Command Palette
Search for a command to run...
SpatialBoost: 언어 기반 추론을 통한 시각적 표현 향상
SpatialBoost: 언어 기반 추론을 통한 시각적 표현 향상
Byungwoo Jeon Dongyoung Kim Huiwon Jang Insoo Kim Jinwoo Shin
초록
다양한 비전 작업에서 대규모 사전 학습 이미지 표현 모델(즉, 비전 인코더)의 탁월한 성공에도 불구하고, 이러한 모델들은 주로 2D 이미지 데이터로 학습되어 실제 세계의 객체와 배경 간의 3D 공간적 관계를 포착하지 못하는 경우가 많으며, 이는 많은 하류 애플리케이션에서의 효과성을 제한합니다. 이를 해결하기 위해 우리는 언어적 설명으로 표현된 3D 공간 지식을 주입함으로써 기존 사전 학습 비전 인코더의 공간 인식 능력을 향상시키는 확장 가능한 프레임워크인 SpatialBoost 를 제안합니다. 핵심 아이디어는 2D 이미지에서 추출된 밀집된 3D 공간 정보를 언어적 표현으로 변환한 후, 이를 Large Language Model(LLM) 을 통해 비전 인코더에 주입하는 것입니다. 이를 위해 우리는 점진적으로 밀집된 공간 지식을 통합하고 계층적 공간 이해를 구축하는 다중 턴 Chain-of-Thought(CoT) 추론 프로세스를 채택합니다. 효과성을 검증하기 위해 SpatialBoost 를 DINOv3 와 같은 최첨단 비전 인코더에 적용하고, 3D 지각과 일반 비전 능력을 모두 요구하는 다양한 벤치마크에서 성능 향상을 평가했습니다. 예를 들어, SpatialBoost 는 ADE20K 에서 DINOv3 의 성능을 55.9 mIoU 에서 59.7 mIoU 로 향상시켜, 사전 학습된 DINOv3 대비 3.8% 의 개선을 통해 최첨단 성능을 달성했습니다.
One-sentence Summary
Researchers from KAIST, RLWRLD, and NAVER Cloud propose SpatialBoost, a framework that injects 3D spatial knowledge into pre-trained vision encoders like DINOv3 using LLM-guided multi-turn Chain-of-Thought reasoning. This approach converts dense geometric data into linguistic descriptions, significantly improving performance on 3D perception and robotic control tasks while preserving general visual capabilities.
Key Contributions
- The paper introduces SpatialBoost, a scalable framework that enhances the spatial awareness of pre-trained vision encoders by converting dense 3D spatial information from 2D images into linguistic descriptions and injecting this knowledge via a Large Language Model.
- A multi-turn Chain-of-Thought reasoning process is presented to build hierarchical spatial understanding through pixel-level, object-level, and scene-level sub-questions, while a dual-channel attention module allows for training only new parameters to preserve existing knowledge.
- Experiments demonstrate that applying this method to state-of-the-art encoders like DINOv3 and SigLIPv2 yields state-of-the-art performance across diverse benchmarks, including a 3.8% gain in mIoU on ADE20K and improved accuracy in monocular depth estimation and image classification.
Introduction
Pre-trained vision encoders excel at semantic understanding but struggle to capture 3D spatial relationships because they are trained primarily on 2D images, limiting their effectiveness in tasks like robotic control and depth estimation. Prior attempts to fix this often require multi-view datasets or training from scratch, which creates significant data curation bottlenecks and computational costs that hinder scalability. The authors introduce SpatialBoost, a framework that enhances existing vision encoders by converting dense 3D spatial cues into linguistic descriptions and injecting this knowledge via a Large Language Model using multi-turn Chain-of-Thought reasoning. By freezing the original encoder and training only new dual-channel attention modules, the method efficiently builds hierarchical spatial understanding without forgetting prior knowledge, achieving state-of-the-art results across diverse benchmarks including semantic segmentation and monocular depth prediction.
Dataset
-
Dataset Composition and Sources The authors construct two primary datasets to enhance spatial reasoning: a Multi-view VQA Dataset and a Multi-turn Visual Spatial Reasoning Dataset. The Multi-view VQA dataset draws from 3D datasets including ScanNet, Mip-NeRF360, and MVIImgNet, alongside the Ego4D ego-centric video dataset. The Multi-turn Visual Spatial Reasoning dataset utilizes 100K images filtered from the SA1B dataset for single-view tasks and 200K samples from the aforementioned 3D and video sources for multi-view tasks.
-
Key Details for Each Subset
- Multi-view VQA Subset: This subset contains 200K samples filtered using the LPIPS metric to ensure image pairs have a similarity score between 0.35 and 0.65, removing outliers that are too similar or too dissimilar. GPT-4o generates three question types: common VQA, adversarial VQA, and multi-choice VQA to probe general multi-view knowledge.
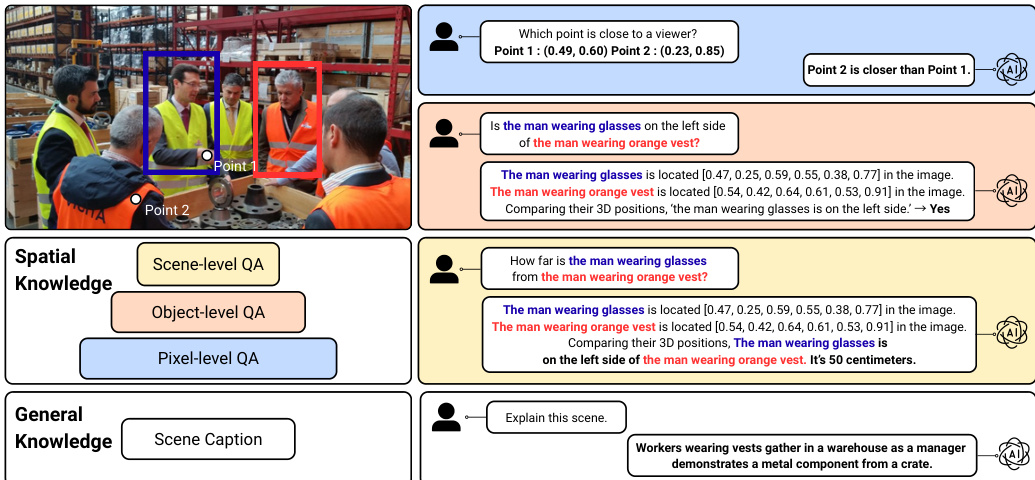
- Multi-turn Visual Spatial Reasoning Subset: This subset features 12 sequential QA turns per image. The first 5 turns address pixel-level depth, the next 4 cover object-level spatial relationships using 3D bounding cubes, the 10th turn handles scene-level distance prediction, and the final 2 turns provide GPT-generated scene captions. Single-view data is filtered via a CLIP-based open-vocabulary model to ensure the presence of multiple objects.
-
Data Usage in Model Training The authors employ these datasets during specific stages of visual instruction tuning. The Multi-view VQA dataset is used in Stage 2 to align the vision encoder with the LLM for handling multi-view data. The Multi-turn Visual Spatial Reasoning dataset is utilized in Stage 3 to inject dense spatial information and enable Chain-of-Thought (CoT) reasoning. The training pipeline processes single-view and multi-view inputs to synthesize QA pairs that range from narrow pixel queries to broad scene understanding.
-
Processing and Construction Strategies
- 3D Information Extraction: For single-view images, the authors use Depth-pro for metric depth estimation and segmentation models to generate 3D point clouds. For multi-view inputs, they apply the VGGT 3D reconstruction model to create point clouds.
- Hierarchical Reasoning: The data generation pipeline synthesizes questions at three levels: pixel (absolute/relative depth), object (relative position using bounding cubes), and scene (distance between objects). Depth values are rounded to the third decimal place, using a centimeter scale for distances under 0.5 meters.
- Viewpoint Expansion: To extend beyond 2-view configurations, the authors sample interpolated frames between anchor views. They verify with GPT-4o that existing VQA pairs remain valid for these new viewpoints, resulting in a final mix of 160K 2-view, 30K 4-view, and 10K 8-view samples.
Method
The authors propose SpatialBoost, a visual representation learning framework designed to enhance vision encoders by injecting 3D spatial information expressed in natural language. The overall methodology involves a multi-modal architecture that incorporates linguistically expressed visual information into the vision encoder through a dual-channel attention layer. This ensures that original visual features are preserved while 3D spatial information is fully exploited.
Refer to the framework diagram for an overview of the spatial knowledge extraction, conversion, and fine-tuning process. The pipeline begins with spatial knowledge extraction from single-view and multi-view images, utilizing depth estimation, segmentation, 3D reconstruction, and region captioning. This extracted knowledge is then converted into natural language descriptions through pixel-level, object-level, and scene-level reasoning. Finally, the vision encoder is fine-tuned using a Large Language Model (LLM) and a projector module.
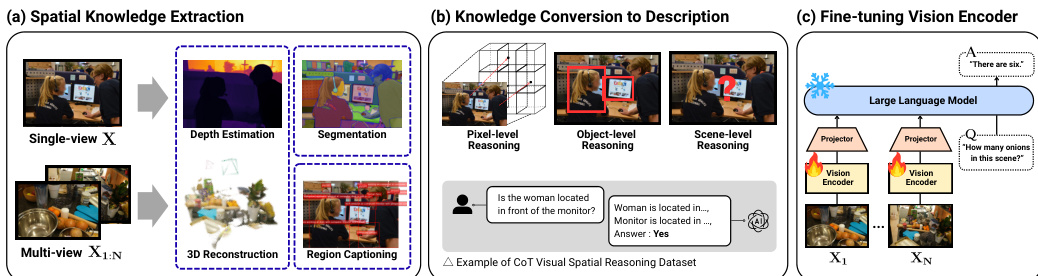
To support this training, the authors design a Visual-Question-Answering (VQA) dataset that hierarchically disentangles 3D spatial relations. As shown in the figure below, the dataset exhibits multi-turn visual spatial reasoning at different granularities. At the pixel-level, the QA task queries 3D positions of points via depth estimation. At the object-level, it extracts spatial properties such as bounding cubes or relative positions. At the scene-level, it determines exact distances between multiple objects requiring rationales from previous steps. Additionally, general scene captioning is included to provide broader context.
The training pipeline consists of three stages, all optimized using supervised fine-tuning (SFT) loss. In Stage 1 (Feature alignment), a projector gP is trained to map image features into the textual embedding space of the LLM while freezing the visual encoder fV and the language model fL. In Stage 2 (Visual instruction tuning), the visual encoder remains frozen while the projector and the LLM are fine-tuned using the multi-view VQA data combined with single-view visual instruction data. This enables the model to handle multi-view visual questions effectively.
In Stage 3, the vision encoder is fine-tuned to acquire spatial understanding. To prevent catastrophic forgetting of pre-trained knowledge during this process, the authors introduce a dual-channel attention mechanism. Refer to the illustration of the dual-channel attention layer for the specific module design. For each attention layer in the visual encoder, an additional attention layer is introduced alongside the original block. The outputs are merged via a learnable mixture factor α.
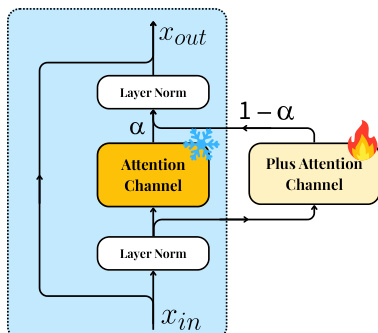
Formally, given an input x to each attention layer, the final output is computed as:
Attnfinal(x)=α⋅Attn(x)+(1−α)⋅Attn+(x)Here, α=sigmoid(a) is a trainable mixture factor initialized with zero, ensuring the model initially relies on pre-trained attention weights. During fine-tuning, only the parameters of the additional attention layer Attn+ and the mixture factor α are updated. This approach allows the vision encoder to smoothly enhance spatial awareness without discarding existing knowledge.
Experiment
- SpatialBoost significantly enhances vision encoders' spatial understanding across dense prediction tasks, including monocular depth estimation and semantic segmentation, by effectively transferring language-based spatial knowledge.
- The method improves performance on complex 3D-centric tasks such as vision-language reasoning and 3D semantic segmentation without compromising general language capabilities or causing catastrophic forgetting.
- Vision-based robot learning experiments demonstrate that the enhanced spatial representations directly lead to superior control performance in locomotion and manipulation domains.
- Evaluations on image classification and retrieval confirm that the approach improves general vision capabilities without overfitting to spatial features, preserving pre-trained knowledge.
- Ablation studies validate that LLM-based fine-tuning provides superior supervision compared to pixel-level alternatives, while a hierarchical forward reasoning order and the combination of single-view and multi-view data yield optimal results.
- The dual-channel attention mechanism is identified as critical for preserving and enhancing pre-trained knowledge during fine-tuning, outperforming standard full fine-tuning and LoRA approaches.
- Experiments confirm the method's robust scalability with increased data size and its complementary nature when applied to encoders that already possess strong spatial awareness.