Command Palette
Search for a command to run...
MSA: 1억 토큰까지의 효율적 엔드투엔드 메모리 모델 확장을 위한 메모리 희소 어텐션
MSA: 1억 토큰까지의 효율적 엔드투엔드 메모리 모델 확장을 위한 메모리 희소 어텐션
초록
장기 기억은 인간 지능의 초석입니다. 인공지능이 수명 주기 규모의 정보를 처리할 수 있도록 하는 것은 해당 분야에서 오랫동안 추구해 온 목표입니다. 전체 어텐션(full-attention) 아키텍처의 제약으로 인해 대형 언어 모델(LLM)의 유효 컨텍스트 길이는 일반적으로 1M 토큰으로 제한됩니다. 하이브리드 선형 어텐션, 고정 크기 메모리 상태(예: RNN), RAG 또는 에이전트 시스템과 같은 외부 저장 방법과 같은 기존 접근법들은 이러한 한계를 확장하려 시도했으나, 컨텍스트 길이가 증가함에 따라 정밀도가 심각하게 저하되고 지연 시간이 급격히 증가하거나, 메모리 내용을 동적으로 수정할 수 없거나, 엔드투엔드 최적화가 부재하는 등의 문제를 겪고 있습니다. 이러한 병목 현상은 대규모 코퍼스 요약, 디지털 트윈, 장기 이력 에이전트 추론과 같은 복잡한 시나리오를 저해하며, 메모리 용량을 제한하고 추론 속도를 늦춥니다.저희는 엔드투엔드 학습이 가능하고 효율적이며 대규모 확장성이 뛰어난 메모리 모델 프레임워크인 메모리 스퍼스 어텐션(Memory Sparse Attention, MSA)을 제안합니다. 확장 가능한 스퍼스 어텐션과 문서 단위 RoPE와 같은 핵심 혁신을 통해 MSA는 훈련과 추론 모두에서 선형 복잡성을 달성하면서도 탁월한 안정성을 유지합니다. 구체적으로, 컨텍스트 길이가 16K 토큰에서 100M 토큰으로 확장될 때 성능 저하가 9% 미만으로 제한됩니다. 또한, KV 캐시 압축과 메모리 병렬 처리(Memory Parallel)를 결합함으로써 2xA800 GPU 환경에서 100M 토큰 추론을 실현했습니다. 더 나아가, 산재된 메모리 세그먼트 간의 복잡한 멀티홉 추론을 용이하게 하기 위해 메모리 인터리빙(Memory Interleaving)을 제안합니다.MSA는 장기 컨텍스트 벤치마크에서 최첨단 LLM, 최첨단 RAG 시스템, 그리고 주요 메모리 에이전트를 크게 앞섭니다. 이러한 결과는 메모리 용량과 추론 능력을 분리함으로써 MSA가 범용 모델에 고유한 수명 주기 규모의 메모리를 부여할 수 있는 확장 가능한 기반을 제공함을 보여줍니다.
One-sentence Summary
Shanda Group and Peking University researchers propose Memory Sparse Attention (MSA), an end-to-end framework using scalable sparse attention and document-wise RoPE to achieve linear complexity. This approach enables stable 100M token inference on limited GPUs, outperforming RAG systems in long-corpus summarization and multi-hop reasoning tasks.
Key Contributions
- The paper introduces Memory Sparse Attention (MSA), an end-to-end trainable framework that combines a scalable sparse attention architecture with document-wise RoPE to achieve linear complexity in training and inference while maintaining precision stability with less than 9% degradation when scaling from 16K to 100M tokens.
- A Memory Inter-leaving mechanism is proposed to facilitate complex multi-hop reasoning across scattered memory segments, addressing the challenge of retrieving and utilizing information from non-contiguous parts of a massive context.
- Experiments demonstrate that MSA significantly outperforms frontier language models, state-of-the-art RAG systems, and leading memory agents on long-context benchmarks, while KV cache compression and Memory Parallel enable 100M token inference on 2x A800 GPUs.
Introduction
Long-term memory is essential for AI applications like Digital Twins and complex agent reasoning, yet current Large Language Models are typically capped at 1M tokens due to the computational constraints of full-attention architectures. Prior approaches such as RAG systems suffer from precision loss and lack end-to-end trainability, while latent state methods like linear attention or KV cache compression either degrade rapidly at scale or incur prohibitive costs. To overcome these barriers, the authors introduce Memory Sparse Attention (MSA), an end-to-end trainable framework that combines sparse attention with document-wise RoPE to achieve linear complexity and maintain high precision across 100M tokens. This approach enables efficient inference on standard hardware while supporting advanced mechanisms like Memory Inter-leaving for robust multi-hop reasoning across massive context windows.
Dataset
- The authors constructed a diverse pre-training corpus containing 158.95 billion tokens across 17.9 million queries to balance robust retrieval capabilities with broad general knowledge.
- The dataset spans multiple domains ranging from scientific literature to general community Q&A.
- To ensure a balanced distribution, any dataset outside the KALM suite exceeding 0.5 million queries is downsampled to a maximum of 0.5 million queries.
- The KALM instruction data is retained in its entirety without downsampling.
- The full corpus serves as the foundation for pre-training the model to achieve both specialized retrieval performance and general language understanding.
Method
The authors introduce MSA (Memory Sparse Attention), a unified, end-to-end trainable latent memory framework designed for massive memory Question-Answering. The core principle of MSA is to seamlessly integrate the processes of memory sparse retrieval and answer generation into a single, jointly-optimized architecture, moving beyond the limitations of conventional decoupled "retrieve-then-read" pipelines while preserving the ability to handle long-context memory.
Sparse Attention Mechanism
To efficiently process massive memory at the latent state level, MSA replaces the standard dense self-attention with a document-based retrieval sparse attention mechanism. Refer to the framework diagram below for the internal structure of the MSA layer.
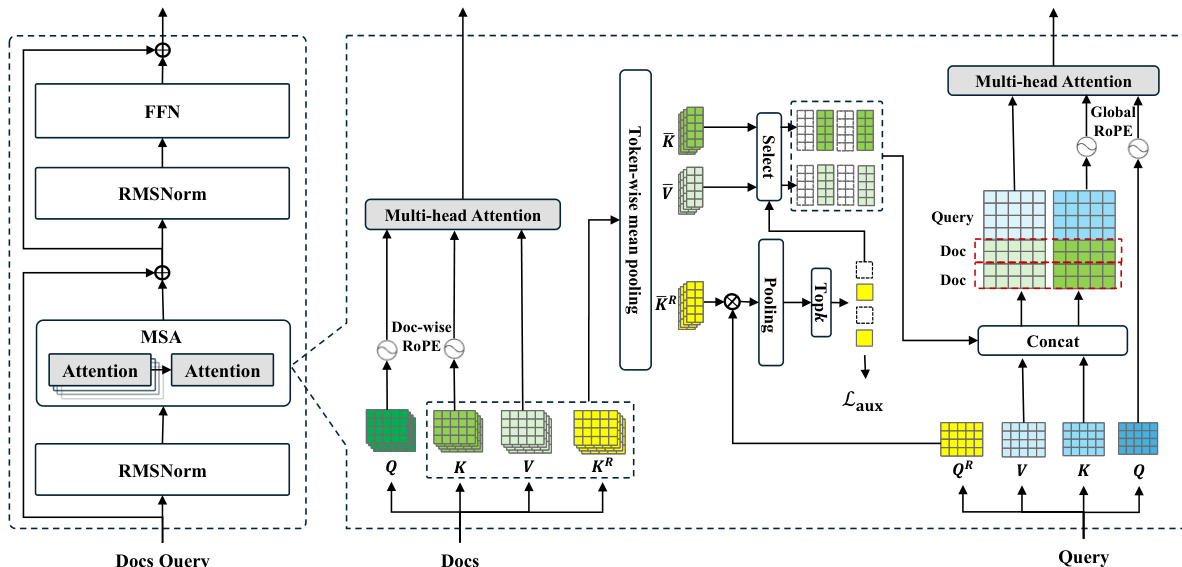
Formally, let the memory bank consist of a set of documents D={d1,d2,…,dN}. For each document di, the model generates standard Key Ki,h and Value Vi,h matrices via the backbone model's projection weights. In parallel, a Router K Projector generates a specialized routing key matrix Ki,hR:
Ki,h=HiWKh,Vi,h=HiWVh,Ki,hR=HiWKRh.To significantly reduce the memory footprint and retrieval complexity, the authors segment each document into multiple fixed-length chunks and perform chunk-wise mean pooling, denoted as ϕ(⋅), to compress these states into latent representations. This yields the compressed matrices Kˉi,h, Vˉi,h, and Kˉi,hR.
During inference, given a user query with hidden state Hq, the model computes standard states Qq,h,Kq,h,Vq,h and a specific routing query Qq,hR via a Router Q Projector. The relevance score Sij for the j-th chunk of the i-th document is computed as the cosine similarity between the query's routing vector and the memory's compressed routing keys, aggregated across attention heads. To identify the most relevant memory segments, a maximum pooling is applied over the query-token-level relevance scores:
Sij=tokent,headhmax(mean(cos((Qq,hR)t,Kˉij,hR))).Based on these scores, the system selects the indices of the Top-k documents. Finally, the generation is performed by concatenating the compressed Key and Value matrices of the selected documents before the query's local cache. The model then performs autoregressive generation where the query Qq from active tokens attends to this aggregated, sparsity-aware context:
Kctx=[{Kˉi}i∈I;Kq],Vctx=[{Vˉi}i∈I;Vq],Output=Attention(Qa,Kctx,Vctx).The authors implement the MSA routing strategy selectively, applying it exclusively to the latter half of the model's layers. Empirical analysis reveals that hidden states in the initial layers fail to capture the high-level semantic abstractions necessary for effective retrieval, rendering the routing mechanism inefficient at these depths.
Positional Encoding
To ensure robust generalization across varying memory scales, MSA employs independent RoPE for each document. Standard global positional encodings would assign monotonically increasing position IDs across the concatenated sequence, causing position indices to shift drastically as the number of documents grows. By assigning independent position IDs (starting from 0) to each document, MSA decouples the positional semantics from the total number of documents in memory. Consequently, the model can effectively extrapolate, maintaining high retrieval and reasoning accuracy on massive memory contexts even after being trained only on smaller subsets.
Complementing this parallel strategy, the authors employ Global RoPE for the active context, which includes the user query and the subsequent autoregressive generation. The position IDs for these tokens are offset by the number of retrieved documents. Specifically, the position indices for the query initiate from k (corresponding to the Top-k retrieved compressed KVs). This strategic offset ensures that the model perceives the active context as a logical continuation of the retrieved background information.
Training Process
To endow the model with robust retrieval capabilities, the authors perform continuous pre-training on a deduplicated corpus. The overarching objective of this stage is to train the model to perform Generative Retrieval, where the model autoregressively generates the unique document IDs of relevant documents.
To explicitly guide the internal sparse attention mechanism beyond the supervision provided by the standard generation loss LLLM, an auxiliary loss, Laux, is introduced to supervise the Layer-wise Routing process. Within each MSA layer, the Router Projector is responsible for selecting the Top-k most relevant documents. The auxiliary loss is defined as a supervised contrastive objective:
Laux=−∣P∣1i=1∑∣P∣logexp(si+/τ)+∑i=1∣N∣exp(si,i−/τ)exp(si+/τ),where τ is the temperature parameter. This objective explicitly enforces separation between relevant and irrelevant document chunks in the latent routing space.
To ensure stability, a two-phase optimization schedule is adopted. In the initial warm-up phase, the focus is on aligning the internal Router Projectors with a loss of L=0.1LLLM+Laux. Upon completion of the warm-up, the system transitions to the main pre-training phase, where the loss weights are adjusted to L=LLLM+0.1Laux. Following continuous pre-training, a two-stage curriculum learning strategy is implemented for SFT on Question Answering tasks, extending the memory context length from 8k to 64k tokens to enhance data quality and length extrapolation.
Inference Pipeline
The inference pipeline is designed to handle the large-scale memory bank efficiently through three distinct stages, as shown in the figure below.
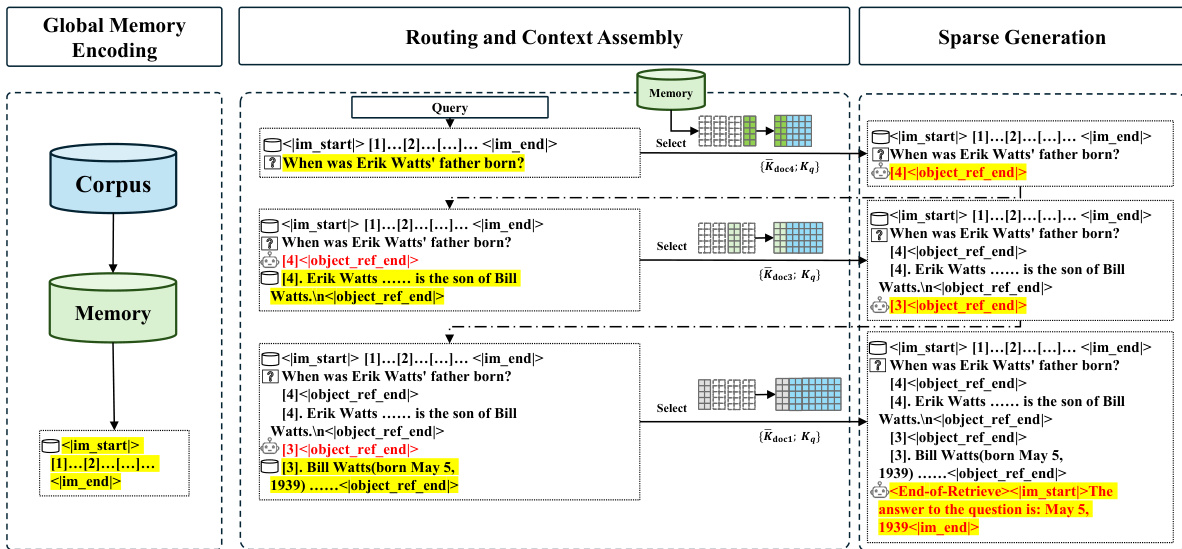
Stage 1: Global Memory Encoding (Offline). This stage is a one-time, offline pre-computation over the entire document corpus. For every document, the model performs a forward pass to generate the standard K and V matrices and the specialized Router K Projector generates the routing key matrix KR. All three matrices are partitioned into chunks and compressed via mean pooling. The resulting compact representations are cached in the memory bank.
Stage 2: Routing and Context Assembly (Online). This stage is initiated upon receiving a user question. The model computes the question's hidden states and projects them via the Router Q Projector to obtain the routing query QqR. This query is matched against the cached global routing keys KˉR to calculate relevance scores and identify the Top-k documents. Crucially, only the compact Key and Value matrices of these selected documents are loaded and concatenated with the question's local Kq and Vq to form the final sparse context.
Stage 3: Sparse Generation (Online). In the final stage, the model operates autoregressively on the assembled sparse context. The standard attention mechanism computes the interaction between the active token's Query Qq and the concatenated KV pairs, generating the final answer token by token.
To address complex queries requiring multi-hop reasoning, MSA incorporates an adaptive Memory Interleave Mechanism. This essentially performs the routing and context assembly and Sparse Generation in an iterative manner. The inference process alternates between Generative Retrieval and Context Expansion, where retrieved documents are treated as part of the query for the next iteration. This cycle repeats adaptively until the model determines that the accumulated documents are sufficient, at which point it transitions to generating the final answer.
Efficiency and Scaling
MSA achieves linear complexity with respect to memory size L in both training and inference regimes. To enable extreme-length memory inference on a standard single node, the authors implement a specialized inference engine called Memory Parallel. This engine supports inference over a massive memory context of up to 100 million tokens with limited GPU resources.
A Tiered Memory Storage Strategy is employed to address capacity constraints. Routing Keys (KˉR) are distributed across the VRAM of multiple GPUs to ensure low-latency retrieval, while the bulk of the memory bank, the Content KVs (Kˉ, Vˉ), is stored in the host DRAM (CPU memory). Upon identifying the Top-k relevant chunks via GPU scoring, only the corresponding Content KVs are asynchronously fetched from the host to the GPU. Additionally, a Memory-Parallel Retrieval strategy is used where the query hidden states are broadcast to all GPUs, and each GPU independently calculates similarity scores against its local shard of Routing Keys before a global reduction identifies the Top-k indices.
Experiment
- MSA was evaluated on nine diverse QA benchmarks and the RULER Needle In A Haystack task to validate its efficacy against same-backbone RAG systems, best-of-breed RAG configurations, and long-context memory architectures.
- The model demonstrates consistent superiority over standard RAG baselines and achieves competitive or top performance against systems using significantly larger generators, proving that its architectural design effectively isolates and enhances retrieval and reasoning capabilities.
- Experiments on context scaling from 32K to 1M tokens confirm that MSA maintains exceptional stability and high retrieval accuracy, avoiding the catastrophic degradation observed in unmodified backbones and other long-context models.
- Ablation studies validate that the two-stage curriculum learning strategy, memory interleave mechanism for multi-hop reasoning, continual pre-training for router precision, and integration of original document text are all critical components for the system's overall performance.
- Analysis of context degradation up to 100M tokens reveals that MSA sustains high generation quality with minimal performance loss, successfully decoupling reasoning capabilities from massive memory capacity.