Command Palette
Search for a command to run...
Kwai Keye-VL-2.0 技術報告
Kwai Keye-VL-2.0 技術報告
概要
本研究では、長尺動画の理解とagentインテリジェンスの向上を目的として設計された、オープンソースのMixture-of-Experts (MoE) マルチモーダル基盤モデルであるKwai Keye-VL-2.0-30B-A3Bを紹介する。数時間規模の動画に内在する超長文脈、情報冗長性、および極めて高い計算コストという課題に対処するため、Keye-VL-2.0はGQAベースのマルチモーダルアーキテクチャに対してDeepSeek Sparse Attention (DSA)を適応させた初の試みであり、重要フレームと長距離時間依存性を捉えながら、損失のない256Kコンテキスト処理を可能にする。このアーキテクチャは、スケーラブルな動画I/O、異種ViT-LM並列処理、およびスループットを大幅に最大化し計算オーバーヘッドを最小化するカスタムDSAカーネルを含む、高度に最適化されたトレーニングおよび推論インフラストラクチャによって支えられている。さらに、マルチタスクアライメントにおける壊滅的忘却のアルゴリズム的ジレンマを克服するため、Context-RLおよびVideo-RLと組み合わせたCross-Modal Multi-Teacher On-Policy Distillation (MOPD)を導入する。オンポリシーロールアウトから得られた高密度なtokenレベルの教師フィードバックを、3Bパラメータのみを活性化させるMoEバックボーンへ蒸留することにより、Keye-VL-2.0はマルチモーダル自己修正機能を通じて、Code、Tool、Searchの各シナリオにおける高度なagent連携をネイティブに可能にする。動画理解、時間的グラウンディング、推論、STEM、およびagentベンチマークにわたる広範な評価により、Keye-VL-2.0-30B-A3Bが同規模のモデル群の中で最先端の性能を達成していることが示されており、特にTimeLensにおける細粒度時間的局所化、およびVideo-MME-v2とLongVideoBenchにおける長尺動画の理解において顕著な成果を上げている。スケーラブルで堅牢なマルチモーダルagentアプリケーションへのコミュニティの進展を加速するため、本モデルのチェックポイントを公開する。
One-sentence Summary
The Keye Team introduces Kwai Keye-VL-2.0-30B-A3B, an open-source Mixture-of-Experts multimodal model that adapts DeepSeek Sparse Attention to GQA-based architectures for lossless 256K context processing to efficiently handle hour-level videos and employs Cross-Modal Multi-Teacher On-Policy Distillation with Context-RL and Video-RL to mitigate catastrophic forgetting, thereby enabling advanced multimodal agent collaboration across code, tool, and search scenarios while achieving state-of-the-art performance among similarly scaled models, particularly excelling in fine-grained temporal localization on TimeLens and long-video comprehension on Video-MME-v2 and LongVideoBench.
Key Contributions
- The paper introduces Keye-VL-2.0-30B-A3B, an open-source Mixture-of-Experts multimodal foundation model that integrates DeepSeek Sparse Attention into GQA-based architectures. This architectural design enables lossless processing of 256K token contexts, effectively managing ultra-long video inputs while preserving critical frames and long-range temporal dependencies.
- To mitigate catastrophic forgetting during multi-task alignment, the work develops Cross-Modal Multi-Teacher On-Policy Distillation paired with Context-RL and Video-RL. This training framework distills dense token-level feedback into a sparse MoE backbone that activates only 3B parameters, further accelerated by custom DSA kernels and heterogeneous parallelism that maximize computational throughput.
- Extensive evaluations across video understanding, temporal grounding, reasoning, STEM, and agent benchmarks demonstrate state-of-the-art performance among similarly sized models. The system achieves particularly strong results in fine-grained temporal localization on TimeLens and long-video comprehension on Video-MME-v2 and LongVideoBench.
Introduction
The provided source text is empty, so I cannot currently extract the technical context, prior limitations, or contributions. Once you share the research body, I will translate it into a concise, technically precise summary that highlights why the application matters, identifies existing methodological gaps, and clearly explains the authors’ main contribution. This ensures the final piece remains readable, strictly avoids em dashes, and maintains an explainer-focused perspective.
Dataset

-
Dataset Composition and Sources
- The authors construct a multi-stage corpus spanning roughly 1.5 trillion tokens across pre-training, supervised fine-tuning, and reinforcement learning phases. Primary sources include large-scale open-image corpora like LAION, DataComp, COYO, and CC12M, supplemented by proprietary Kuaishou e-commerce data, real-world screenshots, and algorithmically generated synthetic datasets.
-
Subset Details and Filtering Rules
- The authors refine image and video captions using an 8B expert model to regenerate high-quality descriptions or correct grammatical errors while preserving original semantics.
- The authors combine real-world OCR captures with XML-structured synthetic samples, applying blur, lighting shifts, wrinkles, and geometric distortions to improve field extraction and chart reading robustness.
- The authors filter math and STEM examples through LLM-based verification to remove low-quality samples and focus on geometry, formulas, and scientific diagrams.
- The authors synthesize grounding and counting data by pasting COCO and OpenImages objects onto backgrounds with controllable positions, then verifying them with an MLLM to ensure precise bounding box and count annotations.
- The authors pair GUI screen captures with control metadata and interaction semantics to support element localization, navigation, and state-change understanding.
- The authors generate synthetic chain-of-thought traces using a strong teacher model, then filter them through query, response, and process-level quality checks, followed by a secondary Doubt2Clean review for mathematical tasks.
- The authors reserve approximately 40 percent of the fine-tuning mix for pure-text corpora, drawing from math, code repositories, Hermes-style tool-use trajectories, and search/RAG examples to prevent language degradation.
-
Training Usage and Mixture Ratios
- The authors train all parameters in stage one on roughly one trillion tokens with a 32K sequence limit, blending image captions, interleaved image-text, interleaved video, pure-text QA, and OCR to establish cross-modal alignment.
- The authors shift to supervised fine-tuning in stage two on about 500B tokens, balancing modality coverage while keeping text-heavy samples to anchor instruction following and reasoning.
- The authors extend the context window to 256K in stage three by mixing long-context and short-context samples at a one-to-one ratio, targeting ultra-long documents, multi-image conversations, and extended agent trajectories.
- The authors freeze the visual encoder and projector during video reinforcement learning, training on approximately 31K samples with GSPO to optimize temporal grounding, dense captioning, and frame-level verification.
-
Cropping Strategy, Metadata, and Processing Pipeline
- The authors segment videos into 15-second clips for stage one training, while longer sequences use scene-wise dense captions annotated with timestamps and global overviews.
- The authors implement a unified cleaning pipeline that removes low-quality text, invalid formats, unsafe content, and unreliable cross-modal pairs.
- The authors apply a joint hashing and CLIP similarity strategy to deduplicate both exact and semantically similar samples across modalities.
- The authors enforce structured interval outputs formatted as coordinate pairs for temporal grounding tasks to force explicit evidence localization rather than global summarization.
- The authors deploy a dual-queue asynchronous architecture that decouples CPU preprocessing from GPU inference, enabling caption generation, translation, and quality evaluation at three to five times standard throughput.
Method
The model architecture of Keye-VL-2.0-30B-A3B is built upon a standard multimodal large language model (MLLM) framework, comprising four core components: a vision encoder (ViT), a language decoder (LLM), an MLP projector, and a sparse attention module. This backbone is augmented with three key architectural innovations to enable native-resolution processing, unified visual encoding, and long-context multimodal modeling via DeepSeek Sparse Attention (DSA). The vision encoder, inherited from Keye-VL-1.5, is a native-resolution Vision Transformer (ViT) that processes images and video frames at their original resolutions, preserving critical details such as text and layout. To support variable input sizes, it employs adaptive position encoding and 2D Rotary Position Embedding (2D RoPE), which are combined with the Patch n' Pack mechanism and FlashAttention to enable efficient sequence packing without padding. The visual encoder is pre-trained on a diverse corpus of 500B tokens to align with the downstream MLLM's data distribution.
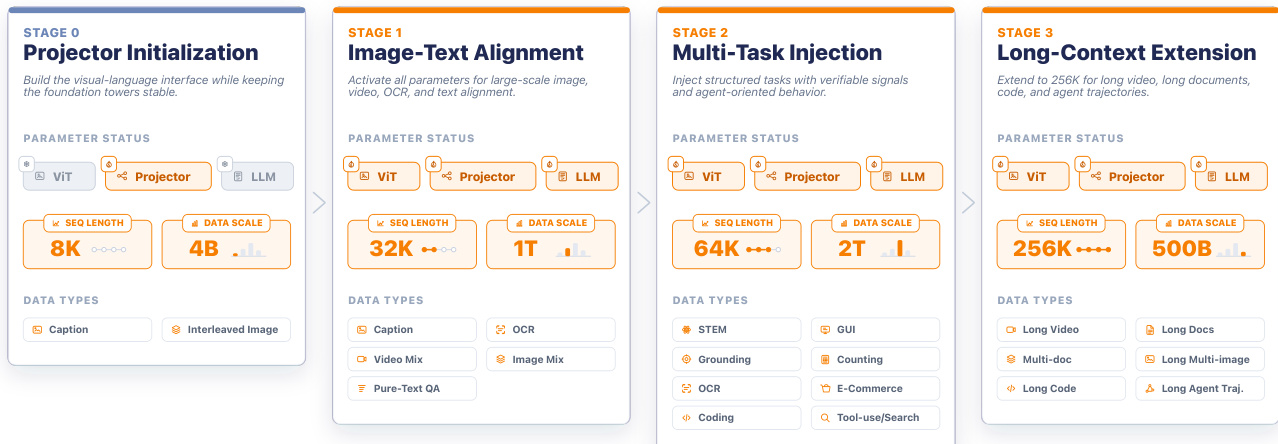
The language decoder is based on the Qwen3-30B-A3B-Thinking-2507 model, providing strong general knowledge and instruction-following capabilities. The MLP projector, randomly initialized, is trained in Stage 0 to align the visual features from the ViT with the LLM's representation space. The core innovation for handling long-context multimodal inputs is the integration of DSA into the decoder's attention pathway. This is achieved through a GQA-compatible DSA design that combines global MQA-based indexing with grouped GQA aggregation. The Lightning Indexer computes a global score It,s between a query token ht and each preceding token hs using a shared key, and selects the top-k tokens to form a sparse index set Ωt. This index set is then applied to all query groups in the GQA backbone, resulting in a sparse attention output νt,g for each group, which is concatenated to form the final attention representation. This design reduces the core attention complexity from O(L2) to O(Lk), enabling efficient long-range spatiotemporal and semantic aggregation. The DSA module is trained in a two-stage process: a dense warm-up phase initializes the indexer to align with the dense attention distribution, followed by a sparse adaptation phase that teaches the model to rely on dynamically selected evidence while minimizing gradient interference.
Experiment
Evaluated across comprehensive video understanding, code agent, agentic tool-use, and general vision-language benchmarks against leading baselines, the experiments validate the model’s long-context comprehension, algorithmic reasoning, multi-turn function calling, and perceptual reliability. Qualitative assessments and representative case studies demonstrate that the architecture effectively synthesizes dense visual context for fine-grained temporal grounding while maintaining robust hallucination resistance in complex reasoning tasks. Ultimately, the model exhibits strong cross-modal proficiency, particularly excelling in long-video analysis, visual mathematics, and the orchestration of multi-domain agentic workflows with reliable state tracking and automated error recovery.
The authors evaluate Keye-VL-2.0-30B-A3B across multiple domains, including video understanding, coding, tool use, and general vision-language tasks. The model achieves top performance on several benchmarks, particularly in long-video comprehension and temporal grounding, while showing competitive results on others. It demonstrates strong capabilities in reasoning, tool interaction, and multi-turn service orchestration. Keye-VL-2.0 achieves the best results on long-video understanding benchmarks and excels in temporal grounding across different frame densities. The model performs competitively on video knowledge acquisition and general vision-language tasks, showing strength in reasoning and hallucination resistance. Keye-VL-2.0 demonstrates robust tool-use and multi-turn interaction capabilities, successfully coordinating complex service scenarios across multiple domains.
The authors evaluate Keye-VL-2.0-30B-A3B on tool-use and function-calling benchmarks, comparing it against several open-source and closed-source models. Results show that Keye-VL-2.0 achieves the best performance on two benchmarks and ranks second on another, indicating strong capabilities in multi-turn tool interaction and state tracking. The model demonstrates competitive performance across a range of tool-use scenarios, particularly in complex life-service tasks and dual-control stateful interactions. Keye-VL-2.0 achieves the best results on two out of three tool-use benchmarks. The model ranks second on the BFCL-V4 benchmark, showing strong performance in single-turn function calling. Keye-VL-2.0 demonstrates competitive performance in multi-turn and complex life-service scenarios.

The authors evaluate Keye-VL-2.0-30B-A3B on coding and software engineering benchmarks, comparing its performance against several open-source and closed-source models. Results show that Keye-VL-2.0 achieves the highest scores on LiveCodeBench v6 and OJBench, and performs competitively on SWE-bench Verified, indicating strong algorithmic reasoning and execution-based self-correction capabilities. Keye-VL-2.0 achieves the best performance on LiveCodeBench v6 and OJBench among the compared models. Keye-VL-2.0 performs competitively on SWE-bench Verified, demonstrating effective transfer of coding ability to repository-level software engineering. Keye-VL-2.0 outperforms all listed baselines on LiveCodeBench v6 and OJBench, with notable gaps in performance compared to the second-best models.

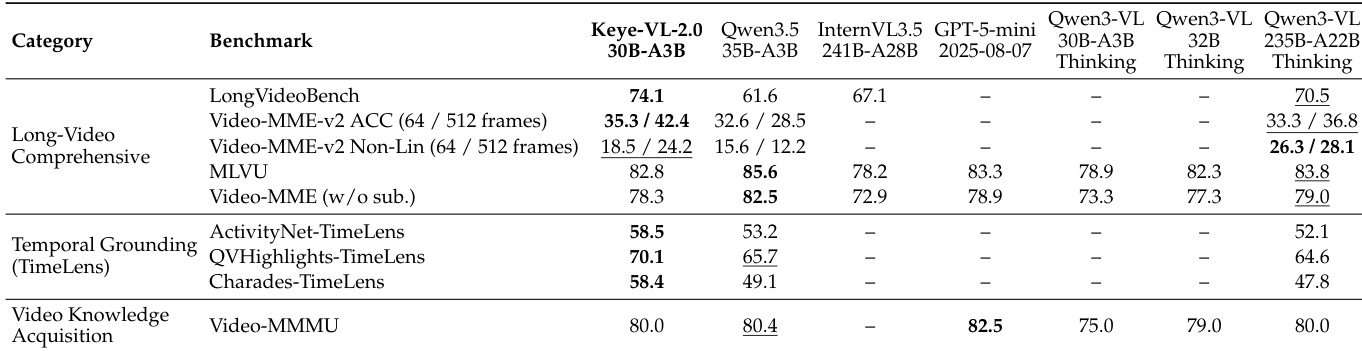
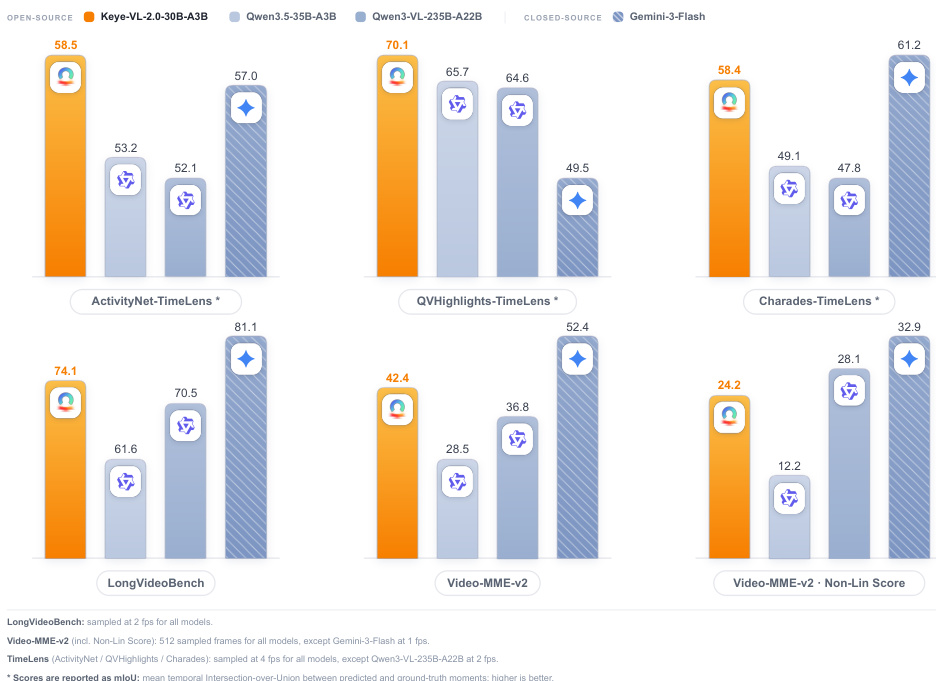
The authors evaluate Keye-VL-2.0-30B-A3B on video understanding benchmarks, comparing it against open-source and closed-source baselines. Results show that the model achieves top performance on LongVideoBench and Video-MME-v2, demonstrates strong accuracy across various settings, and excels in temporal grounding tasks. It also performs competitively on mature benchmarks and achieves the best mIoU on TimeLens subsets, indicating effective handling of dense visual context and long-range aggregation. Keye-VL-2.0 achieves the best result on LongVideoBench and Video-MME-v2, showing strong long-video understanding and accuracy under different frame sampling settings. The model achieves the highest mIoU on all three TimeLens subsets, indicating effective performance in scene-wise dense captioning and temporal grounding. Keye-VL-2.0 remains competitive on mature benchmarks such as MLVU and Video-MME, demonstrating robustness across different evaluation conditions.
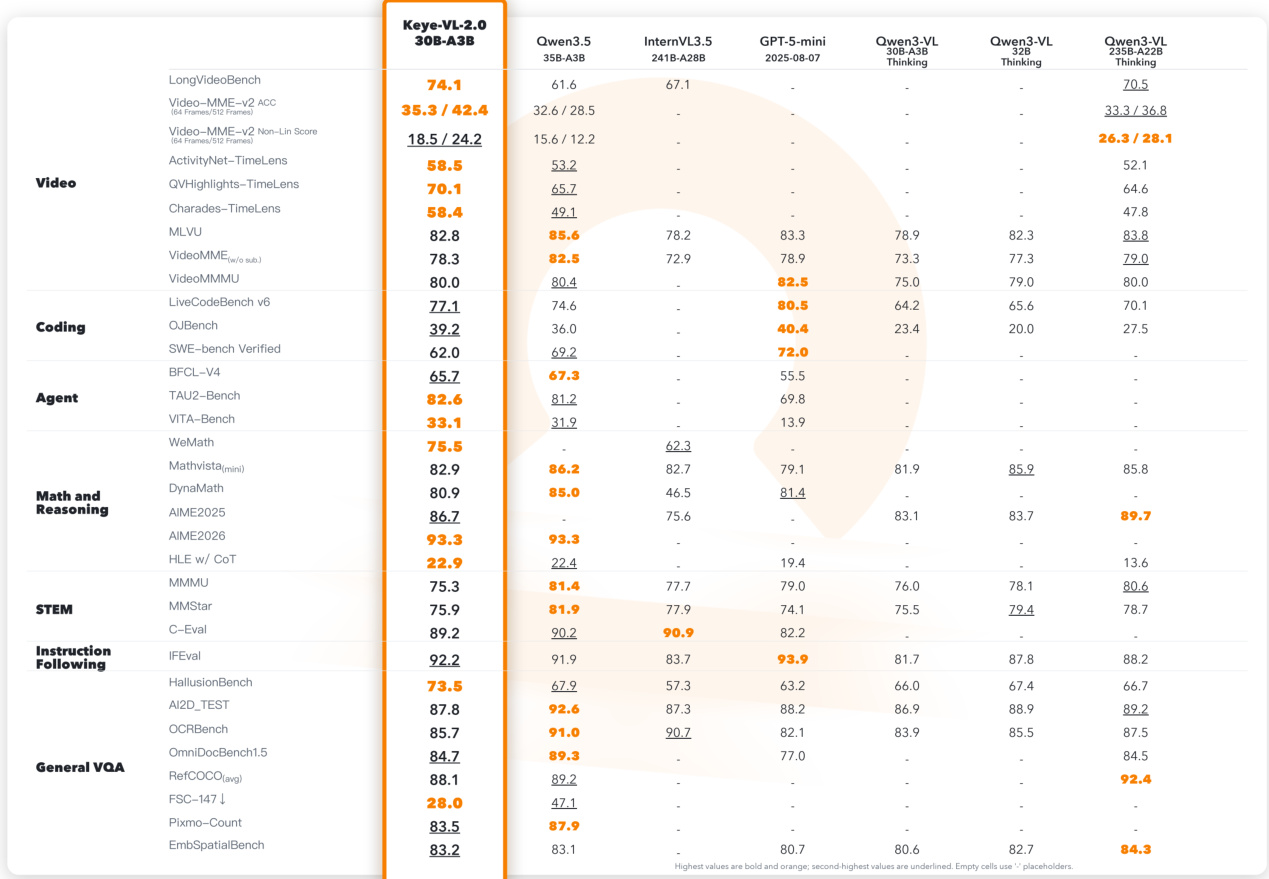
The authors evaluate Keye-VL-2.0-30B-A3B across multiple domains including video understanding, coding, agent capabilities, and general vision-language reasoning. The model achieves top or competitive results on a range of benchmarks, particularly excelling in long-video comprehension, temporal grounding, and mathematical reasoning, while demonstrating strong performance in tool use and multi-domain service orchestration. Keye-VL-2.0 achieves the best results on LongVideoBench and Video-MME-v2, showing strong performance in long-video understanding and temporal grounding. The model ranks first on multiple reasoning benchmarks, including WeMath and AIME2026, and shows competitive results in coding and tool-use tasks. Keye-VL-2.0 demonstrates strong performance in hallucination resistance and general vision-language understanding, particularly in OCR and spatial reasoning tasks.
The evaluation assesses Keye-VL-2.0-30B-A3B across video understanding, coding, tool use, and general vision-language tasks by comparing it against established open-source and closed-source baselines. These experiments validate the model's exceptional proficiency in long-form video comprehension, precise temporal grounding, and robust multi-turn tool interaction for complex service orchestration. The results further highlight its superior algorithmic reasoning, effective repository-level code generation, and strong capabilities in mathematical logic, hallucination resistance, and spatial understanding. Overall, the findings confirm that the model delivers consistently top-tier performance across diverse modalities, establishing it as a highly versatile foundation for advanced multi-agent and vision-language applications.