Command Palette
Search for a command to run...
Flex4DHuman: 4D人体再構築のための柔軟なマルチビュー動画拡散モデル
Flex4DHuman: 4D人体再構築のための柔軟なマルチビュー動画拡散モデル
Jen-Hao Cheng Yipeng Wang Hao Zhang Gengshan Yang Jenq-Neng Hwang
概要
私たちは、Flex4DHuman を紹介します。これは、動体の単一視点動画、あるいはスパースなマルチビュー動画から、相対的なカメラポーズ条件のみを用いて同期した密なマルチビュー動画へと変換する、マルチビュー動画拡散モデルです。従来のヒューマン中心のアプローチは、スケルトン、深さマップ、法線ベクトル、またはレンダリングされた対象視点幾何学に依存していましたが、Flex4DHuman は明示的な幾何事前知識を必要とせず、代わりに相対的なカメラポーズ位置符号化(positional encoding)を通じて生成を条件付けます。生成された動画は、動的な 4D ガウススプラットを構築するためのダウンストリーム再構築パイプラインに直接取り込むことができます。Flex4DHuman は、Wan 2.1 の 1.3B テキスト・トゥ・ビデオモデルを基盤としており、バックボーンアーキテクチャを保持したまま、空間時間 RoPE にビューインデックスと連続的な SE(3) 相対カメラ幾何学を追加した 5軸位置符号化により、カメラおよびビュー情報をエンコードしています。モデルは、ポーズ追従、柔軟な参照・ターゲット視点間の生成、および時間展開(temporal rollout)の順で段階的にトレーニングするカリキュラム手法によって段階的に学習されます。時間展開をサポートするために、クリーンな過去のターゲットビュートークンを用いてトレーニングを行います。さらに、テスト時にテキスト制御を可能とするためにマルチビューキャプションを追加しました。既存の 4D ガウススプラットリング段階と組み合わせることで、当フレームワークは単一視点の静止カメラ動画から動的な 4D ガウススプラットへと変換します。DNA-Rendering および ActorsHQ における実験により、Flex4DHuman が既存の最先端手法を上回る性能を示すことが確認されました。また、人間と動物の混合データでトレーニングすることで、同じ形式が動物カテゴリにも一般化可能であることが示されました。これらの機能により、Flex4DHuman は、シミュレーション、ゲーム、AR/VR、リシェーティング(動画撮り直し)向けの、カジュアルな単一視点動画からのスケーラブルな 4D コンテンツ作成への実用的な一歩となります。
One-sentence Summary
Built on Wan 2.1's 1.3B text-to-video model, Flex4DHuman is a multi-view video diffusion model that transforms monocular or sparse multi-view video into synchronized dense multi-view videos using relative camera-pose conditioning without explicit geometry priors, utilizing a five-axis positional encoding to enable downstream creation of dynamic 4D Gaussian splats while surpassing state-of-the-art methods on DNA-Rendering and ActorsHQ.
Key Contributions
- This work introduces Flex4DHuman, a multi-view video diffusion model adapted from Wan 2.1 that conditions generation on relative camera-pose positional encoding instead of explicit geometry priors like skeletons or depth maps. The architecture employs a five-axis positional encoding scheme to extend spatio-temporal RoPE with view indices and continuous SE(3) relative camera geometry.
- The framework supports flexible synchronized generation with monocular or variable sparse-view inputs, arbitrary target viewpoints, and temporal rollout capabilities. A three-stage curriculum training process ensures robust cross-view consistency and stable temporal performance across different reference views.
- Generated synchronized multi-view videos are sufficiently consistent for downstream dynamic 4D Gaussian Splatting reconstruction to create dynamic 3D assets from single static-camera recordings. Evaluation on DNA-Rendering and ActorsHQ benchmarks demonstrates that the method surpasses prior state-of-the-art approaches and generalizes to animal categories after mixed training.
Introduction
Generating synchronized multi-view videos is essential for reconstructing dynamic 4D assets used in simulation and AR. Existing methods typically rely on explicit geometry priors like skeletons or depth maps to condition diffusion models. These requirements propagate estimation errors and restrict generalization to human-specific models or fixed camera configurations. The authors introduce Flex4DHuman, a flexible multi-view video diffusion framework that removes the need for explicit geometry during training or inference. Instead, the model conditions generation on relative camera-pose encoding to synthesize consistent novel views from monocular or sparse inputs. This approach enables a direct pipeline from single-camera recordings to dynamic 4D Gaussian splats while generalizing to non-human subjects.
Dataset
-
Dataset Composition and Sources
- The authors utilize three multi-view video datasets: DNA-Rendering, ActorsHQ, and the Dynamic Furry Animals (DFA) dataset.
- DNA-Rendering contributes 1,038 human performance sequences from 548 identities captured with a 48-camera rig.
- ActorsHQ offers 14 sequences featuring 8 actors recorded with 160 cameras.
- The DFA dataset consists of 23 sequences across 9 animal species rendered from 36 to 72 camera viewpoints.
-
Caption Generation and Metadata
- Dense natural-language descriptions are generated for every sequence using Gemini 3 Flash.
- This workflow produces 25,031 captions with an average length of 268 words.
- Human captions prioritize appearance attributes to ensure reliability, whereas animal captions retain high-level behavioral descriptions such as gait and tail movement.
-
Image Processing and Cropping
- Sequences are divided into non-overlapping temporal windows of 10, 20, or 60 frames for DNA-Rendering, ActorsHQ, and DFA respectively.
- Frames are uniformly sampled within each window to construct a 2x2 image grid from four approximately orthogonal viewpoints centered on the foreground subject.
- Backgrounds are masked out before the grid-frame sequence is submitted for captioning.
-
Training Usage
- Each sampled clip is paired with the caption corresponding to the temporal window containing its start frame.
- Different clips from the same sequence are exposed to different textual descriptions over time to increase caption diversity and reduce overfitting.
Method
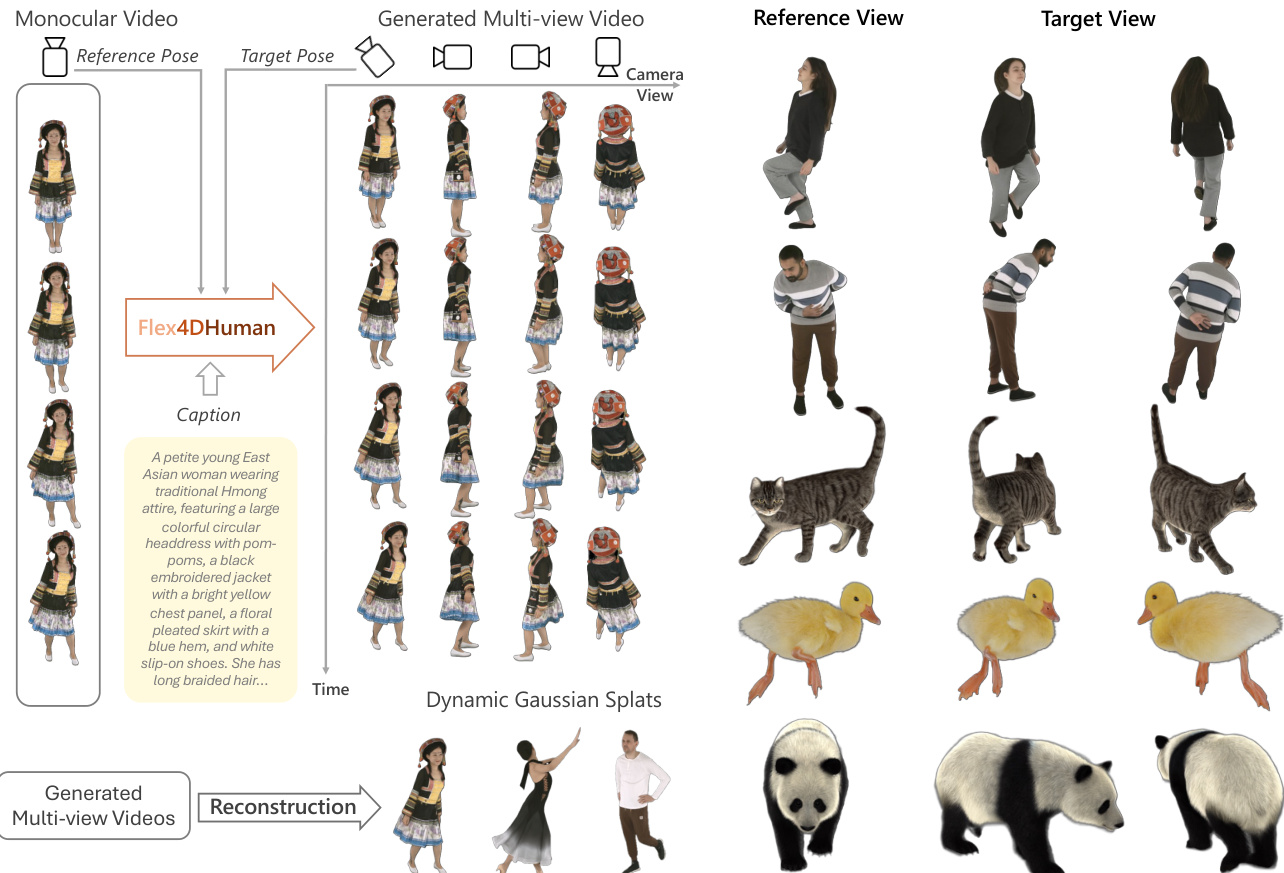
The proposed framework, Flex4DHuman, transforms a monocular video or sparse reference views into synchronized multi-view video generation, which can subsequently be reconstructed into dynamic 3D assets. The overall workflow begins with a monocular input or reference poses, which are processed by the Flex4DHuman model along with a text caption to generate multi-view sequences. These generated videos are then segmented and reconstructed into 4D Gaussian splats for downstream applications.
The core architecture builds upon the Wan 2.1 text-to-video Diffusion Transformer (DiT) backbone. The primary modification lies in the input representation and the positional encoding scheme to accommodate multi-view geometry. Reference and target views share a unified 36-channel input layout. This consists of 16 channels for noisy latents, 16 channels for conditioning latents (clean latents), and a 4-channel binary mask. For reference views, the conditioning channels are populated with encoded latents and an all-one mask, whereas target views utilize zeros for the conditioning channels. This design allows the model to distinguish between observed and unobserved regions, enabling bidirectional information propagation during training and clean history conditioning during inference.
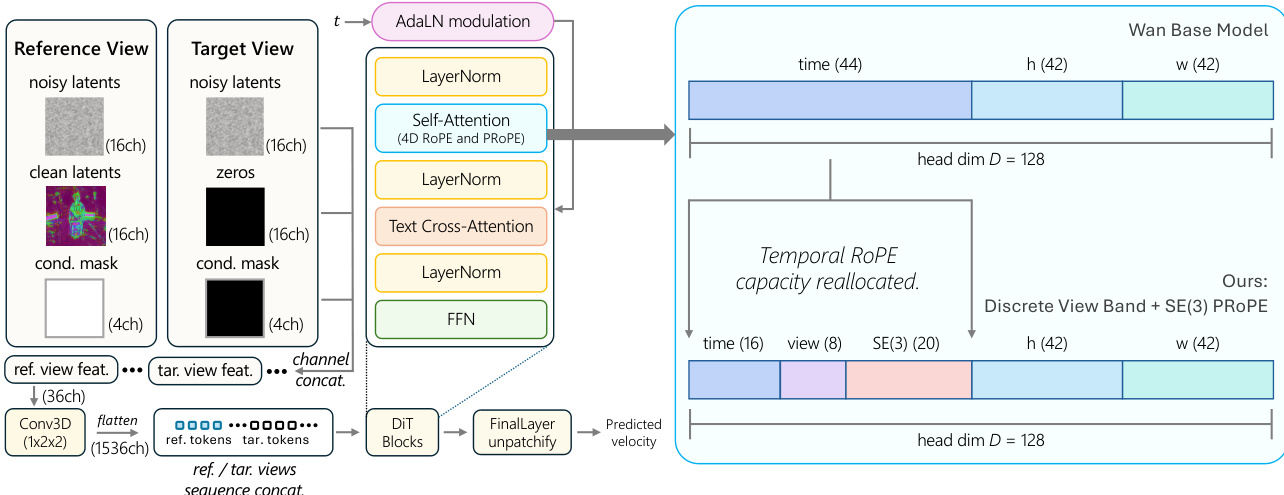
To encode camera geometry without learnable embeddings, the authors replace the original spatio-temporal Rotary Positional Encoding (RoPE) with a projective positional encoding that combines spatial coordinates, discrete frame indices, discrete view-slot indices, and continuous SE(3) camera geometry. The original temporal RoPE capacity is reallocated to support these new dimensions. Specifically, the head dimension D=128 is repartitioned from (Dt,Dh,Dw)=(44,42,42) to (Dtime,Dview,DSE(3),Dh,Dw)=(16,8,20,42,42). The SE(3) component encodes relative camera transformations directly within the attention mechanism. For each token i, the query and key sub-vectors allocated to the SE(3) band are transformed according to the camera pose Ti:
QiSE(3)←Ti⊤QiSE(3),KiSE(3)←Ti−1KiSE(3),where Ti∈SE(3) denotes the camera pose. This formulation ensures that attention depends on the relative camera transformation between tokens, making the model invariant to the number and spatial arrangement of cameras.
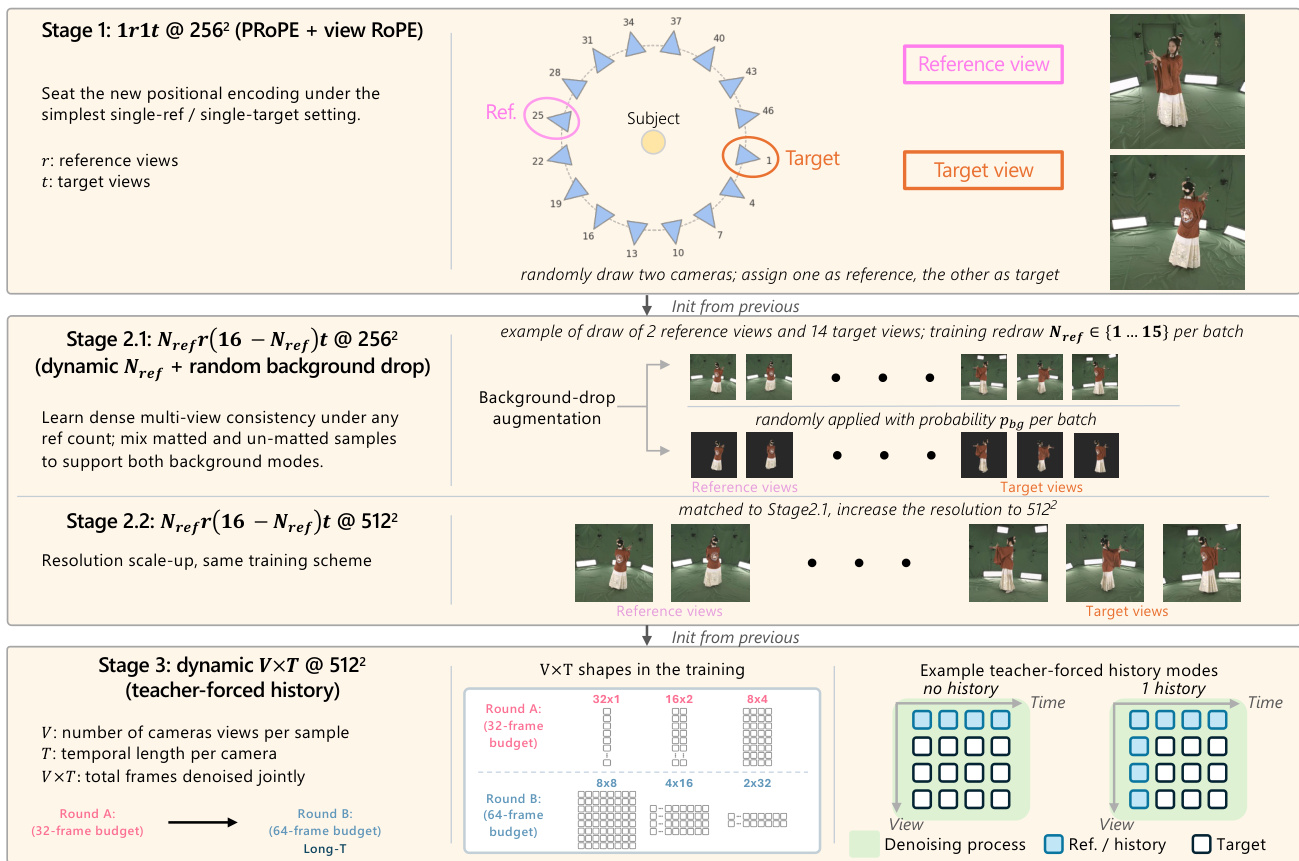
The model is trained using a three-stage curriculum designed to progressively increase complexity. The first stage adapts the pretrained backbone to the new positional encoding using a single-reference single-target setting. The second stage introduces dynamic reference-view sampling with a variable number of reference views and applies random background-drop augmentation to support both foreground-only and full-background generation. This stage is trained at 2562 resolution before scaling to 5122. The final stage extends training to dynamic temporal windows with teacher-forced history conditioning, allowing the model to generalize across different view-time configurations under a shared token budget.
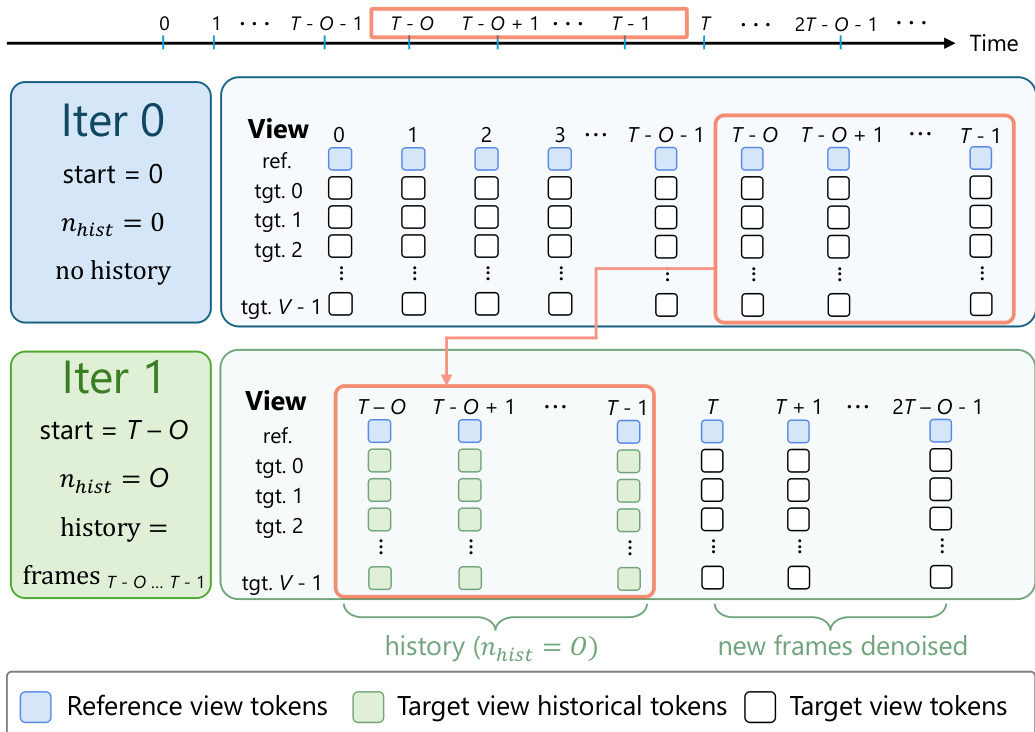
For inference, the system employs a chunked rollout strategy to generate videos longer than the training horizon. As illustrated below, the generation process is divided into iterations. In the first iteration, only reference-view tokens serve as clean conditioning. In subsequent iterations, the model advances by T−O frames and reuses the O overlapping predictions from the previous chunk as clean history tokens for all target views. This mechanism enables long-horizon synchronized multi-view generation by maintaining temporal consistency across chunks.
Finally, the generated multi-view videos can be converted into 4D assets through a reconstruction pipeline. This involves foreground segmentation using MatAnyone2 to isolate the actor, followed by fitting dynamic Gaussian splats using FreeTimeGS. This process lifts the 2D generated videos into a 3D representation suitable for interactive rendering and composition into virtual scenes.
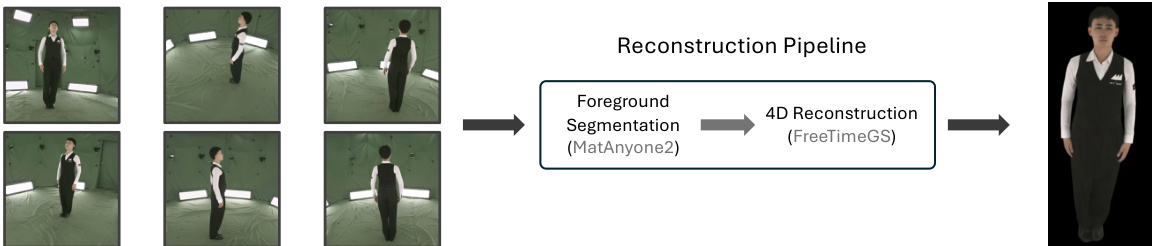
Experiment
Flex4DHuman is evaluated across three benchmarks involving direct novel view synthesis and 4D Gaussian splat reconstruction on held-out camera rigs. Experiments on DNA-Rendering demonstrate that the method outperforms strong baselines while maintaining consistent quality regardless of reference view selection or quantity. Additionally, zero-shot generalization tests on ActorsHQ and animal datasets validate that the model transfers effectively to unseen subjects and camera configurations without relying on explicit human geometry priors.
The authors evaluate the model on the Dynamic Furry Animal dataset to test its ability to generalize beyond human subjects. They compare a within-animal setting, where species are seen during training, against a cross-animal setting with unseen species. Results show that while the model performs best on known species, it retains strong generative capabilities for new animal types. The within-animal setting achieves better reconstruction quality across all reported metrics. Performance remains robust when generalizing to animal species not included in the training set. The method successfully transfers to non-human subjects without relying on human-specific geometry.

The the the table outlines the statistics for the three benchmarks used in the experiments: DNA-Rendering, ActorsHQ, and DFA. DNA-Rendering is the largest dataset by a significant margin, providing the majority of subjects and sequences. The remaining datasets contribute human and animal data with distinct technical configurations. DNA-Rendering contains the overwhelming majority of subjects and sequences compared to the other benchmarks. The datasets include both human and animal subjects to assess generalization beyond human data. The benchmarks differ in technical attributes such as resolution, frame rate, and temporal window duration.

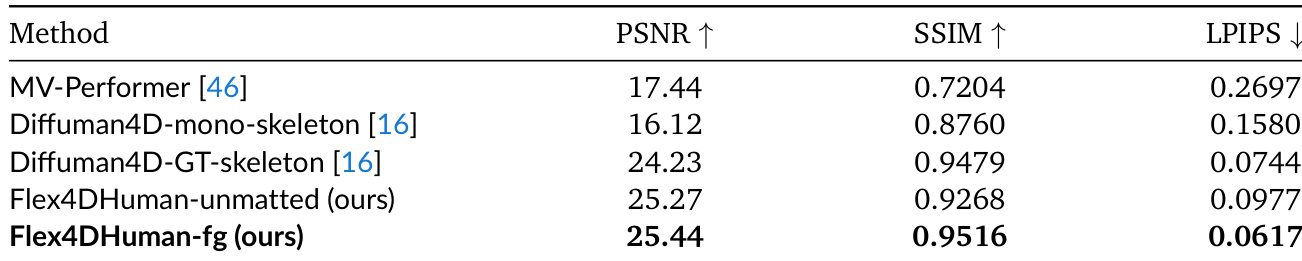
The authors evaluate the proposed Flex4DHuman-fg method against the Diffuman4D-mono-skeleton baseline on the DNA-Rendering benchmark. The results show that the proposed method achieves superior performance across all reported metrics, including PSNR, SSIM, and LPIPS. Flex4DHuman-fg achieves higher PSNR and SSIM scores than the Diffuman4D-mono-skeleton baseline. The proposed method yields a lower LPIPS score, indicating superior perceptual similarity. The results confirm the effectiveness of the foreground-only approach in novel view synthesis.

The authors evaluate Flex4DHuman against multi-view human diffusion baselines on the DNA-Rendering dataset using PSNR, SSIM, and LPIPS metrics. The results demonstrate that the foreground-only version of their method achieves superior reconstruction quality compared to both single-reference baselines and a ground-truth skeleton baseline. Flex4DHuman-fg achieves the highest scores across all evaluated metrics compared to the listed methods. The proposed method significantly outperforms single-reference baselines like MV-Performer and Diffuman4D-mono-skeleton. Flex4DHuman-fg surpasses the strong Diffuman4D-GT-skeleton baseline despite relying on less geometric information at inference.
The study evaluates the model across the DNA-Rendering, ActorsHQ, and Dynamic Furry Animal datasets to assess generalization beyond human subjects. Experiments on human data demonstrate that the proposed foreground-only method achieves superior reconstruction quality compared to multi-view diffusion baselines and ground-truth skeleton baselines. Additionally, results on the Dynamic Furry Animal dataset confirm that the method successfully transfers to non-human subjects without relying on human-specific geometry while maintaining robust generative capabilities for unseen species.