Command Palette
Search for a command to run...
AutoHarness: 코드 하네스(Code Harness)의 자동 합성을 통한 LLM Agents의 성능 향상
AutoHarness: 코드 하네스(Code Harness)의 자동 합성을 통한 LLM Agents의 성능 향상
Xinghua Lou Miguel Lázaro-Gredilla Antoine Dedieu Carter Wendelken Wolfgang Lehrach Kevin P. Murphy
초록
지난 몇 년간 언어 모델 분야에서 상당한 진전이 있었음에도 불구하고, 이러한 모델들을 Agent로 사용할 경우 특정 상태(state)에서 최적의 결과(suboptimal)를 내지 못하는 것을 넘어, 외부 환경에서 엄격히 금지하는 행동을 수행하려는 경우가 빈번하게 발생합니다. 예를 들어, 최근 Kaggle GameArena 체스 경진대회에서는 Gemini-2.5-Flash 패배 원인의 78%가 불법 수(illegal moves)에 기인한 것으로 나타났습니다. 대개 이러한 실패를 방지하기 위해 사람들은 LLM 주변에 수동으로 'harness'를 작성하여 제어하곤 합니다.본 논문에서는 Gemini-2.5-Flash가 (게임) 환경으로부터 피드백을 받아 소수의 반복적인 코드 정제(iterative code refinement) 과정을 거침으로써, 이러한 코드 harness를 자동으로 합성(synthesize)할 수 있음을 입증합니다. 이렇게 생성된 harness는 145가지의 서로 다른 TextArena 게임(1인용 및 2인용 모두 포함)에서 발생하는 모든 불법 수를 방지하며, 이를 통해 상대적으로 규모가 작은 Gemini-2.5-Flash 모델이 Gemini-2.5-Pro와 같은 더 큰 모델보다 더 뛰어난 성능을 발휘할 수 있도록 합니다.나아가 본 기술을 극한까지 적용하면, Gemini-2.5-Flash가 전체 policy를 코드로 생성하도록 하여 의사 결정 시점에 LLM을 사용할 필요를 없앨 수 있습니다. 이렇게 생성된 code-policy는 16개의 TextArena 1인용 게임에서 Gemini-2.5-Pro 및 GPT-5.2-High보다 더 높은 평균 보상(average reward)을 기록했습니다. 우리의 연구 결과는 더 작은 모델을 사용하여 커스텀 코드 harness(또는 전체 policy)를 합성하는 것이 훨씬 더 큰 모델보다 뛰어난 성능을 낼 수 있을 뿐만 아니라, 비용 효율성 측면에서도 더 유리하다는 것을 보여줍니다.
One-sentence Summary
By using iterative code refinement based on environmental feedback, the AutoHarness method enables Gemini-2.5-Flash to automatically synthesize custom code harnesses that prevent illegal actions across 145 TextArena games, allowing the smaller model to outperform larger models such as Gemini-2.5-Pro and GPT-5.2-High.
Key Contributions
- The paper introduces a method for automatically synthesizing code harnesses through iterative refinement, using environmental feedback and a structured tree search with Thompson sampling to ensure action validity.
- This approach enables a smaller model, Gemini-2.5-Flash, to outperform much larger models like Gemini-2.5-Pro by preventing illegal moves across 145 different TextArena games.
- The research demonstrates that the technique can be extended to generate entire code-based policies that eliminate the need for LLM inference during decision-making, achieving higher average rewards than Gemini-2.5-Pro and GPT-5.2-High on 16 TextArena games.
Introduction
Large language models (LLMs) are increasingly used as autonomous agents in complex environments, yet they often struggle to follow strict environmental rules, frequently attempting illegal actions that lead to failure. Current mitigation strategies, such as fine-tuning models or manually engineering hand-coded harnesses, are often too costly, slow, or labor-intensive to scale across different tasks. The authors propose AutoHarness, a framework that leverages an LLM's own code-generation capabilities to automatically synthesize a custom code harness through iterative refinement. By employing a tree search guided by Thompson sampling, the system uses environmental feedback to evolve a program that acts as a rejection sampler, ensuring all agent actions are valid. This approach allows smaller, more cost-effective models to outperform much larger counterparts and can even be extended to generate entire code-based policies that eliminate the need for LLM inference during decision-making.
Dataset

Dataset Overview
-
Composition and Sources: The authors utilize a subset of TextArena, a collection of complex text-based games. The selection includes all 1-player and 2-player games, excluding nine titles with free-form text or dialogue-based action spaces (such as Mafia and Codenames). This results in a final set of 145 games, ranging from classics like Chess, Checkers, Blackjack, and Sudoku to various novel variants.
-
Data Processing and Modifications: To increase task difficulty, the authors manually modified the observation strings by removing all "Available Moves" hints. This change forces the agent to deduce legal actions from environmental feedback rather than simply copying a provided list of moves from the prompt.
-
Usage and Implementation: The dataset is used to evaluate an agent's ability to navigate diverse game environments. The observations are structured to provide the game context and the current state (such as a board representation) without explicit guidance on valid actions, mimicking real-world scenarios where agents must interpret environmental cues.
Method
The authors propose a method that maintains multiple code hypotheses within a tree structure to optimize code-based game playing. To navigate this tree, they employ Thompson sampling to determine which node to refine next, using the average legal move accuracy as the heuristic value for each node.
As shown in the framework diagram:
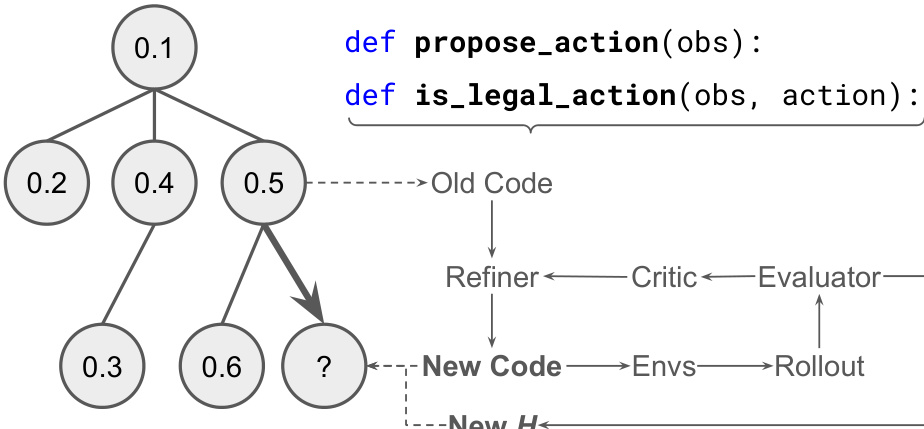
The refinement process functions as a gradient-free code optimizer driven by a base Large Language Model (LLM). This process relies on a feedback loop involving a critic and an evaluator that interacts with the environment. The critic provides feedback regarding whether previous attempted moves were legal and the resulting rewards. The refinement logic is conditional based on the legality of the actions: if the function is_legal_action() returns True but the action is nonetheless invalid, the system refines both the propose_action() and is_legal_action() functions. Conversely, if is_legal_action() returns False and the action is invalid, the refinement is restricted solely to propose_action().
This approach enables the generation of various code harnesses, such as harness-as-action-filter, which uses the LLM to rank a set of legal moves generated by propose_action(). Another variation is the harness-as-action-verifier, where the LLM generates an action that is subsequently verified by is_legal_action(). If the action is found to be invalid, the process repeats with a new prompt containing an illegal action warning. Finally, the harness-as-policy uses the code itself to select actions. In the authors' implementation, this policy utilizes primitive Python functions and standard libraries like numpy, allowing for inference without invoking an LLM.
Experiment
The experiments first validate the effectiveness of a code-based action verifier by training it to achieve a perfect legal action success rate across various games. Subsequent evaluations compare agents using this harness against larger models in both single-player and two-player settings, demonstrating that the augmented smaller model can outperform much larger counterparts. Finally, the harness-as-policy approach is tested to determine if an entire policy can be synthesized into pure code, showing that it achieves superior rewards compared to high-reasoning LLMs while maintaining nearly zero test-time cost.
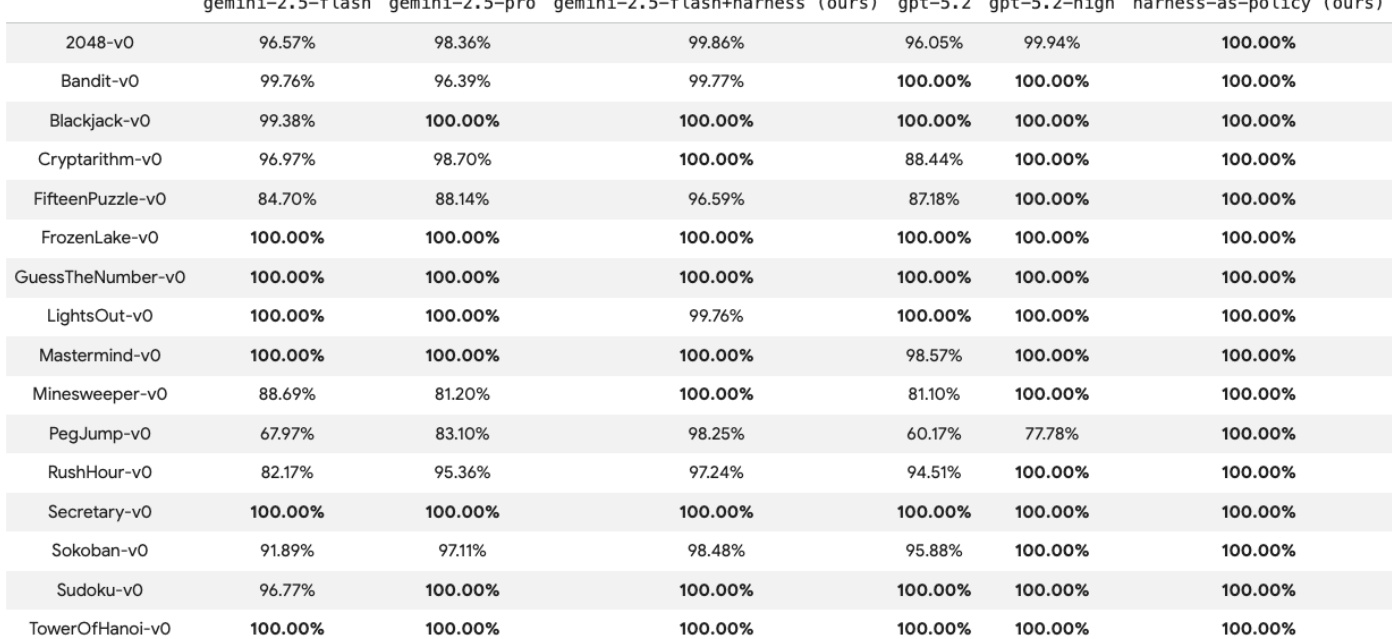
The authors evaluate the performance of various agents across multiple games, comparing different model configurations and the proposed harness methods. The results demonstrate that the proposed harness approach consistently achieves high legal action success rates across a wide variety of game environments. The harness as policy method achieves perfect legal action success rates in several game environments. The proposed harness approach shows competitive or superior legal action rates compared to standard large language models. Most evaluated games show high levels of legal action consistency when using the proposed methods.
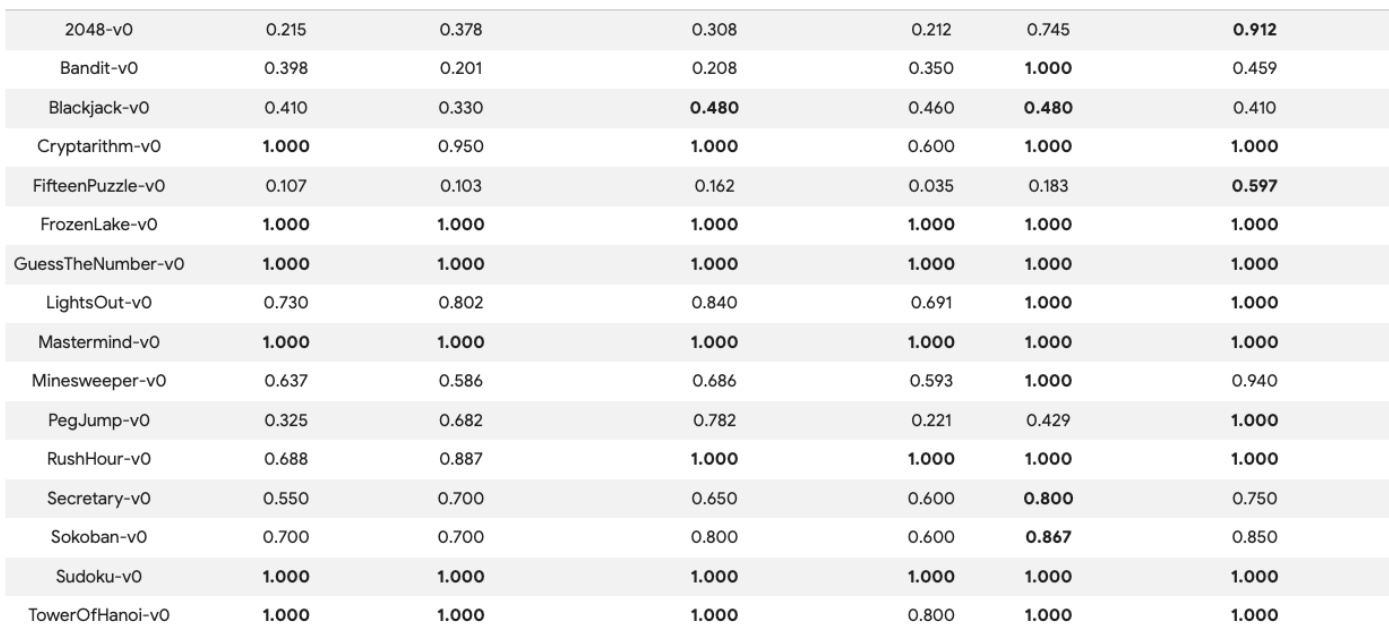
The the the table compares the average rewards achieved by different agents across various single-player games. The results show that the Harness-as-Policy approach generally achieves higher rewards than the other tested agents, including Gemini and GPT models. Harness-as-Policy achieves the highest or near-highest reward in most listed games. The Harness-as-Policy method outperforms both Gemini-2.5-Pro and GPT-5.2-High in several environments. The agents show varying levels of performance depending on the specific game complexity.
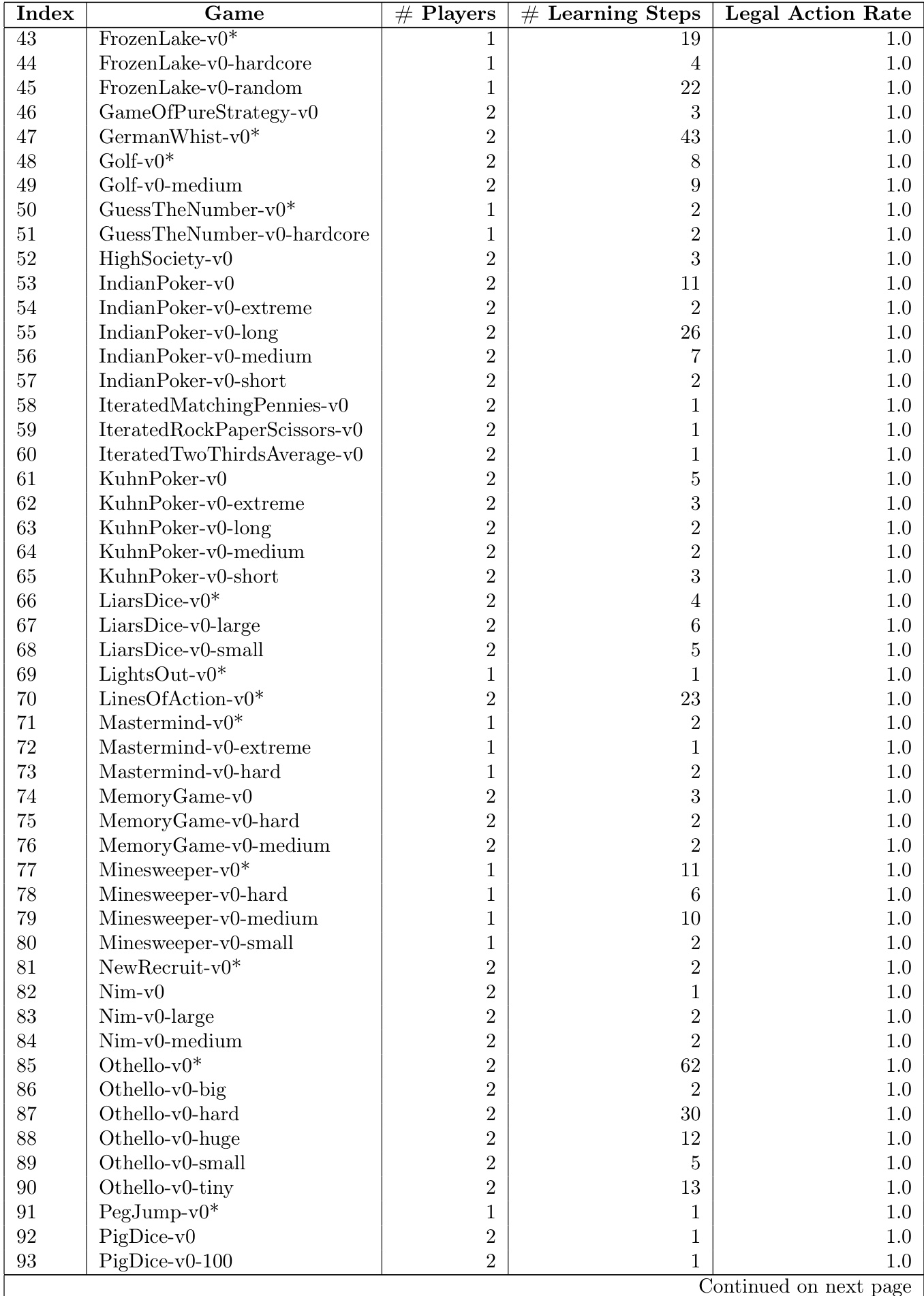
The authors present a list of games used in the TextArena benchmark, detailing the number of players, the required learning steps, and the legal action success rate for each. The data shows that the training process successfully achieves a perfect legal action success rate across all listed games. The training process consistently reaches a full legal action success rate for every game in the dataset. The number of learning steps required to achieve the success rate varies significantly depending on the specific game. The games include a diverse range of player configurations, primarily consisting of single-player and two-player environments.
The authors evaluate various agent configurations and harness methods across a diverse set of single-player and two-player games to validate action legality and reward performance. The results demonstrate that the proposed harness approach consistently achieves high or perfect legal action success rates, often outperforming standard large language models. Furthermore, the Harness-as-Policy method generally secures higher rewards across most environments, proving highly effective despite varying levels of game complexity.