Command Palette
Search for a command to run...
Intern-S1-Pro: Trillion Scale 과학적 멀티모달 기초 모델
Intern-S1-Pro: Trillion Scale 과학적 멀티모달 기초 모델
초록
저희는 1 조 파라미터 규모의 과학 분야 멀티모달 파운데이션 모델인 Intern-S1-Pro 를 처음 소개합니다. 전례 없는 규모로 확장된 본 모델은 일반 분야와 과학 분야 전반에 걸쳐 포괄적인 성능 향상을 실현합니다. 강화된 추론 능력과 이미지 - 텍스트 이해 능력을 넘어, 첨단 Agent 기능을 통해 지능이 더욱 고도화되었습니다. 동시에 화학, 재료과학, 생명과학, 지구과학 등 주요 과학 분야의 100 개 이상의 전문 과제를 숙달하도록 과학적 전문성이 획기적으로 확장되었습니다. 이러한 대규모 모델 구현은 XTuner 와 LMDeploy 의 견고한 인프라 지원 덕분에 가능해졌으며, 이를 통해 1 조 파라미터 수준에서 매우 효율적인 Reinforcement Learning(RL) 학습이 이루어질 뿐만 아니라 학습과 추론 간 엄격한 정밀도 일관성이 보장됩니다. 이러한 발전들을 원활하게 통합한 Intern-S1-Pro 는 일반 지능과 전문 지능의 융합을 한층 강화하여 '특화 가능한 범용 모델(Specializable Generalist)'로 자리매김하였습니다. 이는 오픈소스 모델 중 일반 능력 측면에서 최상위권을 유지하면서도, 전문 과학 과제의 깊이 측면에서는 독점 모델을 능가하는 성능을 입증하고 있습니다.
One-sentence Summary
The Intern-S1-Pro Team from Shanghai AI Laboratory introduces Intern-S1-Pro, a trillion-parameter scientific multimodal foundation model that employs Grouped Routing and Straight-Through Estimators to stabilize massive Mixture-of-Experts training. This approach enables the model to master over 100 specialized scientific tasks while outperforming proprietary systems in deep domain reasoning and general capabilities.
Key Contributions
- The paper introduces Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model that integrates advanced agent capabilities and masters over 100 specialized tasks across chemistry, materials, life sciences, and earth sciences.
- A novel group routing mechanism and a gradient estimation scheme are proposed to address training instability and router optimization challenges in massive Mixture-of-Experts architectures, ensuring efficient load balancing and accelerated expert updates.
- The work demonstrates state-of-the-art performance on scientific benchmarks through a specialized caption pipeline for scientific imagery and co-designed infrastructure using XTuner and LMDeploy, which enables efficient Reinforcement Learning training at the trillion-parameter scale with strict precision consistency.
Introduction
The rapid growth of Large Language Models and Visual Language Models has created a need for unified systems capable of accelerating scientific discovery across diverse fields like chemistry, biology, and materials science. Prior approaches often struggle with the immense diversity of scientific domains, where specialized knowledge and unique reasoning patterns require massive model capacity that smaller or single-purpose models cannot provide. Additionally, scaling to trillion-parameter levels introduces significant engineering hurdles, including training instability caused by expert load imbalance and the difficulty of optimizing router embeddings in Mixture of Experts architectures. To address these challenges, the authors introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model that leverages a novel Grouped Routing mechanism and a synergistic training framework to ensure stability and efficiency. By integrating advanced agent capabilities with joint training on general and specialized tasks, this model achieves state-of-the-art performance across over 100 scientific tasks while outperforming proprietary models in specialized depth.
Dataset
-
Dataset Composition and Sources: The authors construct a 6T-token pre-training corpus for Intern-S1-Pro, combining general image-text data with a specialized 270B-token scientific subset. This scientific data is derived primarily from PDF corpora across life sciences, chemistry, earth sciences, and materials science, addressing the scarcity of high-quality, aligned scientific image-text pairs found in standard web sources.
-
Key Details for the Scientific Subset:
- Source: Massive PDF corpora containing high-information-density figures such as experimental results, statistical plots, and structural diagrams.
- Extraction: The team uses MinerU2.5 for layout analysis to detect and localize figures, formulas, and tables, cropping them into standardized sub-images.
- Deduplication: Perceptual hashing (pHash) is applied to eliminate redundant visual content at scale.
- Captioning Strategy: A model routing mechanism assigns scientific sub-images to InternVL3.5-241B for domain-specific descriptions, while non-scientific sub-images are processed by CapRL-32B, a model trained with Reinforcement Learning with Verifiable Rewards (RLVR) to generate dense captions.
- Quality Control: A 0.5B-parameter text quality discriminator filters out garbled text, repetitive expressions, and low-information-density content.
-
Data Usage in Training: The authors employ the full 6T-token mixture for continued pre-training. The pipeline emphasizes the integration of the newly generated scientific captions to enhance the model's ability to understand and reason about complex visual content, moving beyond the brief or misaligned captions typical of original literature.
-
Processing and Metadata Details:
- Prompting: A multi-template randomized prompting strategy is adopted to ensure linguistic diversity in the generated captions.
- Alignment Focus: The pipeline specifically targets the creation of dense captions where text explicitly refers to visual elements, correcting the common issue where original literature text serves as an extension rather than a description.
- Evaluation Context: While the training data focuses on scientific and general multimodal alignment, the resulting model is evaluated against a suite of benchmarks including SciReasoner, SFE, and MMMU-Pro to test reasoning and perception capabilities.
Method
The Intern-S1-Pro model is constructed upon a foundation designed for scientific modalities and a 1T Mixture-of-Experts (MoE) architecture. The overall framework integrates three core pillars: a foundation for scientific modalities, fusion of scientific and general data, and evolution through Agentic Reinforcement Learning.
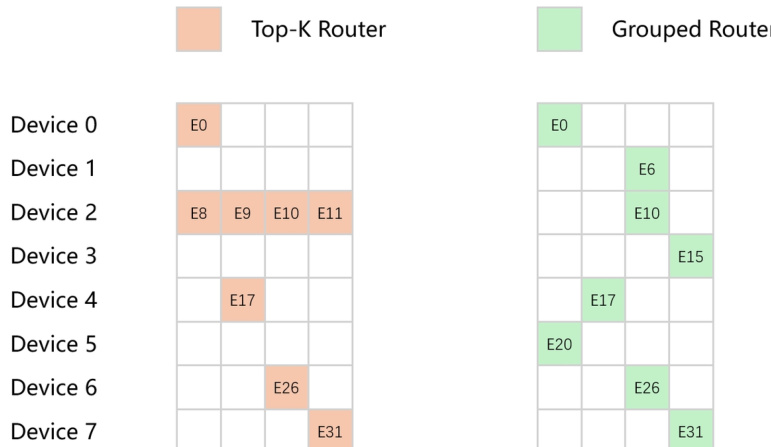
The model architecture is derived from Intern-S1 through an expert expansion process. This upcycling initialization ensures that well-trained experts from the base model are distributed across groups to maintain stability. To address load imbalance in ultra-large-scale MoE models, the authors replace the traditional Top-K Router with a Grouped Router. This design partitions experts into mutually disjoint groups based on device mapping, selecting the top experts within each group to achieve absolute load balancing across devices under an 8-way expert parallelism strategy.
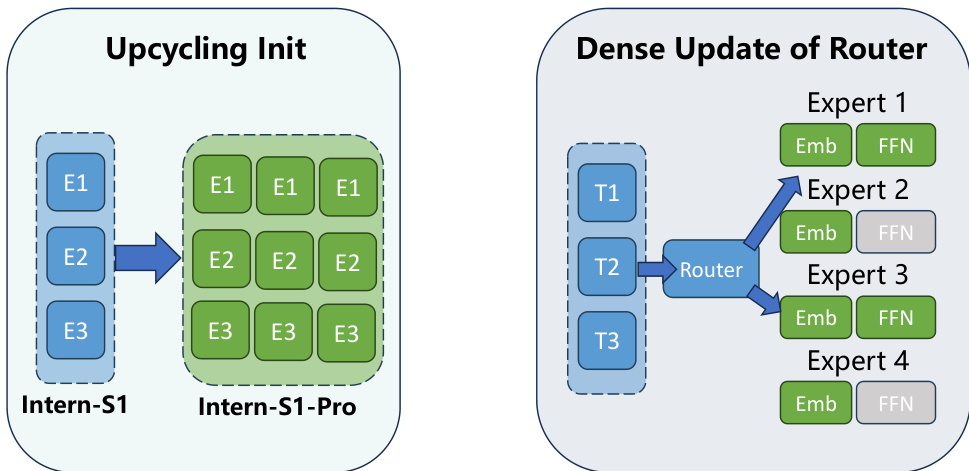
To enable effective training of the sparse routing mechanism, a Straight-Through Estimator (STE) is employed. This technique decouples the forward and backward passes, allowing gradients to flow through the full dense softmax distribution during backpropagation while preserving sparse selection in the forward pass. This ensures that all router embeddings receive informative learning signals, improving load balancing and convergence.
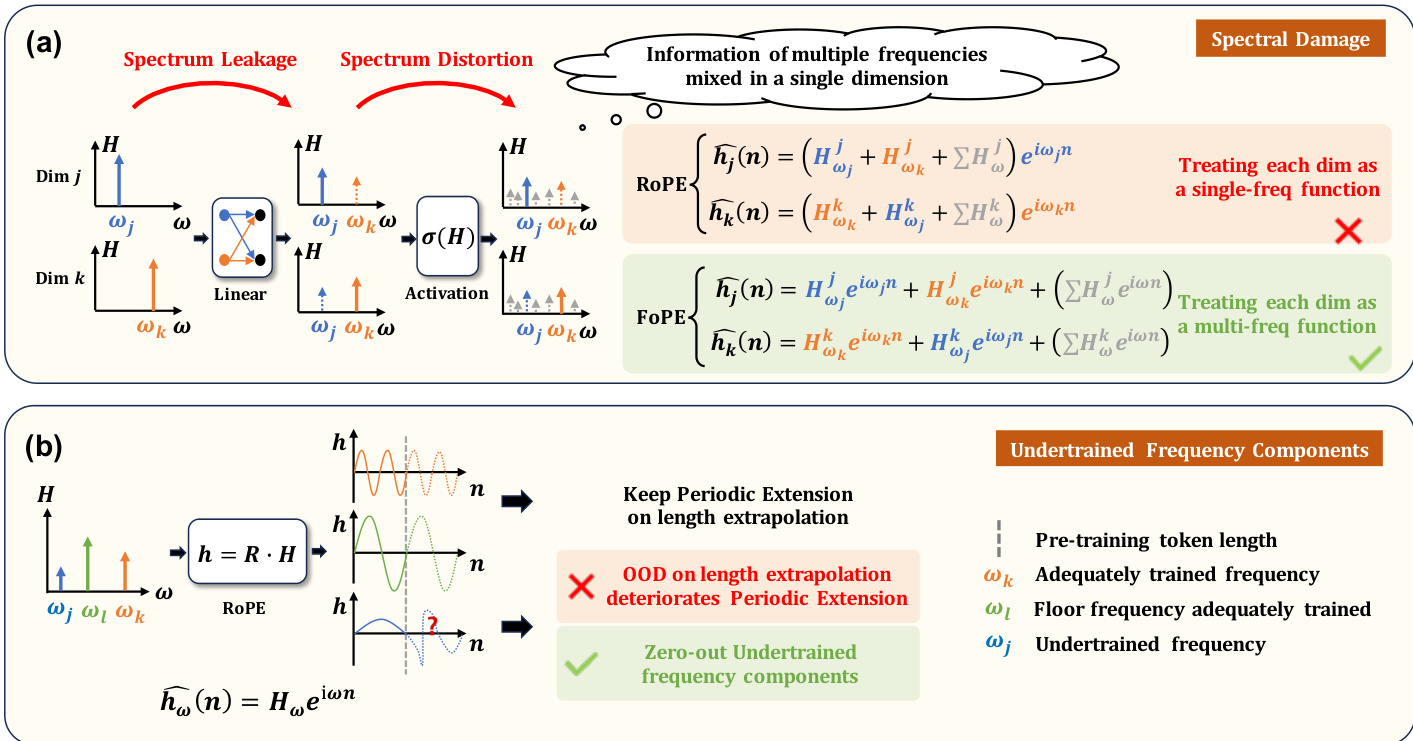
For positional encoding, the model introduces Fourier Position Encoding (FoPE) to better handle the continuous, wave-like nature of physical signals. Unlike Rotary Position Embedding (RoPE), which treats each dimension as a single-frequency function and can suffer from spectral damage, FoPE models each dimension as a multi-frequency function. This approach separates information more effectively and mitigates issues related to undertrained frequency components during length extrapolation.
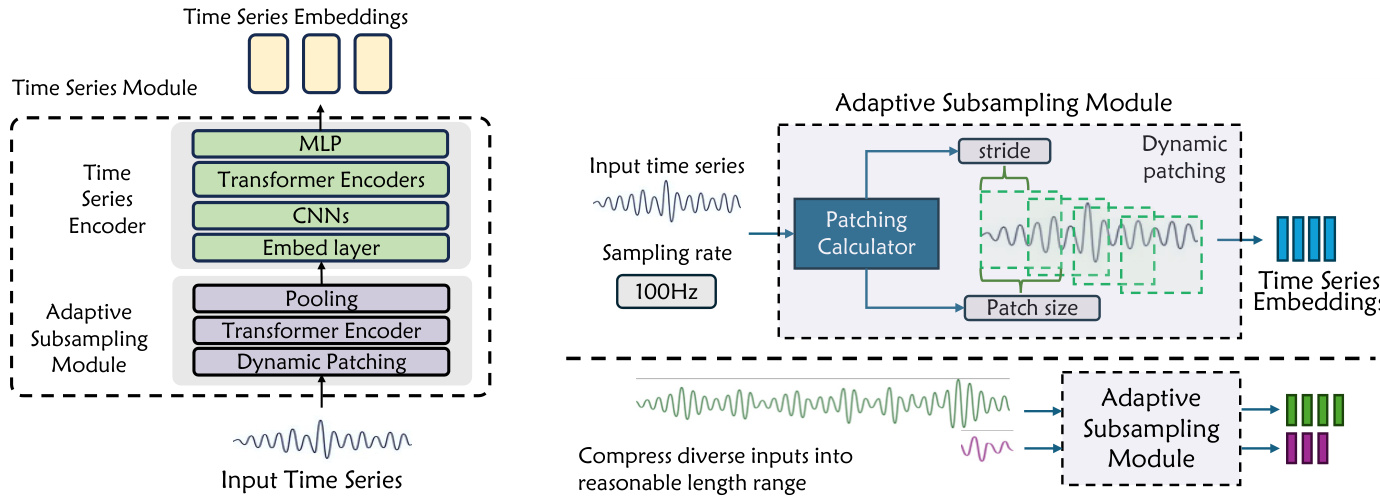
The architecture also includes a dedicated Time Series Module to handle diverse scientific data. This module features an Adaptive Subsampling Module that dynamically determines patch size and stride based on the signal and sampling rate. This allows the model to compress heterogeneous time series into a uniform representation space, handling sequences ranging from 100 to 106 time steps while preserving structural features.
Training involves resolving conflicts between scientific and general data through strategies like Structured Scientific Data Transformation and System Prompt Isolation. Additionally, Stable Mixed-Precision Reinforcement Learning is implemented for the sparse MoE models, utilizing FP8 quantization for expert layers and FP32 for the language modeling head to ensure numerical fidelity and training stability.
Experiment
- Comprehensive evaluations across scientific and general-purpose benchmarks in text-only and multimodal settings validate that Intern-S1-Pro achieves competitive performance with top-tier open-source models and surpasses leading closed-source models in scientific reasoning.
- Comparisons with the previous Intern-S1 generation demonstrate substantial improvements in general capabilities, expanded coverage of diverse scientific domains, and enhanced agent skills for multi-step planning and environmental grounding.
- Time series experiments confirm that incorporating a dedicated time series encoder and dynamic subsampling process allows the model to significantly outperform existing text and vision-language models in capturing complex temporal dynamics.
- A case study in biology reveals that a larger generalist model trained on specialized data outperforms dedicated domain-specific models, proving that integrating general reasoning with specialized knowledge creates a synergistic effect that boosts problem-solving capacity.