Command Palette
Search for a command to run...
단순성에 의한 속도: 빠른 오디오-비디오 생성 기반 모델을 위한 단일 스트림 아키텍처
단순성에 의한 속도: 빠른 오디오-비디오 생성 기반 모델을 위한 단일 스트림 아키텍처
초록
우리는 인간 중심 생성을 위한 오픈소스 오디오-비디오 생성 기반 모델인 daVinci-MagiHuman 을 제안합니다. daVinci-MagiHuman 은 단일 스트림 Transformer 를 활용하여 텍스트, 비디오, 오디오를 통합된 토큰 시퀀스 내 self-attention 만으로 처리함으로써 동기화된 비디오와 오디오를 동시에 생성합니다. 이 단일 스트림 설계는 멀티스트림 또는 크로스 어텐션 아키텍처의 복잡성을 회피하면서도 표준 학습 및 추론 인프라를 통해 최적화가 용이합니다. 본 모델은 인간 중심 시나리오에서 특히 우수한 성능을 발휘하여 표현력 있는 얼굴 연기, 자연스러운 음성 - 표현 조율, 사실적인 신체 움직임, 그리고 정교한 오디오 - 비디오 동기화를 구현합니다. 또한 중국어 (표준 중국어 및 광둥어), 영어, 일본어, 한국어, 독일어, 프랑스어를 포함한 다국어 음성 생성을 지원합니다. 효율적인 추론을 위해 단일 스트림 백본에 모델 증류, 잠재 공간 초해상도, 그리고 Turbo VAE 디코더를 결합하여, 단일 H100 GPU 에서 2 초 내에 256p 해상도의 5 초 분량 비디오를 생성할 수 있습니다. 자동 평가에서 daVinci-MagiHuman 은 주요 오픈 모델 중 가장 높은 시각적 품질과 텍스트 정렬 성능을 달성했으며, 음성 명료도 측면에서 최소의 단어 오류율 (14.60%) 을 기록했습니다. 쌍대 인간 평가에서는 2,000 건의 비교를 통해 Ovi 1.1 대비 80.0%, LTX 2.3 대비 60.9% 의 승리율을 기록했습니다. 우리는 베이스 모델, 증류된 모델, 초해상도 모델, 그리고 추론 코드베이스를 포함한 완전한 모델 스택을 오픈소스로 공개합니다.
One-sentence Summary
SII-GAIR and Sand.ai introduce daVinci-MagiHuman, an open-source audio-video foundation model that uses a single-stream Transformer to generate synchronized human-centric content without complex cross-attention. This approach enables efficient multilingual speech and motion synthesis, achieving superior visual quality and speech intelligibility compared to leading open models.
Key Contributions
- The paper introduces daVinci-MagiHuman, an open-source audio-video generative foundation model that utilizes a single-stream Transformer to process text, video, and audio within a unified token sequence via self-attention only, avoiding the complexity of multi-stream or cross-attention architectures.
- This work demonstrates strong human-centric generation capabilities, including expressive facial performance and precise audio-video synchronization, while supporting multilingual spoken generation across six major languages and achieving a 14.60% word error rate in automatic evaluations.
- The authors present an efficient inference pipeline combining model distillation, latent-space super-resolution, and a Turbo VAE decoder to generate a 5-second 256p video in 2 seconds on a single H100 GPU, alongside a fully open-source release of the complete model stack and codebase.
Introduction
Video generation is rapidly evolving toward synchronized audio-video synthesis, yet open-source solutions struggle to balance high-quality output, multilingual support, and inference efficiency within a scalable architecture. Existing open models often rely on complex multi-stream designs that are difficult to optimize jointly with training and inference infrastructure. The authors introduce daVinci-MagiHuman, an open-source model that leverages a single-stream Transformer to unify text, video, and audio processing within a shared-weight backbone. This simplified approach enables fast inference through latent-space super-resolution while delivering strong human-centric generation quality and broad multilingual capabilities across languages like English, Chinese, and Japanese.
Method
The authors propose daVinci-MagiHuman, which centers on a single-stream Transformer architecture designed to jointly generate synchronized video and audio. Unlike dual-stream approaches that process modalities separately, this model represents text, video, and audio tokens within a unified sequence processed via self-attention only. This design avoids the complexity of cross-attention modules while remaining easy to optimize with standard infrastructure.
As shown in the figure below:
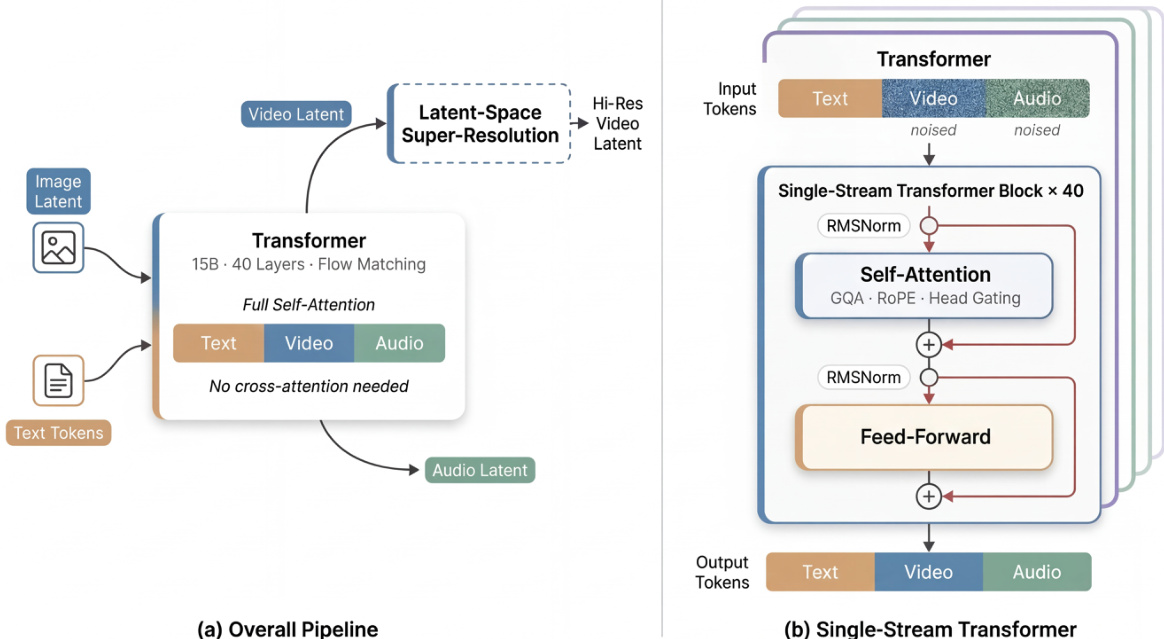
The base generator accepts text tokens, a reference image latent, and noisy video and audio tokens. It jointly denoises the video and audio tokens using a 15B-parameter, 40-layer Transformer. A latent-space super-resolution stage can subsequently refine the generated video at higher resolutions. The internal architecture adopts a sandwich structure where the first and last 4 layers utilize modality-specific projections and normalization parameters, while the middle 32 layers share parameters across all modalities. This design preserves modality sensitivity at the boundaries while enabling deep multimodal fusion in the shared representation space.
Several key mechanisms enhance the model's performance and stability. The system employs timestep-free denoising, inferring the denoising state directly from the noisy inputs rather than using explicit timestep embeddings. Additionally, the model incorporates per-head gating within the attention blocks. For each attention head h, a learned scalar gate modulates the output oh via a sigmoid function σ, resulting in a gated output:
o~h=σ(qh)ohThis improves numerical stability and representability with minimal overhead.
To ensure efficient inference, the authors integrate several complementary techniques. Latent-space super-resolution allows the base model to generate at a lower resolution before refining in latent space, avoiding expensive pixel-space operations. A Turbo VAE decoder replaces the standard decoder to reduce overhead on the critical path. Furthermore, full-graph compilation via MagiCompiler fuses operators across layer boundaries, and model distillation using DMD-2 reduces the required denoising steps to 8 without classifier-free guidance.
Experiment
- Quantitative benchmarks on VerseBench and TalkVid-Bench validate that daVinci-MagiHuman achieves superior visual quality, text alignment, and speech intelligibility compared to Ovi 1.1 and LTX 2.3, while maintaining competitive physical consistency.
- Pairwise human evaluations confirm a strong preference for daVinci-MagiHuman over both baselines, with raters favoring its overall audio-video quality, synchronization, and naturalness in the majority of comparisons.
- Inference efficiency tests demonstrate that the pipeline generates high-resolution 1080p videos in under 40 seconds on a single H100 GPU, utilizing a distilled base stage and Turbo VAE decoder to balance speed and output quality.