HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

BeSafe-Bench: 기능적 환경 내 Situated Agents의 행동 안전 리스크 규명

World Reasoning Arena



























BeSafe-Bench: 기능적 환경 내 Situated Agents의 행동 안전 리스크 규명
World Reasoning Arena
MSA: 1억 토큰까지의 효율적 엔드투엔드 메모리 모델 확장을 위한 메모리 희소 어텐션
Voxtral TTS
RealRestorer: 대규모 이미지 편집 모델을 활용한 일반화 가능한 실세계 이미지 복원을 위한 연구
캘리브레이션: 매개변수 효율적 보정을 통한 Diffusion Transformer 향상
Intern-S1-Pro: Trillion Scale 과학적 멀티모달 기초 모델
PixelSmile: Toward Fine-Grained Facial Expression Editing
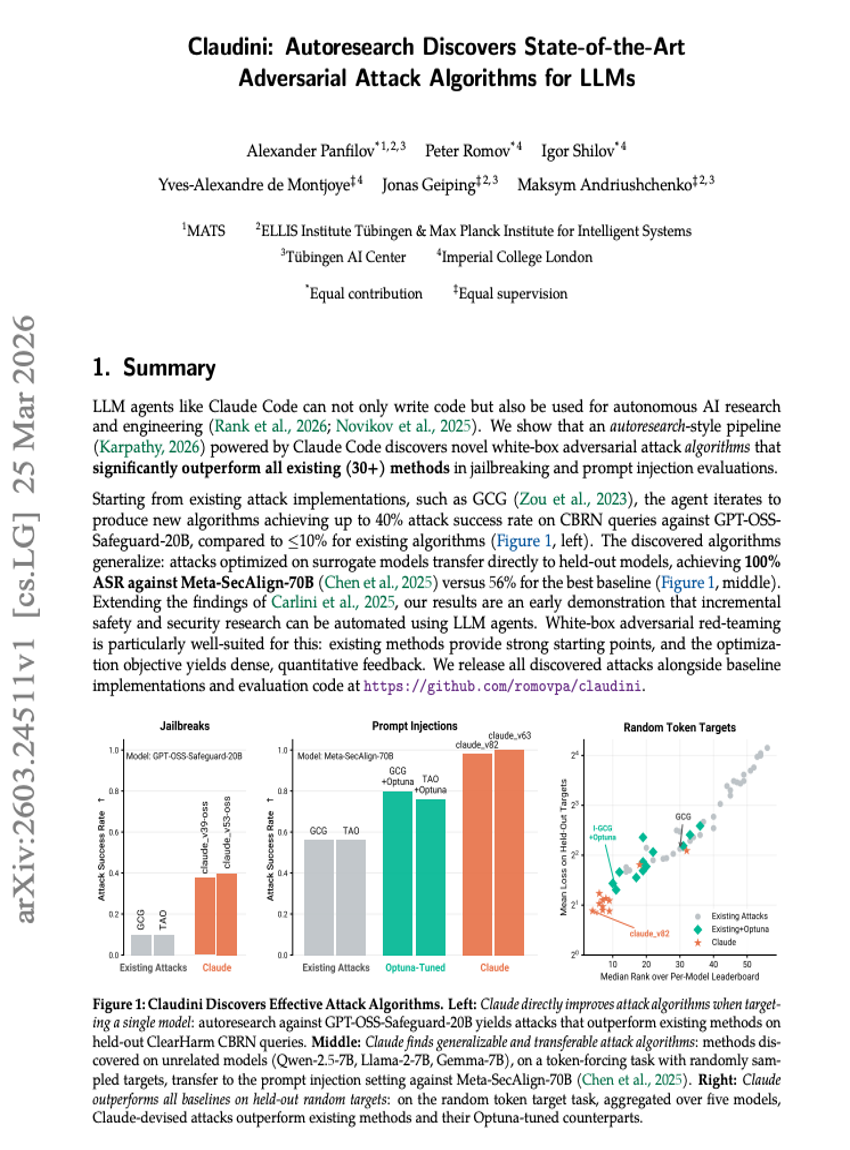
Claudini: Autoresearch를 통한 LLMs용 최첨단 Adversarial Attack 알고리즘 발견
AutoHarness: 코드 하네스(Code Harness)의 자동 합성을 통한 LLM Agents의 성능 향상
GameplayQA: 3D 가상 에이전트의 의사결정이 밀집된 POV 동기화 멀티비디오 이해를 위한 벤치마킹 프레임워크
LLM 의 추론 능력을 (때때로) 저하시키는 이유는 무엇인가?
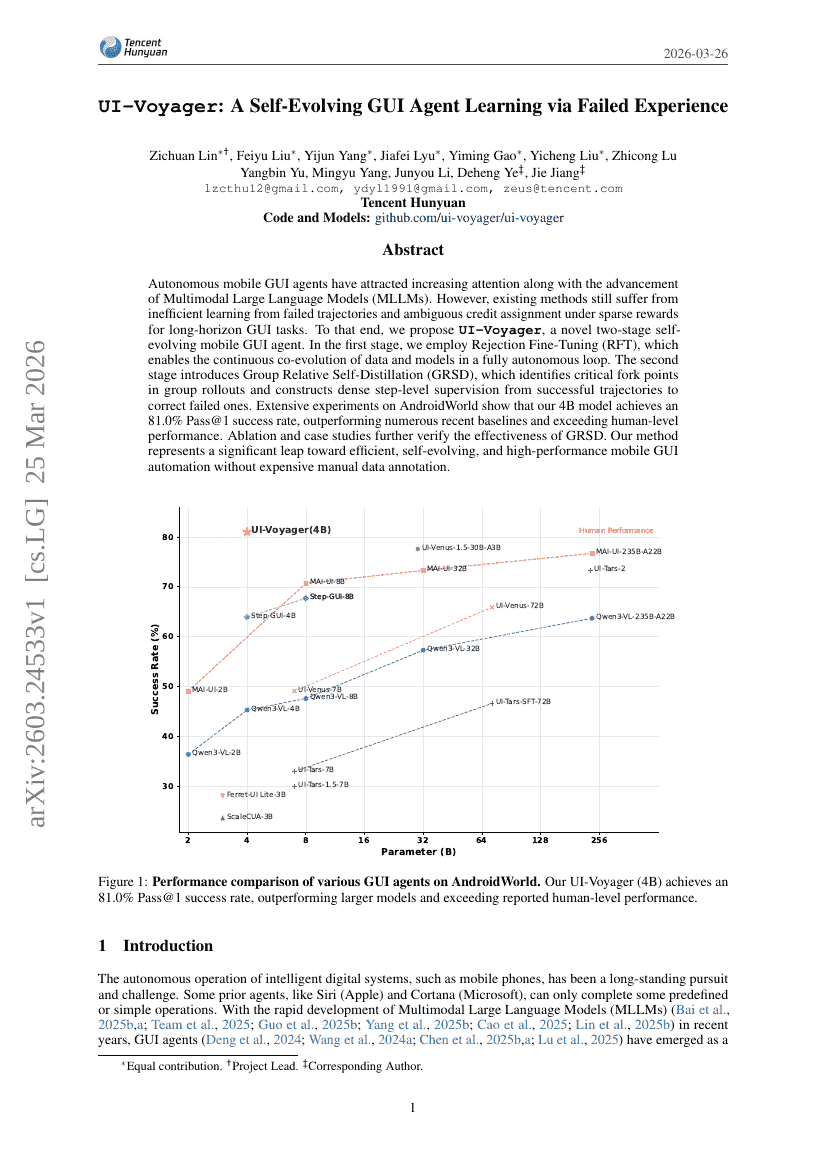
UI-Voyager: 실패 경험을 통한 자기 진화형 GUI Agent 학습
T-MAP: Trajectory-aware Evolutionary Search를 통한 LLM Agents에 대한 Red-Teaming
CUA-Suite: 컴퓨터 사용 에이전트를 위한 대규모 인간 주석 비디오 데모
EVA: End-to-End Video Agent을 위한 효율적 강화학습
Foveated Diffusion: 효율적인 공간 적응형 이미지 및 비디오 생성
Ego2Web: Egocentric Video에 기반한 Web Agent 벤치마크
정적 템플릿에서 동적 런타임 그래프로: LLM 에이전트 워크플로우 최적화에 대한 개요
SpecEyes: Speculative Perception 및 Planning을 통한 Agentic Multimodal LLMs 가속화
DA-Flow: Diffusion Models를 활용한 Degradation-Aware Optical Flow Estimation
PEARL: Personalized Streaming Video Understanding Model
WildWorld: 행동과 명시적 상태를 통한 생성형 ARPG 를 위한 동적 세계 모델링을 위한 대규모 데이터셋
MinerU-Diffusion: Diffusion Decoding를 통한 역 렌더링으로서의 문서 OCR 재고찰
PivotRL: 낮은 연산 비용으로 구현하는 고정밀 Agentic Post-Training
F4Splat: Feed-Forward 3D Gaussian Splatting을 위한 Feed-Forward 예측적 밀도 증가
SpatialBoost: 언어 기반 추론을 통한 시각적 표현 향상
VideoDetective: 장편 영상 이해를 위한 외재적 쿼리와 내재적 관련성을 통한 단서 탐지
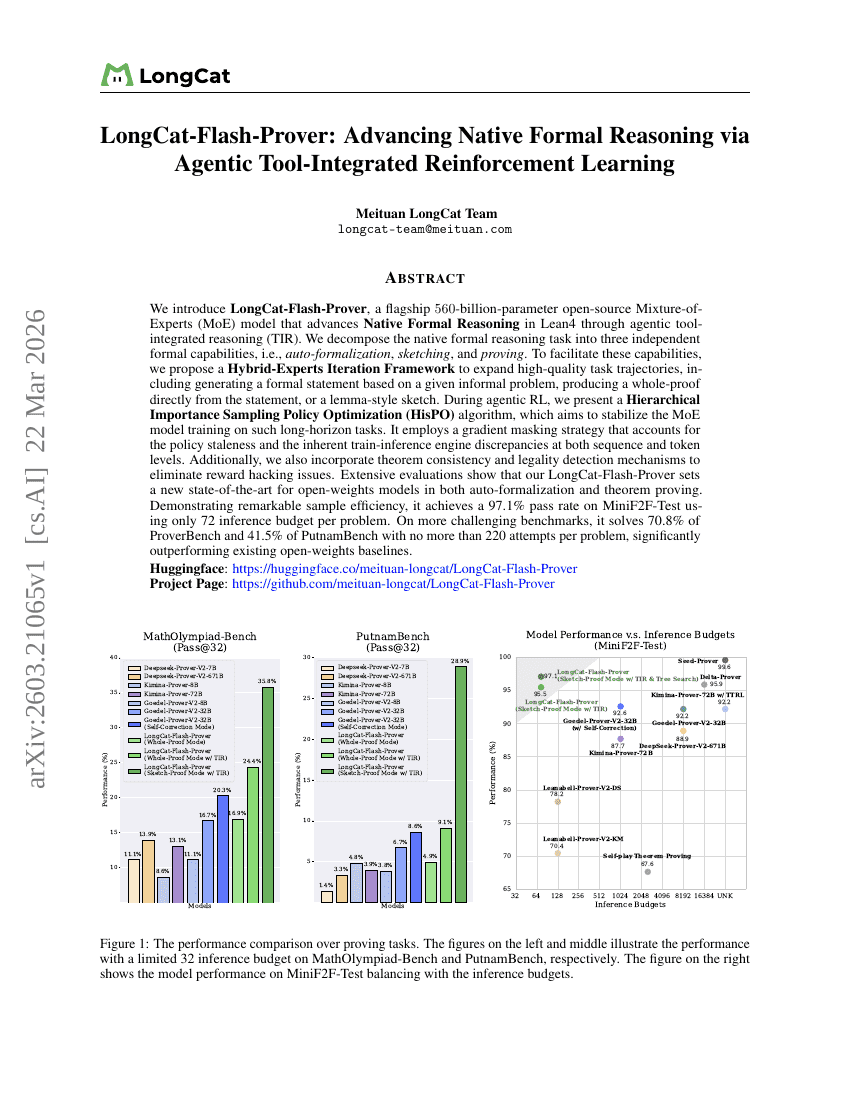
LongCat-Flash-Prover: Agentic Tool-Integrated Reinforcement Learning를 통한 Native Formal Reasoning의 발전
단순성에 의한 속도: 빠른 오디오-비디오 생성 기반 모델을 위한 단일 스트림 아키텍처
Omni-WorldBench: 세계 모델에 대한 포괄적인 상호작용 중심 평가 지향
PrismAudio: 비디오-오디오 생성을 위한 분해된 연쇄 사고와 다차원 보상
MSA: 1억 토큰까지의 효율적 엔드투엔드 메모리 모델 확장을 위한 메모리 희소 어텐션
Voxtral TTS
RealRestorer: 대규모 이미지 편집 모델을 활용한 일반화 가능한 실세계 이미지 복원을 위한 연구
캘리브레이션: 매개변수 효율적 보정을 통한 Diffusion Transformer 향상
Intern-S1-Pro: Trillion Scale 과학적 멀티모달 기초 모델
PixelSmile: Toward Fine-Grained Facial Expression Editing
Claudini: Autoresearch를 통한 LLMs용 최첨단 Adversarial Attack 알고리즘 발견
AutoHarness: 코드 하네스(Code Harness)의 자동 합성을 통한 LLM Agents의 성능 향상
GameplayQA: 3D 가상 에이전트의 의사결정이 밀집된 POV 동기화 멀티비디오 이해를 위한 벤치마킹 프레임워크
LLM 의 추론 능력을 (때때로) 저하시키는 이유는 무엇인가?
UI-Voyager: 실패 경험을 통한 자기 진화형 GUI Agent 학습
T-MAP: Trajectory-aware Evolutionary Search를 통한 LLM Agents에 대한 Red-Teaming
CUA-Suite: 컴퓨터 사용 에이전트를 위한 대규모 인간 주석 비디오 데모
EVA: End-to-End Video Agent을 위한 효율적 강화학습
Foveated Diffusion: 효율적인 공간 적응형 이미지 및 비디오 생성
Ego2Web: Egocentric Video에 기반한 Web Agent 벤치마크
정적 템플릿에서 동적 런타임 그래프로: LLM 에이전트 워크플로우 최적화에 대한 개요
SpecEyes: Speculative Perception 및 Planning을 통한 Agentic Multimodal LLMs 가속화
DA-Flow: Diffusion Models를 활용한 Degradation-Aware Optical Flow Estimation
PEARL: Personalized Streaming Video Understanding Model
WildWorld: 행동과 명시적 상태를 통한 생성형 ARPG 를 위한 동적 세계 모델링을 위한 대규모 데이터셋
MinerU-Diffusion: Diffusion Decoding를 통한 역 렌더링으로서의 문서 OCR 재고찰
PivotRL: 낮은 연산 비용으로 구현하는 고정밀 Agentic Post-Training
F4Splat: Feed-Forward 3D Gaussian Splatting을 위한 Feed-Forward 예측적 밀도 증가
SpatialBoost: 언어 기반 추론을 통한 시각적 표현 향상
VideoDetective: 장편 영상 이해를 위한 외재적 쿼리와 내재적 관련성을 통한 단서 탐지
LongCat-Flash-Prover: Agentic Tool-Integrated Reinforcement Learning를 통한 Native Formal Reasoning의 발전
단순성에 의한 속도: 빠른 오디오-비디오 생성 기반 모델을 위한 단일 스트림 아키텍처
Omni-WorldBench: 세계 모델에 대한 포괄적인 상호작용 중심 평가 지향
PrismAudio: 비디오-오디오 생성을 위한 분해된 연쇄 사고와 다차원 보상