Command Palette
Search for a command to run...
循环深度视觉-语言-动作模型:通过潜在迭代推理实现视觉-语言-动作模型的隐式测试时计算扩展
循环深度视觉-语言-动作模型:通过潜在迭代推理实现视觉-语言-动作模型的隐式测试时计算扩展
Yalcin Tur Jalal Naghiyev Haoquan Fang Wei-Chuan Tsai Jiafei Duan Dieter Fox Ranjay Krishna
摘要
当前的视觉-语言-动作(Vision-Language-Action, VLA)模型通常采用固定的计算深度,对简单调整与复杂多步操作均消耗相同的计算资源。尽管思维链(Chain-of-Thought, CoT)提示方法能够实现可变计算量,但其内存开销随计算深度线性增长,且难以适用于连续动作空间。为此,我们提出循环深度VLA(Recurrent-Depth VLA, RD-VLA),一种通过潜在空间迭代精炼实现计算自适应的架构,而非依赖显式的 token 生成。RD-VLA 采用循环结构且权重共享的动作头,可在保持恒定内存开销的前提下支持任意推理深度。模型通过截断时间反向传播(Truncated Backpropagation Through Time, TBPTT)进行训练,以高效监督迭代精炼过程。在推理阶段,RD-VLA 基于潜在状态的收敛性动态分配计算资源,采用自适应停止准则。在具有挑战性的操控任务实验中表明,循环深度至关重要:在单次迭代推理下完全失败(成功率为0%)的任务,采用四次迭代后成功率超过90%;而较简单的任务则在少量迭代后迅速饱和。RD-VLA 为机器人领域提供了可扩展的运行时计算路径,以潜在空间推理替代传统的 token 推理,实现了恒定内存占用,并相较以往基于推理的VLA模型最高提升80倍的推理速度。项目主页:https://rd-vla.github.io/
一句话总结
NVIDIA 和斯坦福大学的研究人员提出了 RD-VLA,这是一种视觉-语言-动作模型,通过潜在空间迭代细化而非基于 token 的推理动态扩展计算量,可在保持恒定内存使用的同时实现 80 倍更快的推理速度,并在复杂机器人任务中达到 90% 以上的成功率。
主要贡献
- RD-VLA 引入了一个循环、权重共享的动作头,通过潜在空间迭代细化实现自适应的测试时计算,消除了固定深度约束,支持任意推理深度且内存占用恒定。
- 该模型采用截断的随时间反向传播进行训练,并根据潜在空间收敛动态停止推理,使模型能为复杂任务分配更多计算资源,而在简单任务上迅速饱和——在具有挑战性的操作任务中将成功率从 0% 提升至 90% 以上。
- 在 LIBERO 和 CALVIN 基准测试中评估,RD-VLA 实现了最先进的性能,LIBERO 上成功率为 93.0%,CALVIN 的 task-5 成功率为 45.3%,同时推理速度比先前基于推理的 VLA 模型快达 80 倍。
引言
作者利用循环、权重共享架构,使视觉-语言-动作(VLA)模型具备自适应测试时计算能力,解决了先前系统无论任务复杂度如何均消耗固定计算资源的关键限制。现有基于推理的 VLA 依赖显式 token 生成(如思维链),其内存随推理深度线性增长,并迫使推理在有损、离散的输出空间中进行,对连续机器人控制效率低下。RD-VLA 则完全在固定维度的潜在空间内执行迭代细化,训练时使用截断的随时间反向传播,推理时采用自适应停止准则动态分配计算资源。该设计使推理速度比基于 token 的推理模型快达 80 倍,同时保持恒定内存使用,并在 LIBERO 和 CALVIN 等基准测试中实现最先进的性能,包括在毛巾折叠、面包烘烤等实际任务中的迁移能力。
方法
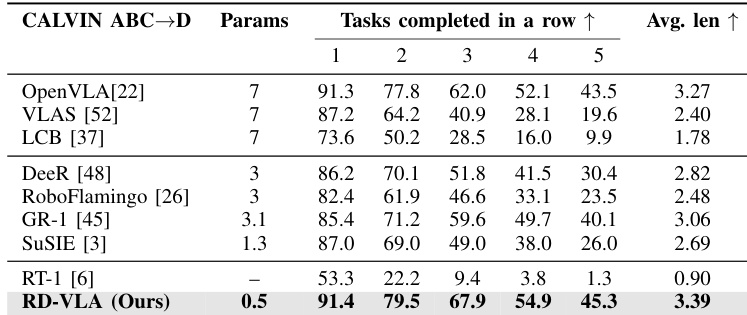
作者采用一种名为循环深度视觉-语言-动作(RD-VLA)的新架构,将计算深度与预训练视觉-语言骨干网络的固定结构约束解耦。不同于依赖固定深度 MLP 头或输出空间迭代方法(如扩散模型),RD-VLA 将计算负担转移到一个权重共享的循环 Transformer 核心,该核心完全在连续潜在流形内运行。这使得模型可通过展开循环块至任意深度 r 实现动态测试时计算缩放,从而为复杂任务分配更多计算,为简单任务分配更少计算,如 LIBERO-10 的性能曲线所示。
RD-VLA 的动作头设计为与骨干网络无关,此处使用基于 Qwen2.5-0.5B 的 VLM,并附加 64 个学习得到的潜在 token,在 LLM 前向传播过程中关注多模态上下文。VLM 执行后,隐藏状态被划分为任务/视觉表示 hvis∈R512×D 和潜在特定表示 hlat∈R64×D。这些表示与本体感知 p 拼接,形成静态条件流形 [hvis+lat(24);p],为循环推理过程提供基础。
该架构遵循功能三元组:序曲(Prelude)、循环核心(Recurrent Core)和尾声(Coda)。序曲 Pϕ 消耗 K=8 个学习查询,首先进行双向自注意力,然后交叉关注 VLM 的中间层特征 hvis+lat(12),生成有基础的潜在表示:
Spre=Pϕ(Queries,hvis+lat(12))∈RK×D同时,潜在草稿区 S0 从高熵截断正态分布初始化:
S0∼TruncNormal(0,γinit⋅σinit)这种噪声初始化确保模型学习稳定的细化算子,而非过拟合固定起点。
循环核心 Rθ 通过持续输入注入维持表示稳定性,执行迭代细化。在每次迭代 k 中,当前草稿状态 Sk−1 与静态基础 Spre 拼接,通过学习的适配器映射回流形维度并归一化:
xk=RMSNorm(γadapt⋅Wadapt[Sk−1;Spre])然后通过权重共享的 Transformer 块更新草稿:
Sk=Rθ(xk,[hvis+lat(24);p])此处,Rθ 对 K 个查询执行双向自注意力,并使用从拼接条件流形派生的键/值执行门控交叉注意力。这确保模型在展开过程中始终扎根于物理观测。

当循环达到深度 r 时,收敛的草稿 Sr 由尾声 Cψ 处理,其通过自注意力和高层 VLM 特征执行最终解码。输出被投影到机器人的动作空间:
a=Wout⋅RMSNorm(Cψ(Sr,[hvis(24);hlat(24);p]))训练采用随机循环:迭代次数 N 从重尾对数正态泊松分布中采样,μrec=32。使用截断 BPTT,仅通过最后 d=8 次迭代传播梯度,迫使模型从任何噪声初始化学习迭代细化至稳定流形。
推理时,通过监控连续预测动作间的 L2 距离实现自适应计算:
∣∣ak−ak−1∣∣22<δ其中 δ=1e−3。这允许模型自我调节计算:简单任务提前终止,复杂任务分配更多迭代。
自适应执行进一步将推理深度与动作时域耦合。对于高不确定性状态(k∗>τ),执行时域截断为 Hshort;否则保持 Hlong。或者,采用线性衰减计划,使时域随迭代次数反向减少:
Hexec(k∗)=max(Hmin,Hmax−max(0,k∗−τbase))这确保代理在高计算需求下更频繁地重新规划,优先保障复杂场景中的安全性。
实验
- 循环计算显著提升操作任务性能,8–12 次迭代后增益趋于平稳,表明超过该点回报递减。
- 任务复杂度差异显著,需不同数量的推理步骤;自适应计算根据任务难度动态分配计算资源,无需预设规则。
- 自适应策略(尤其是二元自适应)与固定深度性能相当,同时将推理成本降低高达 34%,证实条件依赖的计算分配比统一预算更有效。
- 潜在空间推理优于端到端和 token 级推理方法,在 LIBERO 和 CALVIN 基准测试中以更小模型规模(0.5B 参数)实现最先进结果。
- 在双臂机器人上的实际部署显示其在家庭任务中具有强鲁棒性,固定深度变体在多数场景中表现优异,自适应变体保持竞争力并实现效率提升。
- 该方法证明了在物理系统中的可行性,为不确定性感知执行开辟了路径,但深度泛化和饱和仍是未来工作的关键限制。
作者将潜在空间推理方法与端到端和 token 级推理方法进行对比,表明 RD-VLA 在 LIBERO 基准测试中以显著更少的参数实现最先进的性能。结果表明,RD-VLA 的固定和自适应版本在各类任务中均优于先前方法,自适应版本在降低平均推理成本的同时保持强劲性能。研究结果支持:与基于 token 或直接动作预测的方法相比,迭代潜在空间推理在机器人操作中更参数高效且更有效。
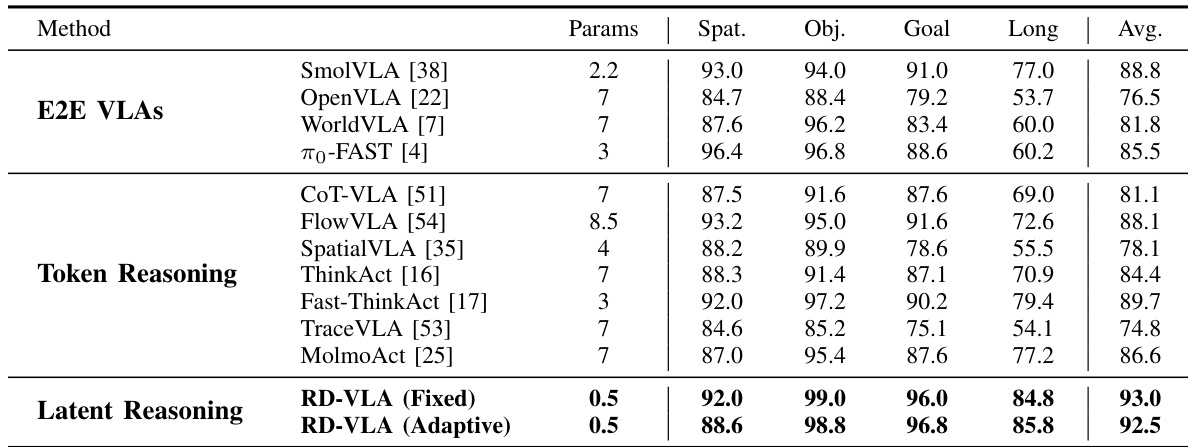
作者评估了其循环推理模型的自适应计算策略,表明基于任务复杂度动态分配推理步骤可实现与固定深度模型相当的性能,同时降低平均计算成本。结果表明,不同任务类别自然需要不同数量的迭代,二元自适应等自适应方法在效率和成功率之间取得最佳平衡。模型根据状态不确定性自我校准计算的能力证明了其在实际部署中的实用性。
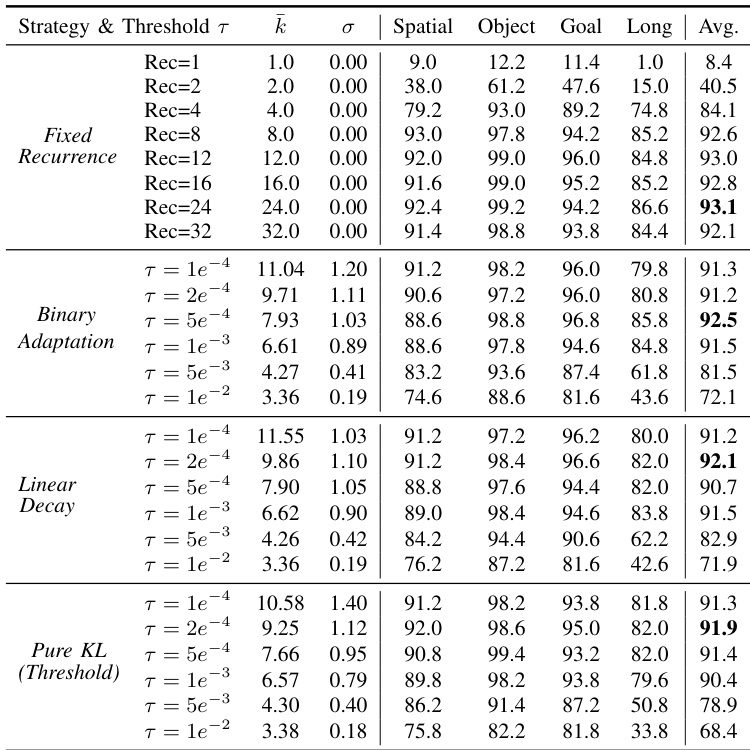
作者在 CALVIN ABC→D 基准测试中评估其 RD-VLA 模型,显示其完成的任务序列长于先前方法,平均链长达到最高的 3.39。尽管仅使用 0.5B 参数——远少于大多数基线模型——该模型通过潜在迭代推理展现出强大的序列规划能力。结果证实,循环深度可提升长时域操作任务的性能,无需大规模架构。