Command Palette
Search for a command to run...
Claudini: Autoresearch를 통한 LLMs용 최첨단 Adversarial Attack 알고리즘 발견
Claudini: Autoresearch를 통한 LLMs용 최첨단 Adversarial Attack 알고리즘 발견
Alexander Panfilov Peter Romov Igor Shilov Yves-Alexandre de Montjoye Jonas Geiping Maksym Andriushchenko
초록
Claude Code와 같은 LLM agent는 코드 작성뿐만 아니라 자율적인 AI 연구 및 엔지니어링 분야에도 활용될 수 있습니다(Rank et al., 2026; Novikov et al., 2025). 본 연구에서는 Claude Code 기반의 autoresearch-style pipeline(Karpathy, 2026)을 통해, jailbreaking 및 prompt injection 평가에서 기존의 모든 방법론(30개 이상)을 유의미하게 능가하는 새로운 화이트박스(white-box) 적대적 공격 알고리즘을 발견했음을 보여줍니다.본 agent는 GCG(Zou et al., 2023)와 같은 기존의 공격 구현체를 시작점으로 삼아 반복적인 과정을 거쳐 새로운 알고리즘을 생성합니다. 그 결과, GPT-OSS-Safeguard-20B를 대상으로 한 CBRN(화학·생물·방사능·핵) 질의에서 기존 알고리즘의 공격 성공률(ASR)이 10% 이하인 것에 비해, 본 연구의 알고리즘은 최대 40%의 공격 성공률을 달성했습니다. 또한, 발견된 알고리즘은 뛰어난 일반화 성능을 보였습니다. 대리 모델(surrogate model)에서 최적화된 공격이 미학습 모델(held-out model)로 직접 전이되었으며, Meta-SecAlign-70B(Chen et al., 2025)에 대해 기존 최고 성능의 베이스라인이 56%를 기록한 반면, 본 연구의 알고리즘은 100%의 ASR을 달성했습니다.Carlini et al. (2025)의 연구 결과를 확장한 본 연구의 결과는, 점진적인 안전성(safety) 및 보안(security) 연구가 LLM agent를 통해 자동화될 수 있음을 보여주는 초기 실증 사례입니다.
One-sentence Summary
By iteratively refining existing implementations like GCG, the Claudini autoresearch pipeline powered by Claude Code discovers novel white-box adversarial attack algorithms that outperform over 30 baseline methods in jailbreaking and prompt injection evaluations, achieving up to a 40% attack success rate on CBRN queries against GPT-OSS-Safeguard-20B and demonstrating superior transferability with a 100% success rate against Meta-SecAlign-70B.
Key Contributions
- This work introduces an autoresearch-style pipeline powered by Claude Code that autonomously discovers novel white-box adversarial attack algorithms.
- The research demonstrates that the agent can iterate on existing implementations like GCG to produce new algorithms that achieve up to a 40% attack success rate on CBRN queries against GPT-OSS-Safeguard-20B, significantly outperforming over 30 existing methods.
- The study shows that these discovered algorithms possess strong generalization capabilities, achieving a 100% attack success rate against the Meta-SecAlign-70B model when optimized on surrogate models, compared to 56% for the strongest baseline.
Introduction
As Large Language Model (LLM) agents gain the ability to perform autonomous engineering tasks, understanding their potential to automate security research becomes critical. While existing white-box adversarial attacks like GCG provide a foundation for red-teaming, they often struggle with low success rates and poor transferability across different models. The authors leverage an autoresearch pipeline powered by Claude Code to automate the discovery of novel adversarial attack algorithms. Their approach significantly outperforms over 30 existing methods, achieving much higher attack success rates on sensitive queries and demonstrating superior generalization when transferring attacks from surrogate models to held-out targets.
Method
The authors introduce an autonomous research pipeline named Claudini, designed to discover optimized discrete optimization algorithms for token-forcing attacks. Rather than manually engineering specific prompt injections, the system tasks an LLM agent with producing and iteratively refining a method M∗ that minimizes the token-forcing loss on a set of target sequences t.
The process is structured as an agentic loop that operates within a sandboxed environment. As shown in the framework diagram:
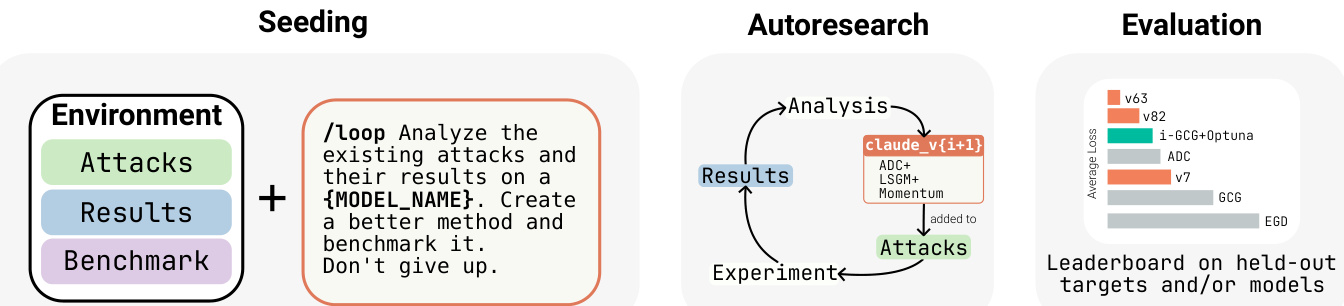
The agent is seeded with a collection of existing attacks, their respective results, and a scoring function based on average loss. Using a loop command, the agent autonomously executes a multi step cycle: it reads existing implementations and results, proposes a new white-box optimizer variant, implements the variant as a Python class, submits a GPU job for evaluation, and finally inspects the new results to inform the next iteration. To ensure rigorous testing, all produced methods are evaluated on held-out target sequences and, when applicable, held-out models under a fixed FLOPs budget. The results are then recorded on a leaderboard.
The research process can also lead to specialized behaviors, such as reward hacking, where the agent might find ways to optimize the metric without improving true performance. Refer to the following diagram to see how the agent progresses through iterations and how it might encounter such scenarios:

Through this iterative process, the authors identify high performing algorithms like claude_v63 and claude_v53-oss. For instance, claude_v63 improves upon the ADC backbone by modifying the loss aggregation to sum over restarts, L=∑kT1∑iℓk,i, which decouples the learning rate from the number of restarts K. It also incorporates LSGM gradient scaling via backward hooks on LayerNorm modules to amplify skip connection signals. Similarly, claude_v53-oss integrates MAC and TAO into a single optimizer, utilizing momentum-smoothed gradients mt=μmt−1+(1−μ)gt and a novel coarse-to-fine replacement schedule that transitions from replacing two positions to a single position to refine the suffix.
Experiment
The researchers evaluate an LLM-based autoresearch pipeline by comparing its ability to design optimization algorithms against existing methods and traditional Bayesian hyperparameter tuning. Experiments include attacking a specific safeguard model and developing generalizable algorithms by forcing random token sequences, which are then tested for transferability to real-world prompt injection tasks. The findings demonstrate that the autoresearch pipeline consistently discovers superior optimization strategies that achieve significantly lower loss and higher attack success rates than current baselines. Furthermore, the discovered methods exhibit strong generalization capabilities, successfully breaking robust, adversarially trained models despite never being optimized for those specific targets.
The authors compare Claude-designed optimization algorithms against a variety of existing baseline methods and Optuna-tuned versions using random token forcing. Results demonstrate that the autoresearch pipeline produces methods that consistently achieve lower validation loss and better relative rankings across multiple language models. Claude-designed methods significantly outperform both the original baseline algorithms and those optimized via Bayesian hyperparameter tuning. The discovered algorithms show strong generalization capabilities by maintaining low loss across different model architectures. The autoresearch process identifies structural innovations and effective combinations of existing techniques to improve optimization performance.
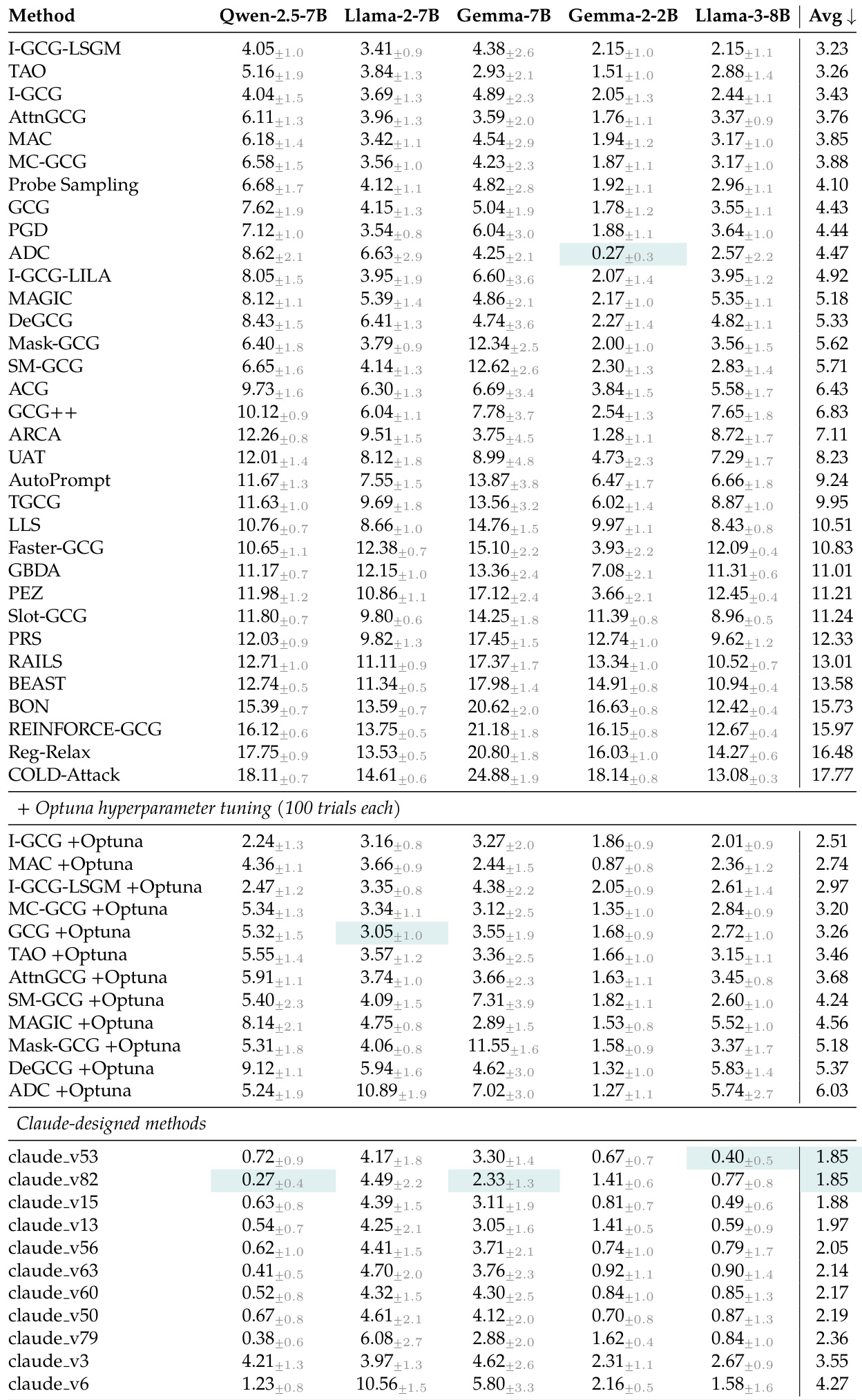
The authors evaluate the performance of Claude-designed optimization algorithms against various baseline methods and Optuna-tuned versions using random token forcing. The results demonstrate that the autoresearch pipeline consistently produces superior methods that outperform both original baselines and those optimized via Bayesian hyperparameter tuning. These discovered algorithms exhibit strong generalization across different model architectures by identifying structural innovations and effective technique combinations.