Command Palette
Search for a command to run...
SenseNova-MARS:強化学習を活用したマルチモーダルエージェント型推論と検索の実現
SenseNova-MARS:強化学習を活用したマルチモーダルエージェント型推論と検索の実現
概要
視覚言語モデル(VLMs)は、エージェント型の推論を用いて複雑なタスクを処理できるが、その能力は主にテキスト中心の連鎖的思考(chain-of-thought)や孤立したツール呼び出しに限定されている。特に、検索や画像切り取りなどの外部ツールを連携して使用する必要がある、知識集約的かつ視覚的に複雑なシナリオでは、人間のような円滑な動的ツール操作と継続的推論の統合を実現できていない。本研究では、強化学習(RL)を活用してVLMに視覚的推論とツール利用の連携能力を付与する、新しいマルチモーダルエージェント型推論・検索フレームワーク「SenseNova-MARS」を提案する。具体的には、SenseNova-MARSは画像検索、テキスト検索、画像切り取りの3つのツールを動的に統合し、細粒度かつ知識集約的な視覚理解課題に取り組む。強化学習段階では、訓練の安定性を向上させ、ツールの適切な呼び出しと効果的な推論能力を高めるため、バッチ正規化付きグループシーケンス方策最適化(Batch-Normalized Group Sequence Policy Optimization: BN-GSPO)アルゴリズムを提案する。複雑な視覚タスクにおけるエージェント型VLMの性能を包括的に評価するため、高解像度画像を用い、知識集約的かつ検索主導の質問を含む、世界初の検索指向ベンチマーク「HR-MMSearch」を導入する。実験の結果、SenseNova-MARSはオープンソースの検索および細粒度画像理解ベンチマークにおいて最先端の性能を達成した。特に検索指向ベンチマークでは、SenseNova-MARS-8BがMMSearchで67.84、HR-MMSearchで41.64のスコアを記録し、Gemini-3-FlashやGPT-5といったプロプライエタリモデルを上回った。SenseNova-MARSは、効果的かつ堅牢なツール利用能力を提供することで、エージェント型VLMの実現に向けて有望な一歩を踏み出した。本研究分野のさらなる発展を促進するため、コード、モデル、データセットをすべて公開する予定である。
One-sentence Summary
The authors from SenseTime Research, Tsinghua University, and the University of Science and Technology of China propose SenseNova-MARS, a multimodal agentic reasoning framework that integrates reinforcement learning with dynamic tool orchestration—image search, text search, and image cropping—to enable seamless interleaving of visual reasoning and tool use, outperforming proprietary models on knowledge-intensive, high-resolution visual search tasks through the novel BN-GSPO algorithm and the HR-MMSearch benchmark.
Key Contributions
- Existing Vision-Language Models (VLMs) struggle with seamlessly integrating dynamic tool use—such as image and text search or image cropping—into continuous, multi-step visual reasoning, limiting their ability to handle knowledge-intensive and high-resolution visual tasks in real-world scenarios.
- SenseNova-MARS introduces a novel multimodal agentic framework that leverages reinforcement learning to enable interleaved visual reasoning and coordinated tool use, dynamically combining image search, text search, and image crop tools through a unified reasoning process.
- The framework achieves state-of-the-art results on search-oriented benchmarks, scoring 67.84 on MMSearch and 41.64 on the newly introduced HR-MMSearch benchmark, outperforming proprietary models like Gemini-3-Flash and GPT-5, with the proposed BN-GSPO algorithm enhancing training stability and multi-tool coordination.
Introduction
Vision-Language Models (VLMs) have advanced toward agentic reasoning, but prior systems are limited to text-centric chains of thought or isolated tool use, failing to dynamically interleave visual reasoning with multi-tool operations like search and image cropping—critical for knowledge-intensive, high-resolution visual tasks. Existing approaches either focus on search-only or image manipulation-only workflows, lacking integrated, adaptive tool coordination. The authors introduce SenseNova-MARS, a reinforcement learning–driven framework that unifies image search, text search, and image crop tools within a cohesive, multi-turn reasoning process. They propose BN-GSPO, a batch-normalized group sequence policy optimization algorithm that enhances training stability and performance in multi-tool scenarios, and introduce HR-MMSearch, the first benchmark for high-resolution, search-driven visual understanding. Experiments show SenseNova-MARS-8B achieves state-of-the-art results on open-source benchmarks, outperforming proprietary models like Gemini-3-Flash and GPT-5, demonstrating robust, human-like agentic reasoning in complex visual environments.
Dataset
-
The HR-MMSearch benchmark consists of 305 high-resolution 4K images sourced exclusively from recent 2025 events, drawn from three reputable international news outlets: Reuters, the Associated Press (AP), and CNBC. This ensures minimal data leakage from pre-trained VLM knowledge and supports evaluation of genuine visual reasoning.
-
Images are manually categorized into eight high-impact domains: Sports, Entertainment & Culture, Science & Technology, Business & Finance, Games, Academic Research, Geography & Travel, and Others, with each image annotated by three bachelor’s-level annotators.
-
For each image, knowledge-intensive, search-oriented questions are crafted to target small or inconspicuous visual elements—such as text or objects occupying less than 5% of the image area—requiring at least one of three tools: image search, text search, or image crop.
-
A team of three master’s-level experts cross-verify all 305 image-question pairs to ensure label accuracy, question quality, and correct answers.
-
Question difficulty is determined via a pass@8 evaluation protocol using Qwen2.5-VL-7B-Instruct as a proxy agent. Questions where the model fails all eight rollouts are labeled as Hard (188 total), typically requiring three or more tool calls and often involving coordinated use of all three tools. The remaining 117 questions are classified as Easy, generally solvable with one or two tool calls. Difficulty distribution is roughly balanced across domains, with about 60% Hard and 40% Easy samples per category.
-
The cold-start supervised fine-tuning (SFT) phase uses a curated dataset of approximately 3,315 high-quality samples derived from three sources: 1,115 filtered and synthesized trajectories from FVQA, ~2,000 samples from the Pixel-Reasoner Corpus emphasizing pixel-level reasoning, and 200 manually constructed complex reasoning trajectories for multi-step tool use.
-
The reinforcement learning (RL) phase leverages a larger, more diverse dataset: 3,695 remaining FVQA samples, 4,000 samples from DeepEyes-4K for high-resolution analysis, and the full 5,729-sample Visual-Probe dataset to support broad visual reasoning.
-
For evaluation, the authors use HR-MMSearch as the primary benchmark for fine-grained agentic search, supplemented by MMSearch, FVQA-test, InfoSeek, SimpleVQA, LiveVQA, and MAT-Search to cover diverse aspects of real-world information seeking, factual accuracy, and dynamic news reasoning.
-
For visual reasoning, the evaluation includes V* Bench (191 high-resolution, detail-rich images from SA-1B), HR-Bench (800 images at 4K and 800 at 8K resolution to test scalability and detail preservation), and MME-RealWorld (23,599 QA samples across 43 subtasks in OCR, remote sensing, diagrams, video monitoring, and autonomous driving, featuring high-resolution, cluttered scenes).
-
During RL training, a text search pipeline uses local retrieval from a Wikipedia knowledge base to reduce cost, while inference employs live web search via Serper API. Retrieved passages from both modes are uniformly summarized by a Qwen3-32B model before being fed to the main model.
Method
The authors leverage a two-stage training framework to develop an agentic search-reasoning model capable of fine-grained visual analysis for complex, knowledge-intensive tasks. The overall architecture is designed to enable a multimodal agent to interact with a dynamic environment through reasoning and tool use, with the goal of answering natural language queries grounded in high-resolution images. The framework operates within a multi-turn interaction setting, where the agent begins with an initial image and query, and iteratively performs reasoning steps and tool actions—such as text search, reverse image search, or image cropping—until it produces a final answer. The process is structured around a formal task formulation that defines the observation space as the full interaction history, including prior reasoning, tool calls, and their outputs, and the action space as a set of four possible actions: text search, image search, image crop, or producing the final answer. Each turn in the interaction includes a reasoning step followed by a single action, forming an evolving trajectory of information.

As shown in the figure below, the training process consists of two distinct stages. The first stage is a cold-start supervised fine-tuning (SFT) phase, which bootstraps the model's ability to perform multi-tool invocations. This stage uses a small, high-quality dataset of multi-turn interaction trajectories, where each sample consists of a user query and a target reasoning trajectory. The SFT objective is formulated as a standard maximum likelihood loss, optimizing the model to predict the correct sequence of reasoning steps and actions given the input query and interaction history. The second stage employs reinforcement learning (RL) to further refine the model's reasoning and tool-use capabilities. To address the challenges of training in a multimodal, tool-augmented environment—such as varying trajectory lengths, reward magnitudes, and task difficulties—the authors propose a novel algorithm called Batch-normalized GSPO (BN-GSPO). This method applies a two-stage normalization to the advantage estimates: first, group-level standardization within each prompt batch, and then batch-level normalization across the entire minibatch. This normalization stabilizes the learning signal, mitigating biases and variances that can destabilize training. The RL objective is a clipped sequence-level loss that incorporates the normalized advantages and a KL divergence term to prevent overfitting to the reference policy.

The training data for the SFT stage is constructed through a three-phase pipeline, as illustrated in the figure below. The process begins with data mining, where a raw data pool is assembled from existing multimodal QA datasets and expert-annotated pairs. This pool is then filtered to identify hard examples—questions that a baseline model answers correctly only once or fewer times. For these hard samples, a large language model (Gemini-2.5-Flash) is prompted to synthesize complete solution trajectories, including reasoning steps and tool invocations. The synthesized trajectories undergo quality verification, where another model (GPT-4o) checks for format compliance, logical coherence, and answer plausibility. Only the validated trajectories are retained, resulting in a high-quality dataset of approximately 3,000 samples. For the RL stage, the training data is drawn from a combination of existing benchmarks, including FVQA-train, VisualProbe-train, and DeepEyes-4K-train, which provide a diverse mix of factual and high-resolution visual analysis tasks.

The reward model used in BN-GSPO is designed to evaluate the quality of a complete interaction trajectory. The sequence-level reward is a combination of two components: accuracy and format compliance. The accuracy reward measures the semantic agreement between the predicted answer and the ground truth, evaluated using a large language model as a judge. The format reward ensures strict adherence to the interaction protocol, which requires that non-final turns contain a reasoning trace and a single tool call, while the final turn must contain a reasoning trace and the answer. All content must be enclosed within special tags, and all tool calls must conform to a specified JSON schema. This dual-component reward function guides the model to produce both correct answers and well-structured, protocol-compliant trajectories.

The text search pipeline, illustrated in the figure below, is designed to be consistent between training and inference to ensure effective transfer of learned behaviors. During training, a local Wikipedia knowledge base is used to avoid the cost of live web searches. The retrieval process uses the E5-retriever to fetch the top-k passages, which are then summarized in two stages: first, each passage is individually summarized by a Qwen3-32B model, and then a final holistic summary of all passages is generated. This two-stage summarization process ensures that the model learns the core tool-use behaviors on data formatted identically to the live inference setting. During inference, the same summarization process is applied to the results from the Serper Search API, allowing the model to generalize effectively despite never having seen real web search outputs during training. The pipeline also uses Playwright to fetch HTML content and BeautifulSoup to parse it, avoiding JavaScript rendering to maintain efficiency and mitigate bot detection.
Experiment
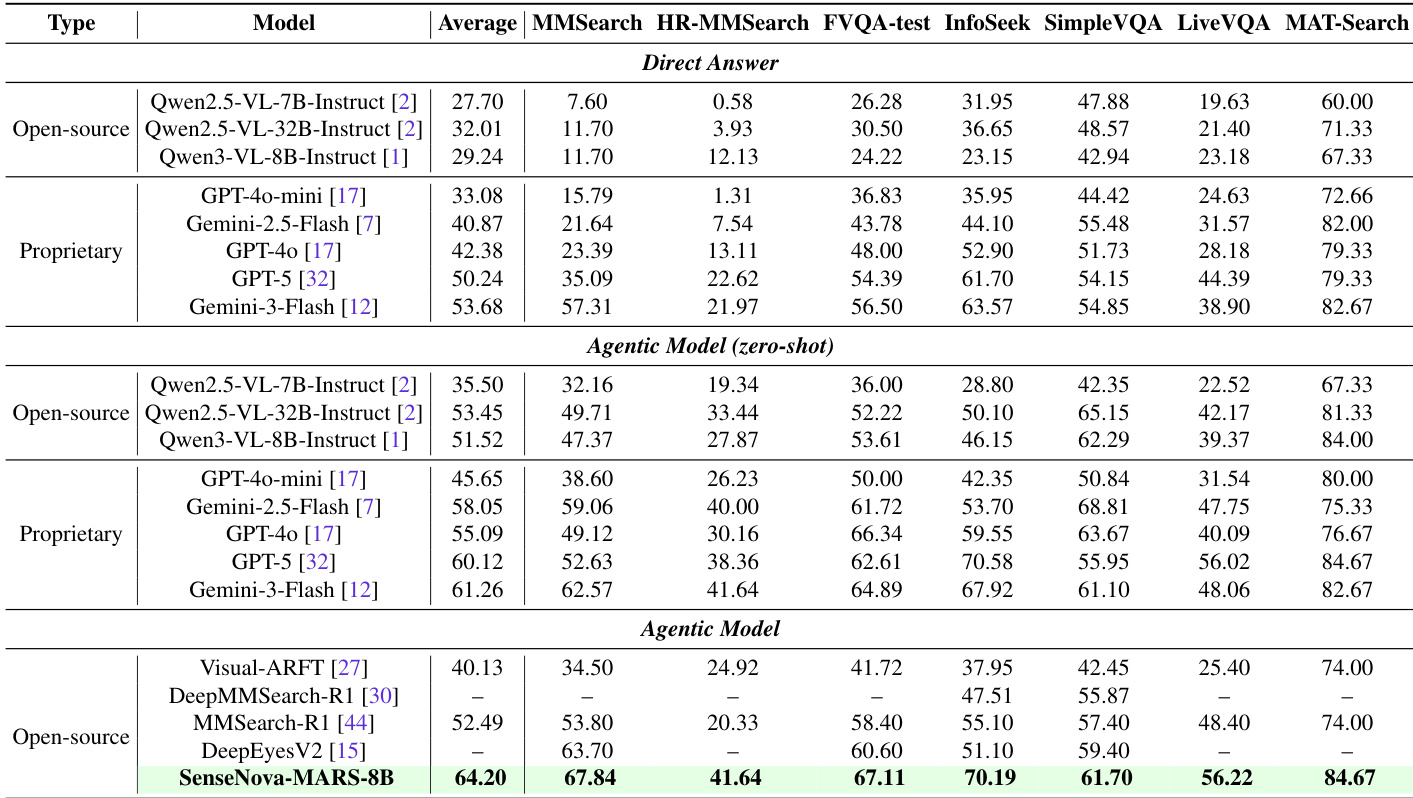
- SenseNova-MARS-8B, trained via a two-stage SFT and RL pipeline using LLaMA-Factory and veRL, achieves state-of-the-art performance among open-source 8B models and surpasses proprietary models like GPT-5, Gemini-2.5-Flash, and Gemini-3-Flash on search-oriented benchmarks, with a 12.68-point average gain over Qwen3-VL-8B and a 11.71-point lead over MMSearch-R1 under the Agentic Model workflow.
- On visual understanding benchmarks, SenseNova-MARS-8B achieves top scores of 92.2 on V* Bench, 83.1 on HR-Bench 4k, 78.4 on HR-Bench-8k, and 67.9 on MME-RealWorld, outperforming existing tool-based models and showing a 4.9-point average improvement over Qwen3-VL-8B.
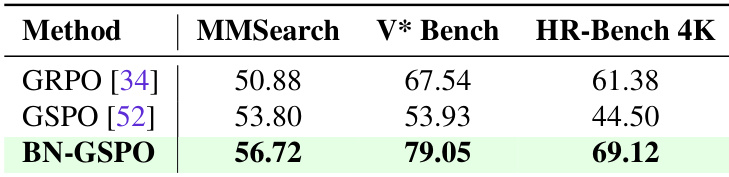
- The proposed BN-GSPO algorithm demonstrates superior stability and balanced performance across search and perception tasks compared to GRPO and GSPO, effectively mitigating reward scale variance in multi-tool RL training.
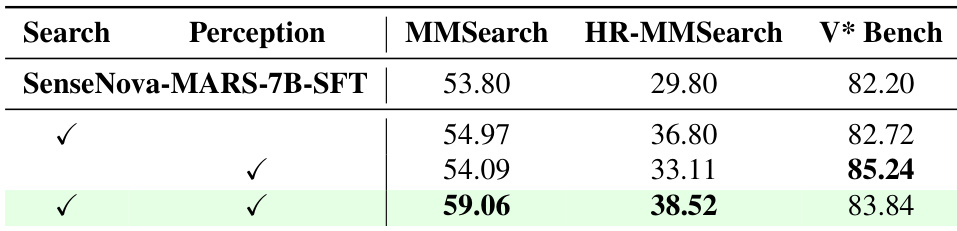
- Hybrid training data combining search and perception tasks is critical, as exclusive training on specialized data leads to overspecialization and degraded performance on cross-domain tasks.
- Tool usage analysis shows that SenseNova-MARS-8B dynamically adapts its strategy—relying on search tools for knowledge-intensive tasks and combining image search and crop for fine-grained analysis—while RL reduces redundant tool calls from ~4 to ~2, improving efficiency.
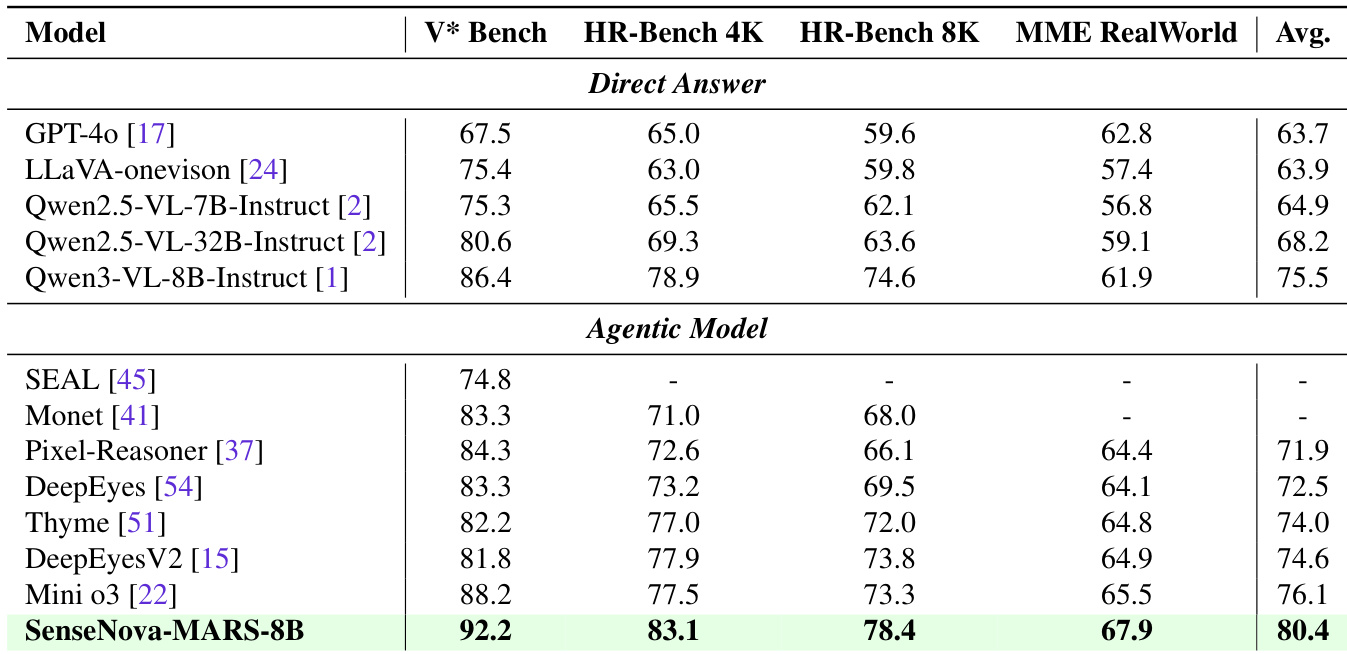
The authors use a two-stage training pipeline combining supervised fine-tuning and reinforcement learning to develop SenseNova-MARS-8B, which achieves state-of-the-art performance on search-oriented benchmarks and outperforms both open-source and proprietary models. Results show that SenseNova-MARS-8B attains the highest accuracy across all evaluated tasks, including MMSearch, HR-MMSearch, and V* Bench, demonstrating its superior capability in integrating external tools and performing fine-grained visual reasoning.
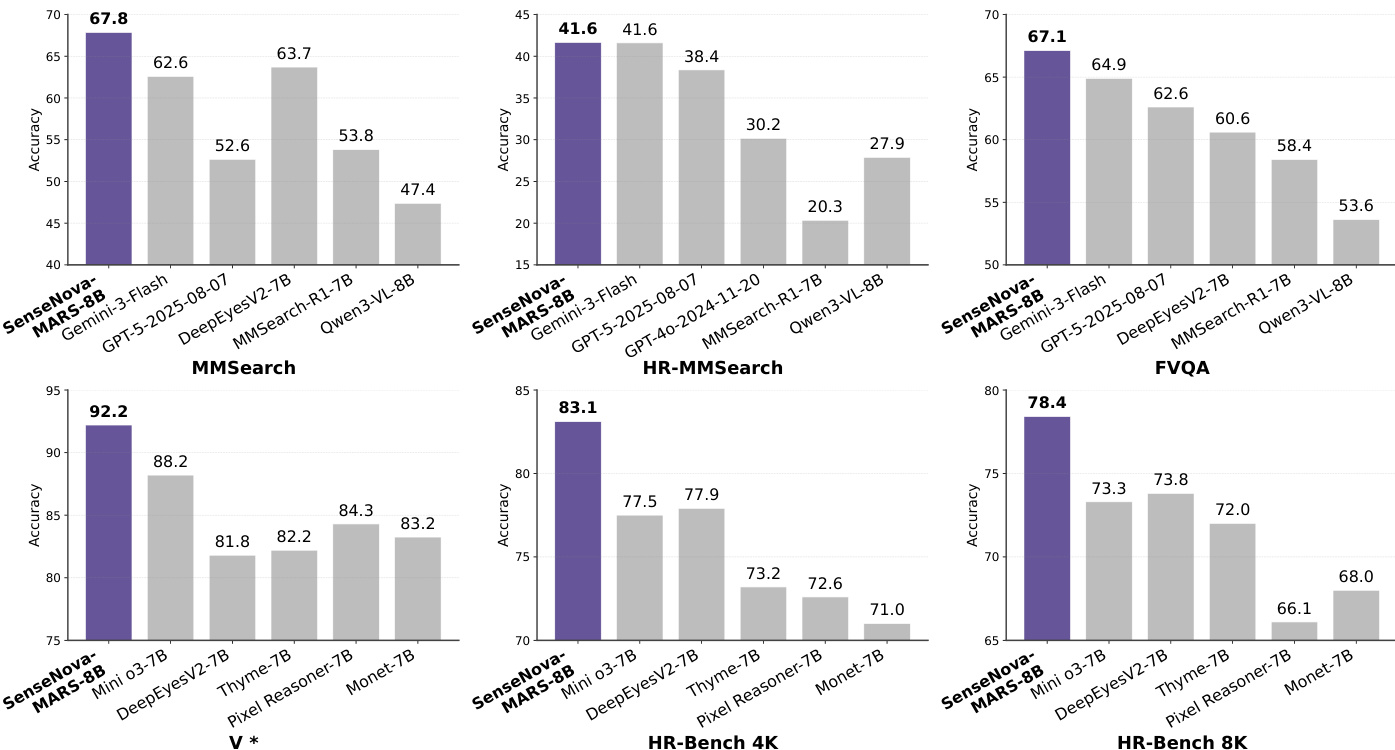
The authors use a two-stage training pipeline combining supervised fine-tuning and reinforcement learning to develop SenseNova-MARS-8B, which is evaluated on search-oriented and visual understanding benchmarks. Results show that SenseNova-MARS-8B achieves state-of-the-art performance among open-source models on both types of tasks, outperforming strong baselines including GPT-4o and Qwen3-VL-8B across multiple metrics.
The authors use a two-stage training pipeline, starting with supervised fine-tuning (SFT) followed by reinforcement learning (RL), to develop SenseNova-MARS-7B. Results show that combining both SFT and RL leads to the best performance across all benchmarks, with the final model achieving 59.06 on MMSearch, 38.52 on HR-MMSearch, and 83.84 on V* Bench, outperforming models trained with only SFT or only RL.
The authors use a two-stage training pipeline combining supervised fine-tuning and reinforcement learning to develop SenseNova-MARS-8B, which is evaluated on search-oriented and visual understanding benchmarks. Results show that SenseNova-MARS-8B achieves state-of-the-art performance among open-source models and surpasses several proprietary models, particularly in agentic search tasks, while also demonstrating strong fine-grained visual understanding capabilities.
The authors compare the performance of different reinforcement learning algorithms on a set of benchmarks, showing that BN-GSPO outperforms both GRPO and GSPO across all tasks. Results indicate that BN-GSPO achieves the highest scores on MMSearch, V* Bench, and HR-Bench 4K, demonstrating its effectiveness in balancing multi-tool learning and improving overall model performance.