Command Palette
Search for a command to run...
OdysseyArena:面向长时程、主动式与归纳性交互的大型语言模型基准测试
OdysseyArena:面向长时程、主动式与归纳性交互的大型语言模型基准测试
摘要
大型语言模型(LLMs)的迅猛发展推动了具备复杂环境导航能力的自主智能体的诞生。然而,现有的评估范式主要采用演绎式方法,即智能体基于显式提供的规则和静态目标执行任务,通常局限于较短的规划周期。这一范式的关键缺陷在于忽视了智能体从经验中自主发现潜在状态转移规律的归纳必要性,而这种能力正是实现智能体前瞻性认知与维持战略一致性的核心基础。为弥合这一差距,我们提出 OdysseyArena,将智能体评估重新聚焦于长周期、主动且具有归纳性的交互过程。我们形式化并实现了四种基本交互原语,将抽象的状态转移动态转化为具体的交互环境。在此基础上,我们构建了 OdysseyArena-Lite,用于标准化基准测试,提供一套包含120个任务的评估集,用以衡量智能体在长周期场景下的归纳效率与发现能力。为进一步挑战智能体的稳定性,我们还推出了 OdysseyArena-Challenge,旨在在极端交互周期(如超过200步)下检验智能体的性能表现。在15种以上主流LLM上的广泛实验表明,即便前沿模型在归纳性场景中仍表现出显著不足,揭示了在复杂环境中实现自主发现能力的关键瓶颈。我们的代码与数据已开源,可通过 https://github.com/xufangzhi/Odyssey-Arena 获取。
一句话总结
徐方志、严航、孙秋实等人提出了 ODYSSEYARENA,这是一种强调归纳性、长视野智能体交互的新型评估框架,与以往的演绎式方法形成对比;该框架引入了 ODYSSEYARENA-LITE 和 -CHALLENGE 基准测试,揭示了大语言模型在复杂环境中自主发现能力方面的关键局限。
主要贡献
- 我们提出了 ODYSSEYARENA,一种新的评估框架,将智能体评估从演绎式任务执行转向在长交互视野中归纳环境潜在动态,填补了当前基准测试中的关键空白。
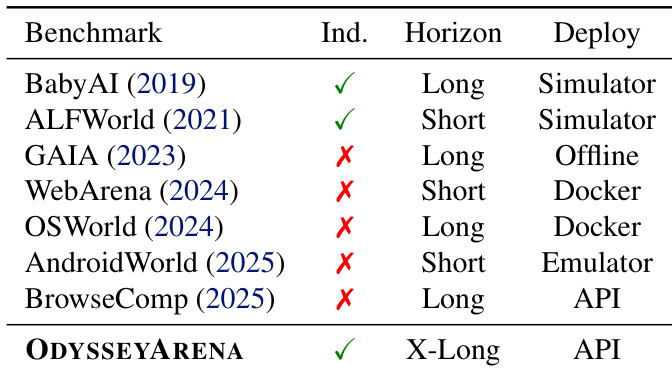
- 我们形式化并实现了四种结构原语——离散规则、随机动态、周期性模式和关系依赖——并将其嵌入具体环境中,提供 ODYSSEYARENA-LITE(120 项任务)和 ODYSSEYARENA-CHALLENGE(>200 步任务)用于标准化和压力测试。
- 对 15+ 种主流大语言模型的实验表明,即使在前沿模型中,归纳推理和长视野稳定性也存在显著缺陷,暴露了自主智能体开发中的关键瓶颈,尽管商业模型表现优于开源模型。
引言
作者利用大语言模型在自主智能体中的日益重要角色,解决评估中的关键空白:大多数基准测试在静态规则和短视野下测试演绎推理,未能衡量智能体如何通过主动、长期交互发现隐藏动态。先前工作常回避探索,将任务长度限制在 50 步以内,并假设目标已预先指定——忽略了现实部署所需的归纳推理。其主要贡献是 ODYSSEYARENA,一个基准套件,形式化了环境动态的四种结构原语(离散规则、随机系统、多目标模式、关系图),并将其实例化于交互环境中。他们引入 ODYSSEYARENA-LITE 用于 120 项任务的标准化评估,以及 ODYSSEYARENA-CHALLENGE 用于 1,000+ 步的压力测试,揭示即使顶级大语言模型在归纳发现方面也表现不佳——突显当前智能体智能的根本瓶颈。
数据集
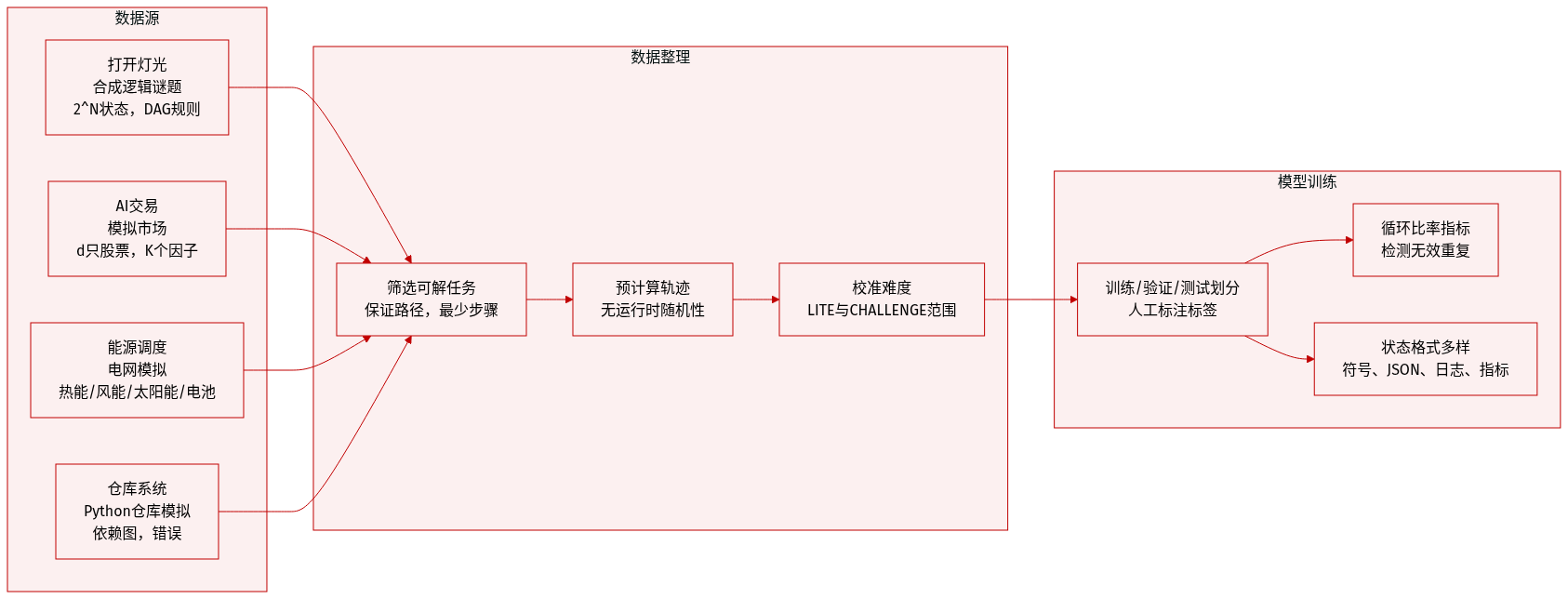
作者使用 ODYSSEYARENA 构建了两个基准套件——ODYSSEYARENA-LITE 用于高效评估,ODYSSEYARENA-CHALLENGE 用于长视野推理压力测试。两者均源自从有界参数分布中采样的确定性任务实例,确保可复现性和可解性。
关键数据集子集及其细节:
-
打开灯光:
- 规模:通过状态空间 N(灯数)可扩展,生成 2^N 种可能状态。
- 来源:基于 DAG 的合成逻辑谜题,使用 {∧, ∨, ¬} 运算符。
- 筛选:仅保留具有保证解路径和最小步数阈值的实例。
- 动作:每步单个整数索引。
- 元数据:固定轨迹、视觉状态符号、含目标和规则的系统提示。
-
AI 交易:
- 规模:通过股票数 d 和市场因子 K 控制。
- 来源:模拟市场,含线性因子模型和噪声(ε)。
- 筛选:所有任务均可解;多样性来自 W 矩阵的稀疏性和信噪比调整。
- 动作:每步先卖后买,格式为 JSON。
- 元数据:每日价格、持仓、现金、新闻提示和预测信号。
-
能源调度:
- 规模:通过每日动态和发电类型(热能、风能、太阳能、电池)调节。
- 来源:国家电网模拟,含固定单位成本和容量限制。
- 筛选:所有任务可解;约束包括预算、需求、碳排放和稳定性。
- 动作:每步规划四种发电类型;电池充放电互斥。
- 元数据:每日状态、先前结果、需求、次日预算和动态阈值。
-
仓库系统:
- 规模:通过依赖图密度和包版本可配置。
- 来源:模拟 Python 仓库,含部分信息、运行时故障和非单调副作用。
- 筛选:解决方案优先生成确保存在真实版本路径。
- 动作:每步单条命令字符串。
- 元数据:执行结果(成功/错误)、含命令反馈的结构化历史。
处理与使用:
- 所有环境使用确定性轨迹:动态因素(如每日波动、效率曲线)预先计算,消除运行时随机性。
- 任务难度通过参数范围校准——LITE 使用可处理设置,CHALLENGE 推向经验极限。
- 训练划分和混合比例未在文中明确定义,但评估使用每例 4 名独立标注者的标注。
- 人工标注:标注者为 AI 学生,报酬为 15 美元/小时;通过 Fleiss’ Kappa(离散任务)和 ICC(AI 交易中的连续利润)衡量评分者间可靠性。
- 循环比率指标跟踪“打开灯光”和“仓库系统”中的无效动作重复,以评估归纳推理失败。
- 状态表示各异:符号视觉(灯光)、结构化金融数据(交易)、每日指标(能源)和执行日志(仓库)。
- 未提及裁剪;所有元数据均构造以保留每个环境独特约束和反馈循环的完整上下文。
方法
作者利用结构化基准框架 ODYSSEYARENA,设计用于评估智能体在四种不同环境原语下进行归纳世界建模的能力。每个环境施加独特的潜在结构约束,要求智能体自主推断转换动态,而非在已知规则下运行。整体架构模块化,每个环境封装自身的状态转换逻辑、观测空间和动作空间,同时与智能体共享通用交互协议。
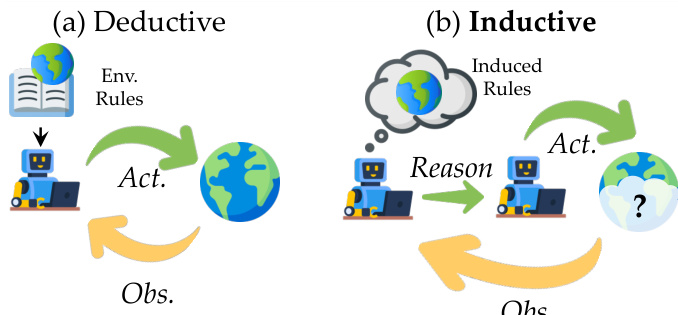
参考框架图,说明演绎与归纳推理范式的区别。在演绎设置中,智能体拥有环境规则的显式知识;而在归纳设置(ODYSSEYARENA 的核心)中,智能体必须通过观测推断潜在规则后行动。此归纳循环构成所有四个环境的基础,智能体迭代观察状态变化、假设转换函数并通过战略干预优化策略。
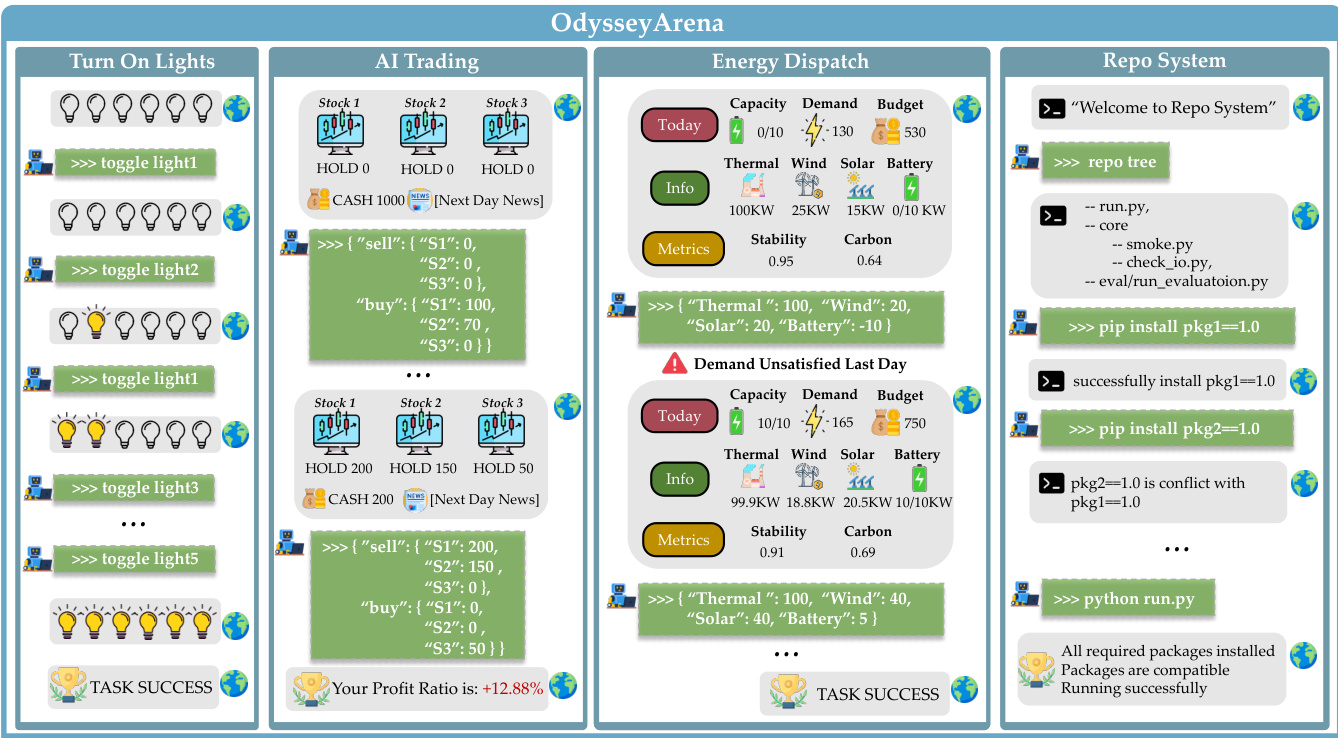
第一个环境“打开灯光”实例化离散符号规则。智能体与由潜在布尔逻辑支配的 N 盏灯网络交互。每盏灯 Li 的激活条件 ϕi 由索引较低的灯定义,确保严格的偏序。转换函数仅在 ϕi(st)=True 时切换灯 i,引入非单调动态。智能体在每次动作后观察完整状态向量 st∈{0,1}N,但必须通过系统切换推断隐藏的逻辑依赖。环境强制随机映射灯 ID 以掩盖任何数字顺序,迫使对因果链进行归纳推理。
第二个环境“AI 交易”建模连续随机动态。资产回报演化为 st+1=Wzt+ϵ,其中 W∈Rd×K 是潜在因子载荷矩阵,将未观测市场因子 zt 映射到资产回报,ϵ 为高斯噪声。智能体观察历史价格和新闻衍生指标作为 zt 的代理,并必须在 d 个资产上执行组合买卖动作。转换逻辑更新投资组合状态并根据累计回报(调整交易成本)计算奖励。成功要求智能体从噪声观测中估计 W 并执行长视野策略。
第三个环境“能源调度”体现周期性时间模式。智能体在热能、风能、太阳能和电池资源间分配电力,以满足每日需求并受预算约束。实际输出 Preal 由时变效率向量 Et 调制,其中风能和太阳能效率遵循不同的隐藏周期函数 Et≈Et+T,周期 T∈[15,25] 随机采样。效率分层生成:基础模式带随机尖峰、每完整周期的循环偏移和微波动,均裁剪至现实范围。智能体观察需求 Dt 和预算 Bt,必须从历史输出差距推断潜在周期结构,规划 120 天视野而不触发提前终止。
第四个环境“仓库系统”编码关系图结构。智能体导航潜在依赖图 G=(V,E),节点表示包版本,边编码兼容性约束。动作是符号化 shell 命令(如 pip install),触发解析过程:系统自动安装依赖、升级/降级冲突包或固定版本以维持局部一致性。这引发非单调副作用,动作顺序影响最终状态。智能体观察终端输出和执行日志,仅揭示断开边(如 ImportError),必须推理隐藏图拓扑以实现全局一致性。
如下图所示,每个环境呈现不同的交互轨迹:“打开灯光”涉及切换灯以达到目标状态;“AI 交易”需根据市场信号重新分配投资组合;“能源调度”需在时间效率周期下分配资源;“仓库系统”需通过符号命令解决依赖。所有环境共享共同评估协议:成功为二元,需全局任务完成,而非部分修复。
基准架构如系统图所示,包含两个主要组件:环境配置和智能体交互。环境通过手动设计的配置初始化,支持难度控制,随后由任务生成器生成带自动验证的配置文件。大语言模型智能体通过基于 API 的接口与环境交互,管理步进循环:智能体接收观测、生成思考与动作,环境更新状态并返回新观测。循环持续至任务评估成功或失败,工作记忆维持跨步骤上下文。
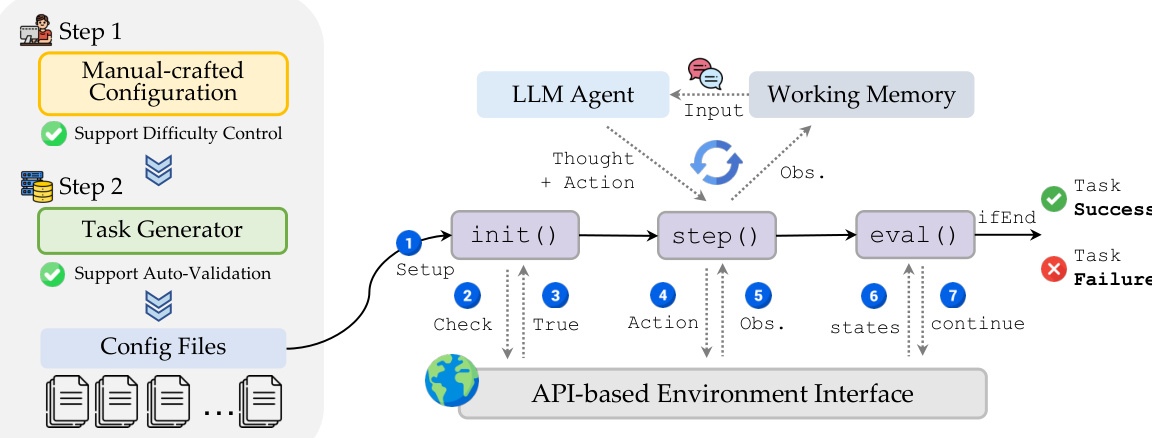
实验
- 在 ODYSSEYARENA-LITE 上评估 15+ 个大语言模型,揭示因大语言模型无法自主归纳环境潜在规则,导致人类与模型表现存在持续差距。
- 专有模型(如 Gemini 3 Pro Preview)表现领先,但在能源调度等复杂任务中仍失败,暴露了建模长期周期模式的共享架构局限。
- 当规则提供时,大语言模型在演绎推理上表现出色,但无规则时表现严重不足,证实归纳世界建模(而非任务逻辑)是核心瓶颈。
- 随交互步数延长,性能趋于平缓,表明更多尝试无法克服内部世界模型的缺失;较弱模型有时表现劣于随机基线。
- 持续“动作循环”和未能将反馈归因于隐藏约束,揭示归纳停滞,尤其在长视野场景中。
- 存在刚性归纳上限:即使顶级模型也失败于 6+ 个高复杂度任务,这些任务无任何大语言模型可解,凸显世界结构发现的扩展极限。
- ODYSSEYARENA-CHALLENGE(1,000+ 步)确认长视野推理仍是未解挑战,暴露信用分配衰减和规划复合错误等失败模式。
- 增加推理预算略微提升归纳性能,但未弥合根本差距;不同模型和环境间标记效率差异显著。
- 人类智能体在所有环境中均优于所有大语言模型,尤其在发现隐藏依赖和随时间调整策略方面。
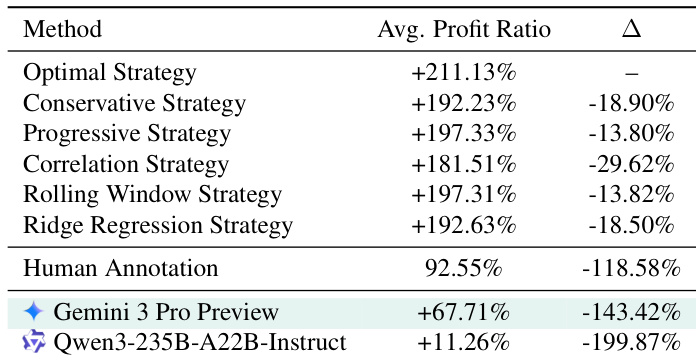
作者评估大语言模型在金融交易任务中的表现,成功取决于在 120 步内推断隐藏市场动态。结果表明,即使 Gemini 3 Pro Preview 和 Qwen3-235B-A22B-Instruct 等顶级模型也表现劣于人工标注者和简单基于规则的策略,利润比率差距超过 100 个百分点。这突显当前大语言模型在从稀疏反馈合成长视野、潜在环境规则时持续存在的归纳推理缺陷。
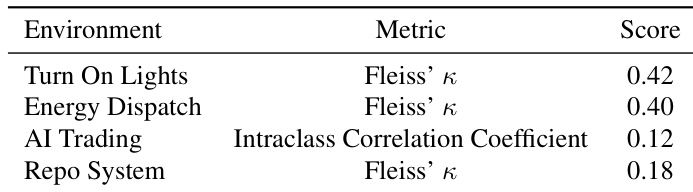
作者使用 Fleiss’ κ 和组内相关系数衡量四个环境中模型间的共识,揭示大语言模型间共识较低至中等。结果显示,在“打开灯光”和“能源调度”中共识最高,但在“AI 交易”和“仓库系统”中急剧下降,表明模型对复杂多约束任务的解释存在更大分歧。这表明任务结构和隐藏规则复杂性显著影响模型行为一致性。
作者在需归纳推理发现隐藏规则的多环境基准上评估多个大语言模型,发现即使顶级专有模型也显著劣于人类,难以自主推断环境动态。结果表明,当规则提供时模型表现优异,但其归纳能力仍有限,尤其在长视野或复杂任务(如能源调度)中,无模型达成成功。性能随交互延长趋于平缓,表明增加步数或规模无法克服从试错反馈中建模世界的根本瓶颈。
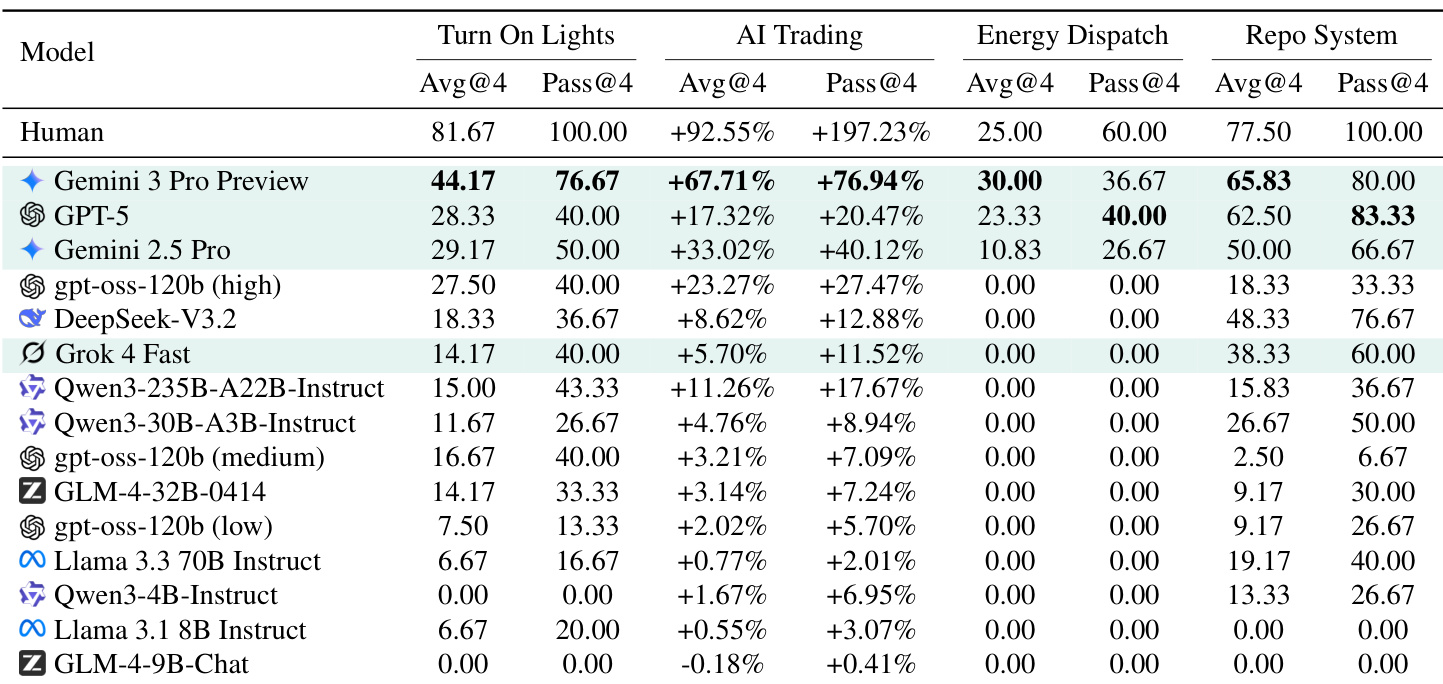
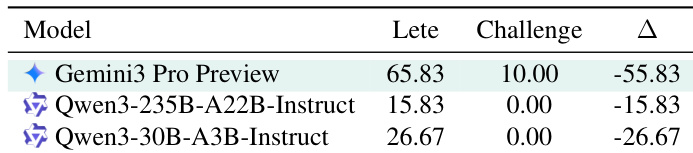
作者在任务复杂度各异的结构化基准上评估多个大语言模型,揭示即使 Gemini 3 Pro Preview 等顶级模型在从标准设置过渡到长视野挑战设置时表现急剧下降。结果表明,当前大语言模型在扩展交互序列中难以进行归纳推理,无论规模或架构,凸显自主世界建模的根本局限。即使在提供明确规则时擅长演绎任务的模型,此差距仍持续存在。
作者引入 ODYSSEYARENA 作为基准,独特结合归纳推理、扩展交互视野和基于 API 的部署,区别于缺乏一个或多个维度的先前基准。结果表明,即使顶级大语言模型在长视野归纳任务中仍表现困难,揭示演绎推理与自主世界建模间的持续差距。这凸显当前智能体的根本局限:无论规模或交互预算如何,它们均无法从经验中合成潜在环境规则。