Command Palette
Search for a command to run...
World Reasoning Arena
World Reasoning Arena
초록
World models (WMs)는 Agent가 복잡한 환경을 이해하고, 예측하며, 그에 따라 행동할 수 있도록 돕는 현실 세계의 내부 시뮬레이터 역할을 수행하도록 설계되었습니다. 기존의 WM benchmark들은 차상태 예측(next-state prediction)과 시각적 충실도(visual fidelity)에만 국한되어 있어, 지능적 행동에 요구되는 더욱 풍부한 시뮬레이션 능력을 간과하고 있습니다.이러한 격차를 해소하기 위해, 본 논문에서는 차세대 월드 시뮬레이션의 세 가지 핵심 차원을 따라 WMs를 평가하는 포괄적인 benchmark인 WR-Arena를 소개합니다. (i) Action Simulation Fidelity: 의미론적으로 유의미한 다단계 지침(multi-step instructions)을 해석 및 수행하고, 다양한 반사실적 롤아웃(counterfactual rollouts)을 생성하는 능력, (ii) Long-horizon Forecast: 장기적인 상호작용 전반에 걸쳐 정확하고 일관되며 물리적으로 타당한 시뮬레이션을 유지하는 능력, (iii) Simulative Reasoning and Planning: 구조화된 환경과 개방형 환경 모두에서 대안적인 미래를 시뮬레이션, 비교 및 선택함으로써 목표 지향적 추론(goal-directed reasoning)을 지원하는 능력을 평가합니다.저희는 단발성 및 지각적 평가를 넘어 이러한 능력들을 정밀하게 측정하기 위해 태스크 분류 체계(task taxonomy)를 구축하고 다양한 데이터셋을 큐레이션하였습니다. 최신 SOTA WMs를 대상으로 진행한 광범위한 실험을 통해, 현재의 모델들과 인간 수준의 가설적 추론(hypothetical reasoning) 사이에는 상당한 격차가 존재함을 확인하였습니다. 또한, WR-Arena가 견고한 이해, 예측 및 목적 있는 행동이 가능한 차세대 월드 모델을 발전시키기 위한 진단 도구이자 가이드라인임을 입증하였습니다.
One-sentence Summary
To address the limitations of existing benchmarks focused on visual fidelity, the authors introduce WR-Arena, a comprehensive benchmark that evaluates world models across three fundamental dimensions: action simulation fidelity, long-horizon forecasting, and simulative reasoning and planning.
Key Contributions
- The paper introduces WR-Arena, a comprehensive benchmark designed to evaluate world models as internal simulators capable of supporting reasoning, long-range forecasting, and purposeful action.
- This work establishes a multi-dimensional evaluation framework that assesses action simulation fidelity, long-horizon forecasting, and simulative reasoning and planning through a curated task taxonomy and diverse datasets.
- Extensive experiments with state-of-the-art models demonstrate the benchmark's ability to diagnose significant gaps in instruction following and temporal consistency, providing a roadmap for developing next-generation world models.
Introduction
World models serve as internal simulators that allow intelligent agents to anticipate outcomes and perform mental thought experiments to guide decision making. This capability is critical for advancing embodied AI and autonomous systems that must navigate complex, unpredictable environments. However, existing benchmarks primarily focus on short term next state prediction and visual fidelity, which fails to measure whether a model can maintain physical consistency or support long horizon reasoning. The authors introduce WR-Arena, a comprehensive benchmark designed to evaluate world models across three advanced dimensions: action simulation fidelity, long horizon forecasting, and simulative reasoning and planning.
Method
The authors propose an evaluation framework centered on Action Simulation Fidelity, which measures a world model's ability to accurately follow multi-step natural language instructions. This property assesses whether a model can generate a sequence of reasonable states that faithfully adhere to high-level control instructions, such as complex tasks involving multiple semantic steps.
The core methodology begins with an initial world state s0. To facilitate evaluation, the authors utilize a Large Language Model (LLM) to propose several multi-step high-level action sequences A=⟨a1,…,an⟩. These sequences are generated under specific feasibility constraints to ensure they are non-contradictory and causally applicable. Once the sequences are defined, the world model performs a rollout R(s0,A)=⟨s1,…,sT⟩, producing a sequence of states conditioned on the provided actions.
As shown in the figure below:
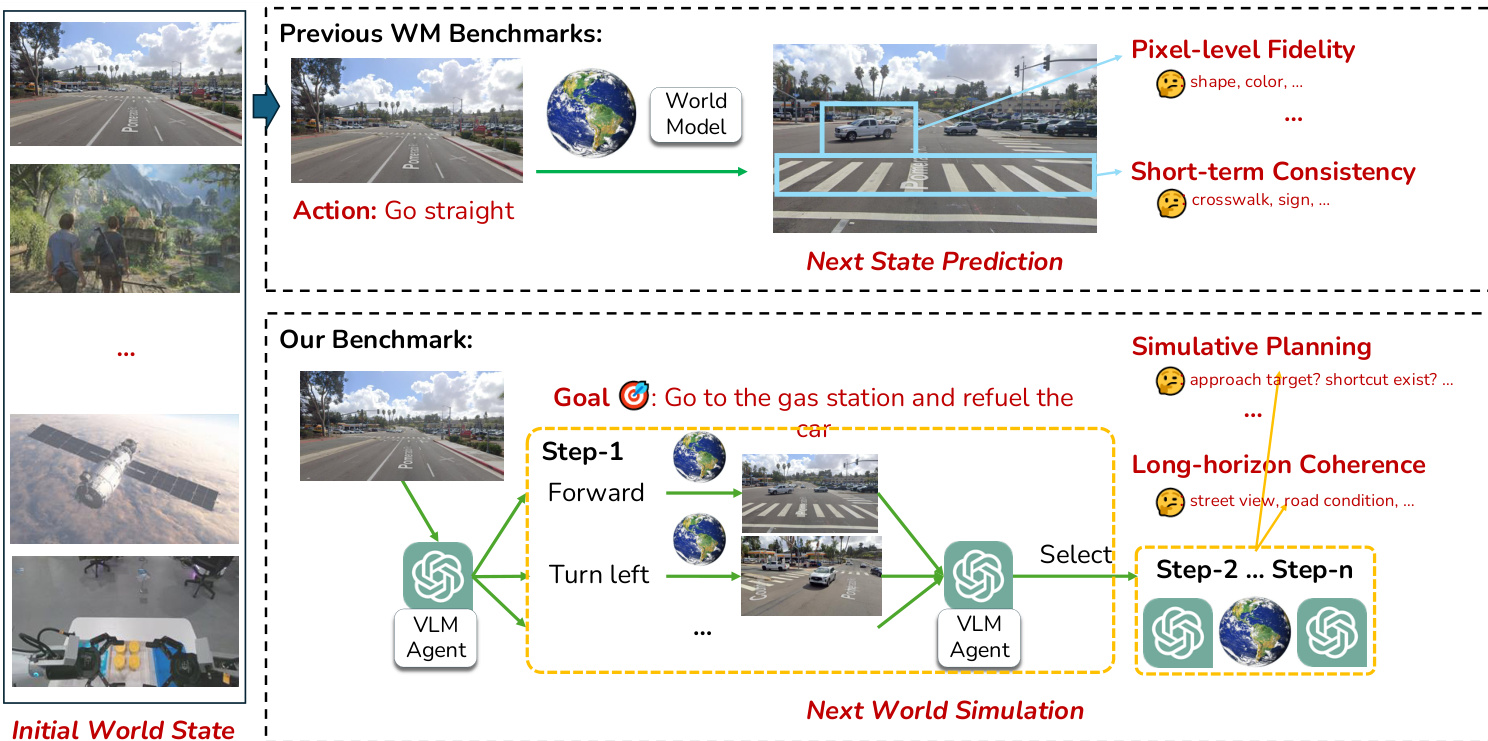 The proposed benchmark distinguishes itself from previous world model evaluations by moving beyond simple pixel-level fidelity or short-term consistency toward simulating complex, long-horizon planning and reasoning tasks.
The proposed benchmark distinguishes itself from previous world model evaluations by moving beyond simple pixel-level fidelity or short-term consistency toward simulating complex, long-horizon planning and reasoning tasks.
The evaluation is bifurcated into two distinct settings: Agent Simulation and Environment Simulation. In Agent Simulation, the goal is to determine if the model can drive a controllable entity through intended behaviors while maintaining stable background dynamics. By sampling multiple distinct action sequences A for a single s0, the authors induce counterfactual futures to verify if the model produces appropriately diverse yet coherent outcomes.
Conversely, Environment Simulation focuses on the model's ability to apply high-level scene interventions and simulate their causal consequences while the agent's policy remains neutral. This setting tests whether scene-level actions result in visually verifiable and predictable downstream effects.
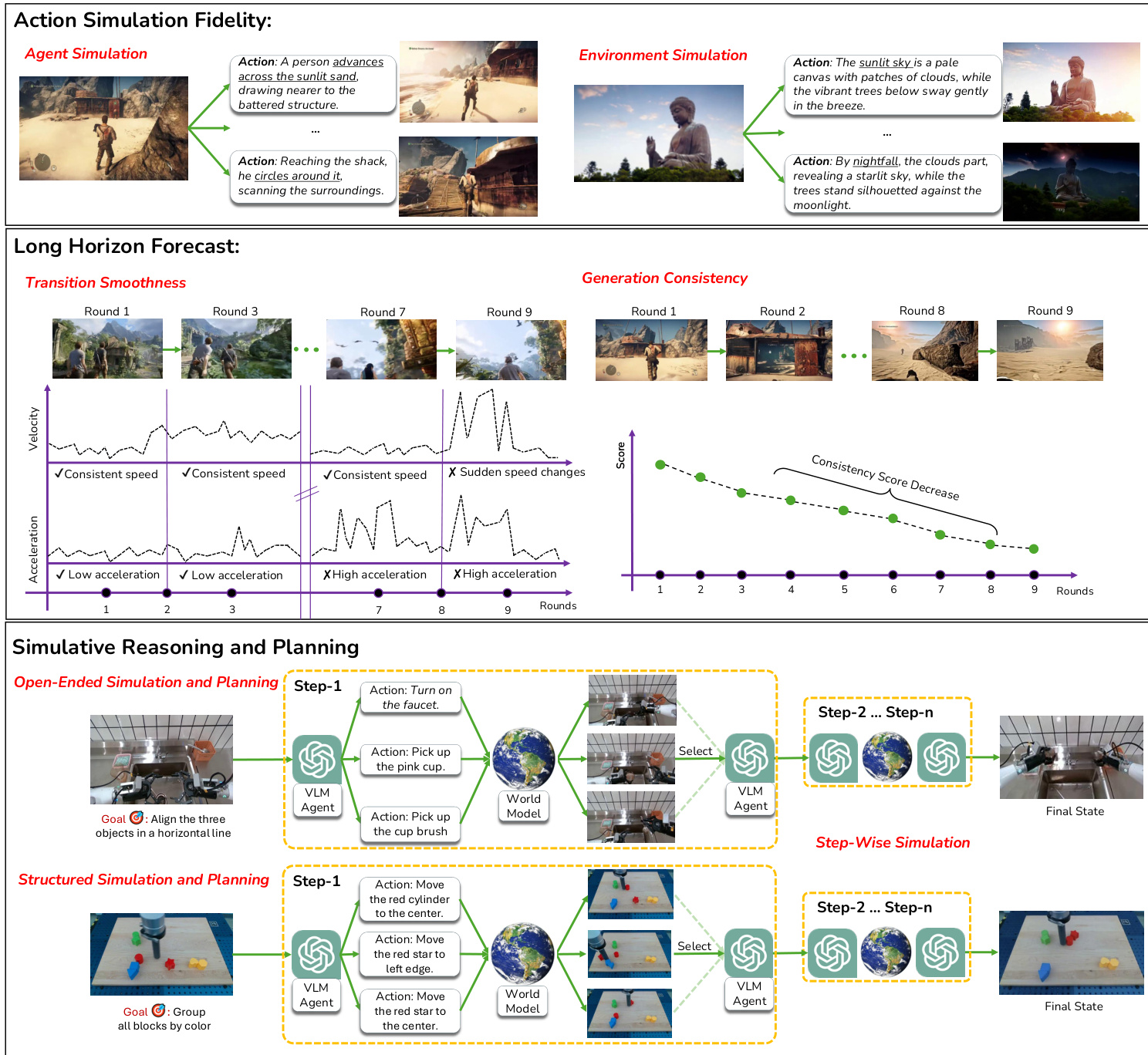
To quantify the quality of these simulations, the authors employ vision-language models (VLMs) as judges. These judges score the generated rollouts based on two primary metrics: action faithfulness, which measures how well the simulation follows the instructions, and action precision, which assesses the accuracy of the resulting state changes.
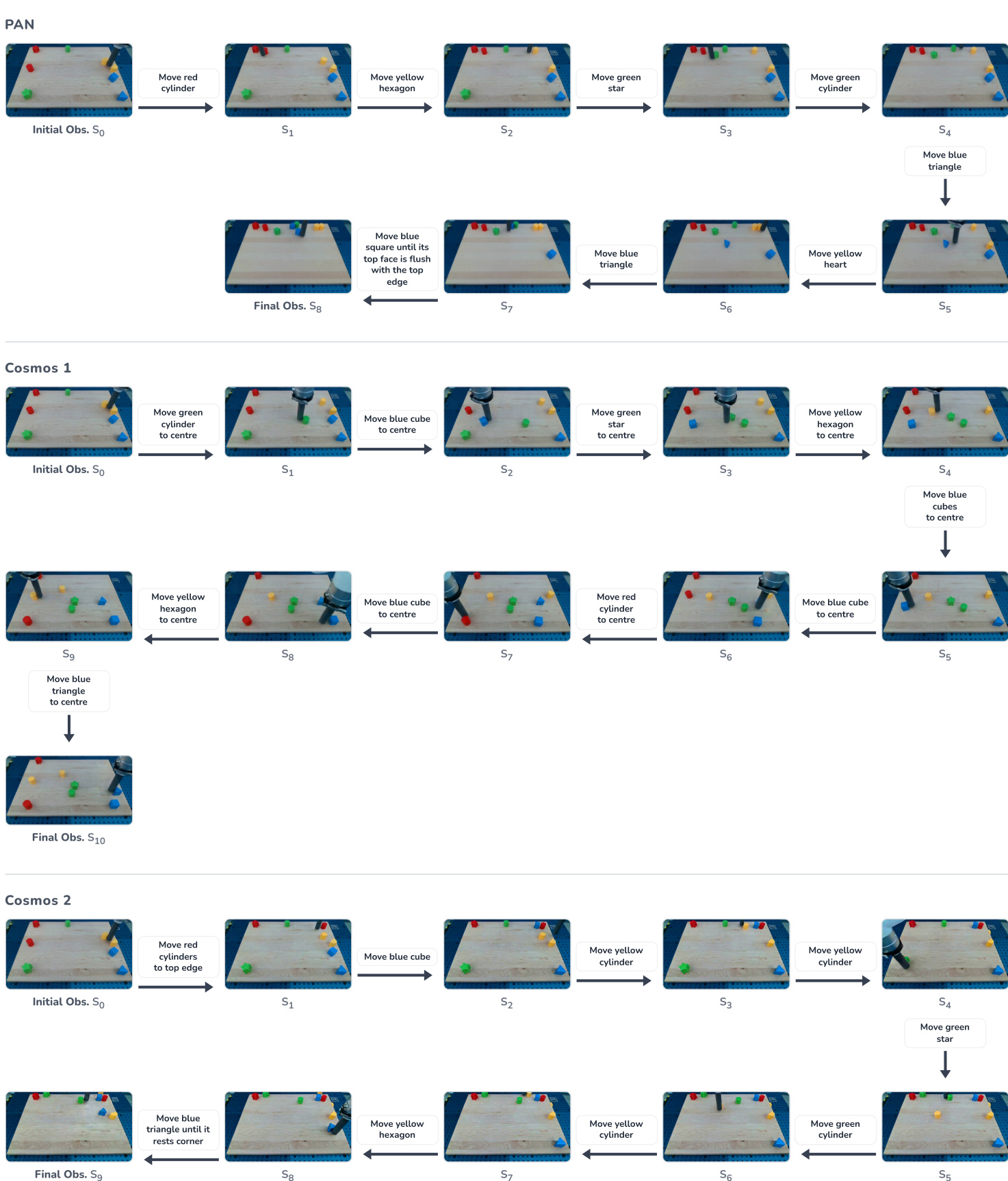
Experiment
The evaluation assesses world models and video generators across three dimensions: action simulation fidelity, long-horizon forecasting, and simulative reasoning and planning. These experiments validate whether models can faithfully simulate environment changes, maintain temporal smoothness and consistency over extended sequences, and support goal-directed decision-making when integrated with a vision-language planner. While commercial video generators offer high perceptual quality, they often struggle with domain adaptation and long-term stability, whereas the PAN model demonstrates a more balanced ability to maintain semantic grounding and mitigate error accumulation during multi-step rollouts.
The authors evaluate various world models and video generators across three dimensions: action simulation fidelity, long-horizon forecasting, and simulative reasoning and planning. The results indicate that while different models excel in specific areas, maintaining consistency and smoothness over long sequences remains a significant challenge for all tested systems. PAN achieves the highest scores in transition smoothness and simulation consistency during long-horizon forecasting. MiniMax demonstrates strong performance in action simulation fidelity for both agent and environment-centric tasks. PAN provides the most substantial improvements in trajectory-level success for both open-ended and structured simulative planning tasks.
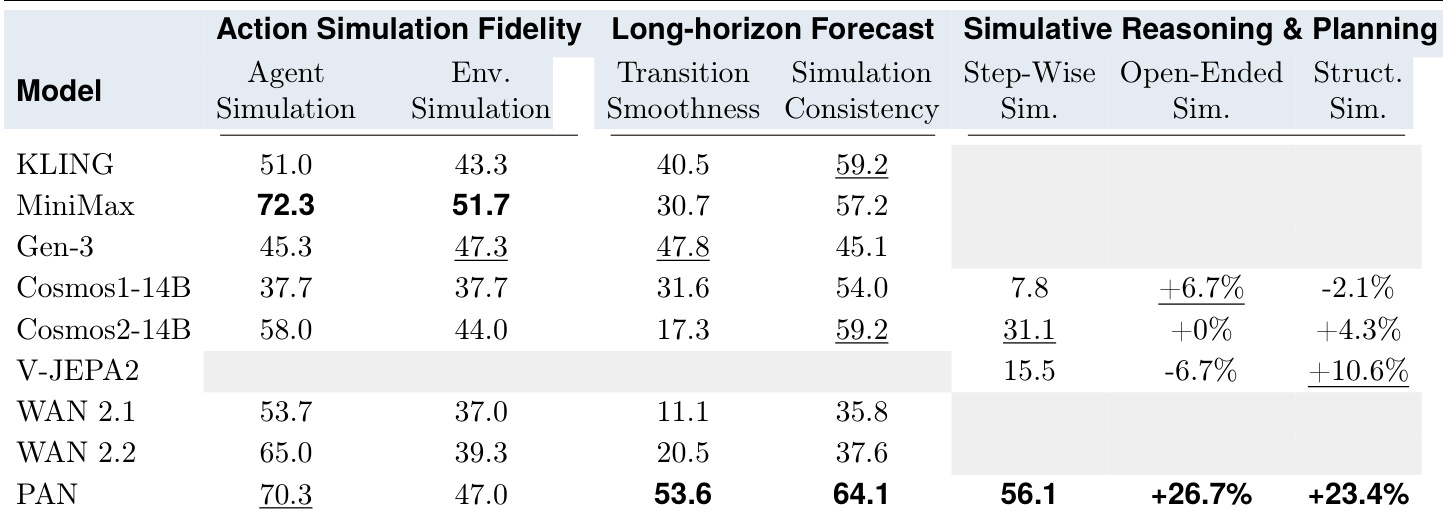
The authors evaluate several world models and video generators based on their action simulation fidelity, long-horizon forecasting capabilities, and simulative reasoning and planning abilities. While MiniMax shows strength in action simulation fidelity for various tasks, PAN demonstrates superior performance in maintaining transition smoothness, simulation consistency, and trajectory-level success during planning. Overall, the experiments reveal that while different models excel in specific dimensions, achieving consistency and smoothness over long sequences remains a persistent challenge for all evaluated systems.