Command Palette
Search for a command to run...
近接政策最適化の領域:プロンプトにおける教師、勾配ではない
近接政策最適化の領域:プロンプトにおける教師、勾配ではない
概要
知識蒸留は教師の能力を小さな学生へ転移させるが、小規模学生の領域では脆い。はるかに大きな教師からのロジットを模倣するように学生を強制すると、教師の最も鋭いモードに集中してしまい、学習コーパス外のベンチマークファミリーにおける汎化性能が損なわれる。強化学習(RL)は、学生自身のロールアウト上で学習を行うことで、ロジットの模倣を回避する。しかし、すべてのロールアウトが失敗し(ゼロアドバンテージを生成し、静かに破棄される)質問において、より強力な教師の応答をポリシー勾配に注入すると、オンポリシー仮定を破り、ドリフトを引き起こす。ヴィゴツキーの近接発達領域に着想を得た本手法は、教師をポリシー勾配ではなくプロンプト内に保持する近接政策最適化(ZPPO)を提案する。困難な質問において、ZPPOは2つの再構成されたプロンプトを構築する。1つは二値候補付加質問(BCQ)で、正解の教師応答と不正解の学生応答を匿名化された候補として対にし、学生がこれらを判別する必要がある。もう1つは負の候補付加質問(NCQ)で、学生の誤ったロールアウトを1つのプロンプトに集約し、それらが共有する失敗モードを浮き彫りにする。プロンプトリプレイバッファは、各困難な質問が卒業する(学生におけるその質問の平均ロールアウト精度が半分(50%)に達する)か、有限の容量下でFIFO(先入れ先出し)方式で除外されるまで、各質問を循環させる。これにより、学生の現在の近接発達領域内でBCQとNCQが増幅される。27Bの教師を用い、ビジョン言語モデルとしてポストトレーニングされた4つの学生スケール(0.8B-9B)のQwen3.5ファミリーにおいて、31のベンチマークスイート(VLM 16、LLM 10、Video 5)で評価した結果、ZPPOはオフ/オンポリシー蒸留およびGRPOを上回り、最も小さなスケールで最大の改善を示した。
One-sentence Summary
Zone of Proximal Policy Optimization (ZPPO) addresses the brittleness of logit imitation and the on-policy drift of reinforcement learning by routing teacher guidance into prompts instead of gradients, utilizing Binary Candidate-included Questions to pair correct teacher responses with incorrect student outputs as anonymized candidates and Negative Candidate-included Questions to aggregate student failures, thereby enabling small student models to learn through targeted prompt discrimination without violating policy assumptions.
Key Contributions
- Introduces Zone of Proximal Policy Optimization (ZPPO) to overcome small-student distillation brittleness and policy drift by relocating teacher guidance from the policy gradient directly into the prompt. This architecture ensures that every token processed by the policy gradient remains student-generated, thereby preserving strict on-policy training dynamics.
- Dynamically constructs two reformulated prompts for challenging questions that yield zero advantage during reinforcement learning. These include Binary Candidate-included Questions (BCQ) that pair anonymized correct teacher responses with incorrect student rollouts for discrimination, and Negative Candidate-included Questions (NCQ) that aggregate failed student attempts to surface shared failure modes.
- Extends reinforcement learning post-training across math, science, broad knowledge, and multimodal reasoning domains while circumventing the generalization collapse typical of small-student regimes. The framework maintains on-policy guarantees through dynamic candidate generation and a targeted prompt replay buffer that amplifies reformulated prompts within the student's zone of proximal development.
Introduction
Efficiently post-training compact vision-language and language models for complex reasoning is essential for deploying scalable AI, yet existing methods struggle to transfer knowledge effectively. Knowledge distillation becomes brittle for smaller students, often triggering memorization and poor generalization, while standard RL post-training silently discards prompts where the model consistently fails due to zero group advantage. Hybrid approaches that splice teacher responses into the policy gradient violate on-policy assumptions and induce severe drift, whereas prompt-based scaffolding typically relies on static hints that encourage shortcut copying. The authors leverage a prompt-centric framework called Zone of Proximal Policy Optimization to bypass these bottlenecks. By reformulating failed prompts with teacher and self-generated candidates and replaying them, the method transfers teacher knowledge exclusively through the prompt, ensuring all gradient updates remain strictly on-policy while dynamically scaffolding the student within its current learning frontier.
Dataset
- Dataset Composition & Sources: The authors construct ZPPO-77K, a multimodal reinforcement learning corpus containing approximately 77,000 triples of input images, text questions, and gold answers. The data is aggregated from two public repositories: the Vero-600k collection, which spans 34 sub-datasets across STEM, chart and OCR, and general visual question answering, and the MMFineReason-SFT-586K collection, a chain-of-thought corpus annotated with a per-sample success rate generated by a 4B teacher model.
- Subset Details & Filtering: The authors organize the corpus into two tiers to balance reasoning depth and auxiliary knowledge. Tier 1 prioritizes direct reasoning tasks like mathematics and diagram analysis, capping each sub-dataset at 2,800 samples. Tier 2 covers auxiliary grounding and recognition tasks, capping each at 1,400 samples. To emphasize genuinely difficult problems, the authors discard any MMFineReason examples where the 4B teacher model achieved a success rate above 0.5. Cross-source duplicates are resolved by prioritizing the Vero repository, while per-sample filters enforce a maximum answer length of 512 characters and a minimum image resolution of 100 by 100 pixels.
- Training Usage & Mixture Strategy: The authors use this curated dataset to train the student policy through reinforcement learning. By applying tier-based caps, they construct a controlled mixture that heavily weights complex multimodal reasoning over general recognition. During training, the model generates rollouts using high-temperature sampling to encourage exploration, while a standardized prompt template forces an internal reasoning process followed by a strictly formatted final answer.
- Input Processing & Evaluation Pipeline: The authors apply consistent image scaling constraints across the pipeline, requiring inputs to stay within a 256 by 32 by 32 to 1280 by 32 by 32 pixel range. They strip all task-specific formatting instructions from upstream prompts and apply a unified RL closer during both training and evaluation. This ensures the policy optimizes against the exact answer-extraction rules it encounters during testing, with evaluation metrics relying on deterministic parsers that fall back to a dedicated judge model only when strict formatting cannot be parsed.
Experiment
Evaluated across LLM, VLM, and video benchmarks at multiple model scales, the main experiments validate that ZPPO consistently enhances generalization where standard reinforcement learning and distillation methods often degrade performance. Component ablations confirm that while prompt replay alone is insufficient, pairing it with contrastive candidate selection and collective negative failure analysis yields a super-additive learning signal that sustains exploration on difficult questions. Training dynamics and candidate audits further validate that the reformulation strategy extracts actionable insights from previously unrecoverable errors without relying on trivial answer matching or off-policy shortcuts. Collectively, these findings demonstrate that the method successfully bridges the capability gap between smaller students and larger teachers, delivering robust cross-domain improvements that scale with model capacity.
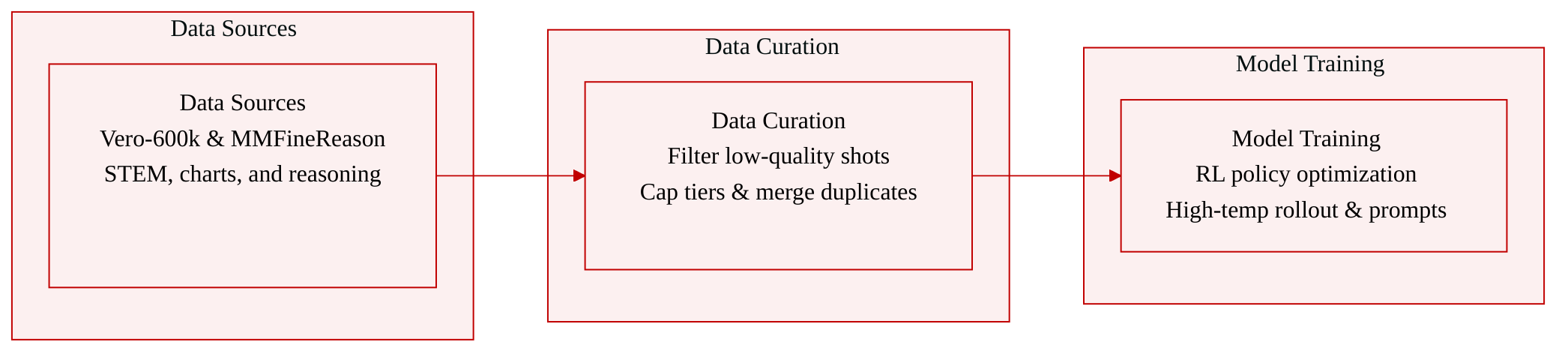
The experiment evaluates multiple training strategies on vision-language models across sixteen diverse benchmarks. The results demonstrate that the proposed ZPPO method consistently outperforms alternative approaches, including policy distillation and standard reinforcement learning variants. This superior performance is observed across both smaller and larger model scales, indicating robust generalization capabilities. ZPPO achieves the highest average performance across all benchmarks compared to distillation and GRPO methods. The method shows consistent improvements on individual benchmarks, with positive gains observed in nearly every category. Scaling up the model size preserves the performance advantage of ZPPO over other training techniques.
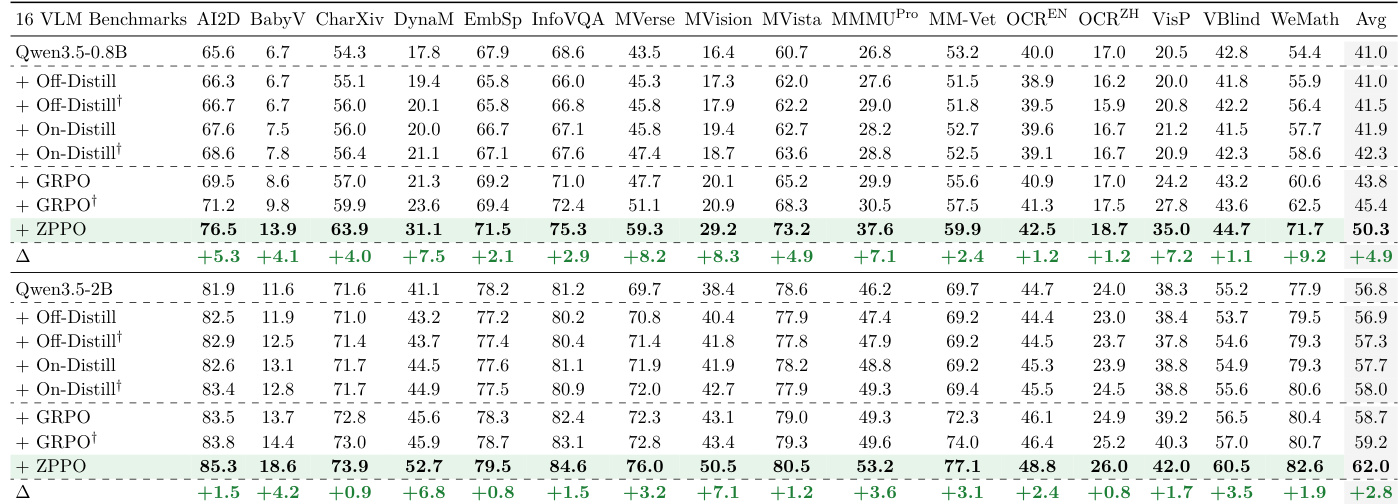
The authors evaluate various training methods on language model and video benchmarks across different model scales. Results demonstrate that distillation techniques generally fail to improve generalization and often degrade performance compared to the base model. In contrast, the proposed ZPPO method consistently yields the largest performance gains across all benchmarks and scales, significantly outperforming both standard reinforcement learning and distillation approaches. Distillation methods typically underperform the base model on video benchmarks and show minimal gains on language tasks. ZPPO achieves the highest average scores across all evaluated benchmarks, with substantial improvements over baseline reinforcement learning. Performance gains from ZPPO are most pronounced at smaller model scales, though they remain robust at larger capacities.
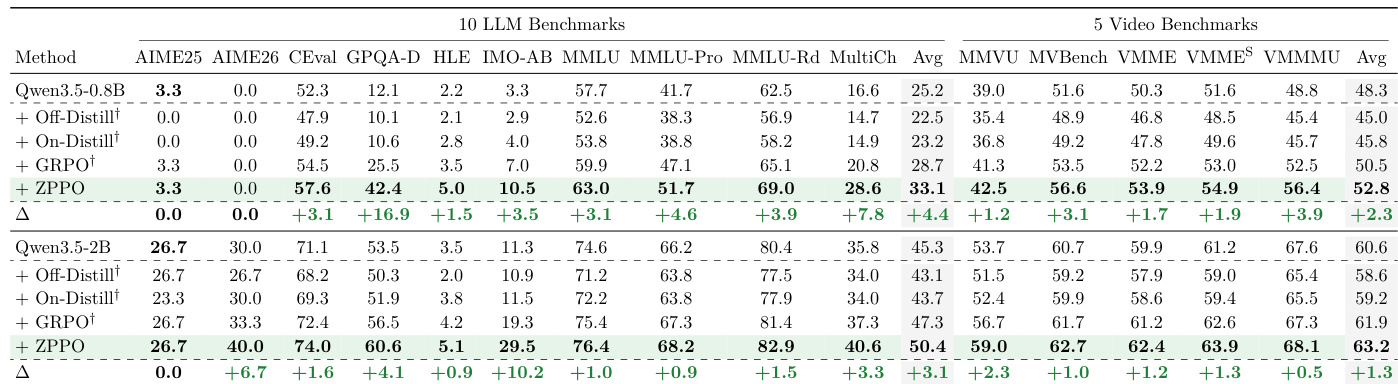
The authors evaluate the proposed ZPPO method against several baseline and ablation variants across different model scales and benchmark types. Results show that ZPPO consistently achieves the highest performance across all categories, demonstrating the effectiveness of combining its core components. The findings highlight the superiority of the full recipe over isolated modifications or simpler prompt-based guidance strategies. ZPPO outperforms all baseline and ablation methods across LLM, VLM, and Video benchmarks for both model sizes. Incorporating BCQ into the GRPO framework yields substantial improvements over the standard GRPO baseline. Prompt-based guidance methods like Hint and Prefix show limited gains compared to the full ZPPO recipe.
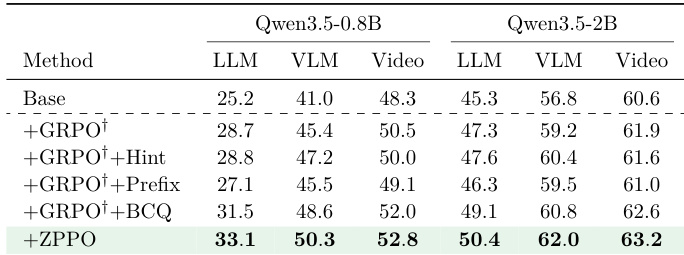
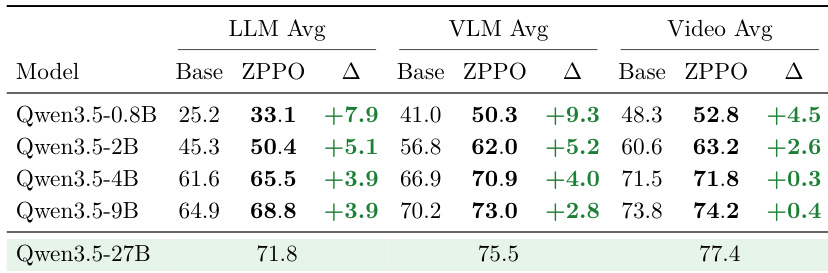
The authors evaluate the ZPPO method across various model scales on LLM, VLM, and Video benchmarks. Results show that ZPPO consistently outperforms the base model across all scales and benchmark families. The performance gains are most pronounced for smaller models, where the gap between the student and teacher is widest, and diminish as model size increases. This indicates that ZPPO is particularly effective at enhancing generalization and learning from hard examples in smaller students. ZPPO consistently improves performance across all model sizes and benchmark categories compared to the base model. Smaller models achieve the largest relative gains, highlighting the method's effectiveness for weaker students. The approach demonstrates strong generalization capabilities, yielding positive results on LLM and Video tasks beyond the training domain.
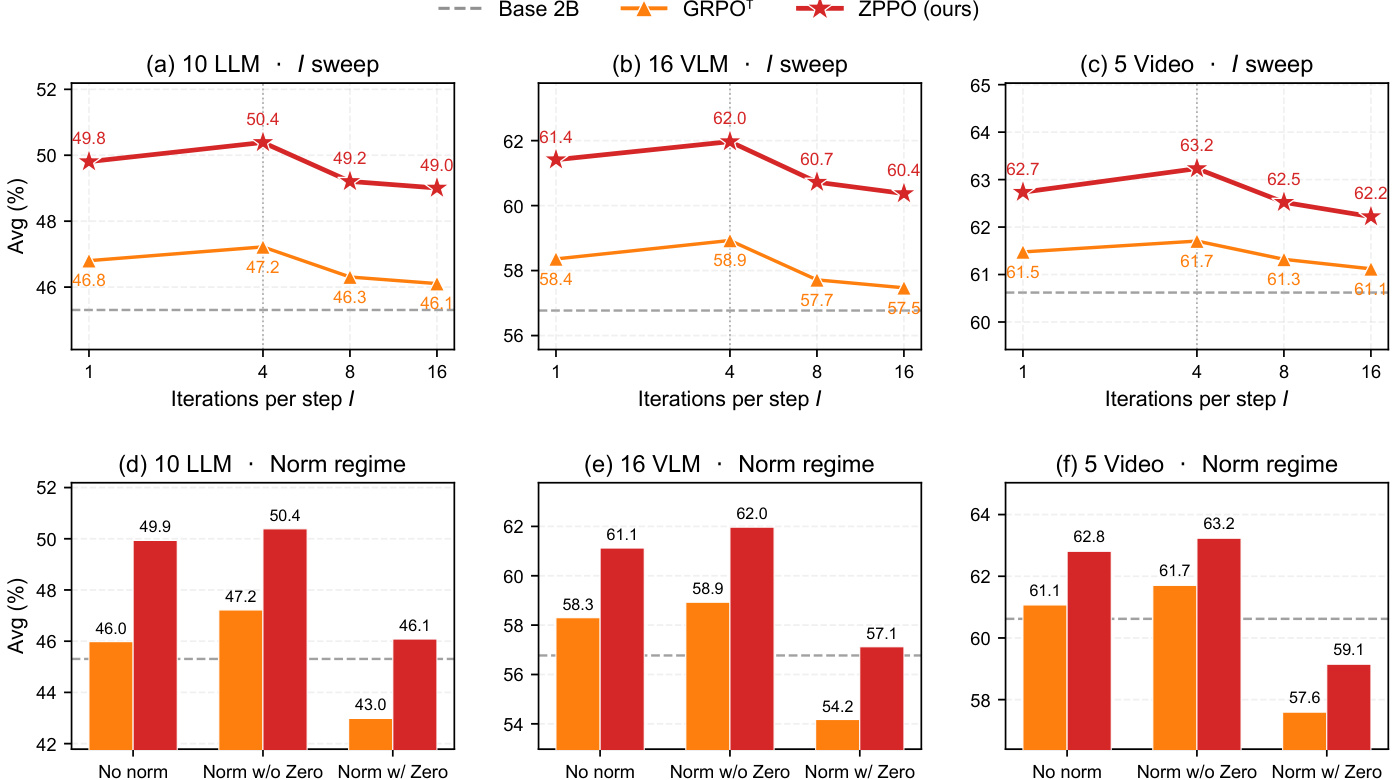
The authors analyze how inner-loop iteration counts and batch normalization choices affect performance across language, vision-language, and video benchmarks. The data shows that moderate iteration settings maximize accuracy, whereas larger counts degrade results by exacerbating policy drift. Furthermore, normalization methods that omit zero-advantage groups consistently surpass both unnormalized and fully inclusive variants. Accuracy peaks at moderate inner-loop iteration counts, with higher values causing performance drops due to off-policy drift. Batch normalization that excludes zero-advantage groups reliably outperforms both unnormalized settings and those that retain trivial groups. The optimal training configuration balances update frequency and stability, delivering consistent gains across all evaluated benchmark families.
The experiments evaluate the proposed ZPPO method against distillation, standard reinforcement learning, and prompt-based baselines across diverse language, vision-language, and video benchmarks at varying model scales. Results demonstrate that ZPPO consistently outperforms all competing approaches, delivering particularly substantial gains for smaller models while maintaining robust improvements at larger capacities. Ablation studies confirm that the full methodological combination is essential, as isolated components yield significantly lower performance. Finally, hyperparameter analysis reveals that moderate inner-loop iterations and batch normalization excluding zero-advantage groups are critical for maximizing training stability and cross-domain accuracy.