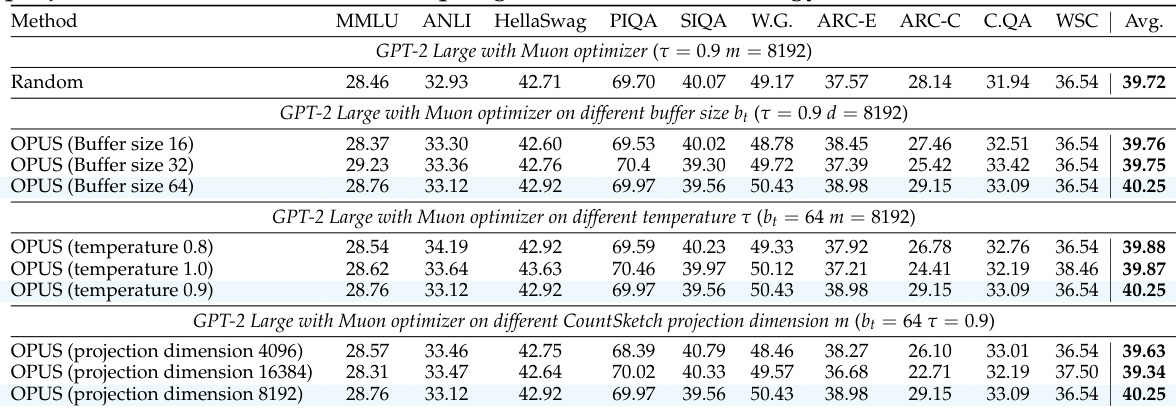
作者使用 OPUS 动态选择与优化器特定更新方向对齐的训练数据,实现比随机、贪心或标准代理选择更高的平均基准性能。结果表明,结合随机采样和基准匹配代理可提升超越狭窄优化信号的泛化能力。OPUS 在相同计算预算下,在多样推理和知识任务中始终优于基线。
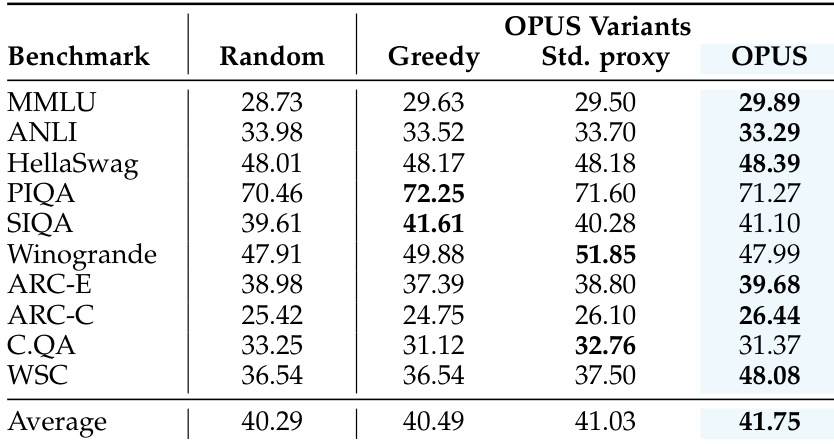
作者使用 OPUS 在预训练期间动态选择训练数据,使选择与优化器特定的更新方向对齐。结果表明,OPUS 在不同模型规模和数据集上始终优于静态和动态基线,即使从较低质量数据子集中选择。该方法实现更强的泛化能力和更快的收敛,同时保持最小计算开销。
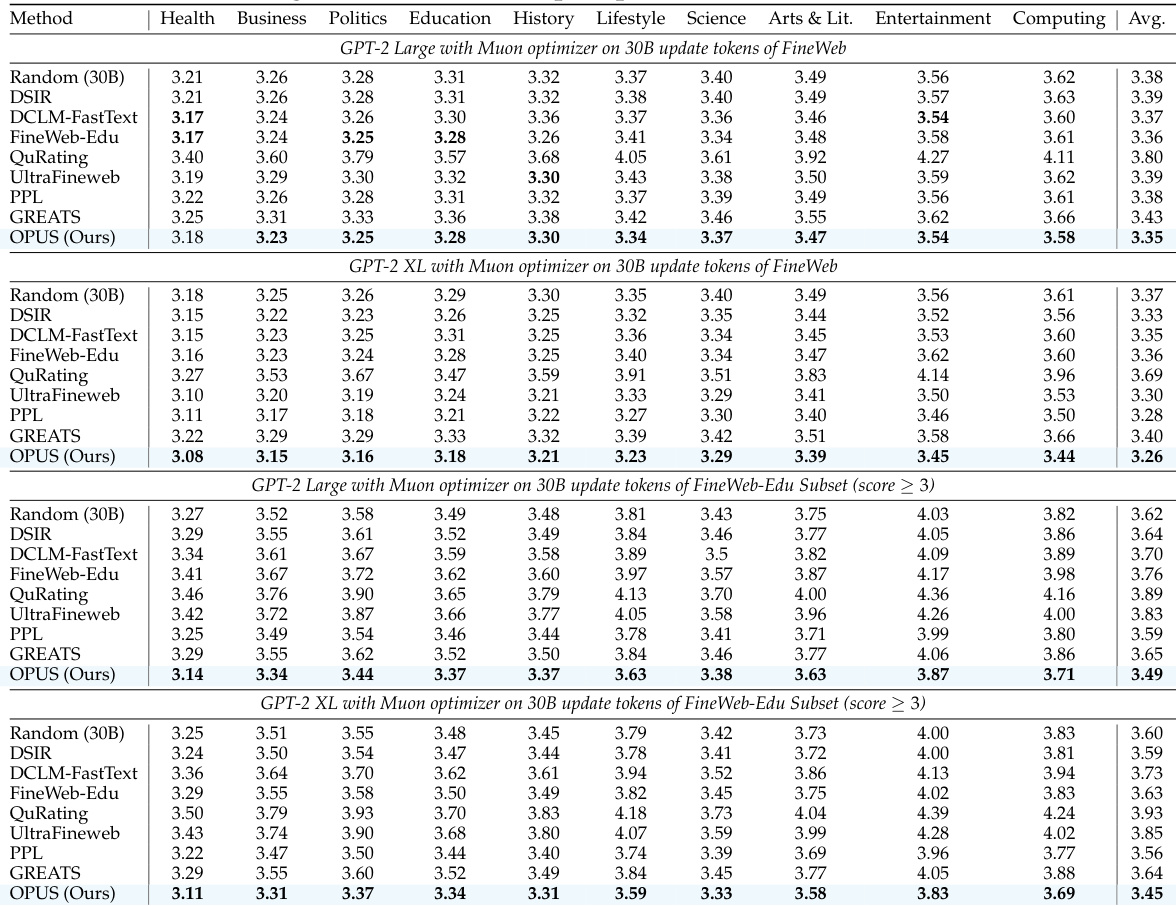
作者使用 OPUS 在预训练期间动态选择训练数据,使选择与优化器的更新方向对齐。结果表明,OPUS 始终优于静态和动态基线——即使从较低质量数据中选择——同时在基准测试中实现更快收敛和更好泛化。该方法也保持高效,相比随机采样仅增加最小计算开销。