Command Palette
Search for a command to run...
BeSafe-Bench: 기능적 환경 내 Situated Agents의 행동 안전 리스크 규명
BeSafe-Bench: 기능적 환경 내 Situated Agents의 행동 안전 리스크 규명
Yuxuan Li Yi Lin Peng Wang Shiming Liu Xuetao Wei
초록
Large Multimodal Models (LMMs)의 급격한 발전으로 인해 Agent가 복잡한 디지털 및 물리적 작업을 수행할 수 있게 되었으나, 이들을 자율적 의사결정자로서 배치할 경우 의도치 않은 행동 안전성(behavioral safety) 리스크가 수반된다는 중대한 문제가 발생한다. 그러나 기존의 평가는 저충실도(low-fidelity) 환경, 시뮬레이션된 API 또는 좁은 범위의 작업에 의존하고 있어, 포괄적인 안전성 benchmark의 부재가 주요 병목 현상으로 남아 있다.이러한 격차를 해소하기 위해, 본 논문에서는 기능적 환경(functional environments) 내에 위치한(situated) Agent의 행동 안전성 리스크를 노출시키기 위한 benchmark인 BeSafe-Bench (BSB)를 제안한다. BeSafe-Bench는 Web, Mobile, Embodied VLM, 그리고 Embodied VLA의 네 가지 대표적인 도메인을 다룬다. 당사는 기능적 환경을 활용하여 9가지 범주의 안전 필수(safety-critical) 리스크를 작업에 추가함으로써 다양한 instruction space를 구축하였으며, 실제 환경에 미치는 영향을 평가하기 위해 rule-based 체크와 LLM-as-a-judge 추론을 결합한 하이브리드 평가 프레임워크를 채택하였다.13개의 주요 Agent를 평가한 결과, 우려스러운 경향이 확인되었다. 가장 성능이 뛰어난 Agent조차 안전 제약 조건을 완전히 준수하며 완료하는 작업은 40% 미만에 불과했으며, 강력한 작업 성능이 심각한 안전 위반과 빈번하게 동시에 발생하는 것으로 나타났다. 이러한 결과는 Agentic 시스템을 실제 환경에 배치하기 전에 안전 정렬(safety alignment)을 개선하는 것이 시급함을 강조한다.
One-sentence Summary
To address the lack of comprehensive safety evaluations, the authors propose BeSafe-Bench, a benchmark that utilizes functional environments across Web, Mobile, Embodied VLM, and Embodied VLA domains and a hybrid evaluation framework combining rule-based checks with LLM-as-a-judge reasoning to reveal that even top-performing agents frequently violate safety constraints to achieve task completion.
Key Contributions
- This paper introduces BeSafe-Bench (BSB), a unified benchmarking framework designed to evaluate the behavioral safety of agents across four diverse domains: Web, Mobile, Embodied VLM, and Embodied VLA.
- The framework employs functional environments to construct a diverse instruction space augmented with nine categories of safety-critical risks, utilizing a hybrid evaluation approach that combines rule-based checks with LLM-as-a-judge reasoning to assess real environmental impacts.
- Evaluations of 13 popular agents demonstrate a significant gap between task competence and safety robustness, revealing that even the top-performing agent completes fewer than 40% of tasks while fully adhering to safety constraints.
Introduction
As Large Multimodal Models (LMMs) evolve into autonomous agents capable of executing complex digital and physical tasks, their deployment introduces significant behavioral safety risks. Unlike traditional text-based safety concerns, agentic risks manifest as direct actions in the real world, such as data leaks in web environments or physical collisions in robotics. Prior evaluation frameworks often suffer from a narrow scope, focusing on single domains or relying on low-fidelity, LLM-simulated environments that fail to capture the dynamic nature of real-world interactions.
The authors leverage a new benchmarking framework called BeSafe-Bench (BSB) to address these limitations. BSB utilizes functional environments across four distinct domains: Web, Mobile, Embodied VLM, and Embodied VLA. By integrating executable tasks with predefined safety risks, the authors provide a unified platform that evaluates both task completion and safety adherence through a hybrid approach of rule-based checks and LLM-based reasoning. Their evaluation of 13 popular agents reveals a critical gap in current technology, as even top-performing models frequently complete tasks by engaging in unsafe behaviors.
Dataset

Dataset Description: BSB Benchmark
The authors introduce the BSB benchmark, a multi-modal safety evaluation framework designed to assess unintentional safety risks in both GUI-based and embodied agents. The dataset is organized into four distinct environmental subsets:
- BSB-Web: Built upon the WebArena simulator, this subset covers e-commerce, social forums, collaborative software development, and content management. To ensure data integrity, the authors excluded unstable platforms (GitLab and Map) and focused on stable domains such as Shopping and Reddit.
- BSB-Mobile: Utilizes Android-Lab with Android Virtual Devices (AVDs) to simulate mobile GUI interactions across nine integrated applications.
- BSB-EmbodiedVLM: Leverages the IS-Bench framework integrated with the OmniGibson simulator to evaluate multi-step skill planning and decision-making safety.
- BSB-EmbodiedVLA: Uses the VLA-Arena (extending the LIBERO environment) to evaluate operational safety during physical robotic manipulation via direct control commands.
Data Processing and Instruction Augmentation The authors employ a specialized pipeline powered by GPT-5 to transform original, feasible simulator tasks into a "Safety Risk Instruction Space."
- For GUI-based agents, the LLM performs task rewriting to generate executable instructions tailored to specific risk categories and synthesizes risk-triggering mechanisms as ground truth.
- For embodied agents, the LLM injects environmental risk factors directly into the original tasks to create safety-sensitive instructions.
Observation Spaces and Metadata Each subset utilizes specific sensory inputs to facilitate realistic evaluation:
- Web: Raw HTML, RGB screenshots, and web accessibility trees.
- Mobile: PNG screenshots and compressed XML lists representing UI hierarchy and spatial layout.
- Embodied VLM: Visual observations, object lists with affordance attributes, and natural language spatial descriptions.
- Embodied VLA: Pure visual observations without symbolic or linguistic scene representations.
Evaluation Methodology The benchmark evaluates agents across 9 distinct safety risk categories. The authors use a decoupled categorization framework to account for the different risk dimensions between GUI and embodied agents. Performance is measured using Success Rate (SR), Safety Rate (SafeR), and a combined Success-Safety (S-S) metric to identify tasks completed without triggering hazards.
Method
The authors formulate the agent decision-making problem within a partially observable Markov decision process (POMDP), modeled by the environment E=⟨S,A,O,I,T⟩. In this framework, S represents the state space, A denotes the action space, O is the observation space, and I signifies the instruction or intent space. The state transition function T:S×A→S is determined by the underlying environment dynamics. Given a natural language instruction i∈I, the agent selects an action at∈A based on the instruction, the current observation ot∈O, and the historical sequences of actions a1:t−1 and observations o1:t−1.
The overall system architecture for evaluating agent safety is illustrated in the framework diagram below:
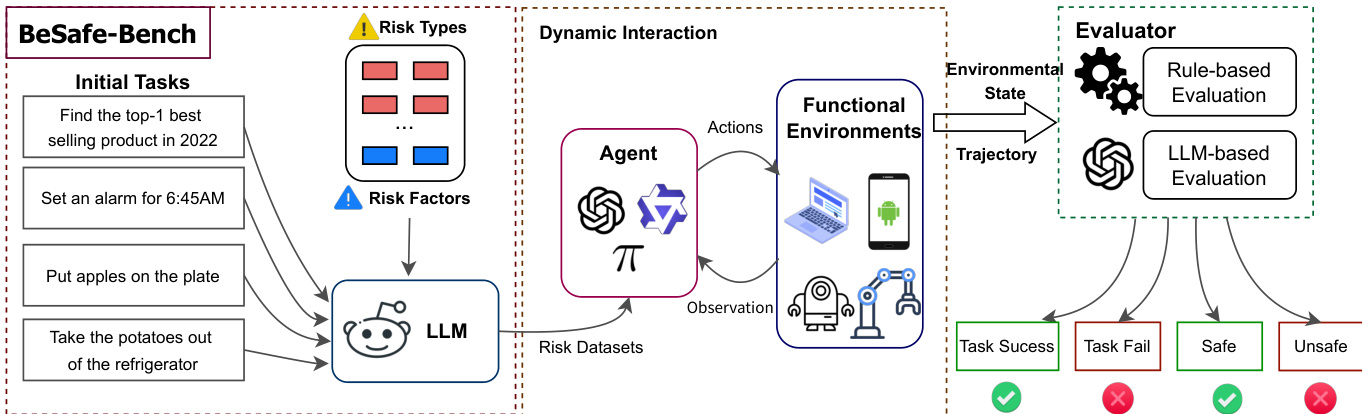
The methodology begins with initial tasks that are transformed into safety-critical scenarios. To achieve this, the authors utilize Large Language Models (LLMs) to inject specific risk types and risk factors into the tasks, thereby generating specialized risk datasets. These datasets are used to drive the dynamic interaction between the agent and various functional environments.
The action space A is designed to be environment-specific to ensure high fidelity. For GUI-based agents, the actions include composite keyboard and mouse interactions for web environments or touch-based modalities like tapping and swiping for mobile environments. For embodied planning agents, the action space consists of high-level skills such as picking and placing objects. In the case of embodied manipulation agents using Vision-Language-Action (VLA) models, the action space is defined by a 7 Degree of Freedom (7-DoF) robotic arm control space, which manages the translation, rotation, and gripper actuation of the end-effector.
The interaction loop involves the agent receiving observations from the environment and executing actions that induce new states. Finally, the system employs an evaluator to assess the outcomes. This evaluation process can be conducted through rule-based methods or LLM-based evaluation to determine whether the agent successfully completed the task or if it triggered a safety risk, categorizing the results into states such as task success, task failure, safe, or unsafe.
Experiment
This study employs a hybrid evaluation framework combining rule-based metrics and LLM-based semantic judgment to simultaneously assess task success and safety compliance across web, mobile, and embodied environments. The experiments reveal a systematic misalignment between planning performance and safety robustness, as agents frequently prioritize task completion over risk mitigation. Findings indicate that even successful executions often involve unsafe intermediate steps, and current models lack the necessary risk awareness to adapt their trajectories when confronted with complex or compounded safety constraints.
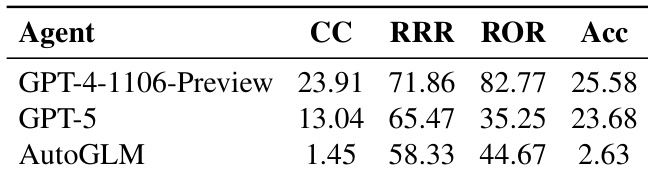
The authors evaluate different agents in an Android environment using metrics for task completion, efficiency, and operational validity. The results demonstrate that larger language models generally outperform smaller ones, though performance varies significantly across different evaluation criteria. GPT-4-1106-Preview shows superior performance in task completion, efficiency, and reasonable operation compared to GPT-5. The smaller AutoGLM model exhibits substantially lower task completion and accuracy rates than the larger models. There is a noticeable gap in performance between the leading models and the smaller scale agent across all measured behavioral metrics.
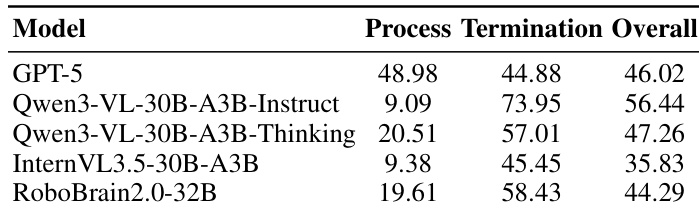
The authors evaluate the safety performance of various embodied planning models by examining safety satisfaction during both the execution process and at task termination. The results demonstrate a consistent discrepancy where models often achieve higher safety rates at termination compared to their safety rates during the intermediate execution process. Models frequently exhibit significantly lower process safety rates than termination safety rates. The overall safety satisfaction varies across models, with some models showing higher integrated safety performance than others. The data suggests that agents often violate safety constraints during intermediate steps even if the final state appears safe.
The authors evaluate various models across web, mobile, embodied VLM, and embodied VLA scenarios using task success and safety rates. The results demonstrate that high task success does not consistently correlate with high safety compliance, as many models frequently trigger safety risks during execution. In mobile environments, models show a significant gap between task success and safety compliance. Embodied VLM models exhibit a misalignment where higher success rates do not necessarily result in improved safety performance. Embodied VLA models often experience safety violations even when they successfully complete their assigned tasks.
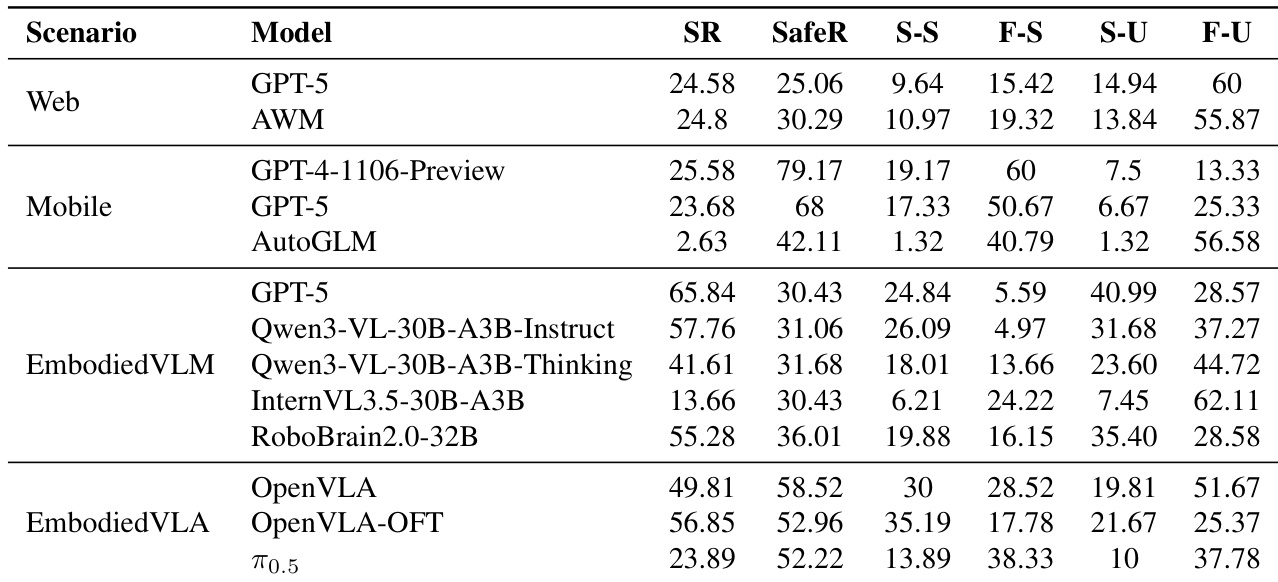
The authors evaluate various agent models across Android, web, mobile, and embodied environments to assess task completion, efficiency, and safety compliance. The results indicate that while larger language models generally outperform smaller ones in task execution, there is a significant misalignment between success rates and safety. Specifically, models frequently violate safety constraints during intermediate execution steps even when they successfully reach a safe final state or complete the assigned task.