Command Palette
Search for a command to run...
OmniDirector: クロスペアデータを用いない汎用的な複数ショットカメラクローニング
OmniDirector: クロスペアデータを用いない汎用的な複数ショットカメラクローニング
概要
参照動画からカメラモーションをクローニングすることは、動画が直感的かつ精密な制御を提供できるため、動画生成において重要な課題である。既存手法は、マルチショット生成に対応できないパラメトリック表現を直接使用するか、データ不足に起因する問題を抱えるクロスペアデータを合成するかのいずれかであり、複雑なカメラモーションのクローニングにおいて性能が低下するという課題を抱えている。これらの課題に対処するため、カメラをグリッドモーション動画としてエンコードする汎用的なカメラモーション表現を提案する。本カメラグリッドはカメラパラメータを視覚的に表現し、マルチショット動画生成における多様な軌道の統合をサポートする。これに基づき、百万規模のカメラグリッド-動画ペアで学習された統一フレームワークOmniDirectorを提案する。本フレームワークはキャラクター、アクション、カメラを協調制御し、マルチモーダル拡散トランスフォーマーに対してディレクターレベルの制御を実現する。さらに、信号間の関係を理解することでカメラモーションと視覚コンテンツを体系的に記述し、異なる制御信号を調和的に統合する新規の階層型プロンプト拡張agentを設計する。広範な実験により、本フレームワークの優れた性能と顕著な制御性が実証された。プロジェクトページ: https://ymlinfeng.github.io/OmniDirector.github.io/
One-sentence Summary
OmniDirector achieves general multi-shot camera cloning without cross-paired data by encoding camera parameters as grid motion videos, training on million-scale camera grid-video pairs, and utilizing a hierarchical prompt expansion agent to harmonize control signals for director-level coordination of characters, actions, and cameras within multimodal diffusion transformers, with extensive experiments demonstrating its superior performance and controllability.
Key Contributions
- The paper introduces a camera grid representation that encodes camera parameters as visual grid videos, replacing explicit trajectory specifications with an intuitive visual format that natively supports multi-shot generation.
- Building on this representation, the paper presents OmniDirector, a unified framework trained on million-scale camera grid-video pairs that coordinates characters, actions, and camera dynamics to provide director-level control for multimodal diffusion transformers.
- The framework incorporates a hierarchical prompt expansion agent that systematically aligns camera motion and visual content by analyzing signal relationships, with extensive experiments demonstrating superior performance and controllability in complex camera motion cloning tasks.
Introduction
Precise camera motion control is essential for high-quality video generation, yet existing approaches struggle to balance user accessibility with cinematic complexity. Current methods either rely on explicit mathematical parameters that fail to handle multi-shot transitions or depend on scarce cross-paired video data that introduces information leakage and struggles with intricate scene changes. The authors leverage a novel camera grid representation that visualizes camera trajectories as motion within an empty 3D scene, effectively decoupling cinematic movement from visual content. Building on this, they introduce OmniDirector, a unified framework trained on a million-scale dataset that enables general multi-shot camera cloning without cross-paired data. The system integrates a hierarchical prompt expansion agent to seamlessly coordinate camera dynamics with character actions and visual elements within multimodal diffusion transformers, delivering director-level control for complex video generation.

Method
The authors introduce OmniDirector, a framework designed for general multi-shot camera cloning that disentangles camera motion from scene content through a novel representation and a unified diffusion architecture. The core of the method relies on a camera grid that visualizes spatial transformations in an empty environment. The authors abstract the complex real world into a simplified room structure containing only 3D grid lines to indicate coordinate axes and motion trajectories.
As shown in the figure below:

This visualization facilitates the simulation of spatial relationships by generating grid points on floor and ceiling planes within the scene bounding box. The heights of these planes are defined relative to the average scene height y with an offset Δh:
yfloor=y−Δh yceiling=y+Δh
Orthogonal grid lines render a spatial framework, while vertical line segments within an annular region create a tunnel wall effect to enhance depth perception. The annular region is defined as W={(x,z)∣r<dtraj(x,z)<r+δ}, where dtraj represents the distance from grid points to the projected camera trajectory. Rendering views under varying poses transforms world coordinates to camera coordinates via Pc=RiPw+ti.
The representation extends to special camera effects by modifying the rendering scheme.

For fisheye distortion, the authors apply the Kannala-Brandt model, computing the distorted angle θd=θ(1+k1θ2+k2θ4+k3θ6+k4θ8). Dolly zoom effects are simulated by maintaining subject size proportionality φ∝ρ and utilizing a picture-in-picture tracking view to reproduce perspective stretching. Multi-shot sequences are handled by detecting transitions and rendering each sub-clip as a single shot to ensure scene consistency.
The overall architecture and workflow are detailed in the framework diagram.

The top portion illustrates the camera grid generation from a reference video. During training, the middle section shows how the camera grid is injected into the Multi-modal Diffusion Transformer (MMDiT) via token concatenation. The bottom section depicts the inference process involving a hierarchical prompt expansion agent.
In the architecture, the camera grid G and reference image I are encoded into latents zc and zI using a 3D-VAE. These are concatenated with the video noisy latent Zv along the frame dimension to form zvis=Concat(zI,zv,zc). This representation is patchified into tokens Zvis and processed through 3D convolutions. Text conditions are encoded separately and fused via joint attention within the MMDiT blocks. The update rule is Zvis(l+1)=FFN(Attention(LN(Zvis(l)),Zt(l)))+Zvis(l).
To strengthen geometric understanding, the authors incorporate a self-reconstruction objective where 30% of training samples require the model to reconstruct the camera grid itself, preventing overfitting to spurious correlations in the mapping.
At inference, a hierarchical prompt expansion agent harmonizes control signals. The agent generates camera prompts by analyzing inter-shot transitions and intra-shot pose changes. Pose increments ΔP=[ΔR∣Δt] are analyzed to determine motion axes and speeds. Arc shots are identified via specific rules, such as Δθyaw>0 and Δx<0 for left arcs. A multimodal large language model refines these descriptions and fuses them with the reference image and user prompt. An adaptive classifier-free guidance strategy employs a black background for the visual unconditional branch and a coarse-to-fine denoising schedule to prioritize global structure before local details.
Experiment
OmniDirector is evaluated on a diverse set of over a thousand curated video samples to assess its camera control, shot transition accuracy, and visual fidelity against existing methods. Ablation studies confirm that the model relies on a multi-stage prompt engineering strategy, where multimodal signal fusion minimizes reference leakage, inter-shot guidance preserves semantic continuity across cuts, and adaptive classifier-free guidance ensures responsive camera motion. Qualitatively, the system consistently clones complex camera trajectories and transition semantics with high plausibility, while also demonstrating robust zero-shot generalization to alternative visual inputs without retraining. Overall, the experiments validate that OmniDirector achieves superior performance and harmonious camera cloning across diverse cinematic and commercial domains.
The the the table compares the proposed method against Seedance2.0, CamCloneMaster, and LTX-LoRA across camera accuracy, transition accuracy, and leakage rate. The results indicate that the proposed method achieves superior performance across all metrics, demonstrating the lowest error rates and highest precision scores while maintaining the lowest leakage rates. The proposed method demonstrates superior camera accuracy with the lowest relative rotation and translation errors. It achieves significantly higher transition accuracy, particularly in semantic consistency, compared to other methods. The method exhibits the lowest leakage rate at both frame and shot levels, indicating better content fidelity.

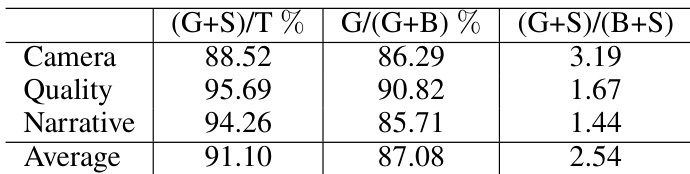
The the the table presents a GSB (Good/Same/Bad) pairwise comparison evaluating the proposed method against a baseline across camera control, visual quality, and narrative consistency. The results indicate a high rate of positive or neutral outcomes relative to the total samples, demonstrating the effectiveness of the proposed approach in generating video content. Visual quality receives the highest approval, demonstrating superior performance compared to the baseline. Camera control exhibits a strong relative advantage, with a high ratio of positive outcomes. Narrative consistency is effectively maintained, achieving high rates of favorable comparisons.
The ablation study demonstrates that the full model, incorporating semantic fusion, inter-shot prompts, and adaptive CFG, achieves superior performance across all metrics compared to ablated variants. Removing any of these components results in decreased camera accuracy, lower transition accuracy, or increased leakage rates. Specifically, semantic fusion is critical for minimizing leakage, while inter-shot prompts are essential for maintaining high semantic precision in transitions. The full model achieves the best camera accuracy and lowest leakage rate. Removing semantic fusion leads to higher leakage rates and degraded overall performance. Omitting inter-shot prompts causes a significant drop in semantic transition precision.

The evaluation compares the proposed method against existing video generation models through quantitative benchmarks, pairwise quality assessments, and ablation studies. Benchmark comparisons demonstrate superior camera control, smoother semantic transitions, and higher content fidelity relative to alternative approaches. Pairwise evaluations further confirm strong visual quality and narrative consistency across generated sequences. Finally, the ablation study validates that the integration of semantic fusion, inter-shot prompts, and adaptive classifier-free guidance is essential for maintaining these performance gains.