Command Palette
Search for a command to run...
世界-VLA-环:视频世界模型与VLA策略的闭环学习
世界-VLA-环:视频世界模型与VLA策略的闭环学习
Xiaokang Liu Zechen Bai Hai Ci Kevin Yuchen Ma Mike Zheng Shou
摘要
近年来,机器人世界模型的进展得益于视频扩散变换器(video diffusion transformers)的应用,这类模型能够基于历史状态和动作预测未来的观测结果。尽管这些模型可以生成逼真的视觉输出,但其在动作跟随精度方面表现较差,限制了其在下游机器人学习任务中的实际应用。在本工作中,我们提出了 World-VLA-Loop,一个用于联合优化世界模型与视觉-语言-动作(Vision-Language-Action, VLA)策略的闭环框架。我们设计了一种状态感知的视频世界模型,通过联合预测未来的观测结果与奖励信号,作为高保真度的交互式模拟器。为提升模型的可靠性,我们构建了 SANS 数据集,该数据集引入了接近成功的轨迹,以增强世界模型中动作与结果之间的对齐能力。该框架实现了在虚拟环境中完全闭环的 VLA 策略强化学习(RL)后训练流程。关键在于,我们的方法形成了一种协同进化循环:由 VLA 策略生成的失败轨迹被迭代反馈至世界模型,用于提升其预测精度,进而反向促进后续强化学习的优化效果。在仿真与真实世界任务中的评估结果表明,该框架在极少依赖物理交互的情况下显著提升了 VLA 模型的性能,建立了世界建模与策略学习之间的互利共生关系,为通用机器人系统的发展提供了新范式。项目主页:此链接。
一句话总结
Show Lab 的研究人员提出了 World-VLA-Loop,这是一种通过迭代失败反馈共同优化视频世界模型与 VLA 策略的闭环框架,借助 SANS 数据集提升动作跟随精度,并在仿真中实现高保真强化学习训练,使真实机器人任务成功率提升 36.7%。
主要贡献
- 我们引入了 World-VLA-Loop,这是一种闭环框架,通过策略的失败回放迭代协同优化世界模型与视觉-语言-动作(VLA)策略,提升模型的动作跟随精度并增强下游强化学习性能。
- 我们的状态感知视频世界模型通过联合预测未来观测与奖励信号实现高保真仿真,使用包含近成功轨迹的 SANS 数据集训练,以增强动作-结果对齐并减少在错误动作下对成功结果的幻觉。
- 在 LIBERO 基准和真实世界任务上的评估表明,我们的框架在两次迭代后将 VLA 成功率提升 36.7%,同时最小化物理交互,证明其在弥合仿真到现实差距方面对通用机器人任务的有效性。
引言
作者利用基于视频的世界模型实现高效的视觉-语言-动作(VLA)策略强化学习,以应对真实机器人训练的高成本和安全风险。以往的世界模型存在动作跟随不精确和奖励信号不可靠的问题,常在错误动作下幻觉出成功结果,因而不适合用于强化学习。为克服此问题,作者引入 World-VLA-Loop —— 一种联合训练世界模型与 VLA 策略的闭环框架:策略的失败回放用于改进模型的动作条件预测,而改进后的模型则支持更有效的强化学习。作者还引入了包含近成功轨迹的 SANS 数据集,以强化动作-结果对齐,从而构建能够同时预测视频帧与奖励的高保真状态感知世界模型。评估显示,仅经两次迭代,真实世界成功率即提升 36.7%,显著降低对物理交互的依赖。
数据集
-
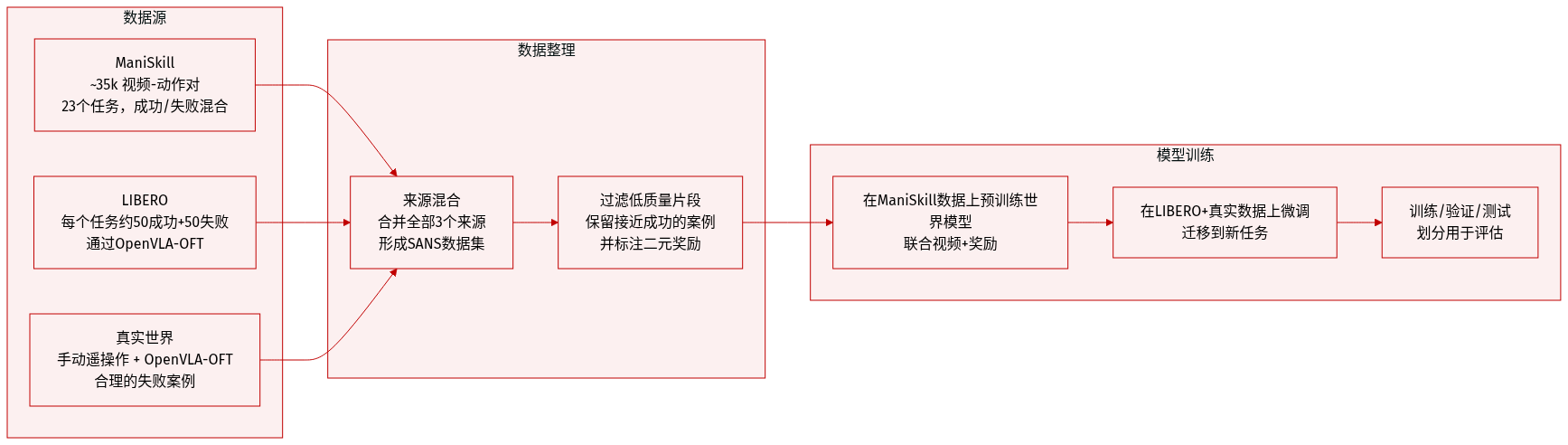
作者使用“成功与近成功数据集”(SANS)训练鲁棒世界模型,该数据集包含因微小定位误差而失败但仍接近目标的轨迹——这对捕捉策略执行中遇到的精细空间动态与真实失败模式至关重要。
-
SANS 数据集从三个来源整理:ManiSkill、LIBERO 和真实机器人设置。在 ManiSkill 中,成功轨迹通过基于真实姿态的策略收集,然后添加扰动生成失败轨迹;额外失败轨迹来自策略回放。在 LIBERO 中,失败轨迹通过 OpenVLA-OFT 回放收集。真实世界数据结合手动遥操作与 OpenVLA-OFT 回放以捕捉合理失败。
-
数据集包含视频-动作对与稀疏二元奖励信号(每步指示是否成功)。对于 ManiSkill,作者在 23 个任务中收集约 35,000 个视频-动作对,混合成功与失败轨迹。对于 LIBERO 和真实世界设置,每个任务收集约 50 个成功和 50 个失败轨迹——数据量虽小,但足以支持微调和迁移。
-
作者首先在 SANS 的 ManiSkill 子集上预训练其动作条件世界模型,使用联合视频与奖励监督。随后在 LIBERO 和真实世界子集上微调模型。完整流程在数据集增强、世界模型预训练、通过 GRPO 的策略回放与部署之间循环——迭代提升模型与策略。
方法
作者采用四阶段框架构建并部署用于视觉-语言-动作(VLA)策略强化学习的状态感知视频世界模型。整体架构旨在使用最少演示高效适应新任务,同时保持高保真视觉与奖励预测。请参阅框架图以获取管道的高层概览。
在第一阶段,作者通过手动编程和策略回放收集轨迹构建 SANS(成功与近成功)数据集。这些轨迹涵盖多样执行结果,包括完全成功与近成功案例,对训练能区分任务完成细微差异的世界模型至关重要。该数据集作为后续模型训练与迭代优化的基础。
第二阶段专注于训练视频世界模型,该模型基于预训练的 Cosmos-Predict 2 架构构建。给定初始观测帧序列 x0,…,xh−1 与机器人动作序列 a1,…,aT∈R6∪{0,1},模型自回归生成未来视频帧 xh,…,xh+T−1。主干采用扩散变换器(DiT),动作条件通过基于 MLP 的动作嵌入器实现,将每个 6 自由度姿态与夹爪状态映射为潜在张量。这些嵌入通过与扩散时间戳嵌入相加融入 DiT,使模型能将视觉预测锚定于提供的控制序列。
为实现内在奖励预测,作者在 DiT 上增加一个轻量级 MLP 奖励头 ϕ,将去噪潜在变量 zt 映射为标量奖励 r^t=ϕ(zt)。模型使用结合流匹配目标与奖励预测误差的联合损失进行训练:
L=Lflow+λt=1∑T∥r^t−rt∥2,其中 λ 根据 EDM 框架按噪声水平调节以稳定训练。此设计确保奖励预测与视觉结果紧密耦合,提升与实际任务成功的对齐度,并促使生成器更好区分成功与失败轨迹。
如下图所示,训练后的世界模型在第三阶段用于 VLA 策略的后训练。作者采用 OpenVLA-OFT 作为基础策略并集成至 SimpleVLA-RL 框架,以学习的视频世界模型替代传统物理模拟器。策略生成动作块,输入世界模型以产生下一个视觉观测与奖励信号。此闭环交互实现完全在神经模拟器内的多步回放。策略更新通过 GRPO 优化进行,使用世界模型奖励预测计算优势值。
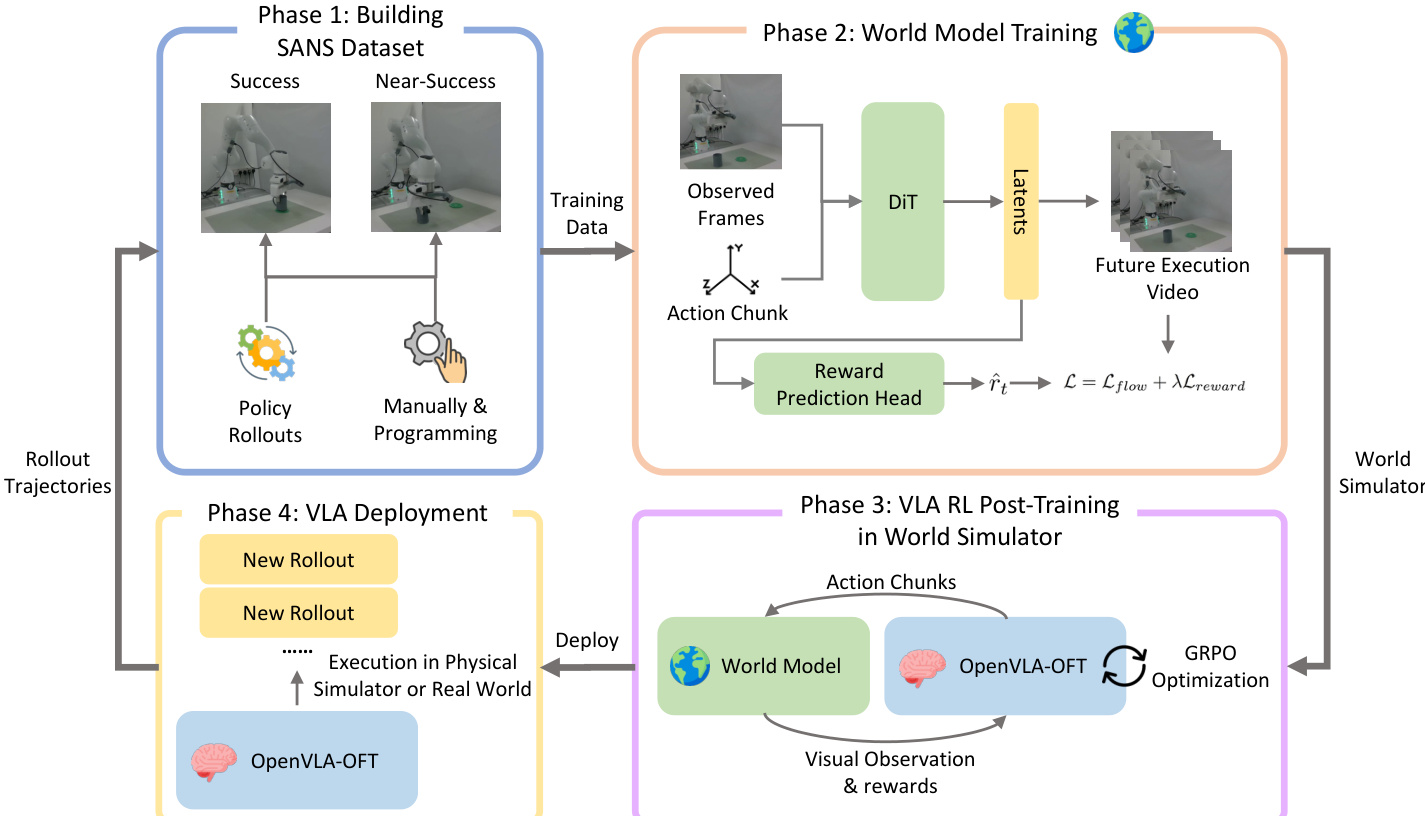
在第四阶段,作者通过在真实世界或物理模拟器中部署优化后的策略收集新回放,闭合循环。这些轨迹——特别是成功与近成功案例——被加入 SANS 数据集,以进一步微调世界模型。此迭代优化循环提升世界模型的预测保真度与策略性能。作者证明,联合优化带来显著提升:从监督微调的 13.3% 成功率,经迭代强化学习优化后,真实世界评估成功率提升至 50.0%。
整个系统采用请求-响应架构支持批量策略回放,可在高端硬件上高效训练。在 NVIDIA H100 上,24 帧视频批处理约需 7 秒,使单任务完整强化学习训练可在 30 小时内完成。此可扩展设计确保实用部署,同时在多样操作任务中维持高视觉与奖励保真度。
实验
- 世界模型展现出高视觉与奖励对齐度,证实其作为策略回放模拟器在仿真与真实世界设置中的可靠性。
- 在模拟器内进行强化学习后训练显著提升策略在 LIBERO 基准与真实世界任务上的成功率,验证模拟器对策略增强的实用性。
- 世界模型与策略的迭代优化进一步提升真实世界精度,凸显联合优化循环的价值。
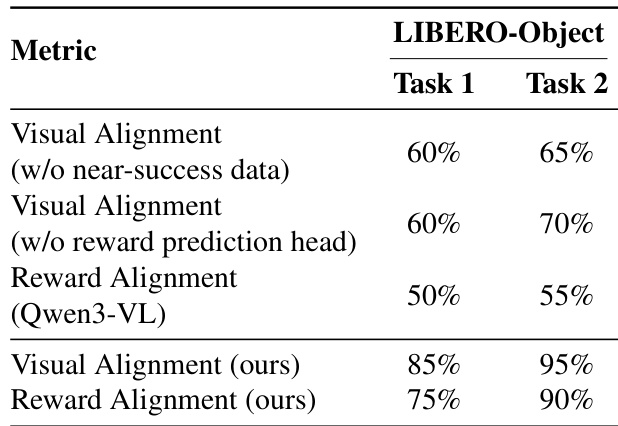
- 消融实验确认,集成奖励预测头对维持生成质量与结果区分至关重要,在可靠性上优于外部视觉-语言模型。
- 训练中包含近成功轨迹对建模失败模式与提升动作-结果保真度至关重要。
- 定性结果显示,世界模型能泛化至新颖动作序列,准确模拟物理后果并区分细微成功-失败边界,支持更鲁棒的策略学习。
作者通过消融实验表明,排除近成功数据或移除奖励预测头会显著降低世界模型的视觉与奖励对齐性能。他们提出的方法包含上述两个组件,在各任务上实现显著更高的对齐率,证明联合训练与多样轨迹覆盖对精确模拟至关重要。结果表明,模型内部奖励头在预测任务结果上优于外部视觉-语言模型,强化其在策略训练中的可靠性。
作者使用世界模型模拟机器人任务执行并通过强化学习优化策略,相比基线取得显著提升。结果表明,在仿真 LIBERO 基准与真实世界任务中成功率均持续提升,真实世界部署中提升最为显著。迭代优化过程通过更好建模边缘案例与失败模式进一步增强策略鲁棒性。

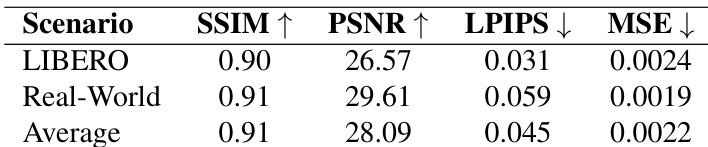
作者使用带奖励预测头的世界模型生成高保真视觉回放,在仿真与真实世界任务中实现超过 85% 的视觉与奖励对齐。结果表明,奖励头与视频生成器的联合训练相比无奖励监督的模型显著提升结果区分能力与视频质量。模型泛化至新颖动作序列并准确模拟失败模式的能力支持其通过迭代强化学习优化 VLA 策略。
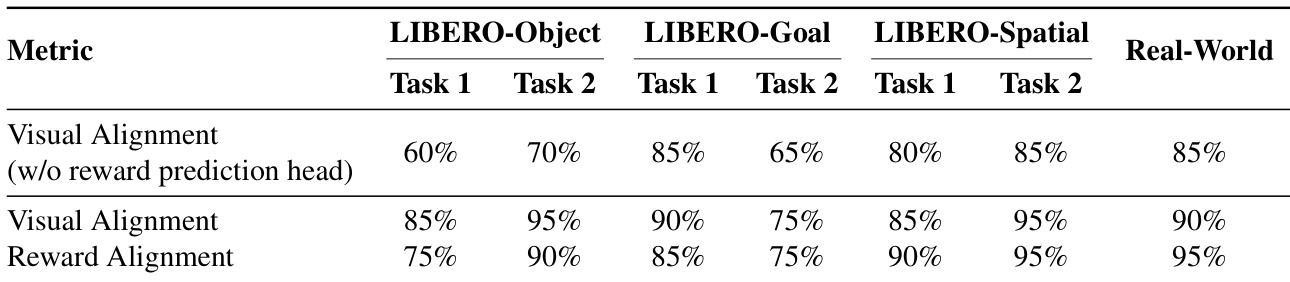
作者使用世界模型模拟机器人任务结果,在仿真与真实世界环境中实现生成与实际视觉及基于奖励结果的高对齐度。结果表明,模型可靠区分成功与失败,视觉与奖励对齐度持续超过 75%,常达 90% 或更高。此保真度支持有效的策略训练与优化,实现多样任务设置下的稳健性能。

作者使用世界模型为策略训练生成高保真视觉序列,在仿真与真实世界设置中实现强大的视频质量指标。结果表明,不同环境间性能一致,SSIM 与 PSNR 得分高,LPIPS 与 MSE 值低,表明模型有效保留结构与感知细节。此视觉可靠性支持下游策略学习的稳定性,并在训练分布外良好泛化。