Command Palette
Search for a command to run...
MemDreamer:階層グラフメモリとエージェント検索機構による長尺動画理解のための知覚と推論の分離
MemDreamer:階層グラフメモリとエージェント検索機構による長尺動画理解のための知覚と推論の分離
Cong Chen Guo Gan Kaixiang Ji ChaoYang Zhang Zhen Yang Guangming Yao Hao Chen Jingdong Chen Yi Yuan Chunhua Shen
概要
現在のビジョン・ランゲージモデルは、長時間の動画の処理において困難をきたしている。これは、フル長の視覚シーケンスを処理すると、許容できないほどのtokenの爆発的増加とアテンションの分散を引き起こすためである。この課題を克服するため、我々は知覚と推論を分離するMemDreamerを導入し、長時間動画の理解をagentによる探索プロセスへと転換する。本手法はプラグアンドプレイのフレームワークとして、動画を逐次ストリーミングし、階層グラフメモリを構築する。これは時空間および因果関係を捉える基盤グラフを土台とし、意味抽象化のためのトップダウン型3層アーキテクチャである。推論時、推論モデルはagentによるツール拡張検索を採用し、Observation-Reason-Actionループを通じて階層の移動、ノードの検索、論理エッジの走査を行う。実験により、MemDreamerは4つの主要ベンチマークでSOTAの結果を達成し、人間専門家との差をわずか3.7ポイントにまで縮小することが示された。本手法は、フルコンテキストの取り込み量のわずか2%に推論用コンテキストウィンドウを制限しながらも、12.5ポイントの絶対的な精度向上を実現している。さらに、統計分析により、VLMの論理推論および長時間動画理解ベンチマークにおけるパフォーマンス間に強い正の線形相関があることが明らかになり、agent能力のスケーリングが多モーダル理解における新たなパラダイムであることが確立された。
One-sentence Summary
MEMDREAMER decouples perception and reasoning for long video understanding by incrementally constructing a hierarchical graph memory and employing an agentic tool-augmented retrieval mechanism that constrains the reasoning context to 2% of full-context ingestion while delivering a 12.5-point absolute accuracy gain and state-of-the-art results across four benchmarks, thereby establishing agentic capability scaling as a new paradigm for multimodal comprehension.
Key Contributions
- This paper introduces MEMDREAMER, a framework that decouples perception and reasoning to mitigate token explosion in long-video processing via a Hierarchical Graph Memory. The three-tier architecture progressively abstracts video semantics into a foundational graph that preserves long-range spatiotemporal and causal dependencies while suppressing irrelevant details.
- The approach replaces passive context ingestion with a tool-augmented Agentic Retrieval Mechanism that operates through an iterative Observation-Reason-Action loop. By leveraging dedicated navigation, search, and traversal tools, the reasoning model actively explores the memory hierarchy to locate logically relevant information.
- Experiments demonstrate state-of-the-art performance across four mainstream long-video benchmarks, narrowing the human expert gap to 3.7 points. The framework constrains the reasoning context window to 2% of full-length video data while delivering a 12.5 point absolute accuracy gain and establishing agentic capability scaling as a new paradigm for multimodal comprehension.
Introduction
The authors tackle long video understanding, a foundational capability required to scale Vision-Language Models toward embodied intelligence and complex real-world interaction. Existing methods typically couple visual perception and logical reasoning within a single context window, which triggers severe token explosion, attention dilution, and the "lost in the middle" phenomenon when processing hours-long footage. Even decoupled systems that store video data in flat or chunk-based memory banks struggle to preserve global context and temporal-causal relationships, often degrading retrieval into inefficient trial and error. To overcome these bottlenecks, the authors introduce MEMDREAMER, a framework that separates perception from reasoning by streaming video content into a three-tier Hierarchical Graph Memory. They then leverage a tool-augmented agentic retrieval mechanism that actively navigates this topological structure through an iterative observation-reason-action loop, enabling precise multi-step information extraction while consuming only a fraction of the standard context window.
Dataset

-
Dataset Composition and Sources: The authors organize raw video content into a structured, multi-granular graph memory. The hierarchy spans a root level that synthesizes the full video, mid-level Super Events that group related segments, and fine-grained Macro Events that capture specific actions or moments.
-
Subset Details and Clustering Rules: Super Events are formed by clustering adjacent Macro Events based on temporal continuity, shared scene or topic, and a common overarching goal. Boundaries are triggered whenever any of these conditions break. The clustering leverages signals like overlapping key entities, event type continuity, and OCR text cues such as scoreboard increments. Each Super Event typically contains three to eight Macro Events, though isolated singletons are permitted for self-contained segments.
-
Model Usage and Processing Pipeline: The authors deploy this graph as a proactive retrieval space for an agentic reasoning model rather than a conventional training corpus. The system operates within an Observation-Reason-Action loop, where the model sequentially queries the graph using a three-part tool bank for hierarchical navigation, precise semantic search, and local graph traversal. To prevent context dilution, the pipeline distills raw tool outputs into task-relevant evidence cues before appending them to the agent working memory.
-
Metadata Construction and Formatting: The authors enforce strict formatting guidelines to maintain consistency across the graph. Super Event labels are kept under ten words and include the central entity when applicable, while descriptions span one hundred to two hundred words. Key entities are deduplicated within each Super Event and canonicalized globally to collapse name variants into single identifiers. The root level metadata includes a concise title, a multi-sentence summary of all Super Events, three to five thematic tags, five to ten canonical entities, and two to three emotional tone descriptors.
Method
MEMDREAMER formulates long-video understanding as a decoupled process comprising two distinct stages: persistent memory construction and tool-augmented agentic retrieval. The framework begins by processing a video stream V through a perception model P, which operates in a streaming fashion to construct a structured, purely textual Hierarchical Graph Memory, denoted as G. This memory is a three-tiered, coarse-to-fine semantic topology designed to abstract and organize video content efficiently. The architecture is composed of a Video Root at the apex, representing the overall narrative, followed by a layer of Super Events that encapsulate broader narrative arcs, and a foundational layer of Macro Events that serve as the primary semantic anchors. Beneath each Macro Event, a local subgraph is constructed to capture fine-grained details.
The memory construction process unfolds in three phases. First, a streaming adaptive segmentation mechanism is employed to partition the video into semantically self-contained Macro Events. This approach avoids the arbitrary truncation common in fixed-length chunking by using semantic boundaries, ensuring each segment is coherent and maintaining the maximum input length to the perception model within a defined horizon τ. This adaptive partitioning yields a sequence of Macro Events that form the leaf nodes of the hierarchy.
Second, for each segmented Macro Event, a downward subgraph extraction process constructs a local spatiotemporal subgraph gi=(Vi,Ei). This subgraph is built using a novel Video-centric Graph Ontology where vertices consist of both standard entities (ViE) and micro-events (ViM). These vertices are interconnected via a heterogeneous edge set Ei that includes spatial-attribute edges for layout and physical properties, subject-object edges for action role binding, and directed temporal-causal edges to model the chronological and causal flow of micro-events. This design allows the model to capture the dynamic evolution and causal chains within an event, which is a limitation of simpler triplet-based graph representations.
Finally, an upward hierarchical aggregation process distills the detailed information from the Macro Event layer into a global navigation backbone. The textual descriptions of all Macro Events are fed into the perception model P, which clusters and aggregates them based on temporal adjacency and semantic affinity. This bottom-up process forms Super Events and ultimately converges at a single Video Root node, creating a coarse-to-fine hierarchy that enables efficient global navigation and precise localization for retrieval.
Upon receiving a text query Q, a reasoning model R equipped with a tool bank T actively explores the pre-constructed hierarchical graph memory. The model operates exclusively on this textual memory, never accessing raw video data. The exploration is guided by an Observation-Reason-Action loop, where the reasoning model first observes the current state, reasons about the next necessary step, and then executes an action by calling one of the available tools. The toolkit is organized into three categories: navigation tools for traversing the hierarchy (e.g., getting summaries, listing events), search tools for finding specific nodes (e.g., semantic search, time-based search), and graph traversal tools for exploring local neighborhoods (e.g., retrieving relations between nodes). This agentic retrieval mechanism allows the model to iteratively refine its search, drill down into relevant subgraphs, and synthesize a concise set of task-relevant clues C to produce the final answer A=R(Q,C).
Experiment
Evaluated across four diverse long-video benchmarks against vanilla vision-language models and memory-based baselines, the main experiments validate the broad superiority and plug-and-play compatibility of a decoupled architectural paradigm. Context reduction analyses further verify that segregating perception from reasoning effectively mitigates attention dilution and token redundancy compared to direct end-to-end ingestion. Finally, qualitative case studies confirm that explicit textual graph navigation successfully captures complex multi-step causal relationships that raw visual processing typically misses, establishing structured agentic reasoning as a robust alternative to brute-force context scaling.
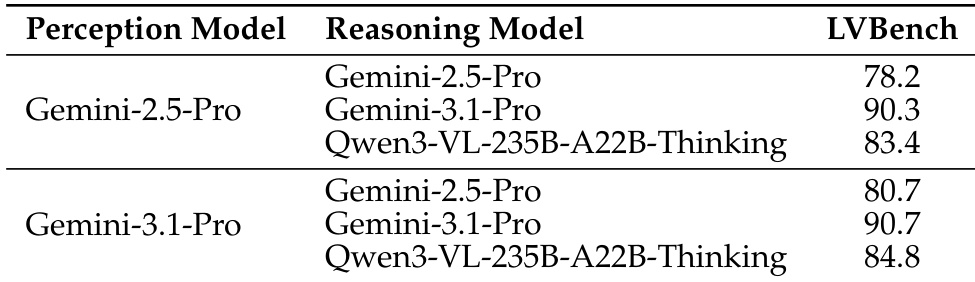
The authors compare different reasoning models using various perception models on the LVBench benchmark, showing that the choice of perception model significantly impacts performance. Results indicate that Gemini-3.1-Pro consistently outperforms Gemini-2.5-Pro across all reasoning models, and the Qwen3-VL-235B-A22B-Thinking model achieves competitive results when paired with the stronger perception model. Gemini-3.1-Pro consistently achieves higher scores than Gemini-2.5-Pro across all reasoning models on LVBench. The Qwen3-VL-235B-A22B-Thinking model performs comparably to Gemini models when used with the Gemini-3.1-Pro perception model. Performance differences between reasoning models are more pronounced when paired with Gemini-2.5-Pro than with Gemini-3.1-Pro.
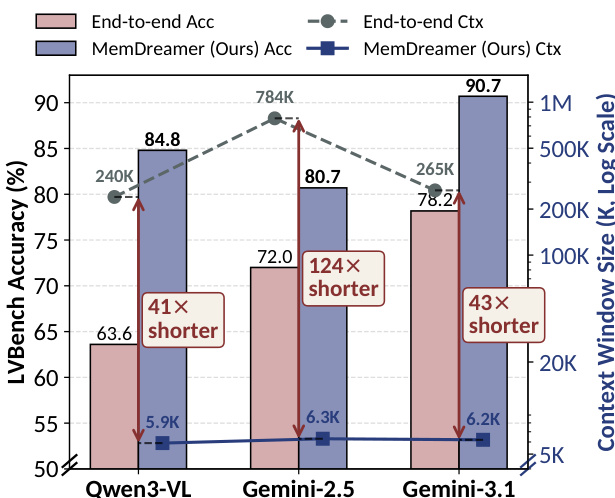
The authors compare their framework, MemDreamer, with end-to-end models across multiple benchmarks, demonstrating superior accuracy while using significantly shorter context lengths. Results show that MemDreamer achieves higher performance with much reduced input token requirements, indicating that decoupling perception from reasoning improves efficiency and effectiveness. The framework outperforms baseline models on LVBench across different reasoning engines, with notable gains in accuracy and context reduction. MemDreamer achieves higher accuracy than end-to-end models while using significantly shorter context lengths. The framework reduces context size by up to 43 times compared to full-video ingestion methods. MemDreamer maintains strong performance across different reasoning engines, showing its generality and effectiveness.
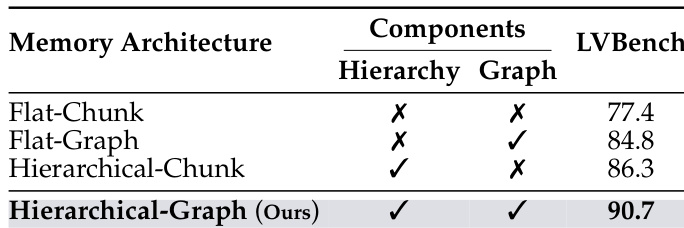
The authors evaluate their proposed MEMDREAMER framework on a long-video benchmark, comparing different memory architectures. Results show that combining hierarchical and graph-based memory components achieves the highest performance, demonstrating the effectiveness of their structured approach. The framework significantly outperforms other configurations, indicating that both memory organization and graph representation are crucial for long-video understanding. Combining hierarchical and graph memory components yields the best performance on the benchmark. The proposed framework outperforms configurations using only flat or hierarchical memory. The results validate the importance of structured memory design in long-video reasoning tasks.
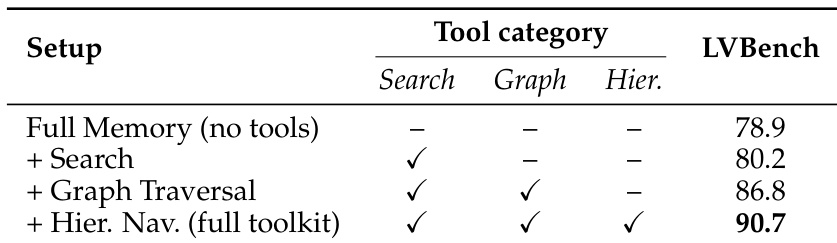
The authors evaluate a framework that enhances long-video understanding by integrating search, graph traversal, and hierarchical navigation tools into a memory-based system. Results show that adding these components sequentially improves performance on a benchmark, with the full toolkit achieving the highest score, indicating that structured, tool-augmented reasoning outperforms direct full-context processing. Adding search capabilities improves performance over a baseline with no tools. Incorporating graph traversal further boosts performance beyond search alone. The full toolkit with hierarchical navigation achieves the highest score, demonstrating the effectiveness of a multi-step, structured reasoning approach.
The authors investigate the impact of varying maximum context lengths on performance across a benchmark, observing that performance improves with increased context length up to a point before stabilizing. Results show that increasing the context length leads to higher scores and more reasoning rounds, with the highest score achieved at a context length of 12, after which performance plateaus. The number of tokens per round also increases with context length, reflecting the expanded input size. Performance improves with increasing context length up to a threshold, after which it stabilizes. The highest score is achieved at a context length of 12, indicating an optimal balance between input size and reasoning effectiveness. Higher context lengths require more tokens per reasoning round, reflecting increased computational load.

The experiments evaluate the MEMDREAMER framework on long-video understanding benchmarks, demonstrating that decoupling perception from reasoning significantly improves accuracy while drastically reducing context requirements. Comparative and ablation studies validate that pairing stronger perception models with advanced reasoning architectures yields the greatest performance gains, while integrating hierarchical and graph-based memory structures alongside sequential tool-augmented reasoning substantially outperforms flat baselines and direct context processing. Finally, context length analysis reveals an optimal threshold beyond which performance stabilizes, confirming that structured, memory-driven reasoning effectively balances computational efficiency with sustained analytical quality.