Command Palette
Search for a command to run...
VideoDetective: 장편 영상 이해를 위한 외재적 쿼리와 내재적 관련성을 통한 단서 탐지
VideoDetective: 장편 영상 이해를 위한 외재적 쿼리와 내재적 관련성을 통한 단서 탐지
Ruoliu Yang Chu Wu Caifeng Shan Ran He Chaoyou Fu
초록
다중 모드 대규모 언어 모델 (MLLM) 에 있어 장편 비디오 이해는 제한된 컨텍스트 윈도우로 인해 여전히 어려운 과제로 남아 있습니다. 이로 인해 희소한 쿼리 관련 비디오 세그먼트를 식별해야 하는 요구가 발생합니다. 그러나 기존 방법들은 주로 쿼리만을 기반으로 단서를 국지화하는 데 그쳐, 비디오의 고유한 구조와 세그먼트 간 가변적인 관련성을 간과하고 있습니다. 이를 해결하기 위해 본 논문은 장편 비디오 질문 응답 (long-video question answering) 에서 효과적인 단서 탐색을 위해 쿼리 - 세그먼트 관련성과 세그먼트 간 친화도를 통합한 VideoDetective 라는 프레임워크를 제안합니다. 구체적으로, 우리는 비디오를 다양한 세그먼트로 분할하고, 시각적 유사성과 시간적 근접성에 기반하여 구축된 시각 - 시간 친화도 그래프 (visual-temporal affinity graph) 로 각 세그먼트를 표현합니다. 이어 가설 - 검증 - 정제 (Hypothesis-Verification-Refinement) 루프를 수행하여 관측된 세그먼트의 쿼리에 대한 관련성 점수를 추정하고, 이를 관측되지 않은 세그먼트로 전파함으로써 최종 답변을 위한 가장 중요한 세그먼트의 국지화를 안내하는 전역 관련성 분포를 생성합니다. 실험 결과, 제안된 방법은 대표적인 벤치마크에서 다양한 주류 MLLM 에 걸쳐 일관되게 상당한 성능 향상을 보였으며, VideoMME-long 기준에서 최대 7.5% 의 정확도 개선을 달성했습니다. 본 연구의 소스코드는 https://videodetective.github.io/ 에서 확인 가능합니다.
One-sentence Summary
Researchers from Nanjing University and the Chinese Academy of Sciences propose VideoDetective, a framework that enhances long video understanding by constructing visual-temporal affinity graphs and employing a Hypothesis-Verification-Refinement loop to localize sparse query-relevant segments, achieving significant accuracy gains on benchmarks like VideoMME-long.
Key Contributions
- The paper introduces VideoDetective, a long-video inference framework that models videos as a Spatio-Temporal Affinity Graph to integrate extrinsic query relevance with intrinsic visual and temporal correlations for effective clue localization.
- This work implements a Hypothesis-Verification-Refinement loop that utilizes graph diffusion to propagate sparse relevance scores from observed anchor segments, dynamically updating a global belief field to recover semantic information from limited observations.
- Experimental results demonstrate that the method acts as a plug-and-play solution that consistently improves performance across diverse MLLM backbones, achieving accuracy gains of up to 7.5% on the VideoMME-long benchmark.
Introduction
Long video understanding is critical for deploying Multimodal Large Language Models (MLLMs) on real-world content, yet these systems struggle with limited context windows that force them to identify sparse, query-relevant segments. Prior approaches rely on unidirectional query-to-video matching or simple sampling, which often overlook the video's intrinsic temporal structure and causal continuity, leading to missed clues and poor reasoning. To address this, the authors propose VideoDetective, a framework that models videos as Spatio-Temporal Affinity Graphs to jointly leverage extrinsic query relevance and intrinsic inter-segment correlations. By executing a Hypothesis-Verification-Refinement loop with graph diffusion, the method propagates relevance scores from observed segments to unseen ones, enabling accurate clue localization and significant accuracy gains across diverse MLLM backbones.
Dataset
- The authors estimate lower bounds for token consumption using official sampling rates, per-frame token counts from API documentation, and standard video resolution settings.
- This analysis serves as a baseline for models including Gemini-1.5-Pro, GPT-4o, and LLaVA-Video-72B rather than describing a specific training dataset composition.
- No training splits, mixture ratios, or filtering rules are defined in this section as the focus is on theoretical efficiency metrics.
- The text does not detail cropping strategies or metadata construction but relies on standard resolution configurations to calculate token usage.
Method
The authors propose VideoDetective, an inference framework that formulates long-video question answering as an iterative relevance state estimation problem on a visual-temporal affinity graph. The core objective is to efficiently combine extrinsic query relevance with intrinsic video correlations to localize query-related segments. The overall architecture consists of three main stages: Graph Construction, a Hypothesis-Verification-Refinement Iteration loop, and final Inference.
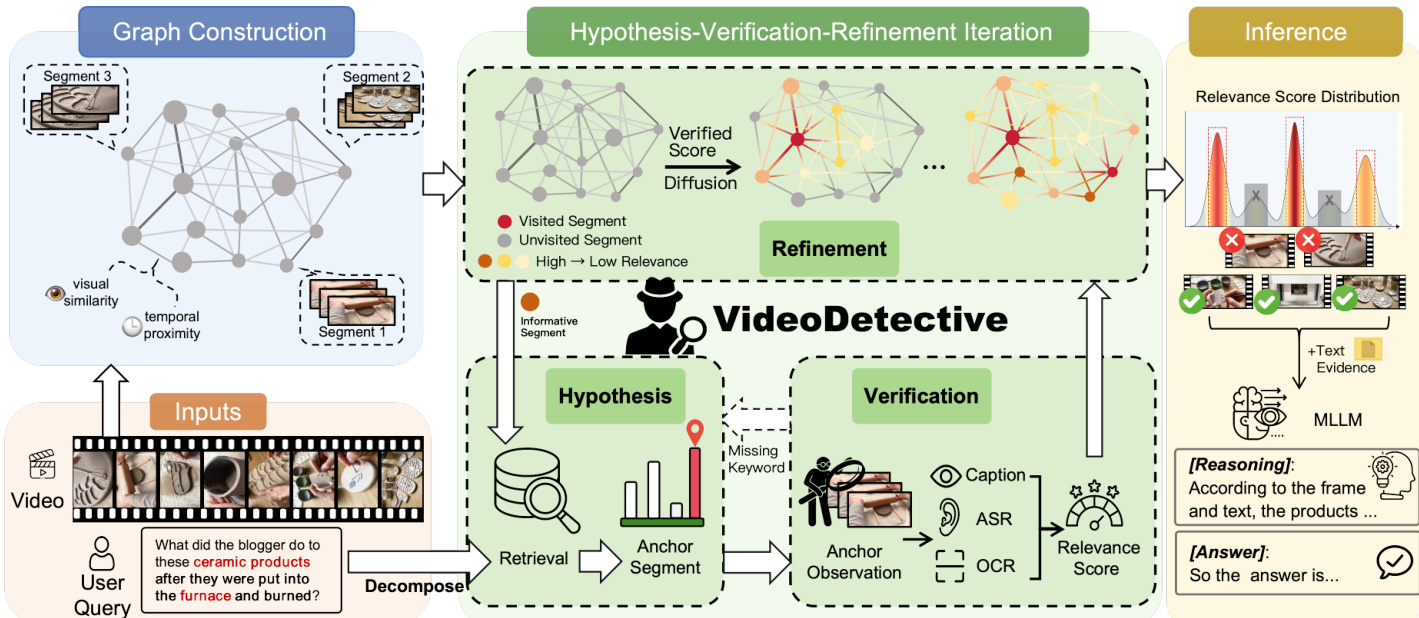
To model the continuous global belief field from sparse segment observations, the method first constructs a Visual-Temporal Affinity Graph. The video is divided into semantic segments based on visual similarity, where each segment serves as a node. The edges are defined by an affinity matrix that fuses visual similarity (cosine similarity of frame features) and temporal proximity (exponentially decaying kernel). This graph structure captures intrinsic associations, defining how relevance scores should propagate from observed anchor segments to unvisited ones.
The core of the framework is the Hypothesis-Verification-Refinement loop, which iteratively updates the relevance state. The system maintains two state vectors: an Injection Vector Y(t) representing sparse verified relevance scores, and a Belief Field F(t) representing the dense global relevance distribution inferred via graph diffusion.
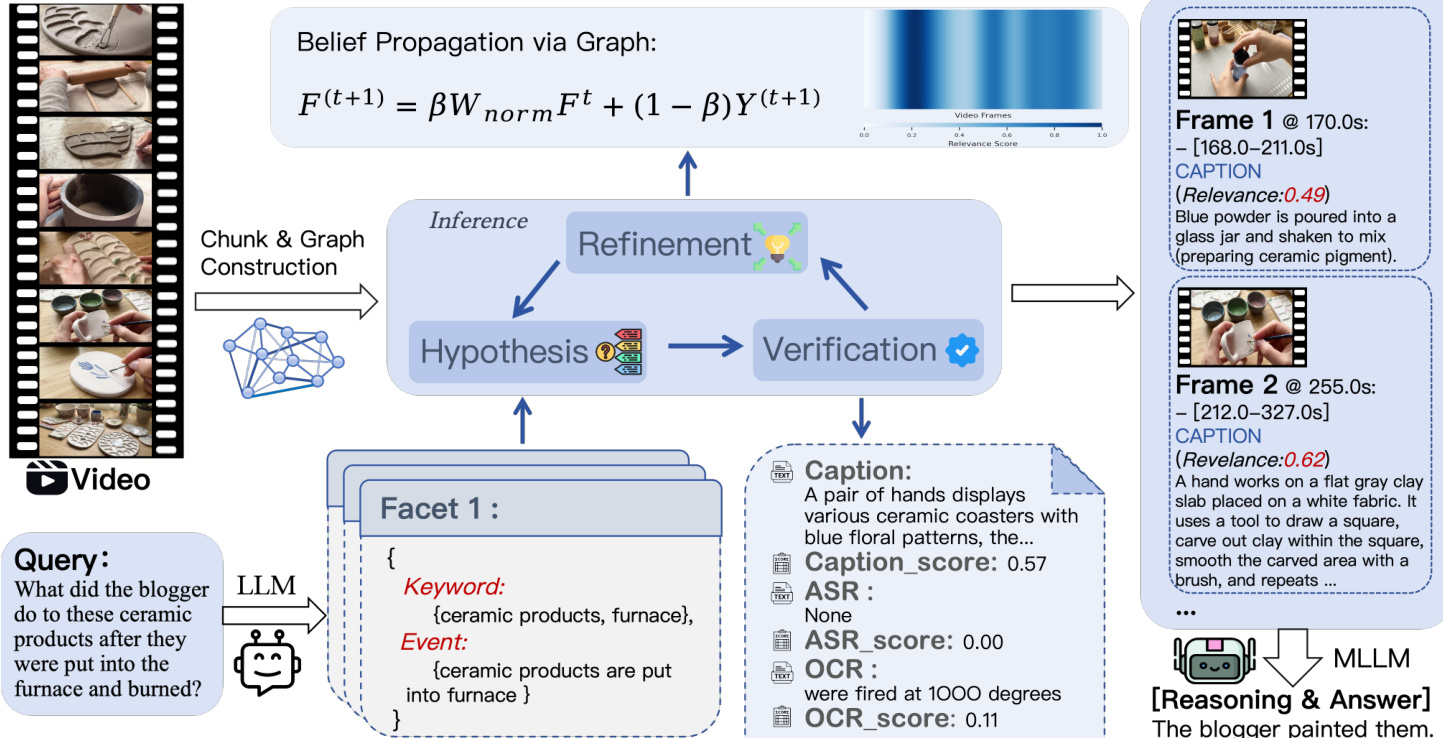
In the Hypothesis phase, the user query is decomposed into semantic facets containing keywords and event descriptions. The system selects an anchor segment to verify. Initially, it uses Facet-Guided Initialization to find the best match. During iterations, it employs Informative Neighbor Exploration to select unvisited neighbors if evidence is missing, or Global Gap Filling to explore high-belief unvisited nodes if all facets are resolved.
Next, the Verification phase observes the selected anchor segment. The system extracts multi-source evidence including visual captions, on-screen text via OCR, and speech transcripts via ASR. A source-aware scoring mechanism computes the relevance score by combining lexical similarity (for precise text matching) and semantic similarity (for event understanding). This score is injected into the state vector Y(t).
Finally, the Refinement phase propagates the observed relevance scores across the graph to update the global belief field. This is achieved through iterative belief propagation, governed by the equation:
F(t+1)=βWnormFt+(1−β)Y(t+1)where Wnorm is the symmetric normalized affinity matrix and β balances smoothness and consistency. This process allows relevance signals to diffuse from sparse observations to the entire video structure.
Upon completion of the iterations, the converged global belief field serves as the final relevance distribution. The system applies Graph-NMS to select a diverse set of high-confidence segments, ensuring coverage of all query facets. These selected segments, along with their multimodal evidence, are packaged and fed into a downstream MLLM to generate the final answer.
Experiment
- Experiments on four long-video benchmarks validate that VideoDetective consistently outperforms proprietary and open-source baselines across various model scales, establishing new state-of-the-art results.
- Generalization tests confirm the framework acts as a plug-and-play solution that significantly boosts performance for diverse backbones without task-specific tuning.
- Ablation studies demonstrate that graph manifold propagation, semantic facet decomposition, and iterative hypothesis-verification loops are all essential components for reducing noise and correcting retrieval biases.
- Modality scaling analysis reveals that visual perception capabilities are the primary performance bottleneck, while the language model component requires only lightweight resources for effective query decomposition.
- Efficiency evaluations show that VideoDetective achieves superior accuracy with moderate token consumption, offering a better cost-effectiveness balance than both larger proprietary models and other method baselines.