Command Palette
Search for a command to run...
GameCraft-Bench: Agentsは実際のゲームエンジンでプレイ可能なゲームをエンドツーエンドで構築できるか?
GameCraft-Bench: Agentsは実際のゲームエンジンでプレイ可能なゲームをエンドツーエンドで構築できるか?
概要
ゲーム生成は、コーディング agent の新興応用分野であり、モデルが自然言語による仕様をプレイ可能なインタラクティブシステムに変換することを要求する。従来のコーディングタスクとは異なり、ゲーム生成はゲームエンジン内で行われ、スクリプト、シーン、アセット、レンダリング、ランタイムインタラクションが協調して一貫性のあるゲームプレイを生成する必要がある。我々は、エンドツーエンドのゲーム生成を、対象環境において観測可能なプレイヤーとゲームのインタラクションを通じて仕様を実現する完全なゲームアーティファクトを生成する問題として形式化する。我々は、この評価設定には3つの望ましい特性(Engine Grounding、Artifact Completeness、Interactive Verification)が必要であると主張する。我々は、再生デモンストレーションとルーブリック誘導型マルチモーダル評価を通じて実行可能なゲームプレイを評価する、インタラクションに根ざした評価フレームワークを提案する。我々は、このフレームワークをGameCraft-Benchとして具現化する。これは15種類のゲームファミリーにわたる140のGodotタスクから構成されるベンチマークである。最先端のコーディング agent に対する評価は、エンドツーエンドのゲーム生成が依然として極めて困難であることを示している。最も性能の高い agent でも達成率は41.46%にとどまり、大半の agent は40%未満のスコアであった。さらなる分析により、agent がしばしば認識可能なゲームメカニクスを実装している一方で、十分なコンテンツ、機能的な視覚フィードバック、一貫性のあるプレゼンテーションを備えた完全なゲームを完成させることには苦戦していることが明らかになった。デモ、コード、データについては https://tongxuluo.github.io/gamecraft-bench-website を参照されたい。
One-sentence Summary
GameCraft-Bench introduces an interaction-grounded benchmark that evaluates engine grounding, artifact completeness, and interactive verification via rubric-guided multi-modal judging across 140 Godot tasks, revealing that frontier coding agents struggle to transform natural language specifications into complete, playable games within real game engines, with the strongest agent achieving only 41.46%.
Key Contributions
- The paper introduces an interaction-grounded evaluation framework that requires executable game artifacts to be tested through replayed demonstrations and rubric-guided multi-modal judging. This framework operationalizes three core desiderata: engine grounding, artifact completeness, and interactive verification.
- The framework is instantiated as GameCraft-Bench, a benchmark comprising 140 Godot engine tasks across 15 game families. It assesses end-to-end construction by requiring complete, playable projects paired with replayable demonstration scripts for consistent runtime evaluation.
- Evaluations of frontier coding agents demonstrate that end-to-end game generation remains highly challenging, with the strongest model achieving only 41.46% success. Analysis reveals that while agents frequently generate recognizable local mechanics, they consistently fail to assemble complete games with sufficient content, functional visual feedback, and coherent interactive presentation.
Introduction
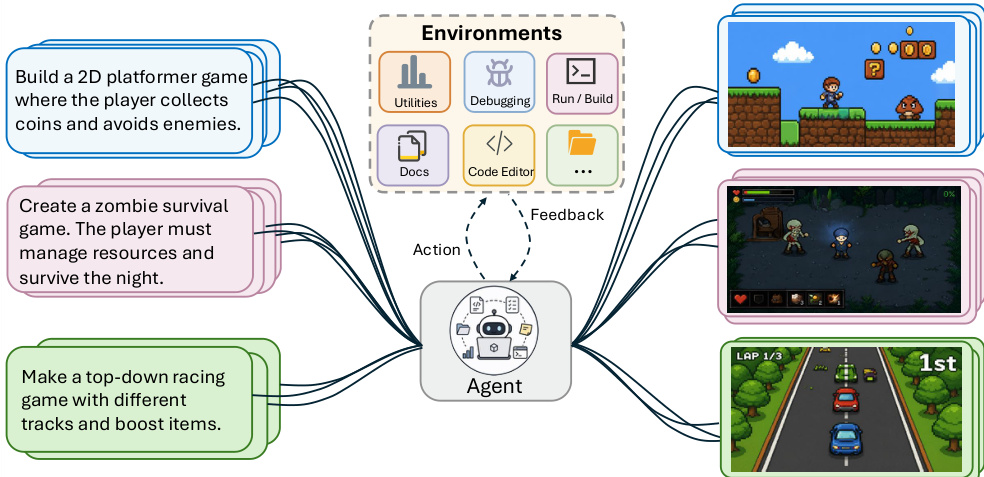
The authors frame end-to-end game generation as a critical frontier for coding agents, where natural language specifications must be transformed into fully playable interactive systems within real game engines. Prior benchmarks fall short by either targeting web-based projects, testing only localized code edits, or relying on static inspection rather than direct gameplay verification. To address these gaps, the authors introduce GameCraft-Bench, a benchmark that jointly enforces engine grounding, artifact completeness, and interactive verification across 140 Godot tasks. By evaluating agents through replayed gameplay demonstrations and rubric-guided assessment, they demonstrate that current models can produce isolated mechanics but consistently struggle to assemble complete, visually coherent, and functionally interactive games.
Dataset

Dataset Composition and Sources
- The authors introduce GameCraft-Bench, a benchmark consisting of 140 tasks spanning 15 distinct game families, including platformers, strategy, tycoon, roguelike, and visual novels.
- All tasks are grounded in the open-source Godot 4 engine to enable lightweight, headless, and reproducible evaluation.
- Visual assets are sourced from Kenney CCO packs and OpenGameArt entries, mounted read-only in the workspace.
Key Details for Each Subset
- The benchmark contains exactly 140 tasks, each authored by one of 12 experienced annotators using the Harbor framework.
- Every task requires a complete, shippable micro-game rather than isolated prototypes or static mockups.
- A strict launchability gate enforces this rule: if the generated Godot project fails to run, the submission receives a zero score.
- Tasks are structured around a hidden evaluation rubric that decomposes gameplay into observable, requirement-level criteria.
Data Usage and Evaluation Pipeline
- The dataset is designed strictly for benchmarking and evaluation rather than model training.
- Agents submit a Godot project along with up to ten demonstration trace files that simulate player input.
- The verifier replays these traces in a headless Godot runtime, records gameplay, and feeds the video to a multimodal judge for scoring.
- No explicit training or validation splits are defined, as the focus is on zero-shot evaluation of agent-generated artifacts against predefined specifications.
Processing, Metadata, and Scoring Details
- Each task is packaged with three metadata files: task.toml for runtime configuration, instruction.md for the public game specification, and tests/rubric.json for the hidden scoring criteria.
- Rubrics are divided into four fixed categories: Core Mechanics, Content Depth, Functional Visuals, and Art & Presentation, with a maximum of 24 scoring items per task.
- Input traces are formatted as JSON files containing timestamped mouse clicks, key presses, and wait commands mapped to a 1280 by 720 viewport.
- Gameplay recordings are sampled at two frames per second, compressed to 854 by 480 resolution, and capped at a 20-second deterministic window per demo.
- Scoring applies a mean aggregation for consistent features like readability and art consistency, while using a max aggregation for existence checks. Weak or purely decorative implementations are capped at 0.5 out of 1.0.
Method
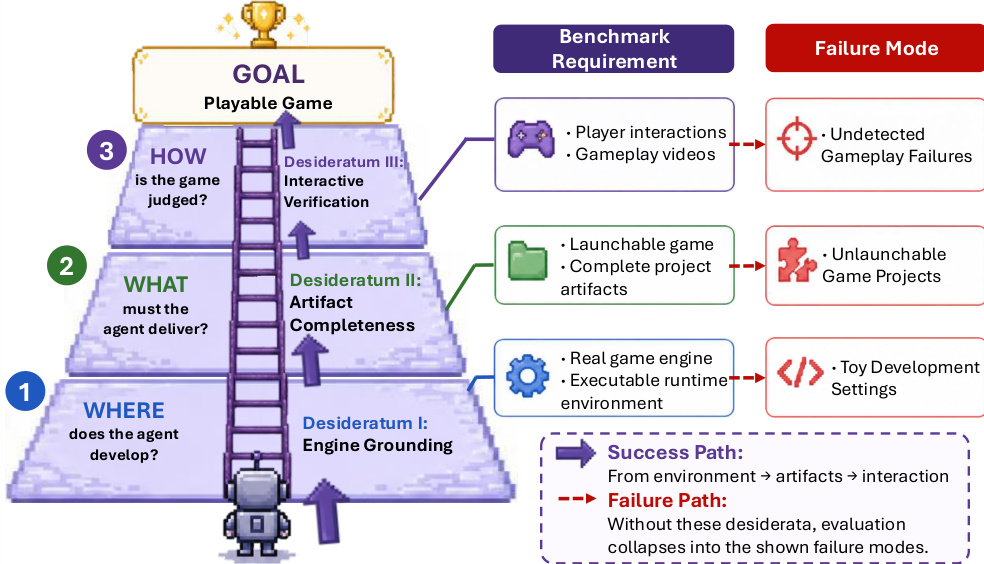
The authors frame the AI game generation task as a mapping (s,E)↦G, where an agent transforms a game specification s and a target environment E into a playable artifact G. To ensure rigorous evaluation, the framework enforces three desiderata: Engine Grounding, which requires operating in a real engine; Artifact Completeness, which demands a launchable project; and Interactive Verification, which judges via gameplay.
As shown in the framework diagram below, these desiderata form a pyramid structure that defines the success path for game generation.
The implementation utilizes a five-stage pipeline to instantiate this mapping. The process begins with Task Packaging, which combines a natural-language specification, the Godot development environment, and a hidden rubric. This rubric decomposes the intent into four scoring categories: Core Mechanics, Content Depth, Functional Visuals, and Art & Presentation.
Refer to the end-to-end evaluation pipeline for the detailed workflow:
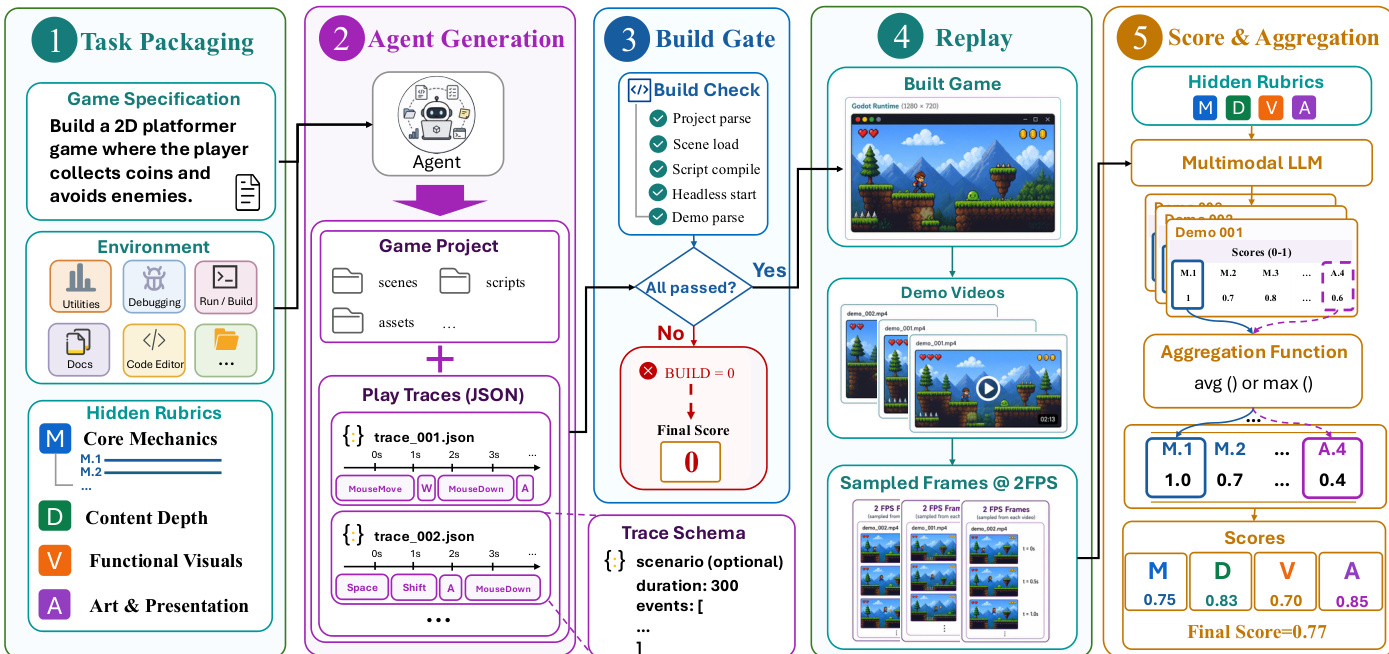
In the Agent Generation stage, the agent constructs the game project G and a set of replayable traces Π. This phase operates as an iterative loop where the agent writes code, runs the project, inspects the output, and fixes errors.
Refer to the core loop diagram for the agent's iterative workflow:
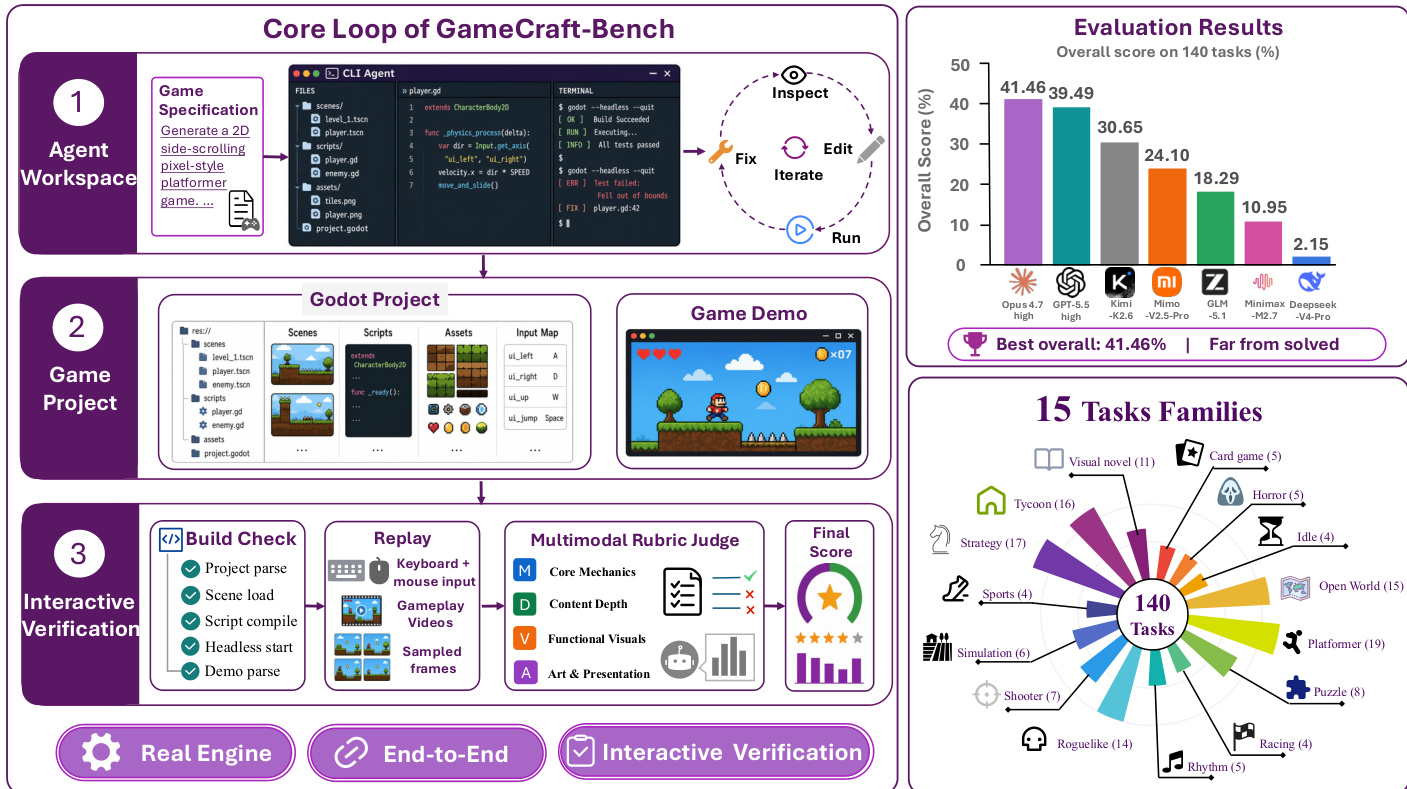
The agent iterates through inspecting, editing, and fixing the game until it meets the specification. The traces Π are recorded to provide standardized interaction evidence.
Once the submission is ready, the Build Gate verifies launchability. If the project fails to parse or launch, the score is zero. For valid submissions, the Replay stage replays the traces in the Godot runtime to generate gameplay videos and sampled frames.
As illustrated in the problem definition diagram, the agent interacts with the environment to produce the final playable artifact.
Finally, the Scoring and Aggregation stage employs a multimodal judge to evaluate the replayed evidence against the hidden rubric. The scores are aggregated using specific functions, such as mean or maximum, depending on the requirement, and combined into a final weighted score, prioritizing content depth and presentation to reflect the complexity of the generated game.
Experiment
Seven frontier coding agents were evaluated on an interaction-grounded benchmark that assesses end-to-end game generation through rendered gameplay across mechanics, content depth, functional visuals, and presentation. The experiments validate the role of visual feedback in iterative debugging, the limited benefit of excessive command-line tooling, and the reliability of an automated playability judge, revealing that agents frequently produce runnable prototypes but consistently struggle to assemble coherent, polished games. Visual interaction proves essential for correcting misaligned gameplay states while raw execution volume yields diminishing returns, and the automated judge demonstrates stable scoring with only mild permissiveness compared to human annotators. These findings confirm that mechanical functionality remains loosely coupled with visual polish and content depth, ultimately demonstrating that reliable creative software generation requires interaction-grounded assessment rather than traditional static code evaluation.
The the the table compares coding agent configurations across diverse game genres and evaluation rubrics, revealing that core mechanics are consistently stronger than content depth and presentation. Top models like Opus-4.7 and GPT-5.5 achieve higher overall scores compared to others, but even they struggle to produce reliable end-to-end game generation. The data highlights a persistent gap between producing runnable code and creating visually polished, complete games. Core mechanics scores are consistently higher than those for content depth and presentation across the leading agents. There is a significant performance gap between the top models and lower-performing agents like DeepSeek-V4-Pro. Even the best configurations fail to consistently realize requested mechanics, visual states, and presentation quality.
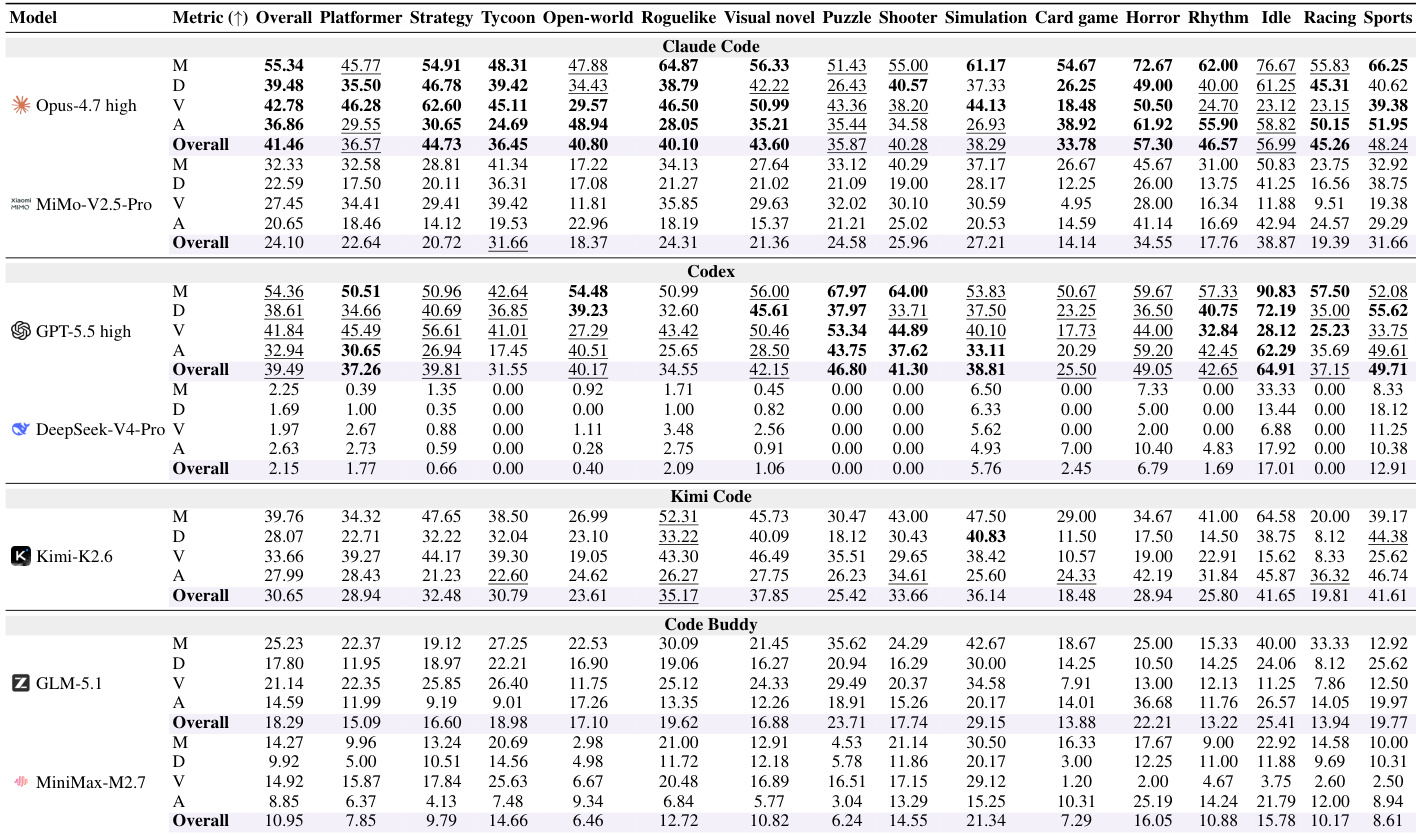
The the the table presents a preliminary calibration comparing human and multimodal judge scores for the Kimi-K2.6 agent across three game families. The judge generally assigns higher overall scores than human annotators, indicating a slight permissiveness. However, the judge is stricter on functional visuals, whereas humans are stricter regarding content depth and art presentation. The multimodal judge is slightly more permissive overall than human raters. Humans are stricter on content depth and art presentation, while the judge is stricter on functional visuals. The largest discrepancy between human and judge scores is observed in the Idle game family.
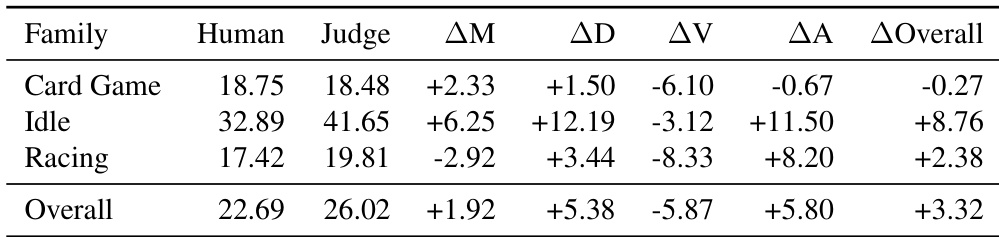
The the the table compares various benchmarks against three essential criteria for game generation evaluation: engine grounding, artifact completeness, and interactive verification. GameCraft-Bench is presented as the most robust option, fulfilling all three requirements by utilizing the Godot engine, demanding complete artifacts, and enabling interactive verification. Other benchmarks show partial capabilities, such as WebGameBench meeting completeness and verification but lacking engine grounding, or GameDevBench offering engine grounding but falling short on completeness and verification. GameCraft-Bench is the sole benchmark listed that satisfies all three evaluation criteria: engine grounding, artifact completeness, and interactive verification. GameDevBench provides engine grounding but is limited to single operations and lacks interactive verification capabilities. Web-based benchmarks like WebGameBench support artifact completeness and interactive verification but do not utilize a specific game engine like Godot.
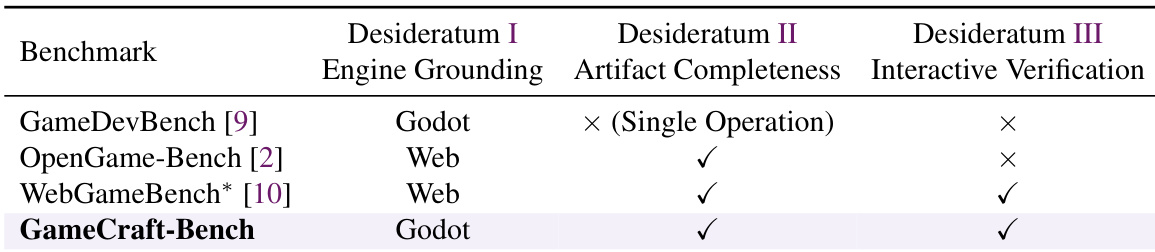
The experiment evaluates seven coding agent configurations on the GameCraft-Bench, revealing that current frontier models struggle with end-to-end game generation. The Opus-4.7 high model under Claude Code achieves the highest overall performance, followed closely by GPT-5.5 high, while DeepSeek-V4-Pro performs significantly worse. Results indicate a consistent gap where agents excel at basic mechanics but falter in delivering complete, polished games with sufficient depth and visual coherence. Top performers achieve their highest scores in Core Mechanics, while struggling more with Content Depth and Art. DeepSeek-V4-Pro yields the lowest overall performance, often failing to produce valid demonstration traces required for evaluation. Even the strongest agents fall significantly short of reliable end-to-end game generation capabilities.
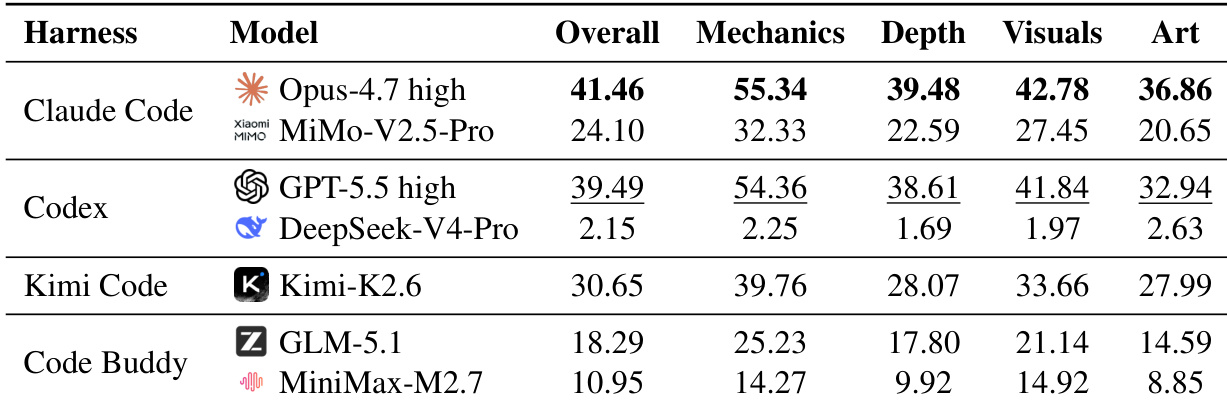
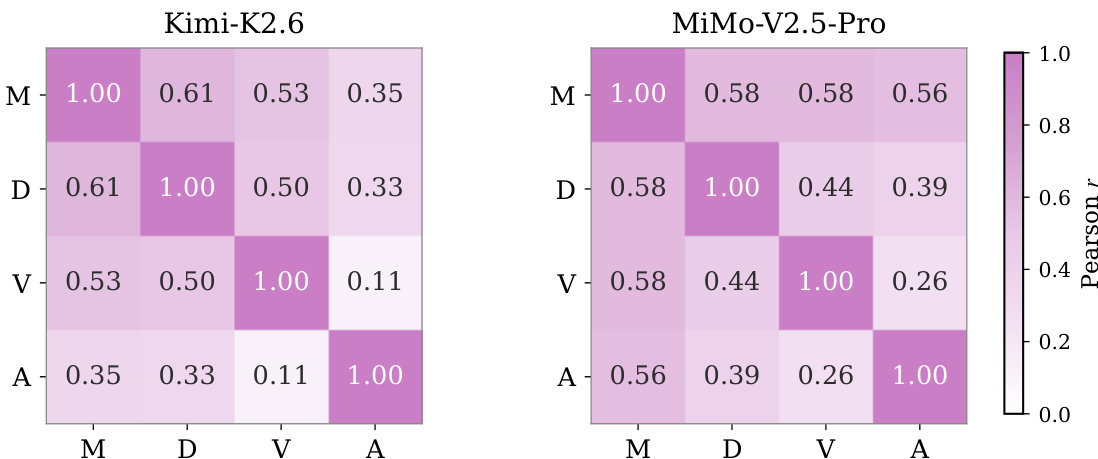
The authors analyze the correlation between rubric categories for Kimi-K2.6 and MiMo-V2.5-Pro to assess the decomposability of game generation ability. The findings reveal that Core Mechanics, Content Depth, and Functional Visuals are moderately correlated, while Art and Presentation is generally less coupled with the other categories. Kimi-K2.6 exhibits a weak correlation between Art and Presentation and Functional Visuals. MiMo-V2.5-Pro shows a more globally coupled pattern with stronger correlations between Art and Presentation and other categories. The moderate coupling of Mechanics, Depth, and Visuals suggests that stronger interaction loops often expose more game state and feedback.
The experiments evaluate multiple coding agents and benchmarks across diverse game genres to assess end-to-end game generation capabilities, validating performance through human and multimodal judge scoring alongside a comprehensive rubric framework. Agent evaluations reveal that while top models consistently excel at implementing core mechanics, they struggle to deliver complete, visually polished games with sufficient depth, highlighting a persistent gap between functional code and production-ready experiences. Benchmark comparisons validate GameCraft-Bench as the most robust evaluation framework due to its unique integration of engine grounding, artifact completeness, and interactive verification. Finally, correlation analysis demonstrates that mechanical and functional visual elements are moderately interdependent, whereas artistic presentation operates more independently, indicating distinct underlying generation dynamics.