Command Palette
Search for a command to run...
DreamOmni3:スクリブルベースの編集と生成
DreamOmni3:スクリブルベースの編集と生成
概要
近年、統合的な生成・編集モデルが、その優れた性能により顕著な成果を上げています。これらのモデルは主にテキストプロンプトを用いて指示に基づく編集および生成を行いますが、言語だけではユーザーが意図する編集位置や細かい視覚的詳細を正確に表現できない場合があります。こうした課題に対応するため、本研究では「スクリブルベースの編集」と「スクリブルベースの生成」という2つのタスクを提案します。これにより、ユーザーがテキスト、画像、および手書きのスケッチを組み合わせたグラフィカルユーザーインターフェース(GUI)上でより柔軟な創造が可能になります。本研究では、データ作成とフレームワーク設計という2つの課題に取り組む「DreamOmni3」を提案します。データ合成パイプラインは、スクリブルベースの編集と生成の2つの部分から構成されています。スクリブルベースの編集については、以下の4つのタスクを定義しました:スクリブルと指示に基づく編集、スクリブルとマルチモーダル指示に基づく編集、画像融合、およびドゥードル編集。DreamOmni2データセットに基づき、編集可能な領域を抽出し、手書きのボックス、円、ドゥードル、または切り抜き画像を重ねることで訓練データを構築しています。一方、スクリブルベースの生成については、以下の3つのタスクを定義しました:スクリブルと指示に基づく生成、スクリブルとマルチモーダル指示に基づく生成、およびドゥードル生成。これらのタスクも、類似のデータ作成パイプラインに従って実施しています。フレームワーク設計においては、複数のスクリブル、画像、指示を含む複雑な編集に対応しづらいバイナリマスクの使用を避け、オリジナル画像とスクリブル画像の両方をモデルに入力する統合入力方式を提案します。異なる色を用いて領域を区別することで、処理を簡素化しつつ、正確な領域の局所化を実現します。また、両方の画像に同じインデックスおよび位置エンコーディングを適用することで、モデルはスクリブル領域を正確に認識しつつ、編集の精度を維持できます。最後に、これらのタスクに対する包括的なベンチマークを構築し、今後の研究を促進することを目的としています。実験結果から、DreamOmni3は優れた性能を達成することが示され、モデルおよびコードは公開される予定です。
One-sentence Summary
The authors from CUHK, ByteDance Inc., and HKUST propose DreamOmni3, a unified model for scribble-based image editing and generation that jointly processes original and scribbled source images with color-coded region differentiation, enabling precise localization and flexible GUI-driven creation beyond text-only instructions, outperforming prior methods in complex, multi-scribble scenarios and advancing interactive image manipulation.
Key Contributions
- We introduce two new tasks—scribble-based editing and generation—that extend unified generation and editing models by incorporating freehand sketches alongside text and image inputs, enabling more intuitive, flexible, and creative user interactions on graphical interfaces.
- We propose a novel joint input framework for DreamOmni3 that feeds both the original and scribbled source images into the model using color-coded scribbles and shared position encodings, allowing precise localization of edit regions without relying on complex binary masks.
- We build the DreamOmni3 benchmark with real-world image data and establish a comprehensive data synthesis pipeline for multiple scribble-based tasks, demonstrating superior performance in editing accuracy and real-world applicability through extensive experiments.
Introduction
The authors leverage recent advances in unified image generation and editing models, which integrate text and image inputs to enable flexible content creation. However, these models often struggle with precise, interactive edits—especially when users need to modify specific regions that are hard to describe with language, involve ambiguous or identical objects, or require creative additions through drawing. To address this, the authors introduce DreamOmni3, a framework that extends unified models with scribble-based editing and generation, enabling users to guide edits and generation via hand-drawn annotations. This approach overcomes limitations of mask-based methods, which rely on precise, often tedious manual segmentation and lack robustness to imprecise inputs. DreamOmni3 introduces a novel data pipeline to generate high-quality, instruction-guided scribble datasets for both editing and generation tasks, and proposes a joint input architecture that processes both source images and colored scribbles while preserving spatial alignment through shared position encodings. The model supports multimodal inputs—including text, images, and scribbles—within a unified framework, ensuring compatibility with existing architectures and enabling complex, context-aware edits. The authors further establish the DreamOmni3 benchmark using real-world data, demonstrating the model’s strong performance in practical, interactive scenarios.
Dataset
- The dataset, named DreamOmni3, is built upon DreamOmni2’s multimodal instruction editing and generation data, extended to include scribbles as instructions for both editing and generation tasks.
- It comprises two main components: a scribble-based editing dataset (70K training samples) and a scribble-based generation dataset (47K training samples), each structured into distinct task types.
- For editing:
- Scribble and multimodal instruction-based editing includes 32K samples, where Referseg locates objects in reference and target images, and manually designed scribble templates (squares and circles) are pasted onto source and reference images.
- Scribble and instruction-based editing has 14K samples, derived by removing the reference image from the above but retaining the scribble and adding object descriptions in the instruction.
- Image fusion involves 16K samples, created by removing the target object via instruction-based editing, cropping it from the reference image using Referseg, resizing, and pasting it into the source image.
- Doodle editing contains 8K samples, where Referseg identifies the object and a dedicated model converts it into an abstract sketch, avoiding Canny edge detection due to imperfect user input.
- For generation:
- Scribble-based multimodal instruction generation has 29K samples, with scribbles placed on a blank white canvas to guide object placement and attribute generation.
- Scribble-based instruction generation includes 10K samples, similar to the above but without a reference image and with object descriptions in the instruction.
- Doodle generation has 8K samples, where abstract sketches are placed on a white canvas to guide the model in generating corresponding objects and background.
- All data is processed using a joint input scheme that encodes both source and scribbled images with the same method, ensuring pixel alignment and compatibility with prior DreamOmni2 data.
- The training split uses all available samples for training, with no explicit validation or test splits mentioned—evaluation is conducted via the newly introduced DreamOmni3 benchmark.
- The benchmark uses real-world images and covers all seven task types, with evaluation based on four criteria: instruction accuracy, visual consistency (appearance, objects, attributes), absence of severe artifacts, and alignment with doodle regions.
- Evaluation leverages VLMs (e.g., GPT-Image-1) for automated assessment, with results shown to closely match human evaluations, ensuring reliability and real-world relevance.
Method
The authors leverage a unified framework for scribble-based image editing and generation, building upon the DreamOmni2 architecture while introducing a novel joint input scheme to handle freehand sketch instructions. The overall framework, as shown in the figure below, integrates both text and visual inputs through a multimodal model (MM-DIT) that processes a combination of source images, scribbled images, and textual instructions. The core innovation lies in the joint input scheme, which feeds both the original source image and a modified version with scribbles into the model simultaneously. This approach avoids the limitations of binary masks, which become cumbersome when multiple scribbles are present, as each requires a separate mask and complex language-based correspondence. Instead, the joint input uses color-coded scribbles to distinguish regions, enabling simple language instructions to establish correspondences via image indices and scribble colors.
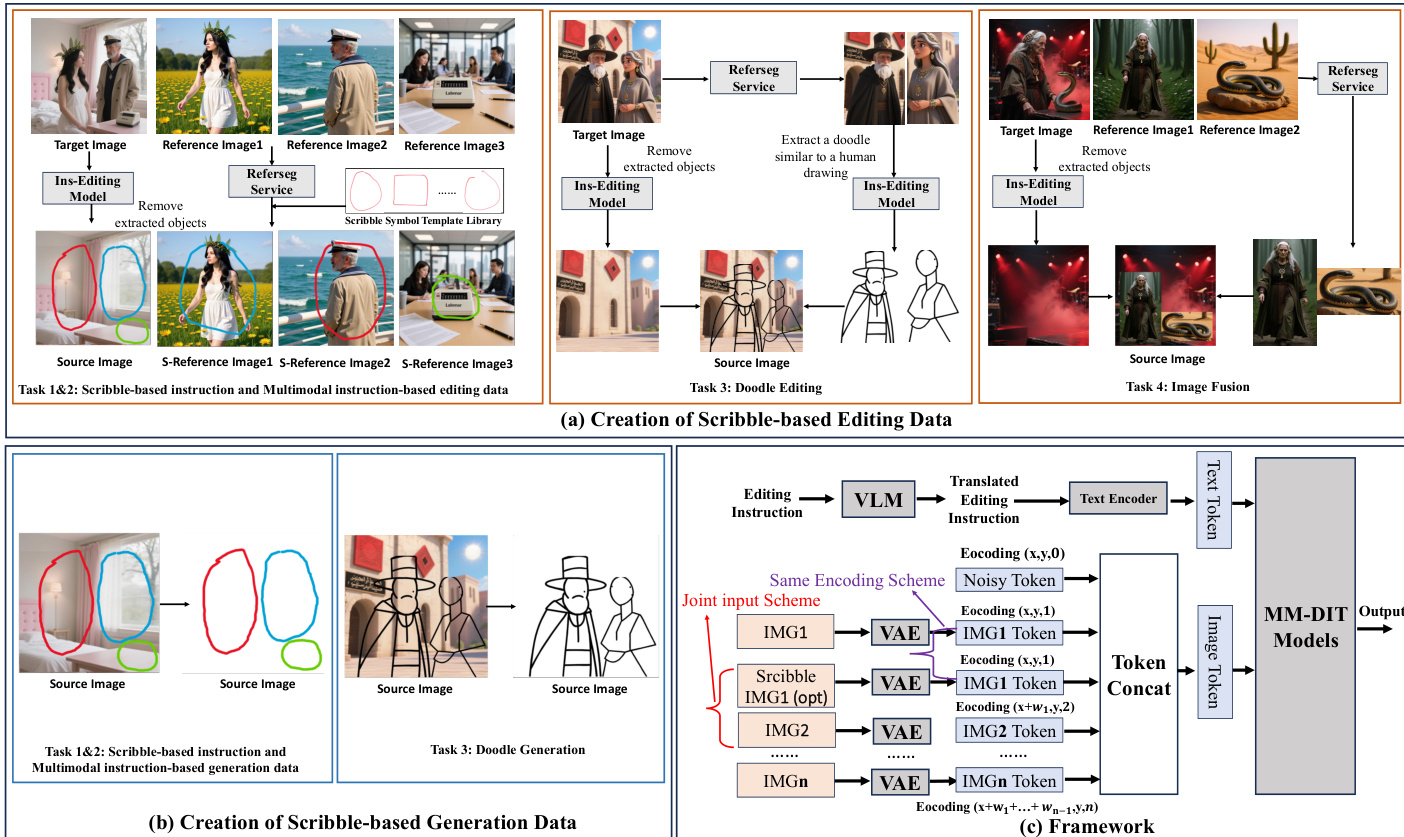
The framework processes inputs through a series of modules. Textual editing instructions are first translated into a structured format by a vision-language model (VLM), which then passes the instruction to a text encoder to generate text tokens. Simultaneously, the source image and the scribbled image (if applicable) are encoded using a Variational Autoencoder (VAE) to produce image tokens. To ensure accurate alignment between the original and scribbled images, both are subjected to the same index and position encoding scheme, which preserves spatial relationships and enables the model to maintain pixel-level consistency in non-edited regions. These encoded tokens are concatenated and fed into the MM-DIT model, which generates the final output. The joint input scheme is applied selectively: during editing tasks where the source image contains scribbles, both the original and scribbled images are input; during generation tasks or when reference images contain scribbles, the joint input is omitted to avoid unnecessary computational overhead. This selective use of the joint input scheme ensures efficiency while maintaining the model's ability to handle complex, multi-scribble editing scenarios.
Experiment
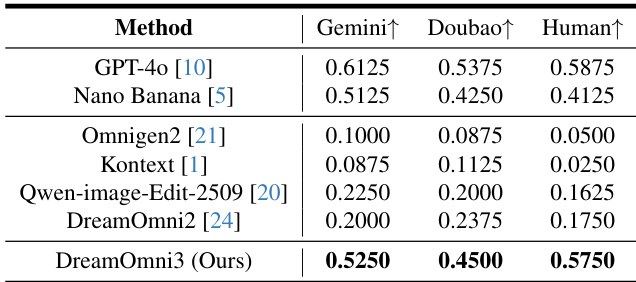
- Evaluated scribble-based editing on DreamOmni3 benchmark using Gemini 2.5, Doubao 1.6, and human assessments (5 reviewers per case); DreamOmni3 achieved the highest pass rates in human evaluation and outperformed open-source models, with results comparable to GPT-4o and Nano Banana, though GPT-4o showed yellowing and pixel mismatches, and Nano Banana exhibited copy-paste effects and proportion errors.
- In scribble-based generation, DreamOmni3 surpassed open-source models (DreamOmni2, Qwen-image-edit-2509) and matched the performance of GPT-4o and Nano Banana, with both human and VLM evaluations confirming its superiority; commercial models still generated unwanted scribbles despite instructions.
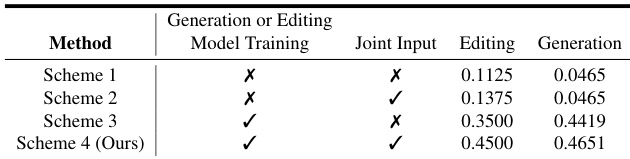
- Joint input experiments demonstrated that training with the custom dataset and using both source and scribbled images as input significantly improved editing performance, especially for pixel-level consistency, while generation benefits were less pronounced due to lower need for exact pixel alignment.
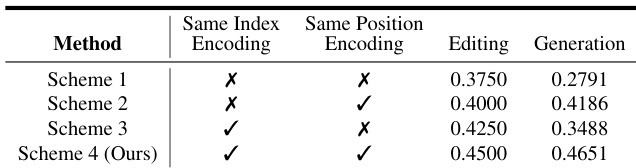
- Index and position encoding experiments showed that using identical encoding for both source and scribbled images yielded the best results, enabling better pixel-level alignment and preserving editing accuracy, while maintaining compatibility with pre-trained capabilities.
The authors compare different joint input schemes for scribble-based editing and generation, showing that training with joint input (source and scribbled images) significantly improves performance. Scheme 4, which uses joint input and training on the custom dataset, achieves the highest success rates in both editing (0.4500) and generation (0.4651), outperforming all other schemes.
Results show that DreamOmni3 achieves the highest pass rates across all evaluation metrics, outperforming both open-source models and commercial models like GPT-4o and Nano Banana in scribble-based editing. The authors use Gemini, Doubao, and human evaluators to assess the success of edits, with DreamOmni3 demonstrating superior accuracy and consistency compared to competing methods.
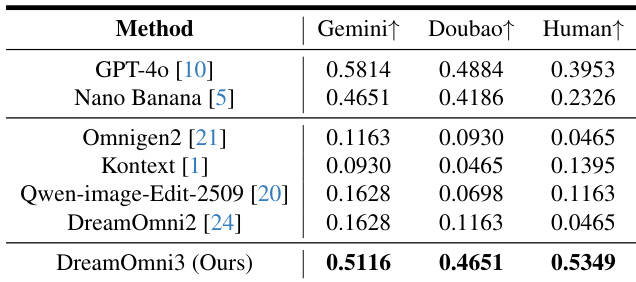
Results show that DreamOmni3 achieves the highest pass rates across all evaluation metrics, outperforming both open-source models and commercial models like GPT-4o and Nano Banana in scribble-based editing. The authors use Gemini, Doubao, and human evaluators to assess the success of edits, with DreamOmni3 demonstrating superior accuracy and consistency compared to competing methods.
Results show that using the same index and position encoding for both source and scribbled images significantly improves performance in both editing and generation tasks. The authors use Scheme 4, which combines joint input with identical encoding, to achieve the highest scores, demonstrating that consistent encoding enhances pixel-level alignment and preserves image details.