Command Palette
Search for a command to run...
APPO: エージェント的手続き的ポリシー最適化
APPO: エージェント的手続き的ポリシー最適化
Xucong Wang Ziyu Ma Yong Wang Yuxiang Ji Shidong Yang Guanhua Chen Pengkun Wang Xiangxiang Chu
概要
近年、エージェント型強化学習(RL)の進展により、大規模言語モデルagentsのマルチターンツール利用能力が大幅に向上した。しかし、既存の手法の多くは、ツール呼び出しの境界や固定されたワークフローといった粗いヒューリスティック単位に対して信用を割り当てており、どの中間決定が下流の結果に影響を与えるかを特定することが困難である。本研究では、エージェント型RLを2つの観点から検討する:\textit{分岐の位置と、分岐後の信用割り当て方法}。予備分析により、影響力のある決定点はツール呼び出しに集中するのではなく生成シーケンス全体に広く分布していることが示され、一方、tokenエントロピーのみでは最終結果への影響を確実に反映しないことが明らかとなった。これらの知見に基づき、本研究では\textbf{Agentic Procedural Policy Optimization (APPO)}を提案する。本手法は、分岐と信用割り当てを粗い相互作用単位からシーケンス内の微細な決定点へと移行させる。APPOは、tokenの不確実性と後続の継続部分におけるポリシー誘導の尤度向上を組み合わせたBranching Scoreを用いて分岐位置を選択し、偽りの高いエントロピー位置をフィルタリングしながら、より標的を絞った探索を可能にする。また、分岐されたロールアウト全体に信用をより適切に分配するため、手順レベルのアドバンテージスケーリングを新たに導入する。13のベンチマークを用いた実験により、APPOが強力なエージェント型RLのベースラインをほぼ4ポイント一貫して改善し、効率的なツール呼び出しを維持しつつ行動の解釈可能性を保持することが示された。
One-sentence Summary
the paper propose Agentic Procedural Policy Optimization (APPO), a reinforcement learning framework for large language model agents that improves multi-turn tool-use by shifting credit assignment from coarse interaction boundaries to fine-grained decision points, employing a Branching Score that combines token uncertainty with policy-induced likelihood gains to guide targeted exploration and procedure-level advantage scaling to distribute credit across branched rollouts.
Key Contributions
- This work proposes Agentic Procedural Policy Optimization (APPO), which shifts branching and credit assignment from coarse heuristic units to fine-grained decision points distributed throughout the generated sequence.
- The algorithm employs a Branching Score that combines token uncertainty with policy-induced likelihood gains to identify high-value branching locations and filter spurious high-entropy positions, while introducing procedure-level advantage scaling to distribute credit across branched rollouts.
- Extensive evaluations demonstrate that the method outperforms existing approaches by approximately three points across thirteen benchmarks, maintaining comparable tool-call efficiency and interpretability.
Dataset
Dataset Composition and Sources
- The authors curate a multi-domain benchmark collection spanning mathematical reasoning, multi-hop knowledge retrieval, and agentic web navigation. Sources include standardized mathematics competitions, Wikipedia-based QA corpora, expert-assembled frontier exams, and real-world tool-use scenarios.
Key Details for Each Subset
- Mathematical Reasoning: AIME24 and AIME25 each contain 30 competition-level problems requiring integer answers between 0 and 999, covering number theory, combinatorics, geometry, and algebra. MATH500 is a 500-problem representative subset of the larger MATH corpus, while the full MATH dataset provides 12,500 problems with step-by-step solutions across a steep difficulty gradient. GSM8K offers 8,500 elementary arithmetic word problems.
- Multi-Hop Knowledge: HotpotQA includes roughly 113,000 Wikipedia pairs with sentence-level supporting facts. 2WikiMultihopQA constructs questions from Wikidata triples to ensure genuine cross-document reasoning. MuSiQue contains approximately 25,000 questions built by chaining single-hop items via directed acyclic graphs to eliminate shortcuts. Bamboogle is a filtered set of 125 two-hop questions specifically designed to defeat standard search engines.
- Agentic and Frontier Evaluation: GAIA features 466 real-world tasks requiring tool use and planning. HLE comprises 2,500 expert-curated questions across STEM and humanities, with about 10 percent requiring image comprehension. WebWalkerQA contains 680 questions demanding multi-page click navigation. XBench provides dynamic, profession-aligned tasks from fields like software engineering and legal work, scored against expert references.
Data Usage and Processing
- The authors employ these datasets primarily for rigorous capability evaluation rather than model training. GSM8K is explicitly split into 7,500 training and 1,000 test examples, while all other benchmarks are used in-distribution or out-of-distribution to probe specific reasoning pathways. AIME25 serves as a contamination-resistant checkpoint due to its post-training cutoff release date. Performance metrics focus on average accuracy across multiple runs for smaller sets and fine-grained reasoning chain evaluation for multi-hop tasks.
Cropping, Metadata, and Strategy Details
- The dataset construction emphasizes structural integrity and adversarial filtering. Multi-hop benchmarks rely on explicit evidence chain annotations and DAG-based composition to prevent shortcut learning. Bamboogle uses search-engine failure as a filtering rule to enforce compositional reasoning. The authors also track rollout trajectories and decision branches, documenting search queries, intermediate results, and code execution blocks to analyze model reasoning stability and tool-augmented planning workflows.
Method
The authors propose APPO, an agentic reinforcement learning algorithm that shifts branching and credit assignment from coarse tool- or workflow-level units to fine-grained decision points within the generated sequence. In a standard agentic reinforcement learning setting, an agent interacts with an external environment and a toolset to complete a task. The rollout consists of interleaved thinking and tool-call steps, followed by answer generation. The training objective aims to maximize the expected reward while penalizing deviation from a reference policy via KL divergence.
To address the limitations of conventional branching strategies that rely solely on token entropy, the authors introduce a fine-grained procedural branching mechanism. Conventional entropy-based methods often select tokens with high lexical uncertainty, which may not correspond to actual decision points that alter downstream reasoning. To overcome this, APPO integrates token entropy with a future-aware likelihood gain to construct a Branching Score. Refer to the overview diagram for a visual comparison of branching locations and the integrated metric.
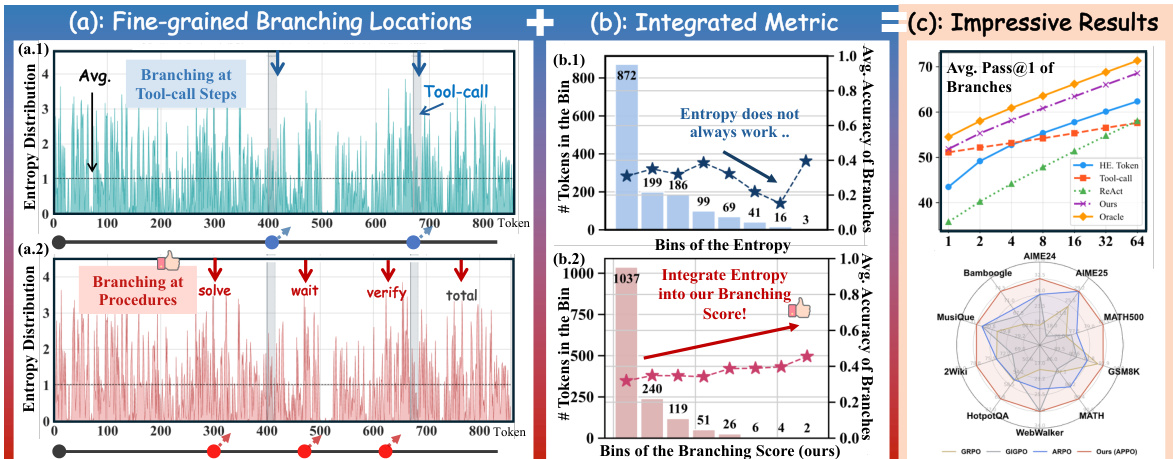
The core training pipeline of APPO is illustrated in the framework diagram below.
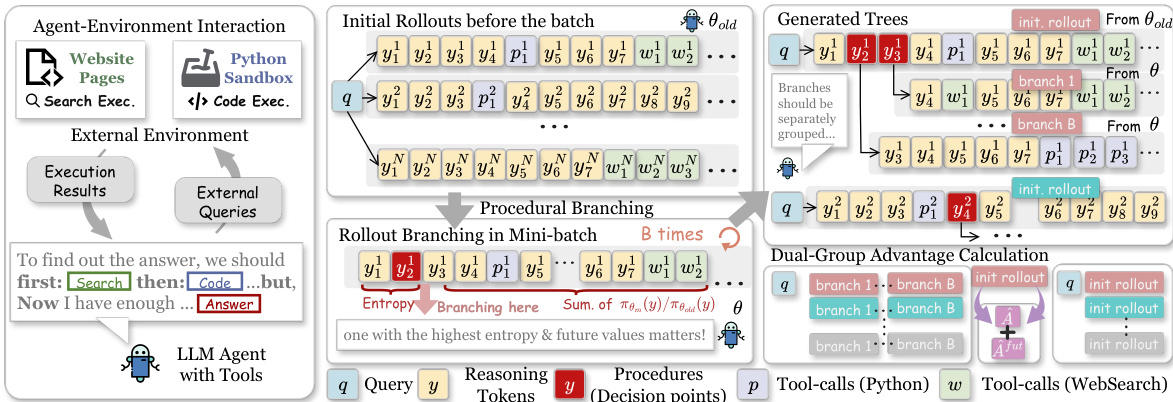
The process begins with initialization. Given an input query and a global rollout budget, the model generates a set of full rollouts using the current policy. These rollouts serve as the roots of independent trees. During the mini-batch training phase, APPO identifies fine-grained decision points by computing the Branching Score for each token in the rollout. The Branching Score is defined as the product of the normalized token entropy and a future value term. The token entropy captures local uncertainty, while the future value term measures the accumulated decayed importance sampling ratio of subsequent tokens. This future value acts as a proxy for posterior accuracy, indicating whether a token leads to states favored by the current policy. By combining these two factors, the method selects tokens that are both uncertain and consequential.
Once the top branching tokens are identified, the model resamples continuations from these positions using the current policy to generate new branches. These branches are then grouped and integrated into the rollout tree. Unlike traditional tree reinforcement learning methods that sample branches from a fixed behavior policy, APPO generates branches using the active mini-batch policy to better reflect current learning dynamics.
For advantage estimation, the authors employ a dual-group strategy to avoid bias from mixing rollouts generated by different policies. Group-relative advantages are computed separately for the initial rollouts and the newly generated branches. This approach treats generated tokens as observable instantiations of latent decision points, allowing for localized credit assignment. Furthermore, to emphasize critical procedures that serve as turning points in the reasoning process, APPO introduces a future-aware advantage term. This term scales the base advantage based on the accumulated importance sampling ratios from the decision point onward, effectively assigning larger credits to decisions with stronger downstream influence. The final advantage is a weighted combination of the base advantage and the future-aware component.
The policy optimization step follows a clipped surrogate objective. The model updates its parameters by maximizing the expected advantage-weighted log probability ratio, subject to a clipping constraint to ensure stable updates. A KL divergence penalty is applied to constrain the policy update relative to the reference model. The branches generated during training are not directly optimized; instead, they provide auxiliary procedural signals that enhance the accuracy of the advantage estimation for the initial rollouts. This design enables targeted credit assignment at procedure-level decisions, significantly improving exploration efficiency and reasoning performance in agentic tasks.
Experiment
The evaluation assesses the proposed APPO method across mathematical reasoning, knowledge-intensive reasoning, and deep search benchmarks against various reinforcement learning and agentic baselines. Main results validate that decision-point-based branching consistently outperforms fixed-step approaches by directing exploration toward structurally meaningful reasoning steps rather than high-entropy noise. Scaling and qualitative analyses further confirm that this targeted strategy yields more stable training dynamics, produces semantically distinct reasoning trajectories, and significantly enhances the diversity and reliability of candidate solutions across varying rollout configurations.
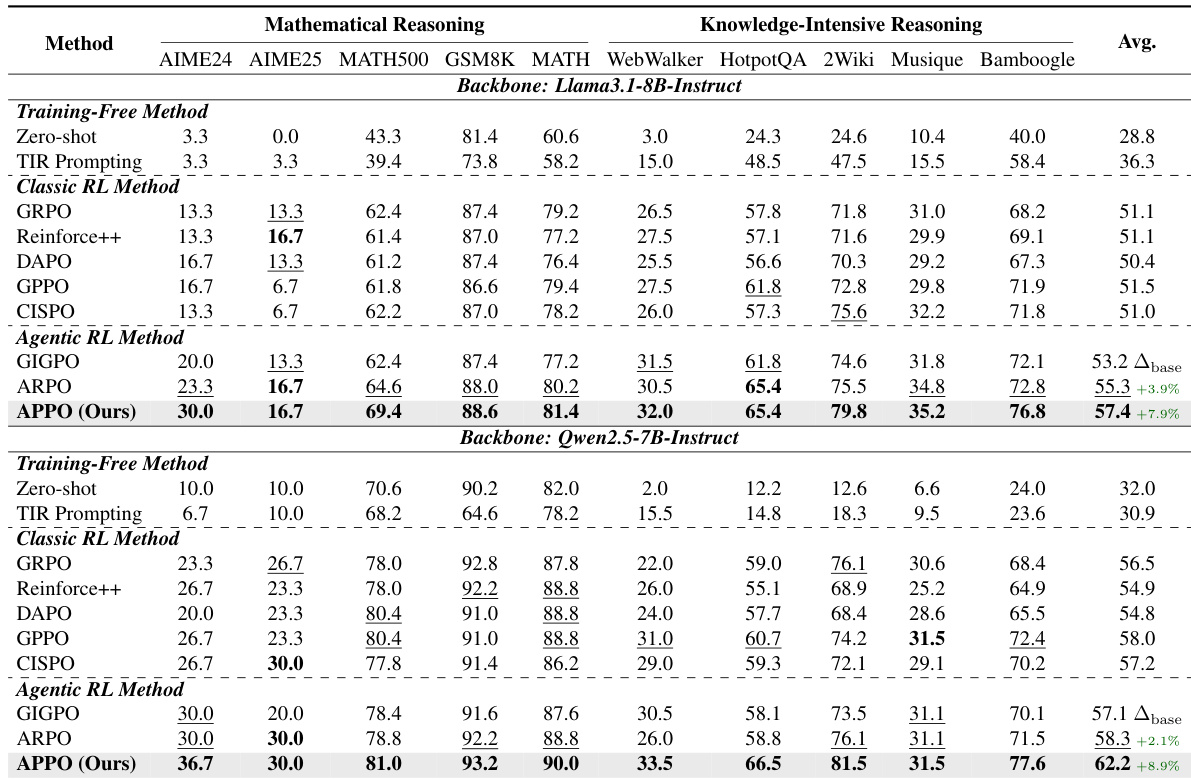
The authors evaluate the proposed APPO method against training-free, classic RL, and agentic RL baselines on mathematical and knowledge-intensive reasoning tasks using Llama3.1-8B and Qwen2.5-7B backbones. Results indicate that APPO consistently achieves superior performance, surpassing all baseline methods across both task categories. The method demonstrates significant average improvements over the base models and establishes new state-of-the-art results for agentic reasoning. APPO outperforms all baselines on mathematical reasoning tasks, including competitive benchmarks like AIME and MATH. The method achieves the highest average scores on knowledge-intensive reasoning datasets, demonstrating strong multi-hop information synthesis capabilities. APPO consistently ranks first across nearly all individual datasets for both model backbones, showing robust generalization.
The authors compare the APPO method with the ARPO baseline across four deep search benchmarks using Pass@K metrics. The results show that APPO consistently achieves higher performance than ARPO across all datasets and sampling settings. Additionally, the performance gap between APPO and ARPO tends to widen as the number of sampled trajectories increases, indicating that APPO effectively improves the diversity of valid reasoning paths. APPO consistently outperforms ARPO across all four datasets (GAIA, HLE, WebWalkerQA, xbench-DS) for Pass@1, Pass@3, and Pass@5. The performance advantage of APPO over ARPO generally increases as the number of sampled trajectories (K) grows. This trend suggests that APPO enhances the overall distribution of candidate solutions rather than just improving the top-1 trajectory.

The experiment evaluates the sensitivity of the APPO method to its branching configuration, specifically focusing on the number of initial trees, branching tokens, and loops. The results demonstrate that configurations with a single initial tree suffer from relatively poor performance across knowledge-intensive reasoning tasks, and this performance remains largely unaffected by changes in branching width or depth. Conversely, increasing the number of initial trees to three results in a significant performance boost, highlighting the importance of initial rollout diversity. Configurations with a single initial tree exhibit suboptimal performance that is insensitive to variations in branching parameters. Increasing the initial tree count to three leads to a marked improvement in overall performance compared to the single-tree setups. The findings suggest that ensuring diverse initial rollouts is more critical for success than fine-tuning the branching budget within a low-diversity framework.

The experiment compares the proposed APPO method against ablation variants and baselines using Llama and Qwen model backbones. APPO consistently achieves the highest average performance across all datasets, outperforming variations that remove specific components or use entropy-based metrics. The results demonstrate that the full method, including future advantage and dual-group estimation, is essential for optimal performance. APPO consistently achieves the highest average scores across all datasets compared to ablation variants and baselines. Removing the future advantage component leads to a noticeable performance drop, especially on the Qwen backbone. Disabling the dual-group advantage estimation results in lower performance compared to the full APPO method.
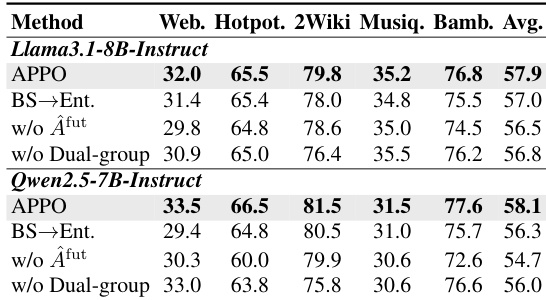
The experiment analyzes how a fixed rollout budget is distributed between the number of initial trees and the number of selected tokens for branching. The results demonstrate that balanced configurations significantly outperform extreme settings where the budget is heavily skewed toward either initial diversity or deep expansion. Balanced configurations of initial trees and selected tokens consistently yield superior performance compared to extreme budget allocations. Increasing the number of initial trees enhances trajectory diversity but reduces the budget available for expanding high-impact decision points. Focusing heavily on expanding specific decision points concentrates the budget on fewer paths, which limits global coverage.
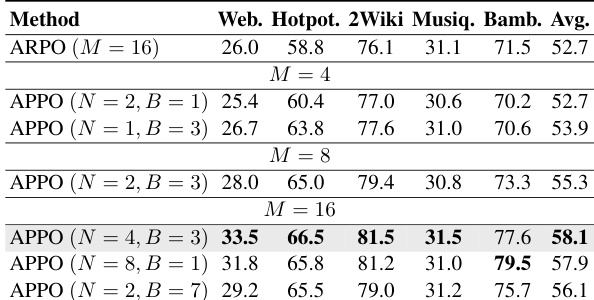
The authors evaluate APPO against multiple baselines and ablation variants across mathematical and knowledge-intensive reasoning tasks using standard LLM backbones. Comparative and ablation studies validate that the full method consistently outperforms existing approaches by effectively enhancing the diversity and quality of reasoning trajectories, with both future advantage estimation and dual-group estimation proving essential for optimal performance. Sensitivity and budget allocation experiments further demonstrate that prioritizing diverse initial rollouts over deep expansion yields the most robust results, while balancing computational resources between initial tree generation and token-level branching is critical for maximizing overall reasoning capability.