Command Palette
Search for a command to run...
拡散モデルは透過性を理解する:動画拡散モデルを用いた透過物体の深度および法線推定
拡散モデルは透過性を理解する:動画拡散モデルを用いた透過物体の深度および法線推定
概要
透明な物体は、依然として認識システムにとって極めて困難な課題である。屈折、反射、透過といった現象により、ステレオ法やToF(時間飛行法)、あるいは単一画像に基づく判別型深度推定の前提が崩れ、深度推定に穴が生じたり、時間的に不安定な結果が得られてしまう。本研究の鍵となる洞察は、現代の動画拡散モデルが既に説得力のある透明物体の現象を合成できており、それらが光学的法則を内部に内包している可能性があるということである。そこで、透明・反射特性を持つシーンを対象とした合成動画コーパス「TransPhy3D」を構築した。このコーパスはBlender/Cyclesでレンダリングされた11,000本の動画シーケンスから構成されており、カテゴリ豊富な静的アセットと形状豊富なプロシージャルアセットを、ガラス・プラスチック・金属などの素材と組み合わせてシーンを構築している。物理ベースのレイトレーシングによりRGB画像、深度マップ、法線マップをレンダリングし、OptiXを用いたノイズ除去処理を施している。大規模な動画拡散モデルを出発点として、軽量なLoRAアダプタを用いて深度(および法線)推定のための動画間変換器を学習した。訓練フェーズでは、DiT(Diffusion Transformer)のバックボーン内でRGB画像と(ノイズを含む)深度潜在変数を連結し、TransPhy3Dと既存のフレーム単位の合成データセットを併用して共同学習を行うことで、任意長の入力動画に対しても時間的に一貫した深度推定が可能となった。このようにして得られたモデル「DKT」は、透明物体を含む実際の動画および合成動画ベンチマーク(ClearPose、DREDS(CatKnown/CatNovel)、TransPhy3D-Test)においてゼロショットで最先端の性能を達成した。従来の画像・動画ベースラインと比較して、精度と時間的一貫性の両面で顕著な向上を示し、法線推定バージョンはClearPoseにおける動画法線推定の最良結果を記録した。小型化された1.3Bパラメータのバージョンは1フレームあたり約0.17秒で実行可能である。把持タスクのスタックに統合した際、DKTの深度推定は、半透明・反射・拡散面のすべてにおいてタスク成功確率を向上させ、従来の推定器を上回った。以上の結果から、広い意味で「拡散モデルは透明性を理解している」という主張が裏付けられた。生成型動画事前学習モデルは、ラベルなしで効率的に再利用可能であり、困難な現実世界の操作タスクにおいて、堅牢かつ時間的に整合性のある認識能力をもたらすことが可能である。
One-sentence Summary
The authors, affiliated with Beijing Academy of Artificial Intelligence, Tsinghua University, and other institutions, propose DKT—a foundation model for video depth and normal estimation of transparent objects—by repurposing a video diffusion model via LoRA fine-tuning on TransPhy3D, a novel synthetic video dataset of 11k transparent/reflective scenes, achieving zero-shot SOTA performance on real and synthetic benchmarks, with applications in robotic grasping across translucent, reflective, and diffuse surfaces.
Key Contributions
- Transparent and reflective objects pose persistent challenges for depth estimation due to physical phenomena like refraction and reflection, which break assumptions in stereo, ToF, and monocular methods, leading to holes and temporal instability in predictions.
- The authors introduce TransPhy3D, a novel synthetic video dataset of 11,000 sequences (1.32M frames) with physically accurate rendering of transparent and reflective scenes, enabling training of video diffusion models on realistic transparent-object dynamics.
- By repurposing a large video diffusion model with lightweight LoRA adapters and co-training on TransPhy3D and existing frame-wise datasets, the proposed DKT model achieves zero-shot state-of-the-art performance on real and synthetic benchmarks, with improved accuracy and temporal consistency for video depth and normal estimation.
Introduction
Accurate depth estimation for transparent and reflective objects remains a critical challenge in 3D perception and robotic manipulation, as traditional methods relying on stereo or time-of-flight sensors fail due to refraction, reflection, and transmission. Prior data-driven approaches have been limited by small, static datasets and poor generalization, while existing video-based models struggle with temporal inconsistency. The authors introduce TransPhy3D, the first large-scale synthetic video dataset of transparent and reflective scenes—11,000 sequences (1.32M frames)—rendered with physically based ray tracing and OptiX denoising. They leverage this data to repurpose a pre-trained video diffusion model (VDM) into DKT, a foundation model for video depth and normal estimation, using lightweight LoRA adapters. By co-training on both video and frame-wise synthetic datasets, DKT achieves zero-shot state-of-the-art performance on real and synthetic benchmarks, delivering temporally coherent, high-accuracy predictions. The model runs efficiently at 0.17 seconds per frame and significantly improves robotic grasping success across diverse surface types, demonstrating that generative video priors can be effectively repurposed for robust, label-free perception of complex optical phenomena.
Dataset
- The dataset, TransPhy3D, is a novel synthetic video dataset designed for transparent and reflective objects, comprising 11,000 unique scenes with 120 frames each, totaling 1.32 million frames.
- It is built from two complementary sources: 574 high-quality static 3D assets collected from BlenderKit, filtered using Qwen2.5-VL-7B to identify transparent or reflective properties, and a procedurally generated set of parametric 3D assets that offer infinite shape variation through parameter tuning.
- A curated material library with diverse transparent (e.g., glass, plastic) and reflective (e.g., metal, glazed ceramic) materials is applied to ensure photorealistic rendering.
- Scenes are created using physics simulation: M assets are randomly selected, initialized with 6-DOF poses and scales in a predefined environment (e.g., container, tabletop), and allowed to fall and collide to achieve natural, physically plausible arrangements.
- Camera trajectories are generated as circular paths around the object’s geometric center, with sinusoidal perturbations to introduce dynamic viewpoint variation; videos are rendered using Blender’s Cycles engine with ray tracing for accurate light transport, including refraction and reflection.
- Final frames are denoised using NVIDIA OptiX-Denoiser to enhance visual quality.
- The authors use TransPhy3D to train DKT, a video depth estimation model, by fine-tuning a pretrained video diffusion model with LoRA. The dataset is used as the primary training source, with no explicit mention of data splitting or mixture ratios, but the diverse scene composition supports robust generalization.
- No cropping is applied; the full rendered frames are used. Metadata such as object categories, material types, and camera parameters are implicitly encoded in the scene generation pipeline and used during training.
Method
The authors leverage the WAN framework as the foundation for their video diffusion model, which consists of three core components: a variational autoencoder (VAE), a diffusion transformer (DiT) composed of multiple DiT blocks, and a text encoder. The VAE is responsible for compressing input videos into a lower-dimensional latent space and decoding predicted latents back into the image domain. The text encoder processes textual prompts into embeddings that guide the generation process. The diffusion transformer serves as the velocity predictor, estimating the velocity of the latent variables given noisy latents and text embeddings.
Refer to the framework diagram  to understand the overall architecture. The model operates within a flow matching framework, which unifies the denoising diffusion process. During training, a noisy latent x0 is sampled from a standard normal distribution, and a clean latent x1 is obtained from the dataset. An intermediate latent xt is then generated by linearly interpolating between x0 and x1 at a randomly sampled timestep t, as defined by the equation:
to understand the overall architecture. The model operates within a flow matching framework, which unifies the denoising diffusion process. During training, a noisy latent x0 is sampled from a standard normal distribution, and a clean latent x1 is obtained from the dataset. An intermediate latent xt is then generated by linearly interpolating between x0 and x1 at a randomly sampled timestep t, as defined by the equation:
The ground truth velocity vt, representing the derivative of the interpolation path, is computed as:
vt=dtdxt=x1−x0.The training objective is to minimize the mean squared error (MSE) between the predicted velocity from the DiT model, u, and the ground truth velocity vt, resulting in the loss function:
L=Ex0,x1,ctxt,tu(xt,ctxt,t)−vt2,where ctxt denotes the text embedding.
The training strategy involves co-training on both synthetic image and video data, referred to as TransPhy3D, to improve efficiency and reduce the computational burden of rendering. As illustrated in the figure below, the process begins by sampling a frame count F for the video in the current batch using the formula:
F=4N+1N∼U(0,5).
If F equals 1, the model samples a batch of paired data from both image and video datasets, where the video consists of a single frame. Otherwise, it samples exclusively from video datasets. The pipeline then proceeds by converting the depth video in each pair into disparity. Both the RGB and depth videos are normalized to the range [−1,1] to align with the VAE's training space. These normalized videos are then encoded by the VAE into their respective latents, x1c for RGB and x1d for depth. The depth latent x1d is transformed into an intermediate latent xtd using the same interpolation scheme as the clean latent. The input to the DiT blocks is formed by concatenating xtd and x1c along the channel dimension. The training loss is computed as the MSE between the DiT's output and the ground truth velocity vtd, which is derived from the depth latent:
L=Ex0,x1d,x1c,ctxt,tu(Concat(xtd,x1c),ctxt,t)−vtd2.All model components, including the VAE and text encoder, are kept frozen during training. Only a small set of low-rank weight adaptations, implemented via LoRA, are trained within the DiT blocks to enable efficient fine-tuning.
Experiment
- Trained on synthetic datasets (HISS, DREDS, ClearGrasp, TransPhy3D) and real-world ClearPose, using AdamW with learning rate 1e-5, batch size 8, and 70K iterations on 8 H100 GPUs; inference uses 5 denoising steps with overlapping segment stitching for arbitrary-length video processing.
- On ClearPose and TransPhy3D-Test datasets, DKT achieves new SOTA performance, outperforming second-best methods by 5.69, 9.13, and 3.1 in δ₁.₀₅, δ₁.₁₀, δ₁.₂₅ on ClearPose, and 55.25, 40.53, and 9.97 on TransPhy3D-Test, demonstrating superior accuracy on transparent and reflective objects.
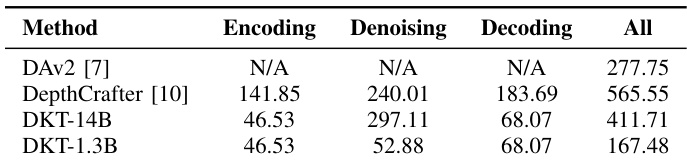
- DKT-1.3B achieves 167.48ms per frame inference time at 832×480 resolution, surpassing DAv2-Large by 110.27ms, with only 11.19 GB peak GPU memory, showing high efficiency suitable for robotic platforms.
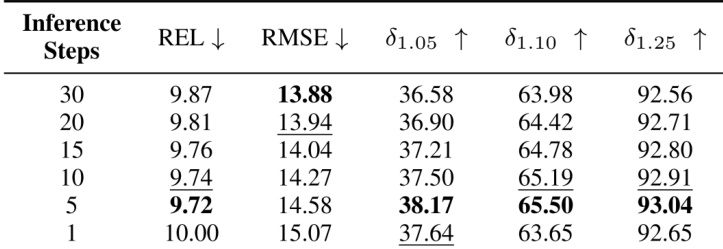
- Ablation studies confirm LoRA fine-tuning outperforms naive finetuning, and 5 inference steps balance accuracy and efficiency, with no significant gain beyond this point.
- DKT-Normal-14B sets new SOTA in video normal estimation on ClearPose, significantly outperforming NormalCrafter and Marigold-E2E-FT in both accuracy and temporal consistency.
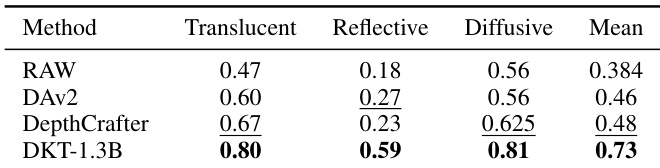
- Real-world grasping experiments on reflective, translucent, and diffusive surfaces show DKT-1.3B consistently outperforms baselines (DAv2-Large, DepthCrafter) across all settings, enabling successful robotic manipulation in complex scenes.
Results show that increasing inference steps improves performance up to a point, with 5 steps achieving the best balance—yielding the lowest REL and RMSE and the highest δ1.05, δ1.10, and δ1.25 scores. Beyond 5 steps, performance degrades, indicating diminishing returns and potential loss of detail.
The authors use a LoRA fine-tuning strategy to improve model performance, with results showing that the 14B model achieves the best performance across all metrics, including lower REL and RMSE values and higher accuracy for δ1.05, δ1.10, and δ1.25 compared to the 1.3B model. The inclusion of LoRA significantly reduces computational cost while enhancing depth estimation accuracy.

The authors compare the computational efficiency of different depth estimation models, showing that DKT-1.3B achieves the fastest inference time of 167.48ms per frame at a resolution of 832 × 480, outperforming DAv2-Large by 110.27ms. This efficiency is achieved with a peak GPU memory usage of 11.19 GB, making it suitable for real-time robotic applications.
Results show that DKT achieves the best performance on both ClearPose and TransPhy3D-Test datasets, outperforming all baseline methods in most metrics. On ClearPose, DKT achieves the lowest REL and RMSE values and ranks first in all error metrics, while on TransPhy3D-Test, it achieves the best results in REL, RMSE, and all δ metrics, demonstrating superior accuracy and consistency in depth estimation.

Results show that DKT-1.3B achieves the highest performance across all object categories in the Translucent, Reflective, and Diffusive classes, with scores of 0.80, 0.59, and 0.81 respectively, outperforming RAW, DAv2, and DepthCrafter. The model also achieves the best mean score of 0.73, indicating superior overall depth estimation accuracy.