Command Palette
Search for a command to run...
GameplayQA: 3D 가상 에이전트의 의사결정이 밀집된 POV 동기화 멀티비디오 이해를 위한 벤치마킹 프레임워크
GameplayQA: 3D 가상 에이전트의 의사결정이 밀집된 POV 동기화 멀티비디오 이해를 위한 벤치마킹 프레임워크
Yunzhe Wang Runhui Xu Kexin Zheng Tianyi Zhang Jayavibhav Niranjan Kogundi Soham Hans Volkan Ustun
초록
3D 환경의 로봇공학부터 가상 세계에 이르기까지, 멀티모달 LLM 이 자율 에이전트의 지각 백본으로 점차 배포되고 있습니다. 이러한 응용 분야는 에이전트가 빠른 상태 변화를 지각하고, 행동을 올바른 개체에 할당하며, 1 인칭 관점에서 동시 다중 에이전트 행동을 추론할 수 있어야 합니다. 그러나 기존 벤치마크는 이러한 능력을 충분히 평가하지 못합니다. 이에 우리는 비디오 이해를 통해 에이전트 중심의 지각 및 추론 능력을 평가하기 위한 프레임워크인 GameplayQA 를 소개합니다. 구체적으로, 우리는 1.22 개/초의 밀도로 멀티플레이어 3D 게임플레이 비디오에 주석을 달았으며, 상태, 행동, 이벤트를 '자신(Self)', '기타 에이전트(Other Agents)', '세계(World)'라는 삼위 체계로 구조화한 시간 동기화 동시 캡션을 생성했습니다. 이는 다중 에이전트 환경을 위한 자연스러운 분해 방식입니다. 이러한 주석을 바탕으로, 우리는 3 단계의 인지 복잡도로 구성된 2,400 개의 진단용 QA 쌍을 정제하였으며, 모델의 환각 현상이 발생하는 지점을 정밀하게 분석할 수 있도록 구조화된 오답 분류체계를 함께 제시했습니다. 최첨단 MLLM 에 대한 평가 결과, 인간 수행 능력과 상당한 격차가 드러났으며, 특히 시간적 및 크로스 비디오 그라운딩, 에이전트 역할 할당, 그리고 게임의 의사결정 밀도 처리에서 공통적인 실패가 관찰되었습니다. 우리는 GameplayQA 가 체화 AI, 에이전트 지각, 그리고 세계 모델링이 교차하는 미래 연구에 자극을 줄 수 있기를 기대합니다.
One-sentence Summary
Researchers from the University of Southern California introduce GAMEPLAYQA, a novel benchmark densely annotating multiplayer 3D gameplay to evaluate multimodal LLMs on agentic perception. This framework uniquely employs a triadic Self-Other-World system to expose critical failures in temporal grounding and agent attribution that prior benchmarks miss.
Key Contributions
- The paper introduces GAMEPLAYQA, a framework for evaluating agentic-centric perception and reasoning that densely annotates multiplayer 3D gameplay videos at 1.22 labels per second with time-synced captions structured around a triadic system of Self, Other Agents, and the World.
- This work presents 2.4K diagnostic QA pairs organized into three levels of cognitive complexity and a structured distractor taxonomy designed to enable fine-grained analysis of where models hallucinate.
- Experiments demonstrate a substantial performance gap between frontier MLLMs and human benchmarks, revealing specific failures in temporal grounding, agent-role attribution, and handling the high decision density of the game environment.
Introduction
Multimodal LLMs are increasingly deployed as perceptual backbones for autonomous agents in 3D environments like robotics and virtual worlds, where they must track rapid state changes and reason about concurrent multi-agent behaviors from a first-person perspective. Existing benchmarks fail to evaluate these capabilities because they rely on slow-paced, passive observations that lack the high-frequency decision loops and dense embodiment required for real-world agency. To address this gap, the authors introduce GAMEPLAYQA, a framework that densely annotates multiplayer 3D gameplay videos with time-synced captions structured around a triadic system of Self, Other Agents, and the World. They refine these annotations into 2.4K diagnostic QA pairs organized by cognitive complexity and a structured distractor taxonomy to pinpoint specific failure modes such as temporal grounding errors and agent-role attribution mistakes.
Dataset
-
Dataset Composition and Sources The authors introduce GAMEPLAYQA, a benchmark derived from synchronized gameplay footage of 9 commercial multiplayer games spanning diverse genres. Data sources include YouTube, Twitch streams, and existing datasets. For multi-POV scenarios, the team identified streamer groups playing in the same match and manually aligned their individual recordings to create temporally synchronized video sets.
-
Key Details for Each Subset The final benchmark consists of 2,365 high-quality QA pairs generated from 2,709 true labels and 1,586 distractor labels across 2,219.41 seconds of footage. The data is organized around a Self-Other-World entity decomposition covering six primitive types: Self-Action, Self-State, Other-Action, Other-State, World-Object, and World-Event. Questions are categorized into three cognitive levels: Level 1 for basic perception, Level 2 for temporal reasoning, and Level 3 for cross-video understanding.
-
Data Usage and Generation Strategy The authors employ a combinatorial template-based algorithm to generate the dataset, initially producing 399,214 candidate pairs before downsampling to 4,000 to ensure balanced category coverage. This process systematically combines verified labels across five dimensions including video count, entity type, and distractor type. The resulting benchmark is used to evaluate MLLMs on fine-grained hallucination analysis, with distractors specifically designed to diagnose failures in lexical, temporal, role, or cross-video reasoning.
-
Processing and Annotation Workflow The pipeline utilizes a dense multi-track timeline captioning approach with a decision density of approximately 1.22 labels per second. Annotation follows a two-stage human-in-the-loop workflow where Gemini-3-Pro generates initial candidates that graduate student annotators verify and refine. The process includes a language prior filtering step where questions solvable without video input are removed, followed by human evaluation to resolve ambiguities and ensure semantic accuracy.
Method
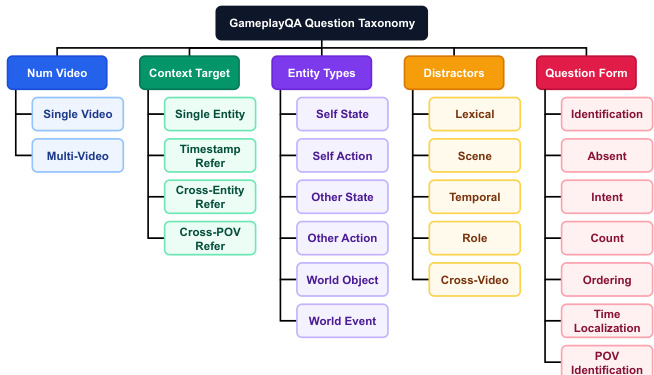
The authors establish a structured methodology for gameplay question answering, beginning with a detailed question taxonomy. Refer to the taxonomy diagram which outlines five orthogonal dimensions that define each question: Number of Videos, Context Target, Entity Types, Distractors, and Question Form. This hierarchical structure allows for the systematic generation of diverse query types ranging from simple identification to complex temporal localization.
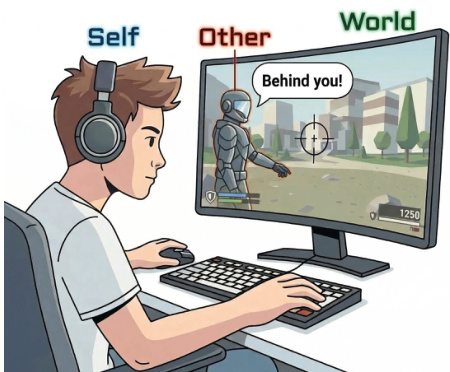
Central to the entity definition is the Self-Other-World perspective. As shown in the figure below, this framework categorizes entities into three groups: the player (Self), teammates or NPCs (Other), and the game environment (World). This tripartite division ensures that questions cover a broad spectrum of gameplay interactions and observations.
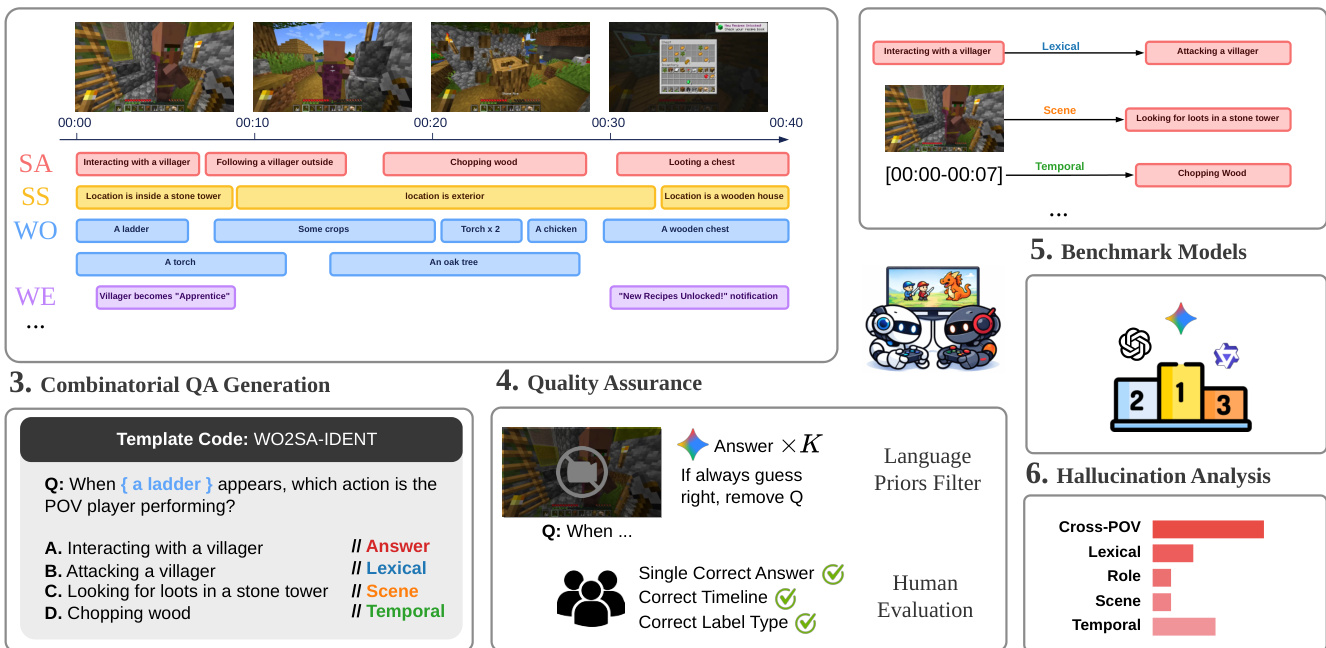
The dataset construction employs a combinatorial QA generation pipeline. Refer to the generation pipeline diagram which details the process from temporal event annotation to final question templating. The system extracts semantic segments such as Self Action and World Objects, then applies template codes to formulate multiple-choice questions. To maintain data integrity, a rigorous Quality Assurance phase is implemented. This includes an automated Language Priors Filter to eliminate questions solvable without visual input, alongside Human Evaluation to validate the answer key and timeline accuracy. For model evaluation, the authors utilize an LLM as a Judge to parse and extract the selected option from the model's raw output, ensuring consistent scoring across different benchmark models.
Experiment
- Evaluation of 16 open-source and proprietary MLLMs on GAME-PLAYQA validates a three-level cognitive hierarchy where performance consistently degrades from basic perception to temporal reasoning and cross-video understanding.
- Experiments identify Occurrence Count and Cross-Video Ordering as critical bottlenecks, confirming that current architectures struggle with sustained temporal attention and aligning events across multiple perspectives.
- Error analysis reveals that models handle static visual inputs better than temporal or cross-video distractors, with performance dropping significantly in fast-paced, decision-dense environments and when tracking other agents.
- Ablation studies demonstrate that genuine visual grounding is essential for task success, while temporal ordering is specifically critical for higher-level reasoning tasks but less so for basic perception.
- Cross-domain transfer experiments on autonomous driving and human collaboration datasets confirm that the benchmark framework generalizes to real-world spatiotemporal tasks while preserving relative difficulty rankings and model performance trends.