Command Palette
Search for a command to run...
プレイフルなエージェント型ロボット学習
プレイフルなエージェント型ロボット学習
概要
現在のagent型ロボットシステムは、実行可能なCode-as-Policyプログラムを記述し、フィードバックを観察し、複数回の試行にわたって行動を修正できるが、依然として主にタスク駆動型である。再利用可能なスキルは明示的な指示が与えられてからでなければ習得されない。本研究では、Playful Agentic Robot Learningを調査する。これは、具現化コーディングagentが、下流タスクが到来する前に、自己主導のプレイを継続的なスキル学習段階として利用するものである。本研究では、プレイ時のスキル習得を目的として設計されたRATs(Robotics Agent Teams)を紹介する。プレイ中、RATsは新規かつ学習可能な探索的タスクを提案し、ロボットコードポリシーの計画と実行、中間進捗の検証、失敗の診断、細粒度なステップレベルのフィードバックを用いた再試行を行い、成功した実行を永続的なコードスキルライブラリに凝縮する。テスト時、agentはこの凍結されたライブラリから関連するスキルを再利用し、新しいタスクの解決を支援する。LIBERO-PROおよびMolmoSpacesにおける実験は、プレイ学習されたスキルが、ノープレイおよびランダムプレイのベースラインと比較してホールドアウト下流タスクの性能を向上させることを示している。LIBERO-PROおよびMolmoSpacesにおいて、それぞれCaP-Agent0に対して20.6および17.0パーセントポイントの向上が観測された。さらに、学習されたスキルは、基盤モデルのファインチューニングを行うことなく、これらを単にコンテキストに取得するだけで他の推論時のCode-as-Policy agentsに組み込むことができ、RoboSuiteおよび実世界転移をそれぞれ8.9および8.8ポイント向上させる。
One-sentence Summary
The authors introduce RATs (Robotics Agent Teams), a playful agentic robot learning framework where autonomous coding teams engage in self-directed play to distill successful executions into a persistent skill library, yielding 20.6 and 17.0 percentage-point gains over CaP-Agent0 on LIBERO-PRO and Molmo Spaces, while enabling fine-tuning-free transfer to other Code-as-Policy agents that improves RoboSuite and real-world performance by 8.9 and 8.8 points, respectively.
Key Contributions
- This work introduces RATs, a Robotics Agent Teams framework that enables embodied coding agents to autonomously propose and execute self-directed exploratory tasks during a play phase prior to downstream instructions.
- The approach replaces reactive task-following with proactive skill discovery by continuously verifying intermediate progress, diagnosing failures, and distilling successful executions into a persistent code skill library for later retrieval.
- Evaluations on LIBERO-PRO and MolmoSpaces demonstrate that play-learned skills improve held-out downstream tasks by 20.6 and 17.0 percentage points over CaP-Agent0 baselines, while plug-and-play retrieval into other Code-as-Policy agents increases RoboSuite and real-world transfer performance by 8.9 and 8.8 points without model fine-tuning.
Dataset
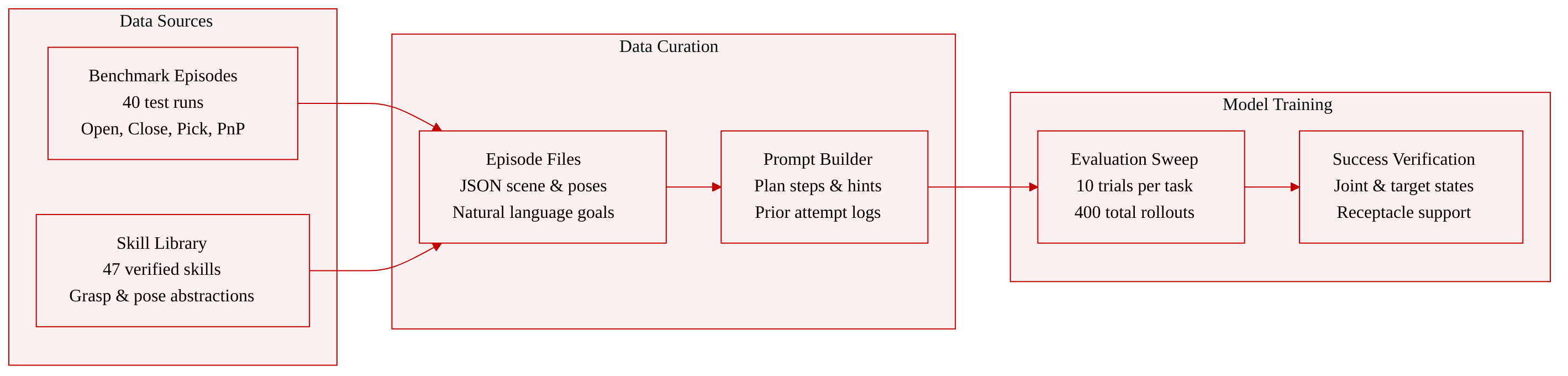
- Dataset Composition and Sources: The authors use a compact, held-out subset of the MolmoSpaces benchmark paired with the LIBERO skill library. The benchmark data originates from four upstream task variants (Open-v1, Close-v1, Pick-v2-classic, and PnP-v2), while LIBERO supplies verified perceptual and manipulation abstractions.
- Subset Details: The evaluation set contains 40 test episodes, randomly sampled at ten per task type across 37 distinct houses. Each episode is stored in a JSON file that records the scene dataset, house index, Franka initialization parameters, object poses, task state, natural-language referral expressions, and camera specifications. The LIBERO library provides 47 learned skills, which the authors leverage as reusable abstractions for robot control.
- Data Usage and Processing: The authors reserve this subset strictly for evaluation and run a main sweep of ten trials per task, yielding 400 total rollouts. They use the data to benchmark RATS against direct code synthesis approaches. Task success is computed via a
judge_success()predicate that validates joint states for articulated tasks, target states for pick tasks, and receptacle support for pick-and-place tasks. - Metadata and Prompt Construction: The authors build iterative agent prompts directly from LIBERO experiment logs. Each prompt template includes structured placeholders for the natural language goal, intended plan steps, affordance hints, executed code, and runtime execution standards. To support self-correction, they append a chronological log of prior attempts, complete with diagnostic notes and associated images, enabling the model to refine its strategy across repeated trials.
Experiment
png]]
the table: MolmoSpaces ablation over play strategy and test-time system. All play-based variants use 50 play iterations. All play-time skills are learned by the proposed RATs system.

average success rate from 21.0% to 25.8%, with the largest gain on closing tasks. When the same learned skills are used by the full RATs execution system, performance improves more substantially, from 32.8% without play to 38.0% with Curious Play. These results suggest that play-time skill learning and the structured RATs test-time execution system provide complementary benefits: the learned skill library alone can improve a standard Code-as-Policy agent, while the full execution system is better able to retrieve, verify, and compose those skills for downstream tasks.
- E.2 Token Cost Analysis
Because RATs relies heavily on Large Language Models (LLMs) for task proposal, planning, code generation, and failure diagnosis, the paper provide a detailed analysis of the token consumption during both the autonomous play phase and the test-time evaluation phase. All LLM calls documented in this section utilized gpt-5.5.
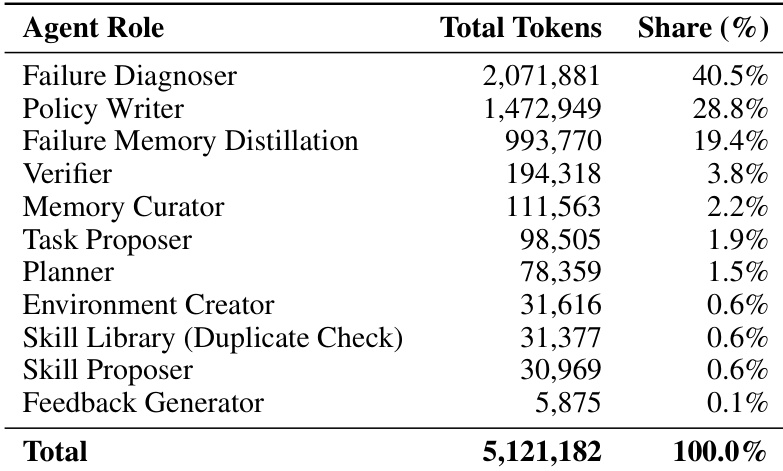
Play-Time Token Consumption. the paper analyzed a play-mode run in the libero_spatial environment. Over the play iterations, where each iteration is budgeted with a maximum of five attempts, token consumption is heavily skewed toward failed iterations that exhaust the retry budget. A component-wise breakdown in the table shows that the Write-Execute-Verify-Diagnose loop is the primary cost driver. This indicates that while intrinsic task proposal is relatively token-efficient, extracting diagnostics and revising policies from repeated physical failures remains the dominant computational expense during play.
Compute-Matched Test-Time Comparison. To ensure a fair comparison, the paper account for the upfront token cost incurred by RATS during autonomous play. A full 50-iteration play phase consumes approximately 30M tokens. the paper amortize this play-time cost across the 60 held-out tasks in LIBERO-PRO.
The baseline CAP-AGENT0 consumes approximately 1.6M tokens per task under a standard 10-turn retry budget. Adding the amortized play-time token cost of RATs to this baseline grants CAP-AGENT0 a larger test-time compute budget, allowing it to run for roughly 15 turns per task. the paper therefore evaluate a compute-matched baseline, CAP-AGENT0 with a 15-turn budget, and compare it against the standard 10-turn CAP-AGENT0 agent augmented with the skill library learned by RATs through Curious Play. This comparison isolates whether the same additional token budget is more useful when spent reactively on extra test-time retries or proactively on play-time skill acquisition.
the table: Play-time token consumption by each agent component (10 iterations).

the table: Compute-matched performance comparison on LIBERO-PRO. The CAP-AGENT0 (15 turns) baseline is granted additional retry budget at test time to match the amortized token cost that RATs spent during play-time. The CAP-AGENT0 + RATs Skills row uses the standard 10-turn CAP-AGENT0 test-time system, with skills learned from 50 iterations of Curious Play.
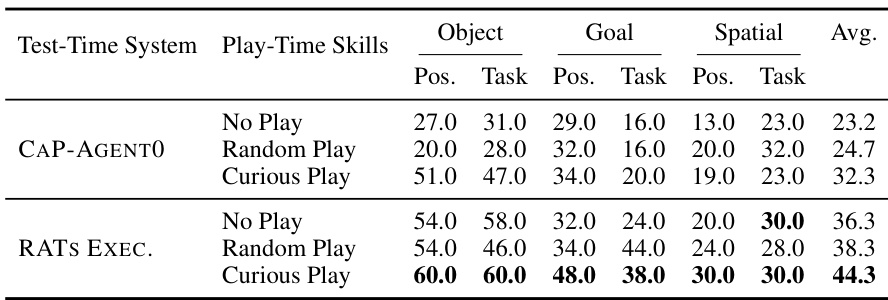
As shown in the table, simply allocating more test-time compute to the baseline yields only modest improvements, increasing average success from 23.2% to 26.0%. In contrast, spending the comparable compute budget proactively during play-time and then reusing the learned skills with the same 10-turn CAP-AGENT0 test-time system improves average success to 32.3%. This result indicates that the gain does not come merely from giving the agent more inference-time retries. Instead, play-time computation is more effective when it is distilled into a reusable skill library that can be retrieved and composed for held-out tasks.
- F.1 Agent I/O Summary
the table enumerates the inputs and outputs of the agents used by RATs.
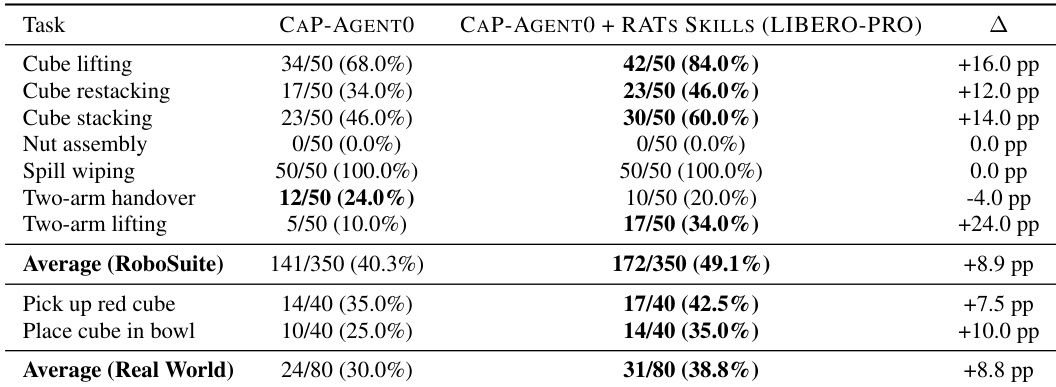
The authors evaluate the cross environment transfer of skills learned through autonomous play in LIBERO-PRO to a separate simulation environment, RoboSuite, as well as a physical robot. Results indicate that integrating the play learned skill library into the baseline agent consistently improves performance across most manipulation tasks. The system demonstrates particularly strong gains in lifting operations, while showing neutral effects on certain assembly and wiping tasks. Additionally, the learned skills successfully transfer to real world scenarios, yielding clear improvements in physical manipulation success. Skills learned from single arm simulation play effectively transfer to a distinct two arm collaborative lifting task. The augmented agent achieves substantial performance gains across most RoboSuite manipulation benchmarks. Play learned capabilities also improve success rates on preliminary real world physical robot tasks.
The authors analyze the token consumption distribution across different agent roles during the autonomous play phase. The results indicate a heavy skew toward failure diagnosis and policy writing, which collectively account for the vast majority of computational overhead. In contrast, auxiliary components such as task proposing, planning, and verification consume a comparatively minor fraction of the total tokens. Failure diagnosis consumes the largest proportion of tokens, highlighting it as the primary computational expense. Policy writing and memory distillation follow as the next most significant token consumers. Auxiliary roles like task proposing and verification account for a minimal fraction of the overall token budget.
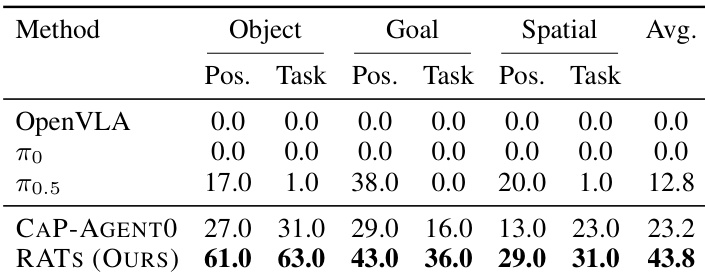
The authors evaluate their proposed framework against several baseline methods on a benchmark testing object, goal, and spatial generalization. Results demonstrate that the proposed method significantly outperforms all compared approaches, achieving the highest success rates across every tested category and perturbation type. The performance gap is particularly pronounced when compared to vision-language model baselines, which show negligible success on these tasks. The proposed method achieves superior performance across all evaluated generalization splits, including object, goal, and spatial categories. Performance improvements are consistent across both initial position swaps and task perturbations. The system substantially outperforms vision-language model baselines, which show negligible success rates on the same tasks.
The authors evaluate the transfer of skills learned through simulated play in MolmoSpaces to real-world manipulation tasks. They compare a standard Code-as-Policy agent against the same agent augmented with these play-learned skills on tasks involving object rearrangement and articulated-object interaction. The results demonstrate that integrating these acquired skills substantially boosts the agent's success rate across both tested real-world scenarios. Augmenting the baseline agent with skills learned from simulated play enables successful execution of complex object rearrangement tasks that the standard agent fails to complete. The skill-augmented system shows marked improvements in handling articulated objects, significantly increasing success rates for drawer manipulation compared to the baseline. Across the evaluated real-world tasks, the integration of play-learned capabilities yields a substantial overall performance gain, highlighting the effectiveness of transferring simulated skills to physical hardware.

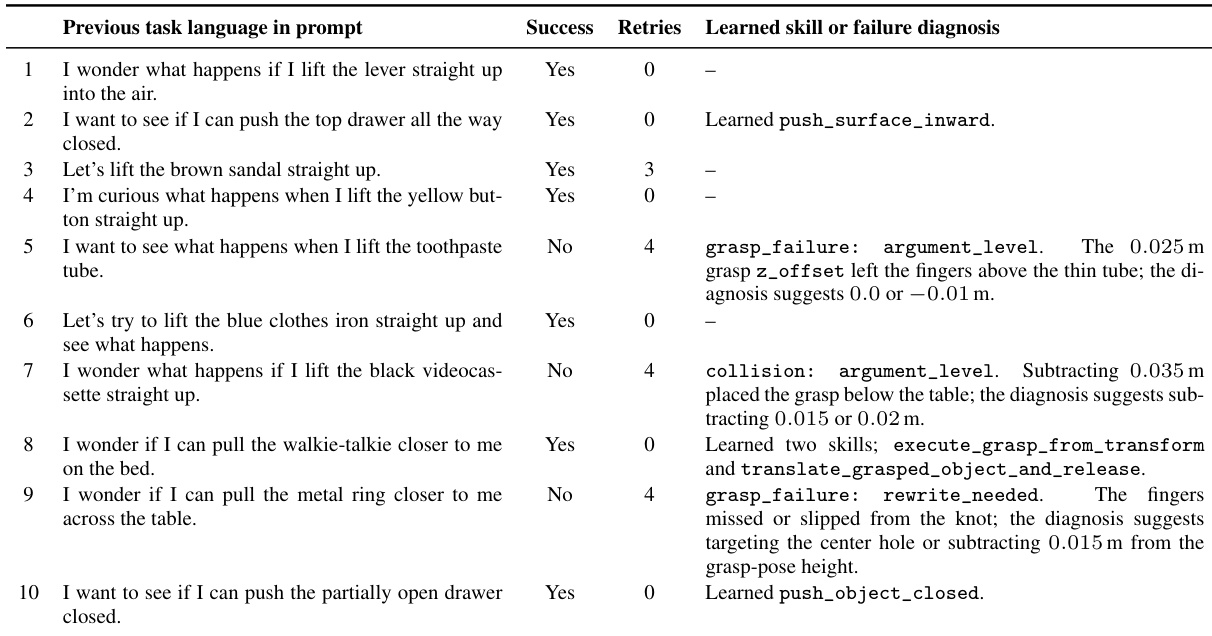
The the the table documents a sequence of manipulation attempts where the agent proposes tasks, executes them, and records outcomes. Successful trials often require no retries and frequently result in the creation of new reusable skills, whereas difficult or failed trials yield detailed diagnostic feedback that suggests specific parameter adjustments or code rewrites. This iterative cycle demonstrates how the system accumulates capabilities and refines its execution strategy based on direct physical feedback. Successful tasks frequently achieve completion with no retries and contribute directly to the growing skill library. Failed attempts generate detailed diagnostic feedback that identifies specific execution issues, such as incorrect grasp positioning or collision risks. The system iteratively builds a diverse set of learned skills and failure memories by varying task objectives and refining execution parameters based on prior outcomes.
The evaluation setup tests an autonomous play framework across simulation and physical environments to validate cross-environment skill transfer, computational efficiency, and spatial generalization. Integrating play-learned capabilities consistently enhances baseline agent performance across diverse benchmarks and real-world tasks, particularly improving complex lifting and articulated object manipulation while demonstrating robust transfer to distinct hardware setups. Computational analysis reveals that failure diagnosis and policy generation dominate token usage, highlighting the system's reliance on iterative feedback for skill accumulation. Overall, the approach successfully builds a diverse capability library through direct physical interaction, substantially outperforming vision-language baselines and establishing a reliable pathway for scalable sim-to-real skill acquisition.