Command Palette
Search for a command to run...
THINGS-data:用于研究人类大脑与行为中物体表征的大规模多模态数据集集合
THINGS-data:用于研究人类大脑与行为中物体表征的大规模多模态数据集集合
Martin N Hebert Oliver Contier Lina Teichmann Adam H Rockter Charles Y Zheng Alexis Kidder Anna Corriveau Maryam Vaziri-Pashkam Chris I Baker
摘要
要理解物体的表征(object representations),需要对视觉世界中的物体进行广泛且全面的采样,并结合对大脑活动与行为的密集测量。在此,我们推出了 THINGS-data,这是一个大规模的人类神经影像与行为数据集的多模态集合。它包含了高密度采样的功能性磁共振成像(fMRI)和脑磁图(MEG)记录,以及针对多达 1,854 个物体概念、在面对数千张照片图像时所进行的 470 万次相似性判断。THINGS-data 的独特之处在于其拥有极其丰富的标注物体,这使得研究人员能够在进行大规模假设检验的同时,评估以往研究结果的可重复性。除了每个独立数据集所能提供的独特见解外,THINGS-data 的多模态特性允许将不同数据集相结合,从而为物体处理过程提供比以往更广阔的视角。我们的分析证明了这些数据集的高质量,并展示了五个基于假设驱动和数据驱动的应用案例。THINGS-data 是 THINGS 项目(https://things-initiative.org)的核心公开资源,旨在弥合不同学科之间的鸿沟,并推动认知神经科学的发展。
一句话总结
THINGS-data 是一个大规模多模态神经影像与行为数据集集合,通过将高密度功能磁共振成像(fMRI)和脑磁图(MEG)记录与针对多达 1,854 个物体概念、涵盖数千张照片图像的 470 万个相似性判断相结合,旨在研究物体表征。
核心贡献
- 本文介绍了 THINGS-data,这是一个旨在研究人类物体表征的大规模多模态神经影像与行为数据集集合。
- 该数据集将高密度采样的功能磁共振成像(fMRI)和脑磁图(MEG)记录与涵盖多达 1,854 个物体概念的 470 万个相似性判断相结合。
- 该研究通过五个不同的假设驱动和数据驱动的应用展示了这一多模态框架的效用,证明了所收集数据的高质量。
引言
所提供的文本仅包含致谢、资助信息和作者贡献,并未描述研究背景、技术上下文或研究的具体科学贡献。因此,信息不足以总结研究目标或先前工作的局限性。
数据集
数据集描述:THINGS-data
THINGS-data 是一个旨在研究人类大脑和行为中物体表征的大规模多模态集合。研究人员利用了 THINGS 数据库,该数据库包含 1,854 个物体概念和 26,107 张自然图像。
数据集构成与来源 该集合由三种主要模态组成:
- 功能磁共振成像 (fMRI): 从 3 名健康受试者中获取的神经影像数据。
- 脑磁图 (MEG): 从 4 名不同的健康受试者中获取的高时间分辨率神经影像数据。
- 行为数据: 通过 Amazon Mechanical Turk 在线众包方式从 12,340 名工人处收集的感知相似性判断。
关键子集详情
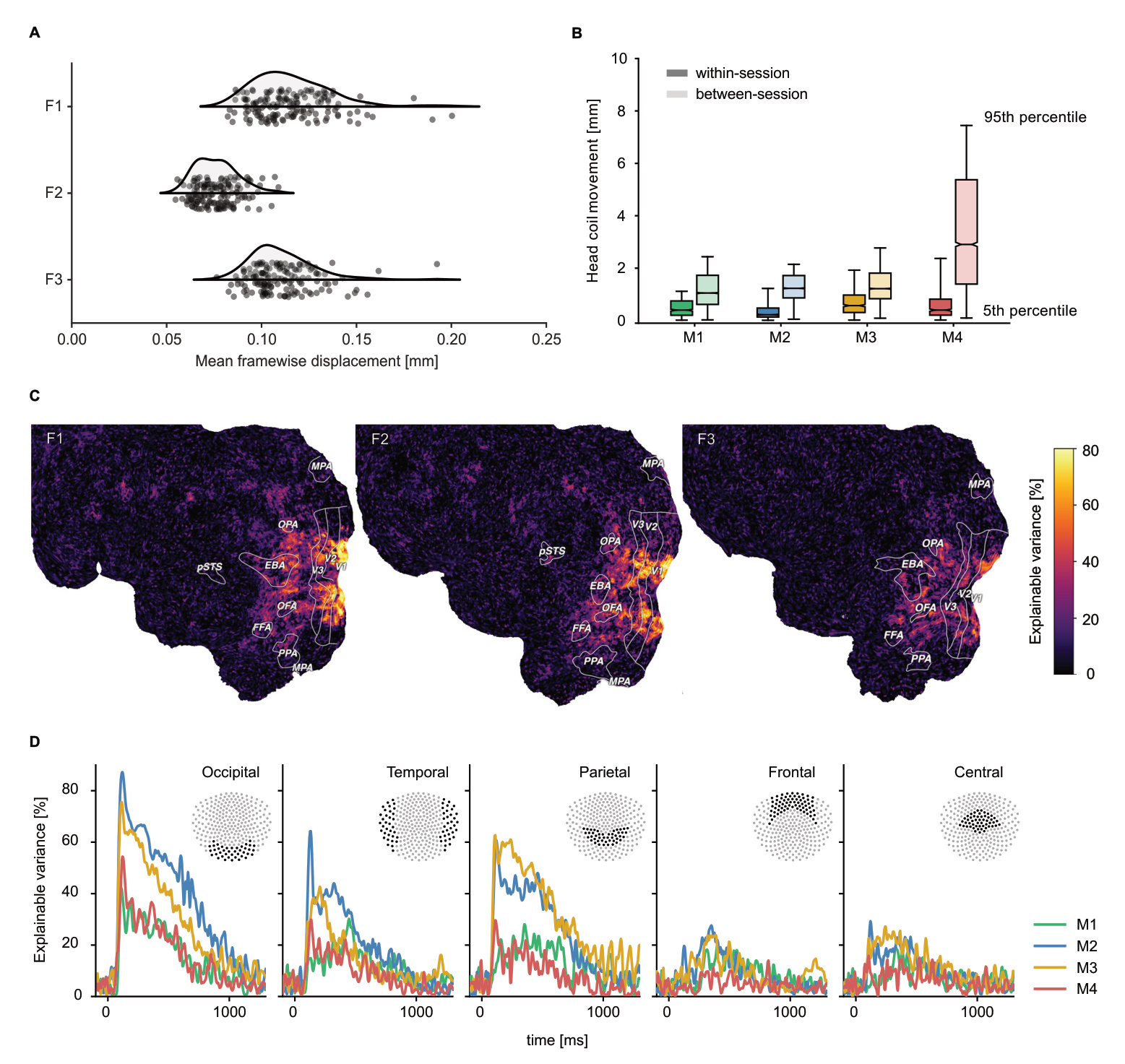
- fMRI 子集: 包括代表 720 个物体概念的 8,740 张唯一图像。为确保数据可靠性,研究人员使用 100 张图像的子集进行噪声上限(noise ceiling)估计和模型测试。
- MEG 子集: 包括代表所有 1,854 个物体概念的 22,448 张唯一图像。使用 200 张图像的子集进行噪声上限估计和模型测试。
- 行为子集: 包含通过三元组“挑出不同者”(odd-one-out)任务收集的 470 万个相似性判断。其中包括 37,000 个被试内三元组,用于估计受试者层面的变异性,以及用于评估数据一致性的额外子集。
数据处理与元数据
- 图像处理: 图像被裁剪为正方形格式,对于不符合尺寸的物体则进行填充。刺激物在中间灰色背景下占据 10 度的视觉角度。
- 神经影像处理:
- fMRI 数据使用 fMRIPrep 和 Freesurfer 进行了层间时间校正、头动校正、易感性失真校正以及空间对齐。
- MEG 数据经过带通滤波(0.1 至 40 Hz)、分段(epoch-based)处理,并降采样至 200 Hz。
- 研究人员为 fMRI 实现了一种基于 ICA 的自定义去噪方法,以将信号与生理噪声分离。
- 眼动追踪: MEG 会话包括 1,200 Hz 的眼动追踪,以监测中央注视。数据经过处理以移除与眨眼和瞳孔扩张峰值相关的样本。
- 元数据构建: 数据集通过语义和图像注释进行了增强,包括高层类别、典型性、物体特征评分和记忆力得分。
论文中的数据使用 研究人员利用这些数据将空间和时间的大脑响应与人类行为联系起来。具体应用包括:
- 模型评估: 使用指定的测试图像子集来评估计算模型。
- 表征分析: 进行多元成对解码、编码分析(专门针对生命力和大小)以及表征相似性分析 (RSA)。
- 多模态融合: 实现一种基于回归的方法,结合 MEG 和 fMRI 响应,以揭示时空分辨率下的信息流。
方法
单试次 fMRI 响应估计
为了应对大规模 fMRI 体素级时间序列中固有的计算挑战和噪声,研究人员实现了一种估计每个单独物体图像 BOLD 响应幅度的方法。这是通过将单试次广义线性模型 (GLM) 拟合到预处理后的时间序列来实现的。该过程首先将每个功能运行的数据转换为百分比信号变化。为了分离任务相关信号,研究人员将时间序列对一组噪声回归量进行回归,其中包括针对每次运行特定的 ICA 噪声分量和最高四阶的多项式回归量。该回归的残差被保留用于后续分析。
为了解释血液动力学响应函数 (HRF) 中的生理变异性,研究人员使用了包含 20 种不同 HRF 的库。对于每个体素,针对这 20 种 HRF 中的每一种都会生成一个单独的 on-off 设计矩阵。通过识别产生最大解释方差的模型,确定每个体素的最佳拟合 HRF。由于快速事件相关设计中的回归量高度相关,研究人员采用了分数岭回归(fractional ridge regression)以防止过拟合。每个体素的正则化参数通过留一会话法(leave-one-session-out)交叉验证进行优化,以最大化留出数据的预测性能。正则化参数的超参数空间经过精细采样,范围从 0.1 到 0.9(步长为 0.1),以及从 0.9 到 1.0(步长为 0.01)。
在确定每个体素的最佳 HRF 和分数岭参数后,拟合单试次模型以获得 beta 系数。由于岭回归可能会在这些系数的尺度上引入偏差,研究人员通过将正则化系数对未正则化系数进行回归,应用线性重缩放,并将所得预测值作为最终的单试次响应幅度。这一过程将高维时间序列转换为一组紧凑的 beta 权重,其中每个体素在每张图像中由单个值表示。
通过 SPoSE 进行行为嵌入
研究人员使用 SPoSE 模型从三元组“挑出不同者”判断中导出低维嵌入。该计算框架旨在识别构成相似性判断的基础的稀疏、非负且可解释的维度。该过程首先使用 90-10 分割将三元组数据分为训练集和测试集。嵌入通过 0 到 1 范围内的 90 个随机维度进行初始化。
对于任何给定的图像三元组,模型计算所有三个可能配对的 90 维嵌入向量的点积。然后对这些乘积应用 softmax 函数,以产生三个预测的选择概率。用于更新嵌入权重的损失函数由两个部分组成:交叉熵损失(softmax 函数的对数)和用于诱导稀疏性的 L1 范数。这两项之间的权衡由正则化参数 λ 控制,该参数通过在训练集上进行交叉验证来确定。
优化使用 Adam 优化器进行,小批量(minibatch)大小为 100 个三元组。优化后,权重低于 0.1 的维度被移除,剩余维度根据其权重之和进行降序排列。为了确保随机优化过程的可重复性,研究人员使用不同的随机种子运行了 72 次该程序。研究人员根据不同嵌入之间平均 Fisher-z 转换后的 Pearson 相关系数,为每个维度计算了一个可重复性指数。最终的嵌入由 66 个维度组成,是基于具有最高平均可重复性而选出的。
实验
研究人员评估了一个大规模的行为、fMRI 和 MEG 数据集,以验证其在研究物体表征方面的效用。通过将行为数据集扩展到 470 万次试验,成功捕捉到了更细粒度的相似性维度,并提高了对类别内评分的预测能力。神经影像分析证实,物体身份和类别都是可靠可解码的,而复制研究表明,已建立的生命力和大小的皮层梯度可以推广到更广泛的物体范围。最后,通过表征相似性分析和直接回归整合这些模态,揭示了人类的相似性判断与神经响应的空间拓扑结构和时间动力学密切相关。