Command Palette
Search for a command to run...
步骤 3.5 快闪:以 11B 激活参数开启前沿级智能
步骤 3.5 快闪:以 11B 激活参数开启前沿级智能
摘要
我们推出 Step 3.5 Flash,这是一款稀疏的混合专家(Mixture-of-Experts, MoE)模型,旨在连接前沿水平的智能体(agent)能力与计算效率之间的鸿沟。在构建智能体时,我们聚焦于最核心的两大要素:精准的推理能力与快速、可靠的执行效率。Step 3.5 Flash 采用 1960 亿参数的基础模型,仅激活 110 亿参数,从而实现高效的推理性能。该模型通过交错式 3:1 滑动窗口注意力与全注意力机制,结合多标记预测(Multi-Token Prediction, MTP-3)技术,显著降低了多轮智能体交互中的延迟与计算成本。为实现前沿级别的智能水平,我们设计了一套可扩展的强化学习框架,融合可验证信号与偏好反馈,在大规模离策略(off-policy)训练下仍保持稳定,从而在数学、代码生成及工具使用等多个领域实现持续的自我优化与提升。在多项基准测试中,Step 3.5 Flash 表现优异:在 IMO-AnswerBench 上达到 85.4% 的准确率,在 LiveCodeBench-v6(2024.08–2025.05)上达到 86.4%,在 tau2-Bench 上达到 88.2%,在包含上下文管理能力的 BrowseComp 上取得 69.0% 的成绩,在 Terminal-Bench 2.0 上达到 51.0%,其综合表现与 GPT-5.2 xHigh、Gemini 3.0 Pro 等前沿模型相当。通过重新定义效率边界,Step 3.5 Flash 为在真实工业场景中部署复杂智能体提供了高密度、高性价比的基础模型支撑。
一句话摘要
StepFun 团队推出 Step 3.5 Flash,一款采用 1960 亿参数 MoE 架构、每次前向仅激活 110 亿参数的模型,结合滑动窗口/全注意力机制与 MTP-3,实现高效智能体推理,在数学、代码和工具任务上达到前沿水平,同时支持可扩展的工业部署。
核心贡献
- Step 3.5 Flash 采用稀疏混合专家架构,总参数 1960 亿,但每次前向仅激活 110 亿参数,通过混合 3:1 滑动窗口/全注意力机制和多令牌预测优化,降低多轮智能体交互延迟。
- 模型采用可扩展强化学习框架,整合可验证信号与偏好反馈,确保稳定离策略训练,驱动数学、代码和工具使用任务的自我提升。
- 在多个基准测试中表现优异,包括 IMO-AnswerBench(85.4%)、LiveCodeBench-v6(86.4%)和 Terminal-Bench 2.0(51.0%),性能媲美 GPT-5.2 xHigh 和 Gemini 3.0 Pro 等前沿模型,同时支持高效工业部署。
引言
作者采用稀疏混合专家(MoE)架构,总参数 1960 亿中仅激活 110 亿,实现前沿级智能体能力,同时保持低推理延迟与成本——这对真实场景智能体部署至关重要。此前大语言模型的强化学习方法常因高梯度方差、离策略偏差及训练/推理基础设施不匹配而稳定性不足。其核心贡献是可扩展 RL 框架,整合可验证信号与偏好反馈,通过 MIS-Filtered Policy Optimization(MIS-PO)稳定训练,实现数学、代码与工具使用任务的持续自我提升,同时性能媲美 GPT-5.2 xHigh 和 Gemini 3.0 Pro 等顶尖闭源模型。
数据集
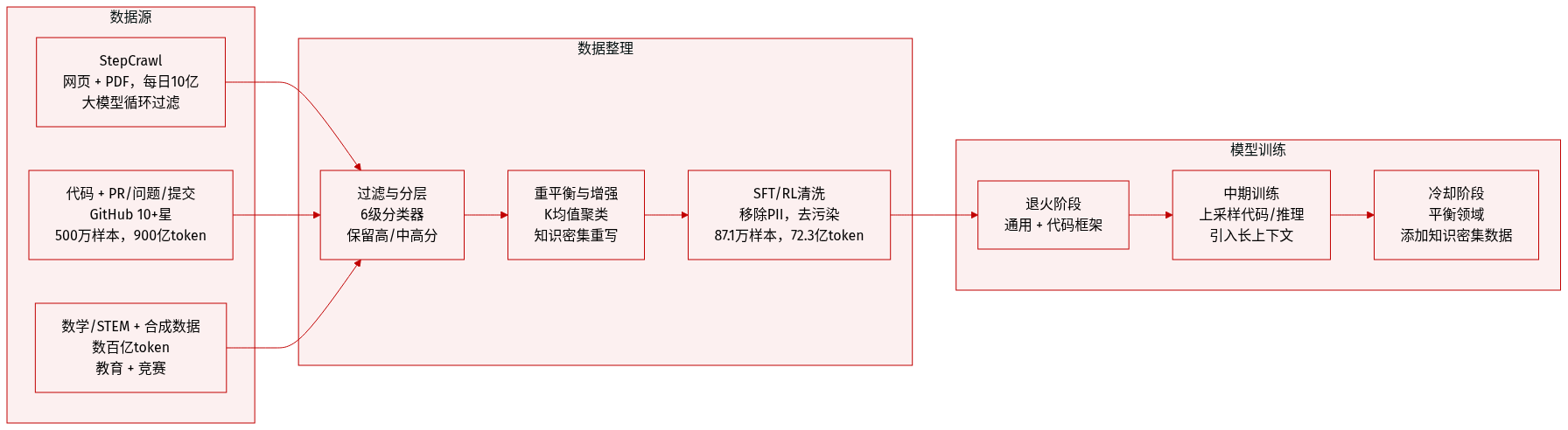
作者使用高度精选的多源训练语料,支持智能体推理、编码与通用知识。以下是简要分解:
-
数据集构成与来源
语料融合通用开放域数据(通过 StepCrawl)、代码数据(改进版 OpenCoder 流程)、PR/Issue/Commit 数据(GitHub 上星数≥10 的仓库)以及合成/半合成工具使用与推理数据。STEM/数学数据通过 StepCrawl 采集并辅以教育内容增强。 -
关键子集详情
- StepCrawl:内部爬虫采集 HTML、ePub、PDF;通过 LM-in-the-loop 评分、去重与净化过滤,日处理约 10 亿页面。
- 代码数据:接受含 0–6 个启发式违规的文档(非严格零容忍),中期训练时上采样。
- PR/Issue/Commit 数据:来自 GitHub 的 500 万样本;包含 Base(与 SWE-Bench 去重)、PR-Dialogue(900 亿 token,基于 Agentless 模板)、Rewritten Reasoning(120 亿 token)及 Environment-based Seed Data(可执行测试补丁)。
- 数学/STEM:通过 StepCrawl 采集数千亿 token + 1 亿教育样本;经 MegaMath 集成 + FineMath 过滤。
- SFT 数据:经规则 + 模型过滤、去污染及领域精炼后,保留 87.1 万样本(72.3 亿 token)。
- RL 数据:聚合 2024 年前竞赛题、合成算术与推理环境数据;按独特性与难度过滤。
-
训练使用与混合策略
数据按阶段混合:- 退火阶段:强调通用知识 + 代码支架。
- 中期训练:上采样代码、PR-Dialogue 与推理数据;引入长上下文样本。
- 冷却阶段:平衡领域采样概率;整合知识密集型增强样本。
混合比例通过消融实验优化,以提升基准性能。
-
处理与元数据
- 质量分层:文档由 6 个轻量级分类器评分;保留高/中高分层。
- 嵌入重平衡:K-means 聚类(10 万+簇)对过度代表主题降采样。
- 知识增强:两阶段流程检索并转换高密度段落。
- 元数据:领域标签、命中计数(代码)、执行标志(代码/STEM)指导采样。
- 基础设施:运行于混合 CPU/GPU 集群,支持 Spark/Ray,存储基于 OSS/HDFS/JuiceFS。
- SFT/RL 过滤:移除 PII、有害内容、语言不一致数据,通过 n-gram/数字掩码匹配去污染。
方法
作者为 Step 3.5 Flash 设计协同架构,明确优化智能体工作流中的低墙钟延迟,平衡长上下文预填充与多轮交互解码。模型核心设计包含三项关键创新:混合注意力机制、稀疏混合专家(MoE)配专家并行负载均衡、多令牌预测(MTP)头用于推测解码。
骨干为 45 层稀疏 MoE Transformer,前 3 层使用稠密前馈网络(FFN),其余 42 层使用 MoE FFN。每 MoE 层每 token 激活 288 个路由专家中的 8 个,外加 1 个共享专家,总容量 1960 亿参数,但每 token 激活限制为 110 亿。此配置确保高知识容量而不牺牲推理速度。为缓解分布式部署中的拖尾效应,作者引入 EP-Group Balanced MoE Routing 策略,显式促进专家并行层级的均匀利用率,其损失函数惩罚专家组激活频率不平衡。
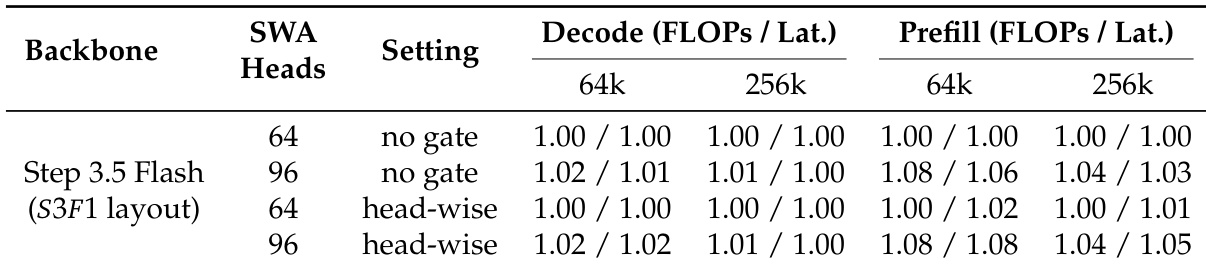
注意力结构为混合布局,以 3:1 比例(S3F1)交替三层滑动窗口注意力(SWA)与一层全注意力,在堆栈中重复。此布局平衡长上下文效率与强长距离连接性。为补偿朴素 SWA 的性能退化,作者将 SWA 查询头数从 64 增至 96,并引入头级门控注意力。该门控机制按注意力头应用,通过计算输入依赖标量门动态调制信息流,有效在注意力机制中引入数据依赖的 sink token。此方法保留标准注意力语义,同时提升性能,未显著增加 FLOPs 或延迟。
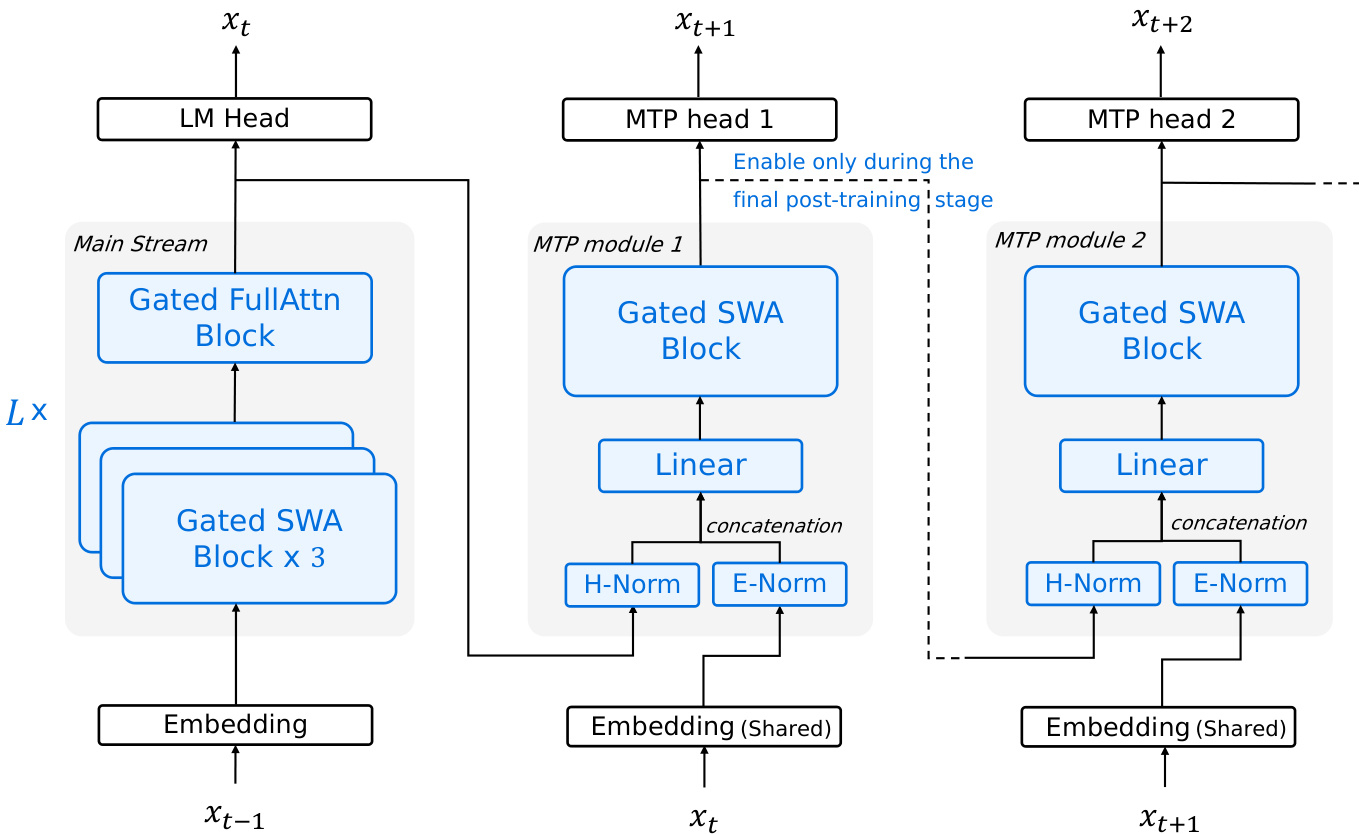
如下图所示,模型还集成三个轻量级 MTP 头,每个预测位置 t 隐藏状态条件下偏移 xt+2、xt+3、xt+4 的令牌。每个 MTP 头由门控 SWA 块、线性层与归一化模块组成,与主干共享嵌入。为控制训练开销,仅 MTP-1 在主预训练阶段训练;MTP-2 与 MTP-3 从 MTP-1 克隆,在轻量级最终后训练阶段联合微调。此模块化设计实现激进多令牌推测,无比例延迟惩罚,尤其利于带宽受限硬件。
模型参数限制在 2000 亿以内,以适配高端工作站 128GB 内存预算。训练通过 Steptron 框架协调,支持混合并行,包括 8 路流水线并行、8 路专家并行和 ZeRO-1 数据并行。关键工程优化包括注意力与 MoE 模块的解耦并行、架构感知通信调度、Muon ZeRO-1 重分片以降低通信开销。内核级优化融合注意力与 MoE 层算子,细粒度选择性检查点通过仅重计算内存密集组件降低峰值内存。
训练分多阶段课程:初始开放域预训练(4k 上下文),随后退火转向代码与推理密集数据并扩展上下文至 32k,中期训练扩展上下文至 128k。后训练采用统一 SFT 流程,后接基于 MIS-Filtered Policy Optimization(MIS-PO)的领域特定 RL,通过在 token 与轨迹层级过滤分布外样本稳定训练。奖励系统解耦可验证与不可验证任务,STEM 使用基于规则与模型的验证器,偏好任务使用生成奖励模型(GenRM),并辅以 MetaRM 惩罚虚假推理。
实验
- 混合注意力布局显示明确的成本-质量权衡:S3F1 FLOPs 最低但性能下降;增加 SWA 查询头(S3F1+Head)以最小成本恢复大部分质量,成为长上下文工作负载默认配置。
- 头级门控注意力在大规模预训练中持续优于 sink token,提升平均基准得分,被采用为默认机制。
- 训练稳定性通过诊断堆栈维持,检测并缓解三类关键问题:数值爆炸、死专家、局部激活激增——尤其在深层 MoE 层,激活裁剪比权重裁剪更有效。
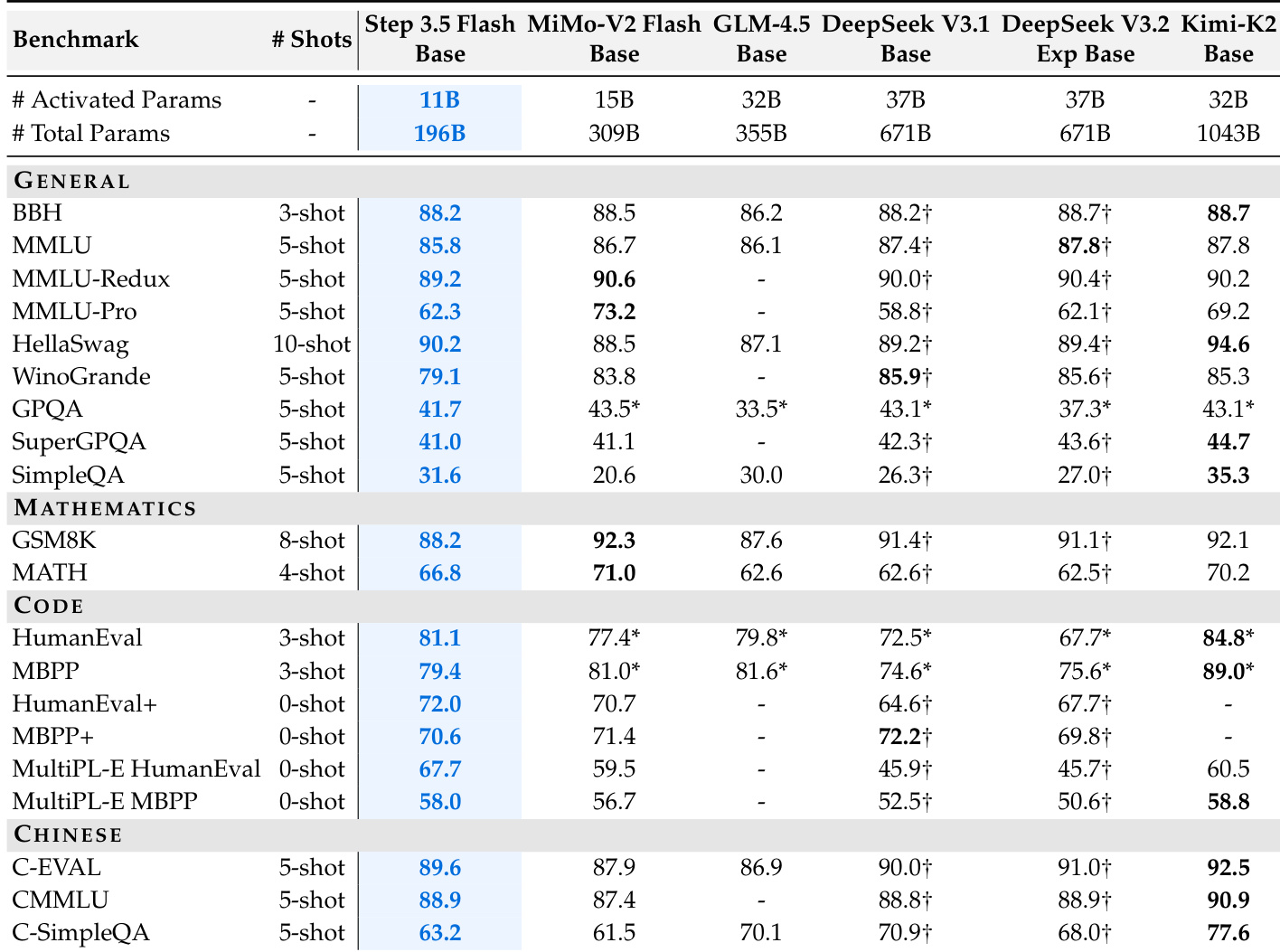
- 尽管仅激活 110 亿参数,Step 3.5 Flash 在推理、数学、编码与中文基准上表现媲美或优于更大模型,展现强大能力密度。
- 后训练评估显示在智能体任务(如 SWE-Bench、Terminal-Bench、GAIA、τ²-Bench)中表现强劲,媲美 GPT-5.2 和 Gemini 3.0 Pro,尤其在工具使用与长视野决策中。
- 采用 MIS-PO 的 RL 训练在样本效率与稳定性上优于 GSPO,适用于稠密与 MoE 模型,实现可扩展离策略训练,控制训练-推理偏差。
- 模型擅长利用外部工具,在 GAIA 与 xbench-DeepSearch 等基准上显示最高工具使用增益,表明强检索与推理整合能力。
- 上下文管理策略(如 Discard-all、Multi-agent)显著影响深度搜索任务表现,多智能体编排通过分解与并行推理获得最佳结果。
- 在真实顾问场景中,Step 3.5 Flash 总体得分媲美 Gemini 3.0 Pro,逻辑与幻觉抑制更优,适合高风险咨询。
- 边缘-云协作(Step 3.5 Flash + Step-GUI)在移动 GUI 基准上显著优于纯边缘执行,验证分布式智能体架构有效性。
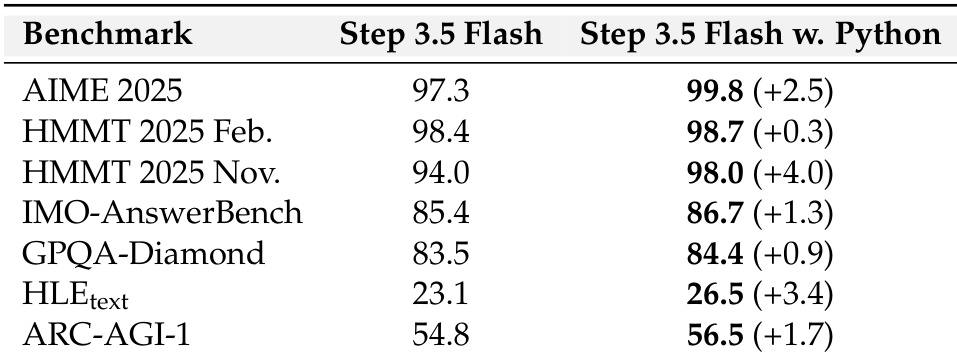
作者在多个推理与智能体基准上评估 Step 3.5 Flash(启用与禁用 Python 执行能力)。结果表明启用 Python 执行持续提升性能,增益范围 +0.3 至 +4.0 分,表明工具集成增强模型解决复杂计算密集型任务能力。最大提升出现在数学与代码相关基准,凸显外部工具使用对增强推理能力的价值。
Step 3.5 Flash 在咨询与推荐基准上表现强劲,得分 39.6%,与 Gemini 3.0 Pro 持平,同时推理成本更低。模型优于 DeepSeek V3.2,略逊于 Claude Opus 4.5 与 GPT-5.2,反映其在真实顾问任务中推理质量与效率的强平衡。

Step 3.5 Flash 在通用、数学、编码与中文基准上表现强劲,尽管总参数 1960 亿中仅激活 110 亿,展现强大能力密度。模型在 BBH 与 SimpleQA 等关键指标上匹配或超越更大稀疏基线,凸显其每参数高效性能。结果证实其架构在保持成本-质量权衡的同时,实现稳健推理与编码能力。
作者评估模型中不同注意力布局与头配置,发现 S3F1 布局中增加 SWA 查询头显著提升多个基准性能,同时保持效率。结果表明 S3F1+Head 变体在 MMLU 与 SimpleQA 等关键指标上优于全注意力基线,并获得最高平均预训练得分。此配置在计算成本与模型质量间取得最佳平衡,成为长上下文工作负载首选。

作者评估 Step 3.5 Flash 在不同 SWA 头数与门控策略下的注意力效率,发现增加 SWA 头数轻微提升 FLOPs,但因 IO 限制行为对延迟影响极小。头级门控相比无门控引入可忽略开销,确认其轻量特性。总体而言,S3F1 布局配头级门控与 96 个 SWA 头为长上下文工作负载提供最佳效率与性能平衡。