Command Palette
Search for a command to run...
Omni-WorldBench: 세계 모델에 대한 포괄적인 상호작용 중심 평가 지향
Omni-WorldBench: 세계 모델에 대한 포괄적인 상호작용 중심 평가 지향
초록
비디오 기반 월드 모델은 비디오 생성과 3D 재구성이라는 두 가지 주류 패러다임을 따라 등장했습니다. 그러나 기존 평가 벤치마크는 생성형 모델의 경우 시각적 충실도와 텍스트 - 비디오 정합성에만 국한되거나, 정적 3D 재구성 지표에 의존하여 시간적 역동성을 근본적으로 간과하고 있습니다. 우리는 월드 모델링의 미래가 공간적 구조와 시간적 진화를 동시에 모델링하는 4D 생성에 있다고 주장합니다. 이 패러다임에서 핵심 역량은 상호작용 응답 능력, 즉 상호작용 행위가 시공간에 걸쳐 상태 전이를 어떻게 유도하는지를 충실히 반영하는 능력입니다. 그러나 현재까지 상호작용 응답이라는 핵심 차원을 체계적으로 평가하는 벤치마크는 존재하지 않습니다. 이러한 격차를 해소하기 위해 우리는 4D 환경에서 월드 모델의 상호작용 응답 능력을 평가하도록 설계된 포괄적 벤치마크인 Omni-WorldBench 를 제안합니다. Omni-WorldBench 는 두 가지 핵심 구성 요소로 이루어집니다: 첫째, 다양한 상호작용 수준과 장면 유형을 아우르는 체계적인 프롬프트 세트인 Omni-WorldSuite, 둘째, 상호작용 행위가 최종 결과와 중간 상태 진화 궤적 모두에 미치는 인과적 영향을 정량화함으로써 월드 모델링 능력을 측정하는 에이전트 기반 평가 프레임워크인 Omni-Metrics 입니다. 우리는 다양한 패러다임에 속하는 18 개 대표 월드 모델에 대해 광범위한 평가를 수행했습니다. 분석 결과, 현재 월드 모델들이 상호작용 응답 측면에서 중요한 한계를 노출하고 있음이 확인되었으며, 이는 향후 연구를 위한 실행 가능한 통찰을 제공합니다. Omni-WorldBench 는 상호작용형 4D 월드 모델링의 발전을 촉진하기 위해 공개될 예정입니다.
One-sentence Summary
Researchers from UCAS, CASIA, Beihang University, BUPT, and Alibaba Group introduce Omni-WorldBench, a novel benchmark evaluating interactive response in 4D world models. Unlike prior static or fidelity-focused tools, it employs Omni-Metrics to quantify how actions drive spatiotemporal state transitions, revealing critical gaps in current generative and reconstruction paradigms.
Key Contributions
- The paper introduces Omni-WorldBench, a comprehensive benchmark designed to evaluate the interactive response capabilities of world models in 4D settings by addressing the lack of systematic evaluation for temporal dynamics and spatial structure.
- This work presents Omni-WorldSuite, a systematic prompt suite spanning diverse interaction levels and scene types, alongside Omni-Metrics, an agent-based framework that quantifies model performance by measuring the causal impact of interaction actions on outcomes and state evolution trajectories.
- Extensive evaluations of 18 representative world models across multiple paradigms reveal critical limitations in current interactive response capabilities, providing actionable insights for future research in interactive 4D world modeling.
Introduction
Video-based world models are critical for tasks like planning and counterfactual simulation, yet current evaluation methods fail to capture their core capability: interactive response in 4D environments. Existing benchmarks either prioritize visual fidelity and text-video alignment or rely on static 3D metrics that ignore temporal dynamics and limit interactions to simple camera movements. To address this, the authors introduce Omni-WorldBench, a comprehensive framework featuring Omni-WorldSuite for diverse interaction prompts and Omni-Metrics, an agent-based system that quantifies how actions causally drive state evolution across space and time.
Dataset
-
Dataset Composition and Sources The authors introduce Omni-WorldSuite, a benchmark containing 1,068 evaluation prompts designed to test interactive world models. The dataset spans general daily-life scenarios and task-oriented domains including autonomous driving, embodied robotics, and gaming. It is constructed using two primary strategies: dataset-grounded generation and concept-driven synthesis.
-
Key Details for Each Subset
- Dataset-Grounded Subset: This portion extracts initial frames and camera trajectories from open-source datasets to ensure realism. It utilizes DriveLM for autonomous driving, InternData-A1 for embodied robotics, and Sekai for gaming and simulation.
- Concept-Driven Subset: This portion synthesizes text, initial frames, and camera trajectories using a generate-verify-refine pipeline. It relies on prototype concepts covering indoor/outdoor scenes and specific interaction types, with initial frames generated by FLUX.1-dev and refined through manual screening.
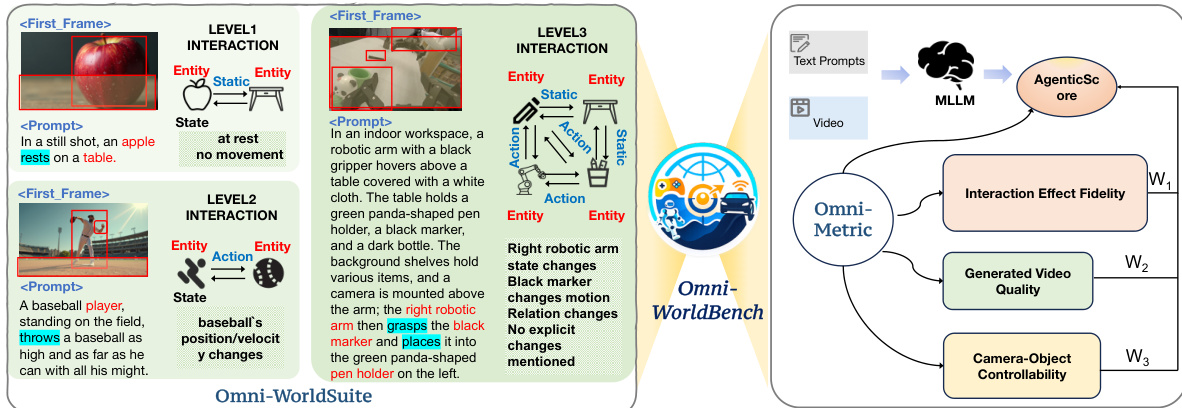
- Interaction Levels: Prompts are categorized into three hierarchical levels: Level 1 (effects confined to a single object), Level 2 (localized interactions between objects), and Level 3 (global environmental changes affecting multiple objects). Level 2 contains the largest number of prompts.
-
Data Usage and Processing The authors use this dataset strictly for evaluation rather than model training. Each prompt serves as a test case comprising an initial frame image, a textual description of interaction-driven evolution, and optional camera trajectories. The evaluation pipeline measures generated video quality, camera-object controllability, and interaction effect fidelity to produce a unified AgenticScore.
-
Metadata Construction and Refinement To facilitate metric computation, the authors annotate each prompt with auxiliary metadata including lists of affected and unaffected entities, expected motion directions, and temporal event sequences. A multi-stage image generation pipeline ensures high-fidelity initial frames with a minimum resolution of 1024x1024. All generated captions and images undergo manual verification to correct spatial relations, eliminate linguistic ambiguity, and ensure physical plausibility.
Method
The authors introduce Omni-Metric, a comprehensive framework designed to facilitate an omni-directional assessment of world models. This framework delineates three pivotal dimensions to establish a rigorous paradigm for benchmarking perceptual quality, environmental stability, and causal reasoning capabilities. As shown in the framework diagram, the system evaluates Generated Video Quality, Camera-Object Controllability, and Interaction Effect Fidelity, ultimately aggregating these scores through an adaptive weighting mechanism.
Before computing specific metrics, the framework performs structured information extraction from the generated video v conditioned on an evaluation prompt P. The authors employ GroundingDINO and SAM to extract temporally consistent segmentation mask sequences for each entity, denoted as {{trajk}k=1N}. Additionally, RAFT is used to estimate the optical flow field F to capture regional motion intensity, while relative camera motion is approximated using optical flow variations between consecutive frames.
The Interaction Effect Fidelity dimension serves as a core contribution, quantitatively assessing long-term content consistency, causal logical ordering, and adherence to physical laws. To address these challenges, four comprehensive evaluation metrics are proposed. InterStab-L quantifies long-horizon temporal coherence by assessing visual content consistency across user-specified temporal revisit pairs R={(ta,tb)}. It integrates low-level structural fidelity and high-level semantic consistency via a composite similarity metric s(i,j):
s(i,j)=I1(SSIMgray(Ii,Ij)+cos(ϕ(Ii),ϕ(Ij))),where ϕ(⋅) represents a pre-trained vision encoder. To prevent trivial static sequences from inflating scores, a dynamics gating mechanism is incorporated. InterStab-N assesses the stability of non-target regions by measuring motion energy in areas outside the target entity masks. InterCov quantifies object-level causal faithfulness by verifying whether interaction-affected entities exhibit semantically consistent responses while unaffected entities maintain stability, leveraging Vision-Language Models (VLMs) for semantic validation. Finally, InterOrder quantifies the alignment between the chronology of propagated events and the ground-truth sequence E={ei}i=1K by using a VLM to verify temporal precedence.
Refer to the interaction examples to understand the complexity of scenarios evaluated, ranging from Level 1 static interactions to Level 3 complex dynamic interactions involving robotics and physics.

For the Generated Video Quality dimension, the authors leverage established metrics from prior benchmarks such as VBench and WorldScore, covering imaging quality, temporal flickering, motion smoothness, and content alignment. To effectively balance static and dynamic video attributes, the framework employs AgenticScore to perform adaptive weight allocation.
The AgenticScore mechanism treats each evaluation metric as an independent agent. Three interaction-centered agents compute scores for Interaction Effect Fidelity (AI), Generated Video Quality (AG), and Camera-Object Controllability (AC). An aggregation agent then analyzes the relative importance of these dimensions using an MLLM conditioned on the evaluation prompt, mapping the resulting ranking to predefined weight coefficients w1, w2, and w3. The final score is defined as:
AgenticScore=w1AI+w2AG+w3AC.This approach ensures that the evaluation adapts to diverse application scenarios, assigning different weights to different evaluation dimensions based on the semantic content of the prompt rather than simply averaging all metrics.
Experiment
- Camera-Object Controllability experiments validate a new evaluation framework that assesses scene coherence, object consistency, and transition detection, demonstrating that reframing object control as a visual question answering task improves robustness over rule-based matching.
- Comprehensive benchmarking of 18 world models across Text-to-Video, Image-to-Video, and camera-controlled paradigms reveals that Image-to-Video models generally achieve the highest overall performance, while camera-aware methods excel in specific controllability metrics.
- Quantitative and qualitative analyses confirm that while most models have mastered basic temporal smoothness and flickering reduction, significant limitations persist in maintaining causal interaction consistency, handling complex physical dynamics, and achieving joint camera-object control.
- Visual comparisons highlight that advanced models like Wan2.2 and HunyuanWorld successfully preserve anatomical integrity and scene logic during complex actions, whereas others suffer from structural collapse or the generation of spurious elements, validating the proposed Omni-Metric framework.