Command Palette
Search for a command to run...
LoopCoder-v2: 効率的なテスト時の計算スケーリングのために一度だけループする
LoopCoder-v2: 効率的なテスト時の計算スケーリングのために一度だけループする
概要
ループ型トランスフォーマーは共有ブロックを繰り返し適用することで潜在計算の規模を拡大するが、逐次ループ処理ではループ数の増加に伴いレイテンシとKVキャッシュメモリが増大する。並列ループトランスフォーマー(PLT)は、クロスループ位置オフセット(CLP)および共有KVゲート付きスライディングウィンドウアテンションを用いてこのコストを軽減し、ループ数を実用的な設計パラメータとし得るようにしている。本研究では、利得とコストの観点からPLTにおけるループ数の選択を調査する。追加のループは表現を精緻化する可能性がある一方で、CLPは各ループ境界において位置の不一致を招く。本研究の具体化として、18T tokensを用いてスクラッチから異なるループ数を有する7B規模のPLTコード生成モデル群であるLoopCoder-v2を学習させ、その後、対応するインストラクションチューニングと評価を実施した。実証結果より、2ループ構成のモデルは、コード生成、コード推論、エージェントソフトウェアエンジニアリング、ツール利用ベンチマークにおいて、ループなしのベースラインに対して広範な性能向上をもたらした。具体的には、SWE-bench Verifiedで43.0から64.4ポイント、Multi-SWEで14.0から31.0ポイントのスコア向上が観測された。一方、3ループ以上の構成では性能が低下し、ループ数に対して強く非単調な効果が現れることが明らかとなった。詳細解析により、2ループ目が主要な表現の精緻化をもたらす一方で、それ以降のループでは更新の効果が減衰し振動的な変化を生じ、表現的多様性が低下することが示された。表現の精緻化による利益が縮小するにつれてCLPに起因する位置不一致はほぼ一定のままとなるため、オフセットに伴うコストが次第に支配的となる。この利得とコストのトレードオフは、PLTが2ループで性能が頭打ちとなる理由を説明するとともに、ループ数の選択に関する診断指針を提供するものである。
One-sentence Summary
Trained from scratch on 18T tokens, LoopCoder-v2 is a family of 7B Parallel Loop Transformer models that employs cross-loop position offsets and shared-KV gated sliding-window attention to optimize test-time computation, with empirical evaluation demonstrating that a two-loop configuration maximizes representational refinement and delivers substantial gains across code generation, reasoning, and agentic software engineering benchmarks, whereas deeper loops introduce positional mismatch and oscillatory updates that degrade performance.
Key Contributions
- This work introduces LoopCoder-v2, a family of 7B Parallel Loop Transformer code models trained from scratch on 18T tokens with matched instruction tuning to systematically evaluate distinct loop configurations.
- A gain-cost analysis of cross-loop position offsets reveals a strongly non-monotonic scaling effect, demonstrating that the second loop delivers the primary productive refinement while deeper iterations yield diminishing returns and oscillatory updates.
- Empirical evaluations across code generation, reasoning, and agentic software engineering benchmarks demonstrate that the two-loop variant significantly outperforms the non-looped baseline, improving SWE-bench Verified scores from 43.0 to 64.4 and Multi-SWE from 14.0 to 31.0.
Introduction
Looped Transformers scale latent computation by repeatedly applying shared blocks to refine internal representations without generating auxiliary reasoning tokens, offering a parameter-efficient path for complex tasks like code generation and agentic software engineering. Standard sequential looping, however, linearly inflates inference latency and KV-cache memory, while parallel variants like PLT mitigate this bottleneck by introducing cross-loop position offsets that create structural mismatches at each boundary. Prior work shows that additional loops quickly yield diminishing returns, oscillatory updates, and performance collapse, yet lacks a diagnostic framework to explain why saturation occurs. The authors leverage a gain-cost analysis to systematically evaluate loop-count selection in PLTs. By training LoopCoder-v2 variants with varying depths and tracking hidden-state dynamics, they demonstrate that a two-loop configuration maximizes productive refinement before positional mismatches dominate. This work delivers interpretability-grounded diagnostics for optimal loop allocation and clarifies the non-monotonic scaling behavior of recurrent depth architectures.
Dataset

- Dataset Composition and Sources: The authors construct an 18 trillion token pretraining mixture sourced from a broad collection of textual and programming data. The corpus is explicitly balanced to maintain a strict 1:1 token ratio between natural language text and code.
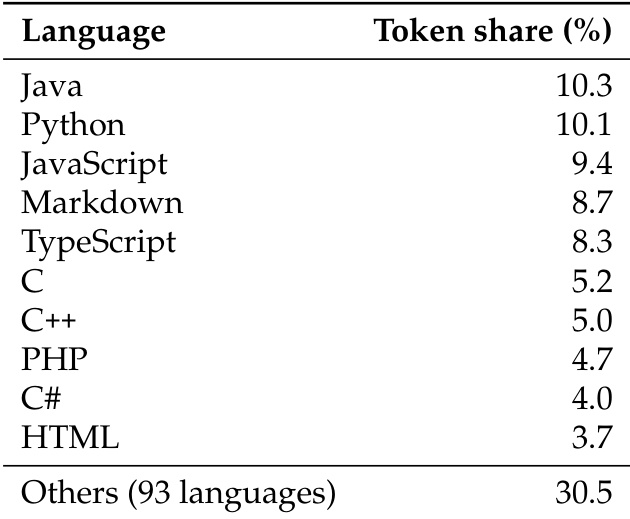
- Subset Details: The code portion is categorized by programming language. The authors report the top 10 languages by token share individually and aggregate the remaining 93 languages into an "Others" category. All distribution percentages are calculated exclusively over the code token pool.
- Model Usage and Processing: This balanced mixture serves as the complete input for the model's pretraining phase. The authors enforce token-level balancing during corpus assembly to ensure equal representation of text and code, with language distribution tracked through the reported token share metrics.
- Additional Processing Notes: The dataset relies on token-level aggregation rather than document-level sampling to achieve its balance. Language classification is applied solely to the code segment, enabling transparent reporting of linguistic distribution without altering the raw token stream.
Experiment
The evaluation employs a 7B-parameter transformer equipped with the Parallel Loop Transformer mechanism, systematically varying the inference loop count from one to four while assessing performance across diverse code, reasoning, and agentic benchmarks. Macroscopic performance analysis reveals a strongly non-monotonic relationship where a single additional loop yields optimal results, making the model highly competitive with significantly larger systems. Microscopic interpretability diagnostics validate that the second loop serves as the primary site of productive refinement, maximizing representational diversity and output shift before subsequent iterations suffer from diminishing returns and compounding positional offset costs. Furthermore, experiments demonstrate that this latent iterative refinement operates complementarily to explicit chain-of-thought reasoning, producing super-additive improvements when combined at the optimal loop configuration.
The authors analyze the internal dynamics of the PLT model across inference loops to understand the trade-offs of loop counts. The data indicates that attention dispersion decreases significantly after the first loop, while the most substantial restructuring of attention maps occurs at the second loop. Furthermore, the gating mechanism consistently prioritizes the global key-value cache over local context throughout the process. Attention dispersion drops sharply from the first to the second loop for all model variants. Inter-loop attention changes are most pronounced at the second loop and diminish rapidly thereafter. The gating weight remains consistently above the midpoint, indicating a persistent preference for the global cache.
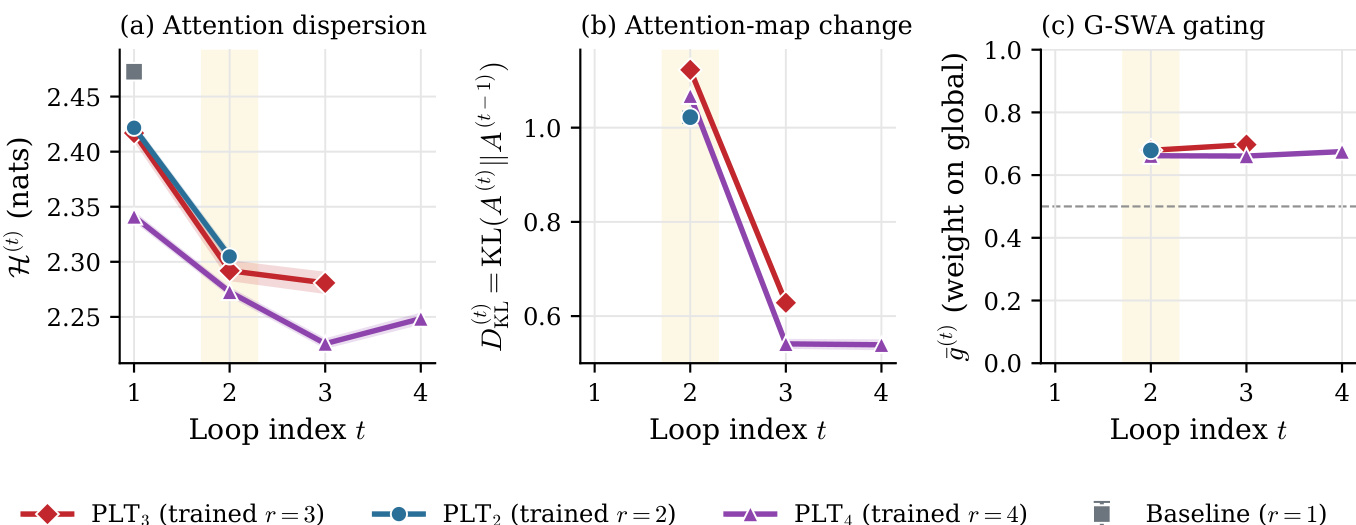
The experiment compares an instruction-tuned model relying solely on latent loops against a thinking model that incorporates explicit chain-of-thought reasoning, both evaluated at a loop count of R=2. The results demonstrate that the thinking model consistently outperforms the baseline across all benchmarks, with particularly significant improvements on reasoning-intensive tasks. This suggests that explicit reasoning traces and latent loop refinement are complementary mechanisms that yield super-additive benefits when combined. The thinking model consistently outperforms the instruction-tuned baseline across all benchmarks. Performance gains are most pronounced on reasoning-heavy tasks, indicating strong synergy between explicit reasoning and latent refinement. Combining explicit CoT with latent loops produces super-additive improvements compared to using either method in isolation.

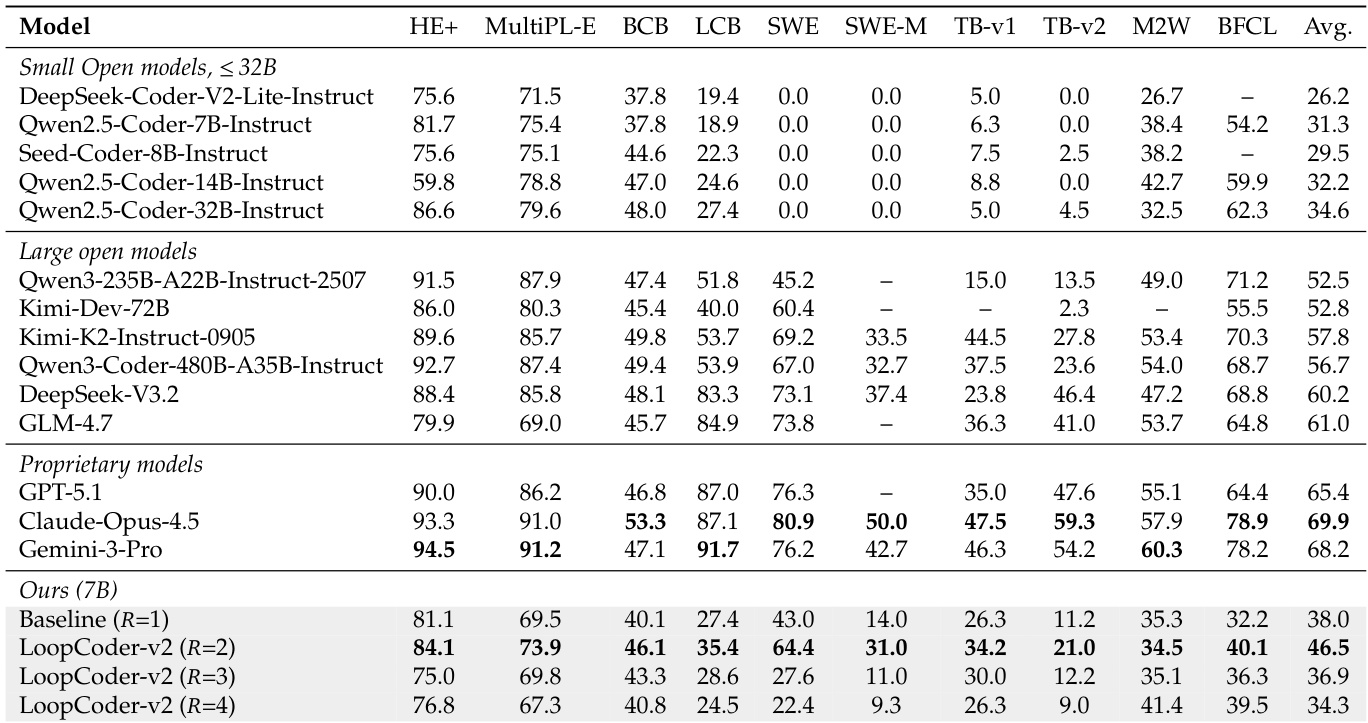
The authors evaluate a 7B-parameter model utilizing Parallel Loop Transformers across varying loop counts to assess the trade-off between representational gains and positional mismatch costs. The results demonstrate a non-monotonic performance curve where a single additional loop yields the highest effectiveness, significantly outperforming the non-looped baseline. Conversely, increasing the loop count further leads to performance regression, often falling below the baseline, indicating that additional iterations introduce detrimental effects rather than refinement. The model configuration with a single additional loop achieves the highest average performance among the proposed variants. Performance degrades when additional loops are introduced beyond the optimal point, suggesting that the fixed cost of positional mismatch outweighs the diminishing representational gains. The optimal configuration demonstrates strong competitiveness on agentic software engineering benchmarks, rivaling the performance of significantly larger open-source systems.
The the the table analyzes per-loop behavioral signatures in a four-loop model, comparing step size, output distribution shift, effective rank, and update alignment. Loop 2 emerges as the principal site of productive refinement, exhibiting the highest effective rank and output distribution shift. Subsequent loops show diminishing representational diversity, with the final loop displaying a shift in update alignment and a rebound in step size, consistent with re-reading the prediction. Loop 2 exhibits the highest effective rank and output distribution shift, marking it as the principal site for productive refinement. Subsequent loops show declining effective rank and attention diversity, indicating diminishing representational gains. The final loop shows a shift in update alignment towards zero and a rebound in step size, consistent with re-reading the prediction.

The model is trained on a dataset containing a balanced mix of text and code, with the code portion spanning over one hundred languages. The distribution is heavily skewed towards Java and Python, which occupy the largest shares. JavaScript, Markdown, and TypeScript are also prominent, while a significant fraction of the tokens comes from a diverse array of other languages. Java and Python are the most dominant languages in the training data. JavaScript, Markdown, and TypeScript appear frequently after the top two languages. A substantial portion of the data is distributed across many other less common languages.
The experiments evaluate the PLT model’s internal inference dynamics, optimal loop configuration, and integration with explicit reasoning across a multilingual code and text dataset. Analysis reveals that the second inference loop serves as the primary stage for attention restructuring and representational refinement, while additional iterations introduce positional mismatch costs that ultimately degrade performance. Throughout the process, the gating mechanism consistently prioritizes global context over local details. Combining latent loop refinement with explicit chain-of-thought reasoning produces strong synergistic improvements on complex tasks, demonstrating that a compactly optimized model can achieve highly competitive results.