Command Palette
Search for a command to run...
Idea2Story:研究コンセプトを完全な科学的物語に変換する自動化パイプライン
Idea2Story:研究コンセプトを完全な科学的物語に変換する自動化パイプライン
概要
大規模言語モデル(LLM)に基づくエージェントを用いた自律的科学発見は、最近、エンドツーエンドの研究ワークフローを自動化する能力を示すとともに、顕著な進展を遂げている。しかし、現存するシステムは多くが実行時中心の実行パラダイムに依存しており、オンラインの膨大な科学文献を繰り返し読み込み、要約し、推論するという処理を実施している。このような即時計算戦略は高い計算コストを伴い、コンテキスト窓の制約に苦しむとともに、脆弱な推論や幻覚(hallucination)を引き起こしやすい。本研究では、自律的科学発見のための前処理駆動型フレームワーク「Idea2Story」を提案する。Idea2Storyは、オンラインでの推論から離れて、オフラインでの知識構築へと文献理解のアプローチを転換する。本フレームワークは、継続的に査読済み論文とその査読フィードバックを収集し、核心的な方法論的単位を抽出して再利用可能な研究パターンを構成し、構造化された方法論知識グラフとして統合する。実行時においては、曖昧なユーザーの研究意図が既存の研究パラダイムと一致させられ、無制限の生成や試行錯誤を避け、高品質な研究パターンの効率的検索と再利用が可能となる。事前に構築された知識グラフに基づいて研究計画と実行を実施することで、Idea2StoryはLLMのコンテキスト窓の制約を緩和し、文献に対する重複する実行時推論を大幅に削減する。定性的分析および初期の実証的検証を通じて、Idea2Storyが一貫性があり、方法論的に根拠を持つ、かつ新規な研究パターンを生成できること、またエンドツーエンドの設定において複数の高品質な研究デモンストレーションを生成できることを示した。これらの結果は、オフラインでの知識構築が、信頼性の高い自律的科学発見の実用的かつスケーラブルな基盤を提供しうることを示唆している。
One-sentence Summary
The AgentAlpha team proposes Idea2Story, a pre-computation framework that builds a methodological knowledge graph from peer-reviewed papers to ground vague research ideas into structured, reusable patterns—reducing LLM context limits and hallucination while enabling efficient, novel scientific discovery without runtime literature reprocessing.
Key Contributions
- Idea2Story introduces a pre-computation-driven framework that constructs a structured methodological knowledge graph from peer-reviewed papers and reviews, replacing inefficient runtime literature processing with offline knowledge curation to improve scalability and reduce hallucination.
- The system grounds user research intents by retrieving and composing validated research patterns from the knowledge graph, enabling efficient, context-aware planning that circumvents LLM context window limits and avoids open-ended trial-and-error generation.
- Preliminary empirical studies show Idea2Story generates coherent, novel, and methodologically grounded research demonstrations end-to-end, validating the practical feasibility of offline knowledge construction for autonomous scientific discovery.
Introduction
The authors leverage large language models to automate scientific discovery but address key inefficiencies in existing systems that rely on real-time, context-heavy literature processing. Prior approaches suffer from high computational costs, context window limits, and brittle reasoning due to repeated online summarization and trial-and-error exploration. Idea2Story introduces a pre-computation framework that builds a structured knowledge graph offline by extracting and organizing methodological units from peer-reviewed papers and their reviews. At runtime, it maps vague research intents to validated research patterns from this graph, enabling faster, more reliable, and more coherent scientific planning without reinventing known methods. This shift reduces hallucination risk and computational load while grounding research in empirically supported paradigms.
Dataset

-
The authors construct a paper pool from ~13,000 accepted machine learning papers (5,000 from NeurIPS, 8,000 from ICLR) published within the most recent three-year window, retaining full text (title, abstract, body) and associated review artifacts (comments, ratings, confidence scores, meta-reviews).
-
Each paper undergoes anonymization to remove author/reviewer identifiers (names, affiliations, emails) and safety filtering to eliminate toxic or abusive content, yielding a de-identified corpus that preserves technical and evaluative signals while minimizing privacy and safety risks.
-
The dataset is used to train Idea2Story, which leverages the paper-review pairs to learn how research contributions are framed and evaluated, supporting retrieval and composition of reusable methodological patterns rather than domain-specific content.
-
The knowledge graph built from this data reveals a hub-and-spoke structure: high-frequency domains act as hubs connecting many papers, while methodological patterns often bridge multiple domains—enabling abstraction-aware retrieval and synthesis beyond paper-level similarity.
Method
The framework of Idea2Story operates through a two-stage paradigm that decouples offline knowledge construction from online research generation, enabling the system to transform informal user ideas into structured, academically grounded research directions. The overall architecture is divided into an offline phase for building a persistent methodological knowledge base and an online phase for grounding user inputs and generating refined research patterns.
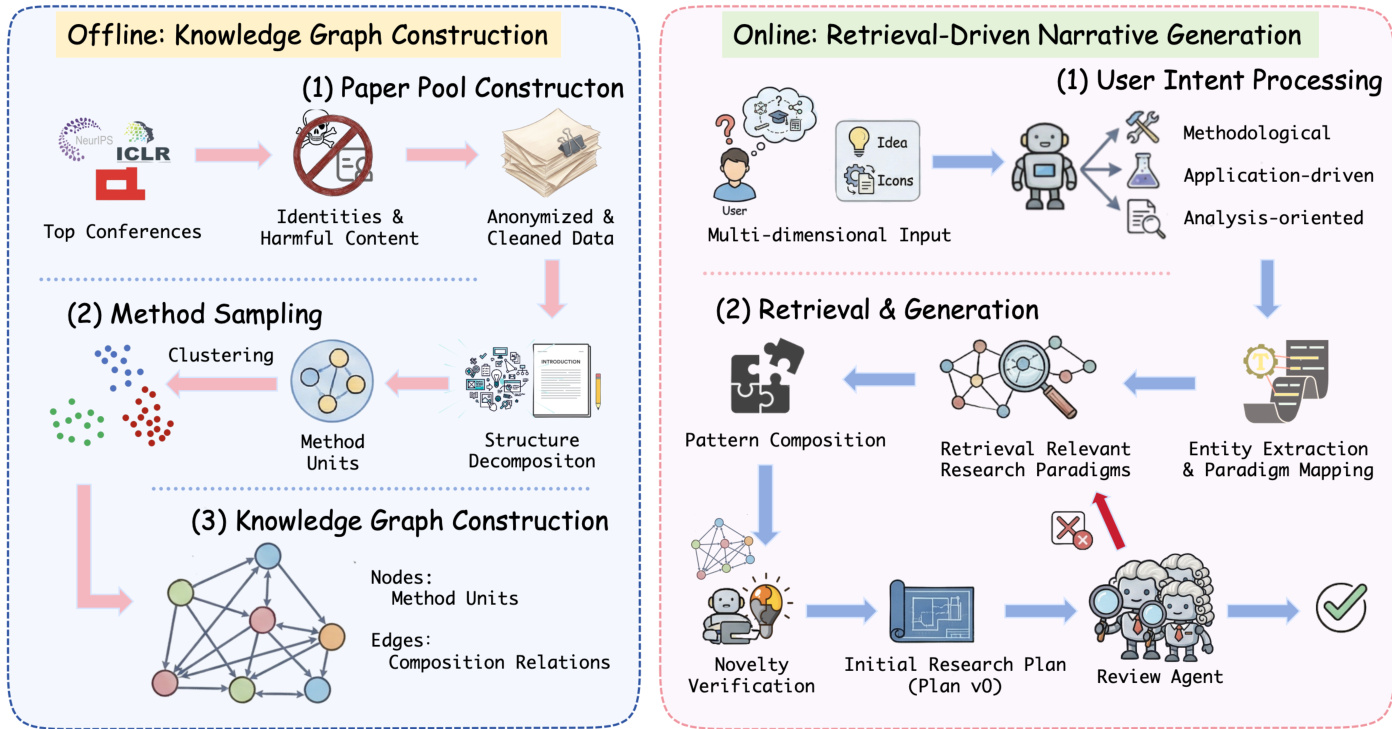
In the offline stage, the system begins by constructing a curated paper pool from top-tier peer-reviewed conferences, filtering out identities and harmful content to ensure privacy and safety. This anonymized and cleaned dataset undergoes method unit extraction, where each paper is deconstructed into its core methodological contributions. The extraction process leverages the structured layout of academic papers, analyzing the introduction, method, and experiments sections to isolate reusable method units that capture essential technical ideas while excluding implementation-specific details such as hyperparameter tuning or dataset selection. Each method unit is normalized into structured attributes, including atomic meta-methods and composition-level patterns, and represented as a vector embedding derived from its associated units. These embeddings are then projected into a lower-dimensional space using UMAP, followed by density-based clustering with DBSCAN to identify coherent research patterns that represent recurring methodological structures across the literature.
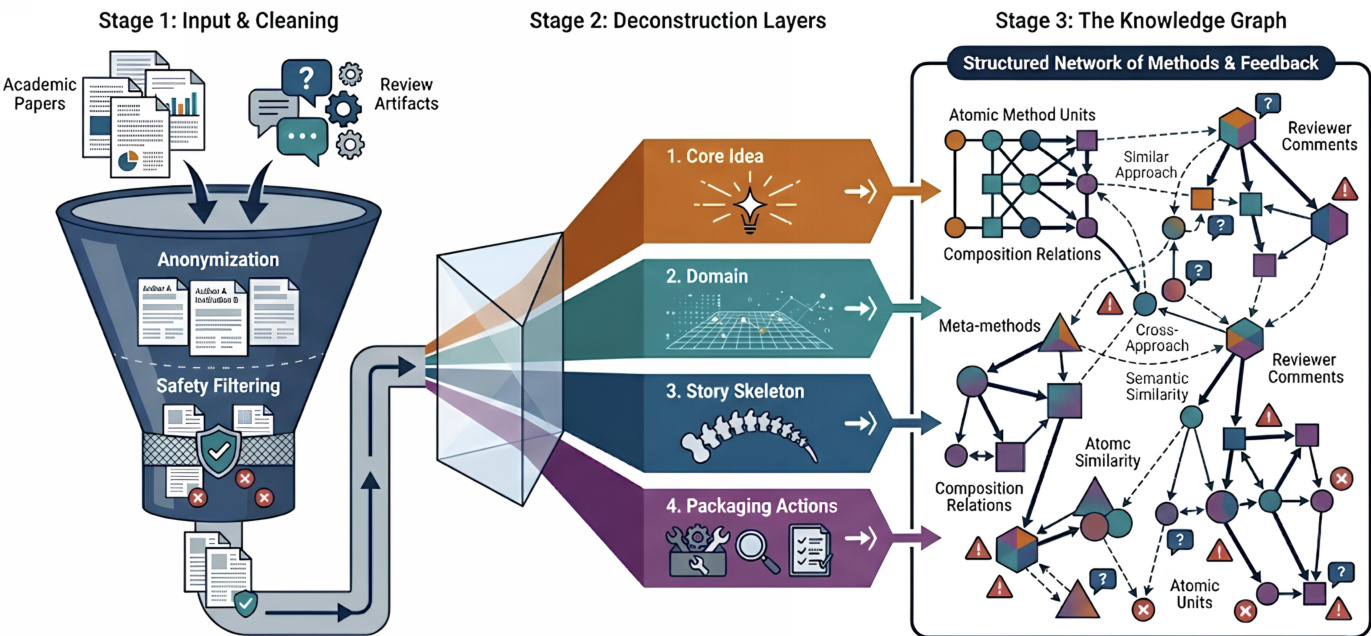
The extracted method units and research patterns are organized into a structured knowledge graph, which serves as a persistent methodological memory. This graph is defined as a directed graph G=(V,E), where nodes represent canonicalized method units or meta-methods, and edges encode composition relations between method units observed in prior work. Canonicalization groups semantically similar units into shared abstractions, reducing surface-level variation while preserving core methodological intent. The graph explicitly captures both reusable methodological elements and empirically observed compatibility, enabling the system to reason about methods at a higher level of abstraction than individual papers.
In the online stage, given a user-provided research idea, the system treats method discovery as a graph-based retrieval and composition problem over the knowledge graph. The process begins with user intent processing, where the input is interpreted as a multi-dimensional query that can be methodological, application-driven, or analysis-oriented. The system then performs retrieval and generation by identifying relevant research patterns through a multi-view retrieval formulation. This approach aggregates complementary signals from idea-level, domain-level, and paper-level retrieval views, each contributing a relevance score based on semantic similarity to the input query. The final ranking of research patterns is determined by a weighted sum of these view-specific scores, producing a ranked list of candidate patterns.
Following retrieval, the system initiates a review-guided refinement loop. A large language model acts as a reviewer, evaluating the retrieved research patterns on criteria such as technical soundness, novelty, and conceptual coherence. Based on the feedback, the system iteratively revises the pattern by recombining compatible method units or adjusting the problem formulation. This generate–review–revise loop continues until the pattern meets the reviewer's criteria for novelty, coherence, and feasibility, or until no further improvement is observed. The output is a refined research pattern that serves as a structured blueprint for downstream planning and paper generation.
Experiment
- Evaluated Idea2Story on 13K ICLR and NeurIPS papers to assess its ability to extract reusable methodological structures and generate coherent research patterns from ambiguous inputs.
- Analyzed extracted method units to confirm they represent meaningful, reusable abstractions.
- Conducted qualitative case studies using three real user ideas, comparing Idea2Story (powered by GLM-4.7) against a direct LLM baseline that lacks explicit pattern modeling.
- Found that Idea2Story reframes vague intent into dynamic, structurally grounded research blueprints, emphasizing generative refinement and evolving representations.
- Direct LLM outputs remained abstract, relied on conventional formulations, and lacked concrete methodological grounding.
- Independent evaluation by Gemini 3 Pro consistently favored Idea2Story for novelty, methodological substance, and overall research quality.